







参考文献:
- [CS05] Choi Y, Swartzlander E E. Parallel prefix adder design with matrix representation[C]//17th IEEE Symposium on Computer Arithmetic (ARITH’05). IEEE, 2005: 90-98.
- [SV11] Smart N P, Vercauteren F. Fully homomorphic SIMD operations[J]. Designs, codes and cryptography, 2014, 71: 57-81.
- [GHS12a] Gentry C, Halevi S, Smart N P. Fully homomorphic encryption with polylog overhead[C]//Annual International Conference on the Theory and Applications of Cryptographic Techniques. Berlin, Heidelberg: Springer Berlin Heidelberg, 2012: 465-482.
- [GHS12b] Gentry C, Halevi S, Smart N P. Homomorphic evaluation of the AES circuit[C]//Annual Cryptology Conference. Berlin, Heidelberg: Springer Berlin Heidelberg, 2012: 850-867.
- [HS13] Halevi S, Shoup V. Design and implementation of a homomorphic-encryption library[J]. IBM Research (Manuscript), 2013, 6(12-15): 8-36.
- [HS14] Halevi S, Shoup V. Algorithms in helib[C]//Advances in Cryptology–CRYPTO 2014: 34th Annual Cryptology Conference, Santa Barbara, CA, USA, August 17-21, 2014, Proceedings, Part I 34. Springer Berlin Heidelberg, 2014: 554-571.
- [ZQH+20] Zhang N, Qin Q, Hou Z, et al. Efficient comparison and addition for FHE with weighted computational complexity model[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2020, 40(9): 1896-1908.
文章目录
[SV11] 提出了 SIMD 打包技术,[GHS12a] 提出了 Permuting/Routing 槽切换技术,这两者都主要是数学推导(没细看,FHE 实现时都是最简单的情况)。[HS13] 设计实现了 RLWE-based BGV 的代码库 HElib(提出了 Double-CRT 表示,描述了设计框架),[GHS12b] 提出如何在 Double-CRT 下快速的执行模切换/秘钥切换,[HS14] 描述了 HElib 的一些优化算法(主要是使用 Shift-Networks 优化槽切换)。
Carry-Lookahead Adder
给定两个整数 A = a n − 1 ⋯ a 1 a 0 A=a_{n-1}\cdots a_1 a_0 A=an−1⋯a1a0, B = b n − 1 ⋯ b 1 b 0 B=b_{n-1}\cdots b_1 b_0 B=bn−1⋯b1b0,为了计算它们的加和,有多种加法器可以选择。我们使用以下逻辑符号:与门 ⋅ \cdot ⋅,或门 + + +,异或门 ⊕ \oplus ⊕,其中 ⋅ \cdot ⋅ 的优先级最高。
全加器(Full Adder, FA)的输入
a
,
b
,
c
i
n
∈
{
0
,
1
}
a,b,cin \in \{0,1\}
a,b,cin∈{0,1},输出
s
o
u
t
,
c
o
u
t
∈
{
0
,
1
}
sout,cout \in \{0,1\}
sout,cout∈{0,1},逻辑表达式为:
s
o
u
t
=
a
⊕
b
⊕
c
i
n
c
o
u
t
=
a
⋅
b
+
a
⋅
c
i
n
+
b
⋅
c
i
n
\begin{aligned} sout &= a \oplus b \oplus cin\\ cout &= a \cdot b+a \cdot cin + b \cdot cin \end{aligned}
soutcout=a⊕b⊕cin=a⋅b+a⋅cin+b⋅cin
定义信号
g
=
a
⋅
b
g=a \cdot b
g=a⋅b(generate),
k
=
a
+
b
k=a+b
k=a+b(kill),
p
=
a
⊕
b
p=a \oplus b
p=a⊕b(propagate),那么
s
o
u
t
=
p
⊕
c
i
n
c
o
u
t
=
g
+
k
⋅
c
i
n
