






编写算法实现顺序表的就地逆置,即利用原顺序表的存储单位把数据元素顺序反向,例如:1,5,6,9,8逆置为 8,9,6,5,1
题目分析:
就地逆置,就是指借用顺序表自身实现顺序逆置,不借助其他线性表。
如果让你口算从1+2+3+4+5+……+99,你会怎么计算呢?很显然,折半加法,将1到99分成两半,1+99=10,2+98 = 100,3+97=100,4+96=100,……,49+51 = 100,50,所以一共49个100,加上最后50,最终答案为4950。
之所以和大家回忆从1加到99这个式子,是因为咱们在就地逆置中会用到这种思想,把第一个数和最后一个数交换位置,第二个数和倒数第二个数交换位置………………那么直到中间就得分情况了
如果顺序表的长度为奇数,那么最后只剩下1个数字,不用做交换,如果是偶数,最后就不会剩下数字,直接完成交换。
那么问题就来了,表长度是奇数还是偶数,对应的算法(结束交换的判断语句)又有着怎样的区别呢?

由上图我们可以知道,不论表的长度length是偶还是奇,我们都只循环了length/2次,因此长度为奇和偶都一样
代码实现:
#include
const int MAX = 20; //设定这个顺序表的最大空间为20,也就是最多可以存20个int数
typedef int dataType; //数据类型为int型
typedef struct seqlist
{
dataType a[MAX]; //声明这条顺序表存储数据的工具————数组(一段连续的地址空间,所以我们称这种方式为顺序存储)
int size; //数据元素个数
}SeqList;
//初始化顺序表
void listInitiate(SeqList *seqlist)
{
seqlist->size = 0; //刚创建顺序表之后的数据个数为0
}
//往顺序表中放10个数
void listOriginal(SeqList *seqlist)
{
for (int i = 0; i < 10; i++)
{
seqlist->a[i] = i*4;
seqlist->size++; //多了一个数据元素,所以size得+1;
}
}
//将顺序表逆置
SeqList* listReserve(SeqList* seqlist)
{
int t;
for (int i = 0; i < seqlist->size / 2; i++)
{
t = seqlist->a[i];
seqlist->a[i] = seqlist->a[seqlist->size - 1 - i];
seqlist->a[seqlist->size - 1 - i] = t;
}
return seqlist;
}
//专门用来遍历输出的函数
void listPrint(SeqList *seqlist)
{
printf("顺序表:");
for (int i = 0; i < seqlist->size; i++)
printf("%d ", seqlist->a[i]);
printf("\n");
}
int main()
{
SeqList seqlist; //定义两条顺序表
printf("长度为奇数时:\n");
listInitiate(&seqlist); //初始化
listOriginal(&seqlist); //往链表里面放十个数
listPrint(&seqlist); //输出原顺序表
printf("就地逆置后的");
listReserve(&seqlist); //逆置顺序表
listPrint(&seqlist); //输出逆置后的顺序表
printf("\n长度为偶数时:\n");
seqlist.a[seqlist.size++] = -1;//往顺序表尾添加一个数据,使之长度变成偶数
listPrint(&seqlist);
printf("就地逆置后的");
listReserve(&seqlist);
listPrint(&seqlist);
return 0;
}[/prism]
运行结果:
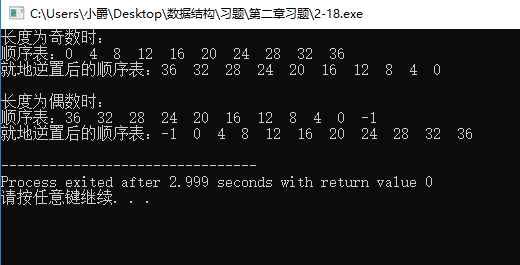
代码编译器:Dev-C++















 4545
4545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









