






1. 友盟+介绍
友盟+ 以“数据智能,驱动业务增长”为使命,为移动应用开发者和企业提供包括统计分析、性能监测、消息推送、智能认证等一站式解决方案。截止 2023 年 6 月,已累计为 270 万移动应用和 980 万家网站,提供十余年的专业数据服务。
作为国内最大的移动应用统计服务商,其统计分析产品 U-App & U-Mini & U-Web 为开发者提供基础报表及自定义用户行为分析服务,能够帮助开发者更好地理解用户需求,优化产品功能,提升用户体验,助力业务增长。

为了满足产品、运营等多业务角色对数据不同视角的分析需求,统计分析 U-App 提供了包括用户分析、页面路径、卸载分析在内的多种「开箱即用」的预置报表,集成 SDK 上报数据后即可查看这些指标。除此以外,为了满足个性化的分析诉求,业务也可以自定义报表的计算规则,提供了事件细分、漏斗分析、留存分析等用户行为分析模型,用户可以根据自己的分析需求灵活地选择时间范围、设置事件名称、where 筛选和 Groupby 分组等。

如上所述,U-App 服务了众多应用场景,每天处理接近千亿条日志,需要考虑平衡好数据新鲜度、查询延迟和成本的关系,同时保障系统的稳定性,这对数据架构和技术选型提出了极高的要求。
针对报表类型不同的看数场景和业务需求,我们底层技术架构通过多种产品来支撑。在数据新鲜度方面,分别是提供了 T+0 的实时计算 和 T+1的离线批量计算,主要支持预置报表的计算场景,并将计算好的结果导出到存储,能够支持高并发的报表查询。在分析时效性方面,实现自定义报表支持秒级的 OLAP 分析,但鉴于成本和稳定性考虑,对于大数据量和大跨度的时间查询会走离线触发式计算。
在本文中,我们会分享友盟+ U-App 整体的技术架构,以及在实时和离线计算上面的优化方案
2. 友盟+数据架构及现状
如下图所示,在大数据领域这是一个比较通用的数据处理 pipeline,贯穿数据的加工&使用过程包括,数据采集&接入、数据清洗&传输、数据建模&存储、数据计算&分析 以及 查询&可视化,其中友盟U-App 数据处理的核心架构是红框部分。

U-App 整体架构大体可以分为四层:数据服务、数据计算、数据存储以及核心组件
● 数据服务:将查询 DSL 解析为底层引擎执行的 DAG,同时智能采样、查询排队等来尽可能减少系统过载情况,保证查询顺滑
● **数据计算:**根据不同分析场景抽象沉淀了自定义分析模型,包括行为分析和画像分析两大类;并且提供预置的基础统计指标的计算
● **数据存储:**使用了以 User-Event 为核心的数据模型,提供基于明细数据的行为分析
● **核心组件:**离线批量计算使用 MaxCompute,流式计算使用阿里云上实时计算 Flink,OLAP 计算使用 Hologres
3. 基于Flink + Paimon的流式湖仓使用实践
本节首先将介绍Apache Paimon主要优势,然后介绍基于Paimon在U-App实时基础指标计算和友盟设备ID维表更新场景的优化方案
3.1 Apache Paimon简介

