






一、流量统计
首先给出元数据表
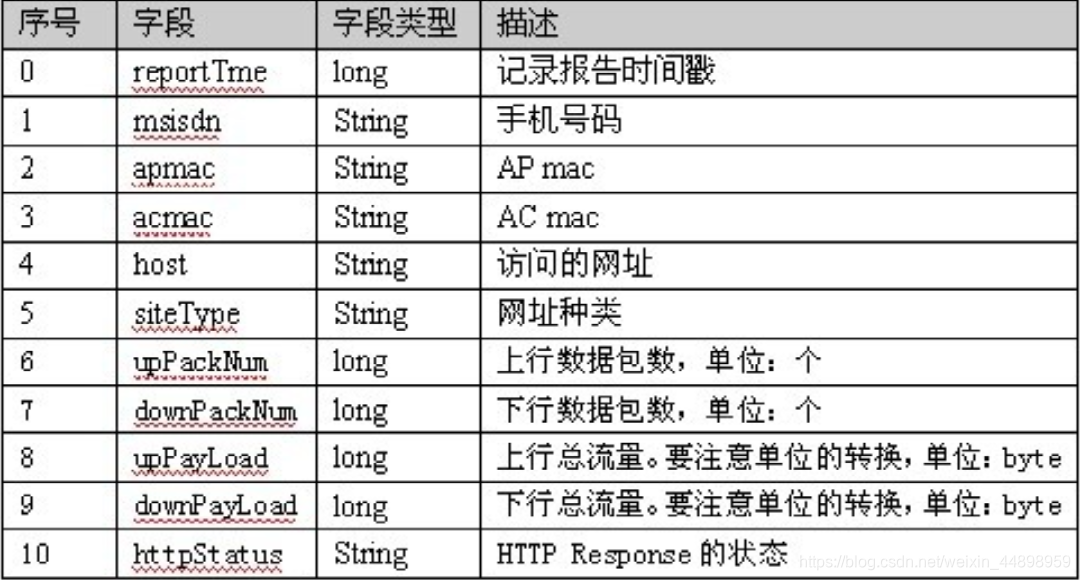
这是一张手机流量统计表

需求一: 统计求和
统计每个手机号的上行数据包总和,下行数据包总和,上行总流量之和,下行总流量之和。
分析:以手机号码作为key值,上行流量,下行流量,上行总流量,下行总流量四个字段作为value值,然后以这个key,和value作为map阶段的输出,reduce阶段的输入
step 1:创建javaBean用于封装数据
public class FlowBean implements Writable {
private Integer upFlow; //上行数据包
private Integer downFlow;//下行数据包数
private Integer upCountFlow; //上行流量总和
private Integer downCountFlow;//下行流量总和
public Integer getUpFlow() {
return upFlow;
}
public void setUpFlow(Integer upFlow) {
this.upFlow = upFlow;
}
public Integer getDownFlow() {
return downFlow;
}
public void setDownFlow(Integer downFlow) {
this.downFlow = downFlow;
}
public Integer getUpCountFlow() {
return upCountFlow;
}
public void setUpCountFlow(Integer upCountFlow) {
this.upCountFlow = upCountFlow;
}
public Integer getDownCountFlow() {
return downCountFlow;
}
public void setDownCountFlow(Integer downCountFlow) {
this.downCountFlow = downCountFlow;
}
@Override
public String toString() {
return upFlow+"\t"
+downFlow+"\t"
+upCountFlow+"\t"
+downCountFlow+"\t";
}
//实现序列化
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(upFlow);
dataOutput.writeInt(downFlow);
dataOutput.writeInt(upCountFlow);
dataOutput.writeInt(downCountFlow);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.upFlow = dataInput.readInt();
this.downFlow = dataInput.readInt();
this.upCountFlow = dataInput.readInt();
this.downCountFlow = dataInput.readInt();
}
}
step 2:自定义Mapper
public class FlowCountMapper extends Mapper<LongWritable, Text,Text,FlowBean> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
FlowBean flowBean = new FlowBean();
flowBean.setUpFlow(Integer.parseInt(split[6]));
flowBean.setDownFlow(Integer.parseInt(split[7]));
flowBean.setUpCountFlow(Integer.parseInt(split[8]));
flowBean.setDownCountFlow(Integer.parseInt(split[9]));
context.write(new Text(split[1]),flowBean);
}
}
step 3:自定义Readucer
public class FlowCountReducer extends Reducer<Text,FlowBean,Text,FlowBean> {
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
//这个flowBean指的是每个手机号的各项流量数总和
FlowBean flowBean = new FlowBean();
flowBean.setUpFlow(0);
flowBean.setDownFlow(0);
flowBean.setUpCountFlow(0);
flowBean.setDownCountFlow(0);
for (FlowBean value : values) {
flowBean.setUpFlow(flowBean.getUpFlow()+value.getUpFlow());
flowBean.setDownFlow(flowBean.getDownFlow()+value.getDownFlow());
flowBean.setUpCountFlow(flowBean.getUpCountFlow()+value.getUpCountFlow());
flowBean.setDownCountFlow(flowBean.getDownCountFlow()+value.getDownCountFlow());
}
context.write(key,flowBean);
}
}
step 4:创建Job
public class FlowCountJobMain extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
Job job = Job.getInstance(super.getConf(), "flowCount");
job.setJarByClass(FlowCountJobMain.class);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.setInputPaths(job,new Path("hdfs://node01:9000/data_flow.dat"));
job.setMapperClass(FlowCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setReducerClass(FlowCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("hdfs://node01:9000/flowcount_out"));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
int run = ToolRunner.run(new Configuration(), new FlowCountJobMain(), args);
System.exit(run);
}
}
Step5:运行并查看结果

