







关于调节样本提升随机森林预测模型准确度和正样本召回率的实例对比
1. 数据预处理
- 数据清洗:处理缺失值、异常值和重复数据,确保数据质量。
- 归一化/标准化:对特征进行归一化或标准化处理,确保特征值在相似的尺度上。
- 类别特征编码:使用独热编码(One-Hot Encoding)或标签编码(Label Encoding)处理类别特征。
- 特征选择:去除不相关或冗余的特征,减少噪声。
2. 特征工程
- 特征构造:根据业务理解构造新的特征,如组合特征、聚合特征等。
- 特征提取:利用PCA(主成分分析)等方法提取重要特征。
- 特征变换:对特征进行非线性变换,如多项式变换,以增加模型的表达能力。
3. 模型参数调优
- 树的数量:增加树的数量通常可以提高模型的稳定性,但需注意过拟合问题。
- 树的深度:调整树的最大深度,过深的树可能导致过拟合,过浅的树可能欠拟合。
- 最小样本数:调整叶子节点和分裂节点的最小样本数,以控制树的复杂度。
- 特征选择数:调整每次分裂时考虑的最大特征数,通常设为特征总数的平方根。
4. 集成学习
- 模型融合:使用不同的机器学习模型进行融合,如梯度提升树(GBDT)、极端梯度提升树(XGBoost)等,与随机森林进行融合。
- Stacking:使用堆叠(Stacking)方法,将多个模型的预测结果作为新的特征进行训练。
- Bagging 和 Boosting:结合Bagging(随机森林本身就是一种Bagging方法)和Boosting方法,进一步提升模型性能。
5. 其他策略
- 交叉验证:使用交叉验证(如K折交叉验证)来评估模型的性能,并选择最佳参数。
- 早停法:在训练过程中使用早停法,当验证集性能不再提升时停止训练,避免过拟合。
- 超参数搜索:使用网格搜索(Grid Search)或随机搜索(Random Search)等方法自动寻找最佳超参数组合。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 加载数据
data = load_iris()
X = data.data
y = data.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 定义随机森林分类器
rf = RandomForestClassifier(random_state=42)
# 定义参数网格
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'max_features': ['auto', 'sqrt', 'log2']
}
# 使用网格搜索进行超参数调优
grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=5, n_jobs=-1, verbose=2)
grid_search.fit(X_train, y_train)
# 输出最佳参数
print(f"Best parameters: {grid_search.best_params_}")
# 使用最佳参数进行预测
best_rf = grid_search.best_estimator_
y_pred = best_rf.predict(X_test)
# 输出准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")实战举例
此次研究的是在多次实验中,数字19出现的概率,分别针对正负样本不平衡问题进行了3次优化,思路和方案如下:
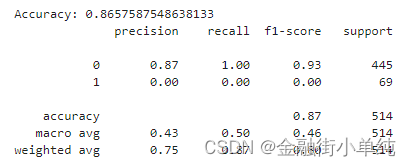
第1次:S19全量——正样本379条(15%),负样本2188条(85%)
模型选择=随机森林,准确度0.8658;但正样本召回率为0,基本预测无效;
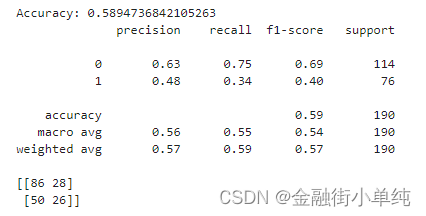
第2次:S19手工调样,正样本不变379条(占比上升到40%),负样本减少到570条(60%),
模型选择=随机森林,准确度0.5894,下降明显;但正样本召回率为0.34,略有起色;
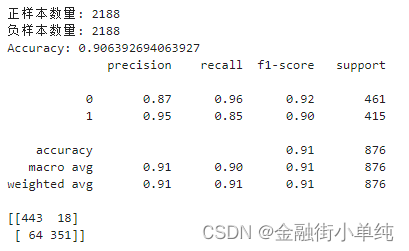
第3次:S19模型过采,正样本提升到2188条,负样本保持2188条
模型选择=随机森林,准确度0.9064,大幅度提升;正样本召回率0.85,大幅度提升;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