3.1.1 概览
Apache Paimon 是一项流式数据湖存储技术,可以为用户提供高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。通俗解释即 Paimon 是一个流批一体的湖存储格式,它不是一个服务只是一个格式一个Jar包, 数据存储在的 OSS 或者 HDFS 上。可以使用 Flink CDC 来一键入湖到 Paimon 中,也可以通过 Flink SQL 或 Spark SQL 来批写、流写到 Paimon 当中。Paimon 也支持主流开源引擎,包括几乎现在所有的开源引擎。Paimon 也可以被 Flink 或 Spark 流读,这也是它作为流式数据湖的特有能力之一。
3.1.2 典型应用场景
● CDC 更新入湖,可被准实时查询(1-5min),并大幅简化入湖架构
● 支持 Partial-Update 能力,基于相同的主键可以各个流实时地打宽,另外支持多种聚合引擎( Deduplicate、Aggregation 等),在 Paimon 当中能被分钟级给下游各种计算引擎查询
● 支持流入的数据生成变更日志 changelog,给下游更好的流计算,即支持流读
● Paimon 作为湖存储格式,有很强的 Append 处理,并给 Append 表上多了流读流写、排序后加速查询的能力
3.2 U-App实时基础指标计算
3.2.1 产品模块介绍
友盟基础指标分为实时和离线指标两类,分别对应实时和离线两条计算链路,通过计算新增、活跃和启动等基础指标为客户提供整体概览数据

3.2.2 计算架构

(TT–阿里巴巴集团内部 datahub)(OTS–阿里巴巴集团内部 TableStore 表存储服务)
上述计算链路即传统的 lambda 架构,数据经过预处理后写入消息队列,离线链路同步消息队列数据到离线数仓进行加工处理将计算结果同步到 OTS (类 Hbase 存储)中;实时链路通过 Flink 直接消费消息队列的数据聚合成统计指标后写入 OTS,查询服务将离线和实时两份指标进行统一展示如上图所示。传统 lambda 架构的优缺点如下:
(1) 优点
● 任务容错性比较高
针对早期实时链路不稳定的特点,每天凌晨通过离线批处理计算结果覆盖实时计算结果的方式,保证T+1的离线数据的准确性。对于数据订正的场景可以通过回溯离线数据完成数据的订正;
● 职责边界划分清晰
实时链路只负责增量数据的计算,数据时效性比较高; 离线批处理链路计算全量历史数据,两条链路职责划分比较明确互相不影响,支持灵活的单独对每条链路进行扩展。
(2) 缺点
● 同时维护实时和离线两套计算逻辑,存储和计算都造成一定的浪费
实时和离线的计算逻辑是相同的,实时链路只计算当天的结果,第二天凌晨再用离线计算去覆盖实时计算结果,带来的问题就是一天的数据实时和离线重复计算,带来资源成本的浪费;
● 两套计算链路开发运维成本比较高,并且涉及实时和链路的数据口径会不一致等问题
两条链路必然带来运维成本的增加,对于友盟来说实时和离线任务还是分两个团队在维护。另外因为实时指标每天凌晨会被覆盖,可能会出现指标不一致的结果,给客户带来困扰;
实时链接直接基于TT的明细数据进行聚合数据不可查,给排查问题带来困难;
● 对于 U-App 数据量大的特性,基于 Flink 计算实时聚合指标会存在 State 大,实时任务稳定性差的问题
U-App 启动日志每天是千亿级数据量,直接基于明细数据通过 Flink 进行实时聚合,造成Flink任务的state比较大,另外上游任务稍微有波动就会对下游计算造成比较大的影响,对任务的稳定性要求比较高,所以我们现在采用的方案是拿资源换稳定,任务资源的 buffer 给的比较足,缺点就是造成一定资源的浪费。

3.2.3 基于阿里云 Flink + Paimon 的优化方案
针对上述提到的痛点问题,使用 Paimon 自带的聚合引擎能力,将指标的聚合下沉到 Paimon 表中实现,从而统计实时和离线计算链路