\begin{aligned} sout &= p \oplus cin\\ cout &= g+k \cdot cin \end{aligned}
soutcout=p⊕cin=g+k⋅cin
Ripple-Carry Adder
行波进位加法器 (RCA):将
n
n
n 个全加器串联起来,输入
A
,
B
,
c
0
A,B,c_0
A,B,c0,迭代计算,
g
i
=
a
i
⋅
b
i
k
i
=
a
i
+
b
i
p
i
=
a
i
⊕
b
i
s
i
=
p
i
⊕
c
i
c
i
+
1
=
g
i
+
k
i
⋅
c
i
\begin{aligned} g_i &= a_i \cdot b_i\\ k_i &= a_i + b_i\\ p_i &= a_i \oplus b_i\\\\ s_i &= p_i \oplus c_i\\ c_{i+1} &= g_i+k_i \cdot c_i \end{aligned}
gikipisici+1=ai⋅bi=ai+bi=ai⊕bi=pi⊕ci=gi+ki⋅ci
关键路径的长度就是进位链 c 1 , ⋯ , c n − 1 , c n c_1,\cdots,c_{n-1},c_n c1,⋯,cn−1,cn 的迭代轮数 O ( n ) O(n) O(n)
Carry-Lookahead Adder
超前进位加法器(CLA):将 RCA 的进位链不断展开,得到
c
i
+
1
=
g
i
+
k
i
⋅
(
g
i
−
1
+
k
i
−
1
⋅
(
g
i
−
2
+
⋯
)
)
=
g
i
+
∑
j
=
0
i
−
1
(
∏
l
=
j
+
1
i
k
l
)
g
j
+
c
0
∏
l
=
0
i
k
l
\begin{aligned} c_{i+1} &= g_i+k_i \cdot (g_{i-1}+k_{i-1} \cdot (g_{i-2} + \cdots))\\ &= g_i + \sum_{j=0}^{i-1} \left(\prod_{l=j+1}^i k_l\right)g_j + c_0\prod_{l=0}^i k_l \end{aligned}
ci+1=gi+ki⋅(gi−1+ki−1⋅(gi−2+⋯))=gi+j=0∑i−1
l=j+1∏ikl
gj+c0l=0∏ikl
所以进位信号 c i + 1 c_{i+1} ci+1 可以直接根据 ( g i , k i ) (g_i,k_i) (gi,ki) 信号计算出来,不必等待 c i c_{i} ci 信号。每个 c i + 1 c_{i+1} ci+1 需要计算 i i i 个乘积项 ∏ l k l \prod_l k_l ∏lkl,构造 i i i 颗二叉树,关键路径长度仅为 O ( log n ) O(\log n) O(logn),但是扇入扇出系数极高,所需的计算单元超多。为了平衡计算延迟和电路复杂度,可以使用分块/分级的超前进位。
观察到 j = 0 , 1 , ⋯ , i , ∏ l = j i k l j=0,1,\cdots,i,\,\, \prod_{l=j}^i k_l j=0,1,⋯,i,∏l=jikl 有相同的后缀,以及 i = 1 , 2 , ⋯ , n , ∏ l = j + 1 i k l i=1,2,\cdots,n,\,\, \prod_{l=j+1}^i k_l i=1,2,⋯,n,∏l=j+1ikl 有相同的前缀。是否可以合并某些二叉树呢?或者使用 Horner 法则?
Parallel-Prefix Adder
并行前缀加法器(PPA):为了更好的理解 CLA,可以用代数语言描述
(
g
i
,
k
i
)
(g_i,k_i)
(gi,ki) 信号的合并过程。我们定义有序对
(
g
,
k
)
(g,k)
(g,k) 上的二元运算
∘
\circ
∘ 如下:
(
g
j
,
k
j
)
∘
(
g
i
,
k
i
)
:
=
(
g
j
+
k
j
g
i
,
k
i
k
j
)
(g_j,\,\, k_j) \circ (g_i,\,\, k_i) := (g_j+k_jg_i,\,\, k_ik_j)
(gj,kj)∘(gi,ki):=(gj+kjgi,kikj)
容易验证,它是:结合的、幂等的、不交换的。
那么 CLA 的逻辑表达式可以重写为:
(
c
i
+
1
,
k
0
k
1
⋯
k
i
)
=
(
g
i
+
k
i
⋅
(
g
i
−
1
+
k
i
−
1
⋅
(
g
i
−
2
+
⋯
)
)
,
k
i
⋯
k
1
k
0
)
=
(
g
i
,
k
i
)
∘
(
g
i
−
1
,
k
i
−
1
)
∘
⋯
∘
(
g
0
,
k
0
)
∘
(
c
0
,
1
)
\begin{aligned} (c_{i+1},\,\, k_0k_1\cdots k_i) &= (g_i+k_i \cdot (g_{i-1}+k_{i-1} \cdot (g_{i-2} + \cdots)),\,\, k_i\cdots k_1 k_0)\\ &= (g_i,k_i) \circ (g_{i-1},k_{i-1}) \circ \cdots \circ (g_0,k_0) \circ (c_0,1) \end{aligned}
(ci+1,k0k1⋯ki)=(gi+ki⋅(gi−1+ki−1⋅(gi−2+⋯)),ki⋯k1k0)=(gi,ki)∘(gi−1,ki−1)∘⋯∘(g0,k0)∘(c0,1)