需求二:上行流量倒序排序(递减排序)
以需求一的输出数据作为排序的输入数据,自定义FlowBean,以FlowBean为map输出的key,以手机号作为Map输出的value,因为MapReduce程序会对Map阶段输出的key进行排序
Step1:创建FlowBean实现可比较器
public class FlowBean implements WritableComparable<FlowBean> {
private Integer upFlow; //上行数据包
private Integer downFlow;//下行数据包数
private Integer upCountFlow; //上行流量总和
private Integer downCountFlow;//下行流量总和
public Integer getUpFlow() {
return upFlow;
}
public void setUpFlow(Integer upFlow) {
this.upFlow = upFlow;
}
public Integer getDownFlow() {
return downFlow;
}
public void setDownFlow(Integer downFlow) {
this.downFlow = downFlow;
}
public Integer getUpCountFlow() {
return upCountFlow;
}
public void setUpCountFlow(Integer upCountFlow) {
this.upCountFlow = upCountFlow;
}
public Integer getDownCountFlow() {
return downCountFlow;
}
public void setDownCountFlow(Integer downCountFlow) {
this.downCountFlow = downCountFlow;
}
@Override
public String toString() {
return upFlow+"\t"
+downFlow+"\t"
+upCountFlow+"\t"
+downCountFlow+"\t";
}
//实现序列化
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(upFlow);
dataOutput.writeInt(downFlow);
dataOutput.writeInt(upCountFlow);
dataOutput.writeInt(downCountFlow);
}
//反序列化
@Override
public void readFields(DataInput dataInput) throws IOException {
this.upFlow = dataInput.readInt();
this.downFlow = dataInput.readInt();
this.upCountFlow = dataInput.readInt();
this.downCountFlow = dataInput.readInt();
}
//实现比较器
@Override
public int compareTo(FlowBean o) {
return this.upFlow - o.upFlow;
}
}
Step2: 自定义Mapper
public class FlowSortMapper extends Mapper<LongWritable, Text,FlowBean,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
FlowBean flowBean = new FlowBean();
flowBean.setUpFlow(Integer.parseInt(split[1]));
flowBean.setDownFlow(Integer.parseInt(split[2]));
flowBean.setUpCountFlow(Integer.parseInt(split[3]));
flowBean.setDownCountFlow(Integer.parseInt(split[4]));
context.write(flowBean,new Text(split[0]));
}
}
Step3:自定义Reducer
public class FlowSortReducer extends Reducer<FlowBean, Text,Text,FlowBean> {
@Override
protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
Text phone = values.iterator().next();
context.write(phone,key);
}
}
Step4:创建Job任务
public class FlowSortJobMain extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
Job job = Job.getInstance(super.getConf(), "flowSort");
job.setJarByClass(FlowSortJobMain.class);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.setInputPaths(job,new Path("hdfs://node01:9000/flowcount_out/part-r-00000"));
job.setMapperClass(FlowSortMapper.class);
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(FlowSortReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("hdfs://node01:9000/flowsort_out"));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
int run = ToolRunner.run(new Configuration(), new FlowSortJobMain(), args);
System.exit(run);
}
}
Step5:运行并查看结果