(TT–阿里巴巴集团内部 datahub)(OTS–阿里巴巴集团内部 TableStore 表存储服务)
CREATE TABLE paimon-ump .default.dwd_ump_app_install_paimon_table (
app_key STRING,
umid STRING,
cli_datetime BIGINT,
launch_time BIGINT,
launch_flag INT,
new_install_umid STRING,
new_install_flag INT,
app_channel STRING,
country STRING,
province_name STRING,
city_name STRING,
puid STRING,
device_brand STRING,
device_model STRING,
os STRING,
os_version STRING,
sdk_version STRING,
app_version STRING,
inst_datetime STRING,
inst_channel STRING,
inst_app_version STRING,
terminate_duration DOUBLE,
resolution STRING,
access STRING,
carrier STRING,
server_datetime BIGINT,
upload_traffic DOUBLE,
download_traffic DOUBLE,
app_upgrade INT,
hh STRING,
ds STRING
) PARTITIONED BY (ds)
WITH (
'metastore.partitioned-table' = 'true',
'maxcompute.life-cycle' = '360',
'bucket' = '-1',
'sink.parallelism' = '64',
'consumer.expiration-time' = '86400 s',
'snapshot.expire.limit' = '100',
'consumer.ignore-progress' = 'true'
);
由于 Paimon 的聚合引擎不支持去重,所以设计 DWM 层实现去重逻辑
CREATE TABLE `paimon-ump`.`default`.`dwm_ump_app_install_paimon_table` (
app_key STRING,
dimSTRING,
granularitySTRING,
distinct_idSTRING,
dsSTRING,
PRIMARY KEY (ds, app_key, dim, granularity, distinct_id) NOT ENFORCED
)PARTITIONED BY (ds)
WITH (
'metastore.partitioned-table' = 'true',
'merge-engine'='first-row',
'first-row.ignore-delete'='true'
'changelog-producer' = 'lookup',
'maxcompute.life-cycle' = '360',
'bucket' = '512',
'sink.parallelism' = '128',
'consumer.expiration-time' = '86400 s',
'snapshot.expire.limit' = '100',
'consumer.ignore-progress' = 'true'
);
CREATE TABLE `paimon-ump`.`default`.`dws_ump_app_install_paimon_table` (
app_key STRING,