其中的每个信号 ( g i , k i ) (g_i,k_i) (gi,ki) 和 ( c 0 , 1 ) (c_0,1) (c0,1) 都是立即的。根据二元运算的结合律,可以设计出一族 ( g , k ) (g,k) (g,k) 信号的并行合并网络。Knowles 提出了一类深度最优的并行前缀加法器,电路的构造为:

Knowles Adder 以两种著名的 PPA 为极限:Kogge-Stone Adder, Ladner-Fischer Adder。其中 LF 结构需要无限扇出(适合 FHE 运算),而 KS 结构需要无限并行(乘法数量)。Brent-Kung Adder 通过提升 level 层数(乘法深度)来平衡扇出系数和运算单元数量,还有一些 Hybrid Schemes 混合了 KS, LF, BK 结构。
我们用 Parallel-Prefix Graghs 来简化表示 PPA,每个黑点表示二元运算 ∘ \circ ∘ 运算(两次乘法,一次加法),运算方向从下往上。不同扇出的 Knowles Adder:

最适合 FHE 运算的 PPA 就是 Ladner-Fischer Adder:我们的软实现不关心扇出系数,重点关注的是乘法深度和乘法数量。
HE library
Double-CRT
[HS13] 基于 C++ NTL 设计了 RLWE-BGV 的代码实现库 HElib,使用了 [SV11] 的 SIMD 技术,以及 [GHS12a] 的 Permuting/Routing 技术。
为了进一步加速,[HS13] 将环 Z q [ x ] / ϕ m ( x ) \mathbb Z_q[x]/\phi_m(x) Zq[x]/ϕm(x) 中的多项式,表示为了 double-CRT 形式。在 BGV 中使用了 chain of moduli, q l = ∏ i = 0 l p i q_l = \prod_{i=0}^l p_i ql=∏i=0lpi,其中 p i p_i pi 是大小近似的素数,并且满足 m ∣ p i − 1 m|p_i-1 m∣pi−1 使得 Z p i \mathbb Z_{p_i} Zpi 中存在 m m m 次本原单位根 ζ i \zeta_i ζi,于是 ϕ m ( x ) = ∏ j ∈ Z m ∗ ( x − ζ i j ) ( m o d p i ) \phi_m(x)=\prod_{j \in \mathbb Z_m^*}(x-\zeta_i^j) \pmod{p_i} ϕm(x)=∏j∈Zm∗(x−ζij)(modpi)
我们先对模数
q
l
q_l
ql 做 CRT 分解,简记
R
=
Z
[
x
]
/
ϕ
m
(
x
)
R = \mathbb Z[x]/\phi_m(x)
R=Z[x]/ϕm(x),
R
p
=
R
/
(
p
R
)
R_{p}=R/(pR)
Rp=R/(pR),
Z
q
l
[
x
]
/
ϕ
m
(
x
)
≅
R
/
(
q
l
R
)
≅
R
/
(
p
0
R
)
×
R
/
(
p
1
R
)
×
⋯
×
R
/
(
p
l
R
)
Z_{q_l}[x]/\phi_m(x) \cong R/(q_lR) \cong R/(p_0R) \times R/(p_1R) \times \cdots \times R/(p_lR)
Zql[x]/ϕm(x)≅R/(qlR)≅R/(p0R)×R/(p1R)×⋯×R/(plR)
然后对于每个小环
R
p
i
≅
Z
p
i
[
x
]
/
ϕ
m
(
x
)
R_{p_i} \cong \mathbb Z_{p_i}[x]/\phi_m(x)
Rpi≅Zpi[x]/ϕm(x) 继续做 CRT 分解,
Z
p
i
[
x
]
/
ϕ
m
(
x
)
≅
Z
p
i
[
x
]
/
(
x
−
ζ
i
j
1
)
×
⋯
×
Z
p
i
[
x
]
/
(
x
−
ζ
i
j
ϕ
(
m
)
)
,
j
t
∈
Z
m
∗
\mathbb Z_{p_i}[x]/\phi_m(x) \cong \mathbb Z_{p_i}[x]/(x-\zeta_i^{j_1}) \times \cdots \times Z_{p_i}[x]/(x-\zeta_i^{j_{\phi(m)}}), j_t \in \mathbb Z_m^*
Zpi[x]/ϕm(x)≅Zpi[x]/(x−ζij1)×⋯×Zpi[x]/(x−ζijϕ(m)),jt∈Zm∗
假设 m = 2 k m=2^k m=2k 使得 ϕ m ( x ) = x m / 2 + 1 \phi_m(x)=x^{m/2}+1 ϕm(x)=xm/2+1,那么 Z m ∗ = { 1 , 3 , 5 , ⋯ , m − 1 } \mathbb Z_m^*=\{1,3,5,\cdots,m-1\} Zm∗={1,3,5,⋯,m−1},可以使用 FFT/NTT 来快速计算。对于一般的 m m m(混杂的 radix-X),在 Z m ∗ \mathbb Z_m^* Zm∗ 中的数字分布不规律,系数表示到 Double-CRT 之间的转化较为复杂。
综上,给定模数
q
l
q_l
ql 对应 level 的环元素
a
∈
Z
q
l
[
x
]
/
ϕ
m
(
x
)
a \in Z_{q_l}[x]/\phi_m(x)
a∈Zql[x]/ϕm(x),可以表示为矩阵形式:第
i
i
i 行是
a
(
x
)
(
m
o
d
p
i
)
a(x) \pmod{p_i}
a(x)(modpi) 的 NTT 域,第
i
i
i 行第
j
j
j 列是元素
a
(
ζ
i
j