可以看到排序完成了
需求三:手机号分区
在需求一的基础上,继续完善,将不同的手机号分到不同的数据文件的当中去,需要自定义分区来实现,这里我们自定义来模拟分区,将以下数字开头的手机号进行分开
- 135 开头数据到一个分区文件
- 136 开头数据到一个分区文件
- 137 开头数据到一个分区文件
- 其他分区
这里为了方便我就将需求一的代码修改一下
自定义Partitioner
public class FlowCountPartitioner extends Partitioner<Text,FlowBean> {
@Override
public int getPartition(Text text, FlowBean flowBean, int i) {
String phone = text.toString().substring(0, 3);
if(phone.equals("135"))
return 0;
else if(phone.equals("136"))
return 1;
else if(phone.equals("137"))
return 2;
else return 3;
}
}
step2: 修改job
给Job指定分区类和ReduceTask的个数
job.setPartitionerClass(FlowCountPartitioner.class);
//由于我们是4个分区,就设施4个ReduceTask
job.setNumReduceTasks(4);
step3:查看结果


二、Reduce端实现JOIN
案例需求
假如数据量巨大,两表的数据是以文件的形式存储在 HDFS 中, 需要用 MapReduce 程序来实现以下 SQL 查询运算
select a.id,a.date,b.name,b.category_id,b.price
from t_order a
left join t_product b
on a.pid = b.id


Step1:编写Mapper
比较关键的就是获得数据的来源
public class JoinMapper extends Mapper<LongWritable, Text,Text,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//判断数据来自哪个文件
FileSplit fileSplit = (FileSplit)context.getInputSplit();
String name = fileSplit.getPath().getName();
if(name.equals("product.txt"))
{
String[] split = value.toString().split(",");
context.write(new Text(split[0]),value);
}
else
{
String[] split = value.toString().split(",");
context.write(new Text(split[2]),value);
}
}
}
Step2:编写Reducer
public class JoinReducer extends Reducer<Text,Text,Text,Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String first = "";
String second = "";
for (Text value : values) {
if(value.toString().startsWith("p"))
{
first = value.toString();
}
else {
second = value.toString();
}
}
context.write(key,new Text(first+"\t"+second));
}
}
Step3 :编写job
public class JoinJobMain extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
Job job = Job.getInstance(super.getConf(), "joinReduce");
job.setJarByClass(JoinJobMain.class);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://node01:9000/joinreduce"));
job.setMapperClass(JoinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(JoinReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("hdfs://node01:9000/joioreduce_out"));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
int run = ToolRunner.run(new Configuration(), new JoinJobMain(), args);
System.exit(run);
}
}
查看结果

三、Map端实现join
使用场景:在有小表的情况下,可以使用分布式缓存,将小表数据发送至有所Map节点,Map节点在本地就可以对小表和大表进行join操作并输出结果。省去了网络IO阶段的大量资源消耗。
使用Job.addCacheFile即可指定上传到分布式缓存的文件路径
用上下文context对象的getCacheFiles方法可以获得所有分布式缓存文件的路径
然后使用文件系统对象下载文件,存入map中就行了
Mapper
public class MapJoinMapper extends Mapper<LongWritable, Text,Text,Text> {
private HashMap<String, String> map = new HashMap<>();
//将分布式缓存的数据读到本地
//setup方法只会调用一次
@Override
protected void setup(Context context) throws IOException, InterruptedException {
URI[] cacheFiles = context.getCacheFiles();
FileSystem fileSystem = FileSystem.get(cacheFiles[0], context.getConfiguration());
FSDataInputStream inputStream = fileSystem.open(new Path(cacheFiles[0]));
//将字节输入流包装成字符缓冲流
//这样我们可以一行一行读取
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
String line = null;
while ((line = bufferedReader.readLine())!=null)
{
String[] split = line.split(",");
map.put(split[0], line);
}
bufferedReader.close();
fileSystem.close();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(",");
String productId = split[2];
String productLine = map.get(productId);
String valueLine = productLine+"\t"+value.toString(); //V2
//3:将K2和V2写入上下文中
context.write(new Text(productId), new Text(valueLine));
}
}
Job任务
public class MapJoinJobMain extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
Job job = Job.getInstance(super.getConf(), "mapJoin");
job.setJarByClass(MapJoinJobMain.class);
//将指定文件放入分布式缓存
job.addCacheFile(new URI("hdfs://node01:9000/joinreduce/product.txt"));
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://node01:9000/joinreduce"));
job.setMapperClass(MapJoinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("hdfs://node01:9000/mapjoin_out"));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
int run = ToolRunner.run(new Configuration(), new MapJoinJobMain(), args);
}
}















 2150
2150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