dimSTRING,
granularitySTRING,
`value`DOUBLE,
dsSTRING,
PRIMARY KEY (ds, app_key, dim, granularity) NOT ENFORCED
)PARTITIONED BY (ds)
WITH (
'merge-engine'='aggregation',
'metastore.partitioned-table' = 'true',
'changelog-producer' = 'lookup',
'changelog-producer.lookup-wait' = 'false',
'maxcompute.life-cycle' = '360',
'bucket' = '16',
'sink.parallelism' = '16',
'fields.value.aggregate-function' = 'sum',
'consumer.expiration-time' = '86400 s',
'snapshot.expire.limit' = '100',
'consumer.ignore-progress' = 'true'
);
该方案带来的收益如下:
● 计算资源成本的节省
在实时基础指标计算场景下,在相同34实时个指标下,用 Paimon 替换 Flink 纯实时计算,计算资源方面可以来了 28% 的资源节省;
在离线指标计算场景下,Paimon 可以直接将离线计算链路任务替换掉不再需要,极大节省离线链路的计算和存储成本;
● 开发运维效率的提升
后续任务的开发和运维不再需要区分实时和离线两条链路,只需要开发维护一套代码逻辑即可,也不存在数据口径不一致等问题,极大的提高开发和运维效率;
数据可查,之前直接基于消息队列(TT)的数据不可直接查询,需要同步到离线或其他存储才可以,导致排查问题效率比较低,基于 Paimon 的表可以直接查询,极大提供问题排查和定位的效率;
同时 Paimon 表支持批读批写,支持数据的订正和回溯;
● 计算链路架构的统一
随着实时和批处理技术的发展,早期的 lambda 架构的缺点在当前业务场景下被逐渐放大变得越来越显著。通过 Paimon + Flink 构建的流式湖仓统一了实时和批处理链路架构,后续不需要再维护两套计算链路,降低了整个计算链路的复杂性。
3.3 U-App 设备 ID 维表的更新
3.3.1 使用场景
目前设备属性表包含两部分内容,一部分是设备相关的属性信息;同时还包括该设备对应的账号的用户属性。现在设备属性维表主要在各种分析模型管理用户属性、人群的用户列表和个体细查等模块。
3.3.2 计算架构
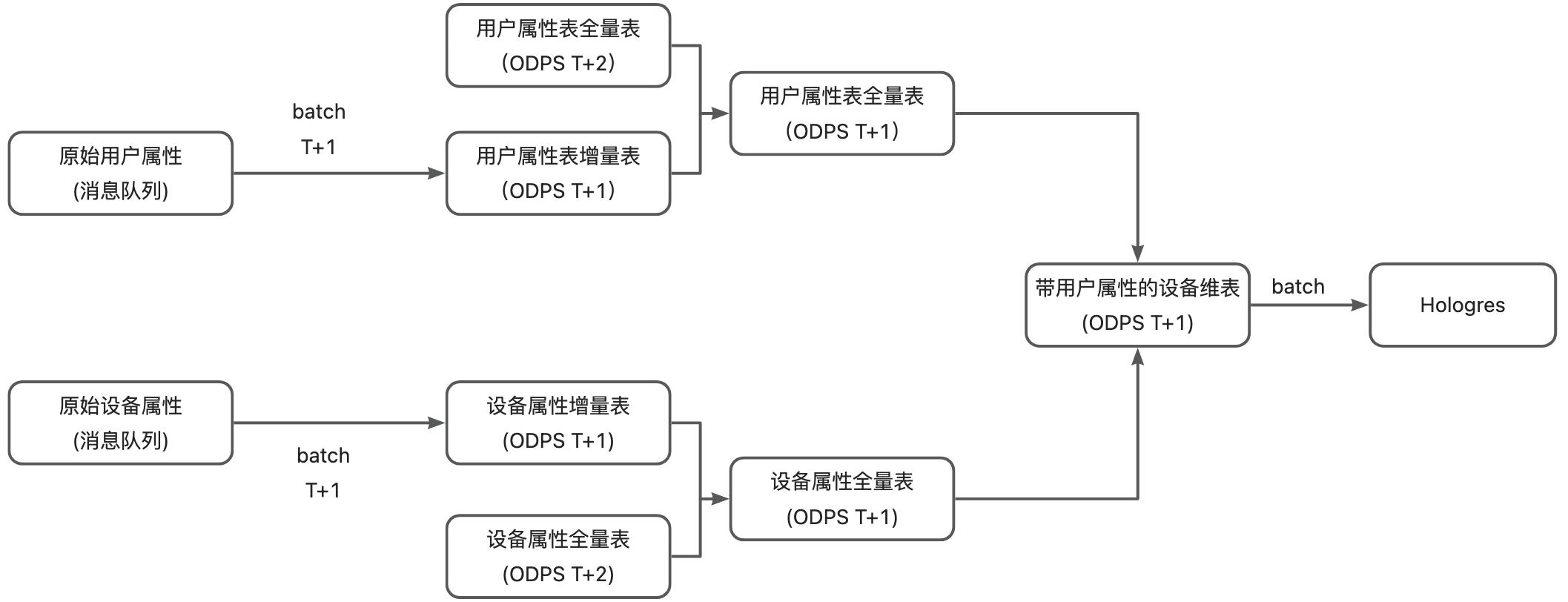
目前友盟设备属性维表的实现方案如上图所示,采用全量+增量的实现方式,这套架构的缺点如下:
● 时延高
目前这套逻辑都是在离线实现的,至少 T + 1 延时,而且需要等全量和增量合并完成后(任务运行2-3小时)下游任务才能使用,数据时效性比较差,用户无法看到当天设置的设备及用户属性信息;
● 存储计算成本高
每天需要读取全量数据(百亿级),与增量数据进行全量合并,在全量数据特别大,增量数据不多时任务计算成本加高,并且带来资源的浪费;
每天全量表一个分区存储所有数据,在增量数据不多的场景下,意味全量分区存在大量的重复数据,造成存储资源的浪费;
● 架构链路复杂度高
由于设备属性表中带有该设备关联的用户属性信息,加之这种全量和增加合并的实现方式导致链路复杂,导致每天产出全量分区容易有问题导致不能按时产出,新增业务也比较复杂,全量和增量割裂。
3.3.3 基于阿里云Flink + Paimon的解决方案
该方案使用 Paimon 的核心能力:主键更新能力,使用 Paimon Partial Update 引擎的能力,将整理计算链路的时效性从之前的 T+1 降低到分钟级。