)
(
m
o
d
p
i
)
a(\zeta_i^j) \pmod{p_i}
a(ζij)(modpi),形状
(
l
+
1
)
×
ϕ
(
m
)
(l+1) \times \phi(m)
(l+1)×ϕ(m)
D
o
u
b
l
e
C
R
T
l
(
a
)
=
{
a
(
x
)
(
m
o
d
p
i
)
(
m
o
d
x
−
ζ
i
j
)
}
0
≤
i
≤
l
,
j
∈
Z
m
∗
=
{
a
(
ζ
i
j
)
(
m
o
d
p
i
)
}
0
≤
i
≤
l
,
j
∈
Z
m
∗
\begin{aligned} DoubleCRT^l(a) &= \{a(x) \pmod{p_i}\pmod{x-\zeta_i^j}\}_{0\le i\le l,\,\, j\in \mathbb Z_m^*}\\ &= \{a(\zeta_i^j) \pmod{p_i}\}_{0\le i\le l,\,\, j\in \mathbb Z_m^*}\\ \end{aligned}
DoubleCRTl(a)={a(x)(modpi)(modx−ζij)}0≤i≤l,j∈Zm∗={a(ζij)(modpi)}0≤i≤l,j∈Zm∗
容易验证,环元素的加法/乘法,就是矩阵的 component-wise 加法/乘法,
D
o
u
b
l
e
C
R
T
l
(
a
+
b
)
=
D
o
u
b
l
e
C
R
T
l
(
a
)
+
D
o
u
b
l
e
C
R
T
l
(
a
)
D
o
u
b
l
e
C
R
T
l
(
a
⋅
b
)
=
D
o
u
b
l
e
C
R
T
l
(
a
)
⋅
D
o
u
b
l
e
C
R
T
l
(
a
)
\begin{aligned} DoubleCRT^l(a+b) &= DoubleCRT^l(a) + DoubleCRT^l(a)\\ DoubleCRT^l(a \cdot b) &= DoubleCRT^l(a) \cdot DoubleCRT^l(a)\\ \end{aligned}
DoubleCRTl(a+b)DoubleCRTl(a⋅b)=DoubleCRTl(a)+DoubleCRTl(a)=DoubleCRTl(a)⋅DoubleCRTl(a)
另外 Galois 群
G
a
l
(
Q
(
ζ
)
/
Q
)
≅
Z
m
∗
\mathcal{Gal}(\mathbb Q(\zeta)/\mathbb Q) \cong \mathbb Z_m^*
Gal(Q(ζ)/Q)≅Zm∗ 中的自同构映射为
κ
k
(
a
(
x
)
)
:
=
a
(
x
k
)
(
m
o
d
ϕ
m
(
x
)
)
,
∀
k
∈
Z
m
∗
\kappa_k(a(x)):=a(x^k) \pmod{\phi_m(x)},\,\, \forall k \in \mathbb Z_m^*
κk(a(x)):=a(xk)(modϕm(x)),∀k∈Zm∗
因为 m ∣ p i − 1 m|p_i-1 m∣pi−1,因此 G a L ( Z p i ( ζ ) / Z p i ) \mathcal{GaL}(\mathbb Z_{p_i}(\zeta)/\mathbb Z_{p_i}) GaL(Zpi(ζ)/Zpi) 的所有元素都是明文槽之间的置换(Frob 映射 κ 1 ( ζ ) = ζ p i = ζ \kappa_1(\zeta)=\zeta^{p_i}=\zeta κ1(ζ)=ζpi=ζ 是恒等映射)。其他的映射 κ k : ζ ↦ ζ k \kappa_k:\zeta \mapsto \zeta^{k} κk:ζ↦ζk 就等价于:把矩阵 D o u b l e C R T l ( a ) DoubleCRT^l(a) DoubleCRTl(a) 的第 j j j 列,移动到第 j k ( m o d m ) jk \pmod m jk(modm) 列。所以在 Double-CRT 表示上 Routing 是容易实现的。
对 BGV 采用 Double-CRT 是容易的,但是转换到 BFV 上就很麻烦了。
New Key Switching in CRT
秘钥切换本质上是关于
W
[
s
1
→
s
2
]
=
E
n
c
s
2
(
s
1
;
e
)
W[s_1 \to s_2] = Enc_{s_2}(s_1; e)
W[s1→s2]=Encs2(s1;e) 的同态数乘运算:
c
2
=
c
1
W
=
E
n
c
s
2
(
c
1
s
1
;
c
1
e
)
c
2
s
2
=
c
1
W
s
2
=
c
1
s
1
c_2=c_1W=Enc_{s_2}(c_1s_1; c_1e)\\ c_2s_2 = c_1Ws_2 = c_1s_1
c2=c1W=Encs2(c1s1;c1e)c2s2=c1Ws2=c1s1
注意, W [ s 1 → s 2 ] W[s_1 \to s_2] W[s1→s2] 不被解密,因此纠错是不必要的,形如 W = ( p 0 = s 1 − ( s 2 ⋅ p 1 + e ) , p 1 ) W=(p_0=s_1-(s_2 \cdot p_1 + e), p_1) W=(p0=s1−(s2⋅p1+e),p1),它满足 p 0 + p 1 ⋅ s 2 = s 1 + e p_0+p_1\cdot s_2=s_1+e p0+p1⋅s2=s1+e,这里的 s 1 s_1 s1 被破坏了,不过用于同态解密运算是足够的。同态解密后,密文 c 1 c_1 c1 作为标量的范数相对于模数 q l q_l ql 过大,导致同态运算后的噪声项 c 1 e c_1e c1e 破坏了明文。
在 BGV 中,为了控制秘钥切换的噪声项,使用的是二进制分解方案:给定
s
′
s'
s′ 下的密文
c
′
c'
c′,计算
c
′
=
∑
i
2
i
c
i
′
c'=\sum_i 2^i c_i'
c′=∑i2ici′,令
c
∗
=
c
0
′
∣
c
1
′
∣
c
2
′
∣
⋯
,
s
∗
=
s
′
∣
2
s
′
∣
4
s
′
∣
⋯
c^*=c_0'|c_1'|c_2'|\cdots,\,\, s^*=s'|2s'|4s'|\cdots
c∗=c0′∣c1′∣c2′∣⋯,s∗=s′∣2s′∣4s′∣⋯
那么计算出矩阵
W
=
W
[
s
∗
→
s
]
W=W[s^* \to s]
W=W[s∗→s],它满足
s
∗
=
W
⋅
s
s^*=W \cdot s
s∗=W⋅s,那么计算密文
c
=
c
∗
⋅
W
c=c^* \cdot W
c=c∗⋅W,
⟨
c
′
,
s
′
⟩
=
⟨
c
∗
,
s
∗
⟩
=
⟨
c
,
s
⟩
\langle c', s' \rangle = \langle c^*, s^* \rangle = \langle c, s \rangle
⟨c′,s′⟩=⟨c∗,s∗⟩=⟨c,s⟩
为了计算 c ′ c' c′ 的二进制分解,首先需要把 Double-CRT 转换回系数表示。接着,再把 log q l \log q_l logql 个密文 c i ′ c_i' ci′ 分别转化到 Double-CRT 下,以执行解密的内积运算。这花费了 O ( l log q l ) O(l \log q_l) O(llogql) 个长度为 n = ϕ ( m ) n=\phi(m) n=ϕ(m) 的 FFT/NTT 运算。
[GHS12b] 使用了不同的噪声项控制技术:临时提升模数。使用 LSB 编码方案,假设
⟨
c
′
,
s
′
⟩
=
2
e
′
+
a
(
m
o
d
q
)
\langle c',s' \rangle=2e'+a \pmod q
⟨c′,s′⟩=2e′+a(modq),对于任意的奇数
p
p
p,都有
⟨
c
′
,
p
s
′
⟩
=
2
p
e
′
+
p
a
=
2
e
′
′
+
a
(
m
o
d
p
q
)
\langle c',ps' \rangle = 2pe'+pa = 2e''+a \pmod{pq}
⟨c′,ps′⟩=2pe′+pa=2e′′+a(modpq)
其中 e ′ ′ = p e ′ + a ( p − 1 ) / 2 e'' = pe'+a(p-1)/2 e′′=pe′+a(p−1)/2 大约是原始噪声 e ′ e' e′ 的 p p p 倍。只要执行模切换,回到模数 q q q,那么噪声就基本还是 e ′ e' e′ 的量级。因此,我们选取充分大的奇数 p ≈ q m p \approx q\sqrt m p≈qm,使用变换矩阵 W = W [ p s ′ → s ] ( m o d p q ) W=W[ps' \to s] \pmod{pq} W=W[ps′→s](modpq) 的密文作为秘钥切换辅助。
虽然不需要对 c ′ c' c′ 做二进制分解了,但是依然需要计算 c ′ ( m o d p ) c' \pmod p c′(modp) 以组成 Z p q [ x ] / ϕ m ( x ) \mathbb Z_{pq}[x]/\phi_m(x) Zpq[x]/ϕm(x) 的 Double-CRT 表示。不过因为不需要维度扩展 log q l \log q_l logql 倍,因此只需要 O ( l ) O(l) O(l) 个 FFT/NTT 运算。
注意,因为模数 p q ≥ q 2 pq \ge q^2 pq≥q2,使得 ratio of modulus/noise 变得很大,因此需要将格的维度 n = ϕ ( m ) n=\phi(m) n=ϕ(m) 扩大接近两倍,以维持安全强度。但是 FFT/NTT 的复杂度为 O ( n log n ) O(n \log n) O(nlogn),因此计算效率依旧提升了大约 log q l / 2 \log q_l/2 logql/2 因子,同时公钥的存储开销也更低。
也可以混合使用进制分解和提升模数:把密文 c ′ c' c′ 分解为 ∑ i D i c i ′ \sum_i D^ic_i' ∑iDici′,其中 D D D 是很大的 radix 使得 c i ′ c_i' ci′ 的个数很少;接着,对于每个 c i ′ c_i' ci′ 采取临时提升模数的方案。后续有文章指出,使用混合方案,效率和噪声增长都表现的更好。
Modulus Switching in CRT
我们希望除了某些必要的系数表示,将密文和秘钥始终保持在 Double-CRT 表示下,方便快速计算。从模数 q l = ∏ j = 0 l p j q_l=\prod_{j=0}^l p_j ql=∏j=0lpj 下的密文 c c c 切换到模数 q l − 1 = ∏ j = 0 l − 1 p j q_{l-1}=\prod_{j=0}^{l-1} p_j ql−1=∏j=0l−1pj 下的密文 c ′ c' c′ 时,保持解密正确性 c ′ s ≡ c s ( m o d 2 ) c' s\equiv cs \pmod 2 c′s≡cs(mod2),同时要求 “rounding error” τ = c ′ − c / p t \tau=c'-c/p_t τ=c′−c/pt 的范数很小。