CREATE TABLE paimon-ump.default.dim_ump_umid_paimon_table (
app_key STRING,
umid STRING,
cli_datetime BIGINT,
app_channel STRING,
province_name STRING,
city_name STRING,
idfa STRING,
imei STRING,
oaid STRING,
puid STRING,
zid STRING,
device_brand STRING,
device_model STRING,
os STRING,
os_version STRING,
app_version STRING,
inst_datetime STRING,
inst_channel STRING,
inst_app_version STRING,
active_ds STRING,
mobile STRING,
email STRING,
custom_properties STRING,
PRIMARY KEY(app_key,umid) NOT ENFORCED
) COMMENT 'paimon设备属性表'
WITH (
'merge-engine'='partial-update',
'metastore.partitioned-table' = 'false',
'changelog-producer' = 'lookup',
'partial-update.ignore-delete' = 'true',
'maxcompute.life-cycle' = '7',
'bucket' = '64',
'tag.automatic-creation' = 'process-time',
'tag.creation-period' = 'daily',
'tag.creation-delay' = '10 m',
'tag.num-retained-max' = '7',
'sink.parallelism' = '64',
'num-sorted-run.stop-trigger' = '2147483647',
'sort-spill-threshold' = '10',
'changelog-producer.lookup-wait' = 'false',
'sequence.field' = 'cli_datetime'
);
该方案带来的收益如下:
● 提高数据时效性降低时延
该方案将整个计算链路的时效性从T+1降低到 分钟级,用户当天设置的属性信息当天就可以使用进行分析使用,助力提升业务价值;
● 降低存储计算成本高
得益于Paimon的 Snapshot 管理,加上 LSM 的文件复用,比如同样是存储 100天的快照,原有离线数仓 100 天需要 100 份的存储,其中在增量数据不多的场景下大部分数据都是重复的,但是Paimon只需要 1 份的存储,大幅节省存储资源;
得益于 LSM 的增量合并能力,此条链路只有增量数据的处理,没有全量的合并;
● 简化计算链路架构复杂度
简化了之前的全量和增量计算链路,只需要维护一个Flink任务就可以实现全增量合并的目的,提升开发运维效率。
4. 总结展望
综上所述,通过 Flink + Paimon 的组合方式在降低计算资源成本,提高数据时效性,提升开发运维效率和统一数据链路架构方面,相比于传统的实现方案,体现出相当大的优势。后续友盟会继续跟进 Paimon 的新特性并探索 Paimon 在友盟+具体业务场景中的落地方案。
后续规划:
- 利用 Paimon 对 U-App 自定义事件的计算场景进行优化
- 跟进 Paimon 新特性,对现有任务的性能和资源使用进行进一步的优化
- 基于 Paimon 自带的 Metric 特性完善 Paimon 任务的监控
最后,由衷感谢@之信、 @才智老师在方案落地过程中的指导
更多内容
阿里云提供的基于Flink和Paimon的云上流式湖仓解决方案,旨在搭建高效、低延时的流式数据湖仓。此方案利用Flink的实时计算能力,结合Paimon的高效更新能力,实现数据在数仓分层间的实时流动。其优势包括将数据变更的传递延时从小时级甚至天级降低至分钟级,无需覆写分区即可直接接受变更数据,从而极大地降低了数据更新与订正的成本。此外,ETL链路的逻辑基于Flink SQL实现,统一了模型并简化了架构,提高了数据处理效率。点击下方链接了解更多详情。















 714
714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