因为 p l p_l pl 是奇素数,这只需计算出 c † = p l ⋅ c ′ c^\dagger = p_l \cdot c' c†=pl⋅c′,使得: p l ∣ c † p_l|c^\dagger pl∣c†, c † ≡ c ( m o d 2 ) c^\dagger \equiv c \pmod 2 c†≡c(mod2)(充分但不必要),并且 c † − c c^\dagger-c c†−c 的范数很小。然后输出 c ′ = c † / p l c'=c^\dagger/p_l c′=c†/pl 即可。在 Double-CRT 下的模切换算法为:
- 从 Double CRT 的最后一行中,计算出 c ˉ = c ( m o d p l ) \bar c=c \pmod{p_l} cˉ=c(modpl) 的系数表示,取值范围 [ − p l / 2 , p l / 2 ) [-p_l/2,p_l/2) [−pl/2,pl/2),但是注意 c ˉ \bar c cˉ 属于 R R R(可在 R q l R_{q_l} Rql 中模拟)
- 将 c ˉ \bar c cˉ 的那些是奇数的系数,通过加减 p l p_l pl 变成偶数,取值范围 [ − p l , p l ) [-p_l,p_l) [−pl,pl),得到小多项式 δ \delta δ,满足 δ ≡ c ( m o d p l ) \delta \equiv c \pmod{p_l} δ≡c(modpl) 以及 δ ≡ 0 ( m o d 2 ) \delta \equiv 0 \pmod{2} δ≡0(mod2)
- 计算 δ \delta δ 的 Double CRT 表示,然后计算出 c † = c − δ ( m o d q l ) c^\dagger = c-\delta \pmod{q_l} c†=c−δ(modql),它满足 p l ∣ c † p_l|c^\dagger pl∣c†
- 对每个 c † ( m o d p j ) , j < l c^\dagger \pmod{p_j}, j<l c†(modpj),j<l,通过计算 p l − 1 ⋅ c † ( m o d p j ) p_l^{-1} \cdot c^\dagger \pmod{p_j} pl−1⋅c†(modpj),获得 c ′ = c † / p l c'=c^\dagger/p_l c′=c†/pl 的 Double-CRT 表示
上述过程中,step 1 花费了 1 1 1 个 INTT,step 3 花费了 l l l 个 NTT,共计 O ( l ) O(l) O(l) 个长度为 n = ϕ ( m ) n=\phi(m) n=ϕ(m) 的 FFT/NTT 运算。对于一般的明文模数 t t t,[GHS12] 也在附录中给出了对应算法,要稍微复杂一些。
注意:
- 利用上述的模切换算法,通过密文缩放
q
l
−
1
/
q
l
q_{l-1}/q_l
ql−1/ql 来减少噪声的绝对大小,需要保持切换前后的解密噪声保持同余关系,
c ( m o d p q ) ↦ c ′ ≈ c / p ( m o d q ) , s . t . [ c s ] p q ≡ [ c ′ s ] q ( m o d t ) c \pmod{pq} \mapsto c' \approx c/p \pmod{q},\,\, s.t.\,\, [cs]_{pq} \equiv [c's]_{q} \pmod{t} c(modpq)↦c′≈c/p(modq),s.t.[cs]pq≡[c′s]q(modt)
因此,需要仔细计算 c , c † c,c^\dagger c,c† 之间的小差距 δ \delta δ,以保持它们的同余关系 - 如果仅仅是将两个密文切换到相同的 Level,并且无需减小噪声,那么就不需要上述算法了,而是简单取模即可,
c ( m o d p q ) ↦ c ′ = c ( m o d q ) , t h e n [ c s ] p q ≡ [ c ′ s ] q ( m o d t ) c \pmod{pq} \mapsto c'=c \pmod{q},\,\, then\,\, [cs]_{pq} \equiv [c's]_{q} \pmod{t} c(modpq)↦c′=c(modq),then[cs]pq≡[c′s]q(modt)
对应的 Double-CRT 表示下的算法就是,简单地删除 p l p_l pl 对应的那一行
WCC
在 Level FHE 的高层应用中,可以使用乘法数量、乘法深度来衡量算法的效率。然而许多工作中,人们往往只关注某一方面,而非综合考量,因此设计出的高级算法并不一定适合在 level FHE 上做计算。
[ZQH+20] 提出了 Weighted Computational Complexity(WCC)计算模型,复杂度定义为
W
C
C
=
∑
l
=
0
L
W
l
⋅
N
l
WCC = \sum_{l=0}^L W_l \cdot N_l
WCC=l=0∑LWl⋅Nl
其中 N l N_l Nl 是第 l l l 层的乘法数量, W l W_l Wl 是第 l l l 层的乘法开销(若 W l = 1 , ∀ l W_l=1,\forall l Wl=1,∀l 则只关注乘法数量,若 W l = 0 , l < L W_l=0,l<L Wl=0,l<L 则只关注乘法深度)。根据 [GHS12b] 的 Double-CRT 下的秘钥切换、模切换,开销为 O ( l ) O(l) O(l) 个长度 n = ϕ ( m ) n=\phi(m) n=ϕ(m) 的 NTT/FFT 运算。因此,忽略繁复的细节,粗略地选取权重为 W l = l + 1 , l ≥ 0 W_l = l+1, l\ge 0 Wl=l+1,l≥0,这是合适的,且足够指导我们设计更加适合 level FHE 的高级算法。
WCC Analysis
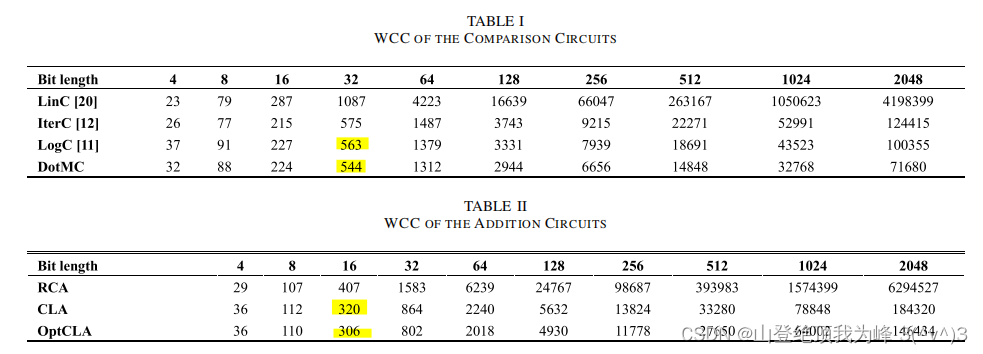
[ZQH+20] 分析了整数比较、整数加法的 WCC 复杂度。
三种比较算法,
-
Linear Comparison (LinC),线性比较
c o m i = ( a i ⊕ 1 ) ⋅ b i + ( a i ⊕ b i ⊕ 1 ) ⋅ c o m i − 1 com_i=(a_i\oplus 1) \cdot b_i + (a_i\oplus b_i\oplus 1) \cdot com_{i-1} comi=(ai⊕1)⋅bi+(ai⊕bi⊕1)⋅comi−1最终输出 C O M ( A , B ) = c o m n − 1 COM(A,B)=com_{n-1} COM(A,B)=comn−1,可计算出 W C C = O ( n 2 ) WCC=O(n^2) WCC=O(n2)。注意到, ( a i ⊕ 1 ) ⋅ b i (a_i\oplus 1) \cdot b_i (ai⊕1)⋅bi 和 ( a i ⊕ b i ⊕ 1 ) (a_i\oplus b_i\oplus 1) (ai⊕bi⊕1) 不可能同时为 1 1 1,因此公式中的 OR 逻辑 “ + + +” 就是 XOR 逻辑 “ ⊕ \oplus ⊕”,
c o m i = ( ( a i ⊕ 1 ) ⋅ b i ) ⊕ ( ( a i ⊕ b i ⊕ 1 ) ⋅ c o m i − 1 ) com_i=((a_i\oplus 1) \cdot b_i) \oplus ((a_i\oplus b_i\oplus 1) \cdot com_{i-1}) comi=((ai⊕1)⋅bi)⊕((ai⊕bi⊕1)⋅comi−1) -
Iteration Comparison (IterC),分治算法
t i , 1 = ( a i ⊕ 1 ) ⋅ b i , z i , 1 = a i ⊕ b i ⊕ 1 t i j = t i + h , j − h + z i + h , j − h ⋅ t i , h z i j = z i + h , j − h ⋅ z i h j > 1 , h = ⌈ j / 2 ⌉ t_{i,1} = (a_i \oplus 1)\cdot b_i,\,\, z_{i,1}=a_i\oplus b_i \oplus 1\\ t_{ij} = t_{i+h,j-h}+z_{i+h,j-h} \cdot t_{i,h}\\ z_{ij} = z_{i+h,j-h} \cdot z_{ih}\\ j>1,\,\, h=\lceil j/2 \rceil ti,1=(ai⊕1)⋅bi,zi,1=ai⊕bi⊕1tij=ti+h,j−h+zi+h,j−h⋅ti,hzij=zi+h,j−h⋅zihj>1,h=⌈j/2⌉最终输出 C O M ( A , B ) = t 0 , n COM(A,B)=t_{0,n} COM(A,B)=t0,n,它的 WCC 通项公式较为复杂难以写出
-
Logarithm Comparison (LogC),将线性比较完全展开
d i = ( a i ⊕ 1 ) ⋅ b i , z i = a i ⊕ b i ⊕ 1 c i = d i ⋅ ∏ j = i + 1 n − 1 z j d_i=(a_i \oplus 1) \cdot b_i,\,\, z_i=a_i \oplus b_i \oplus 1\\ c_i = d_i \cdot \prod_{j=i+1}^{n-1} z_j di=(ai⊕1)⋅bi,zi=ai⊕bi⊕1ci=di⋅j=i+1∏n−1zj最终输出 C O M ( A , B ) = ∑ i = 0 n − 1 c i COM(A,B) = \sum_{i=0}^{n-1}c_i COM(A,B)=∑i=0n−1ci,使用二叉树计算 Z n − 1 = ∏ j = 1 n − 1 z j Z_{n-1}=\prod_{j=1}^{n-1} z_j Zn−1=∏j=1n−1zj,其他的 Z n − i = ∏ j = i n − 1 z j Z_{n-i}=\prod_{j=i}^{n-1} z_j Zn−i=∏j=in−1zj 是这个二叉树的某些中间结果的乘积(总的乘法数量为 O ( n log n ) O(n \log n) O(nlogn) 而非 O ( n ) O(n) O(n))。它的复杂度为 W C C = O ( n log 2 n ) WCC=O(n \log^2 n) WCC=O(nlog2n)

两种整数加法,
- Ripple-Carry Adder,可计算出 W C C = O ( n 2 ) WCC=O(n^2) WCC=O(n2),隐藏的常数比 LinC 更大
- Parallel-Prefix Adder,可计算出 W C C = O ( n log 2 n ) WCC=O(n \log^2 n) WCC=O(nlog2n),隐藏的常数比 LogC 更大
Dot Multiplication
类似于 PPA 的二元运算,[ZQH+20] 定义了 DotMC,
(
P
1
,
G
1
)
∘
(
P
0
,
G
0
)
=
(
P
1
+
G
1
⋅
P
0
,
G
1
⋅
G
0
)
(P_1,\,\,G_1) \circ (P_0,\,\,G_0) = (P_1+ G_1 \cdot P_0,\,\, G_1 \cdot G_0)
(P1,G1)∘(P0,G0)=(P1+G1⋅P0,G1⋅G0)
简记
A
d
d
[
(
P
,
G
)
]
=
P
+
G
Add[(P,G)]=P+G
Add[(P,G)]=P+G 是最终信号的合并操作。定义初始信号
p
i
=
(
a
i
⊕
1
)
⋅
b
i
,
0
≤
i
≤
n
−
1
p_i=(a_i \oplus 1) \cdot b_i, 0 \le i \le n-1
pi=(ai⊕1)⋅bi,0≤i≤n−1,以及
g
i
=
a
i
⊕
b
i
⊕
1
,
1
≤
i
≤
n
−
1
g_i=a_i \oplus b_i \oplus 1,1\le i \le n-1
gi=ai⊕bi⊕1,1≤i≤n−1,
g
0
=
0
g_0=0
g0=0,那么有:
C
O
M
(
A
,
B
)
=
c
o
m
n
−
1
=
(
a
n
−
1
⊕
1
)
⋅
b
n
−
1
+
(
a
n
−
1
⊕
b
n
−
1
⊕
1
)
⋅
c
o
m
n
−
2
=
p
n
−
1
+
g
n
−
1
⋅
(
p
n
−
2
+
g
n
−
2
⋅
(
⋯
(
p
1
+
g
1
⋅
(
p
0
+
g
0
)
)
)
)
=
(
p
n
−
1
+
g
n
−
1
⋅
p
n
−
2
)
+
(
g
n
−
1
⋅
g
n
−
2
)
⋅
(
⋯
(
p
1
+
g
1
⋅
(
p
0
+
g
0
)
)
)
=
A
d
d
[
(
p
n
−
1
,
g
n
−
1
)
∘
(
p
n
−
2
,
g
n
−
2
)
∘
⋯
∘
(
p
0
,
g
0
)
]
\begin{aligned} COM(A,B) &= com_{n-1} = (a_{n-1}\oplus 1) \cdot b_{n-1} + (a_{n-1}\oplus b_{n-1}\oplus 1) \cdot com_{n-2}\\ &= p_{n-1}+ g_{n-1}\cdot(p_{n-2} + g_{n-2} \cdot (\cdots(p_1 + g_1 \cdot (p_0 + g_0))))\\ &= (p_{n-1}+ g_{n-1}\cdot p_{n-2}) + (g_{n-1}\cdot g_{n-2}) \cdot (\cdots(p_1 + g_1 \cdot (p_0 + g_0)))\\ &= Add\left[(p_{n-1},g_{n-1}) \circ (p_{n-2},g_{n-2}) \circ \cdots \circ (p_0,g_0)\right] \end{aligned}
COM(A,B)=comn−1=(an−1⊕1)⋅bn−1+(an−1⊕bn−1⊕1)⋅comn−2=pn−1+gn−1⋅(pn−2+gn−2⋅(⋯(p1+g1⋅(p0+g0))))=(pn−1+gn−1⋅pn−2)+(gn−1⋅gn−2)⋅(⋯(p1+g1⋅(p0+g0)))=Add[(pn−1,gn−1)∘(pn−2,gn−2)∘⋯∘(p0,g0)]
注意到
p
i
=
(
a
i
⊕
1
)
⋅
b
i
p_i = (a_i\oplus 1) \cdot b_i
pi=(ai⊕1)⋅bi 和
g
i
=
(
a
i
⊕
b
i
⊕
1
)
g_i = (a_i\oplus b_i\oplus 1)
gi=(ai⊕bi⊕1) 不可能同时为
1
1
1,因此 DotMC 算符中的 OR 逻辑就是 XOR 逻辑(甚至还是 Add 算术)。当然在计算
p
i
,
g
i
p_i,g_i
pi,gi 的初始信号时,必须使用 XOR 逻辑(对于一般的
p
>
2
p>2
p>2 需要乘法门)。
因为 DotMC 运算是结合的,因此可以使用二叉树方式,并行地合并信号(减小乘法深度)

可以计算出 W C C = O ( n log n ) WCC=O(n \log n) WCC=O(nlogn),乘法数量 O ( n ) O(n) O(n),乘法深度 O ( log n ) O(\log n) O(logn)。对比下 LogC 的乘法数量为 O ( n log n ) O(n \log n) O(nlogn),计算复杂度为 W C C = O ( n log 2 n ) WCC=O(n \log^2 n) WCC=O(nlog2n)。原因:类似于 Horner Rule,有许多乘法是冗余的。
而 CLA 本身就是使用了 DotMC,不过它的某一些 DotMC 可以延迟计算,平移到更低的 level 上计算,使得 W l W_l Wl 更小。
原始的 CLA 电路为:

把一些 DotMC 移动(绿色的那些点),

论文指出当 n > 16 n>16 n>16 时,DotMC 的比较和 OptCLA 更加高效,并且随着 n n n 增大效果更好。















 1491
1491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









