






作者介绍:王伟骏,花名(鸿历),2016 年硕士毕业于南京邮电大学,目前就职于阿里巴巴智能引擎事业部,长期从事大数据开发相关工作。
01
背景
在阿里集团数据湖计划的大背景下,入湖作为数据链路的第一环非常重要。
本文对 Flink 流 / 批 Job 写数据进 Paimon 主键表的源码进行了深入浅出的总结,后续会持续更新 Paimon 别的模块的解读。
02
写入 Paimon 表组合方式
表类型:PrimaryKeyTable、AppendTable
Bucket类型:FixBucketTable,DynamicBucketTable
Record 类型:NormalRecord,CdcRecord
本文介绍的是 PrimaryKeyTable + FixBucketTable + NormalRecord
03
Flink 入湖作业拓扑
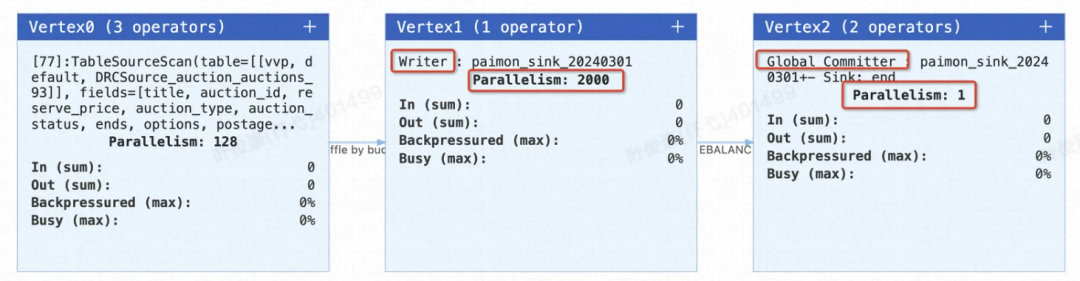
我们起了个 Flink 流任务写数据入湖作业,作业运行后拓扑如下:
第一个节点是产生数据的 Source 节点。
第二个节点是 Paimon Writer 节点,一个并发里面可以有多个 Bucket LSM Writer。
最后一个节点是一个并发恒为 1 的节点,是 Paimon 用来做两阶段提交的 Commit 节点。
04
Write 节点
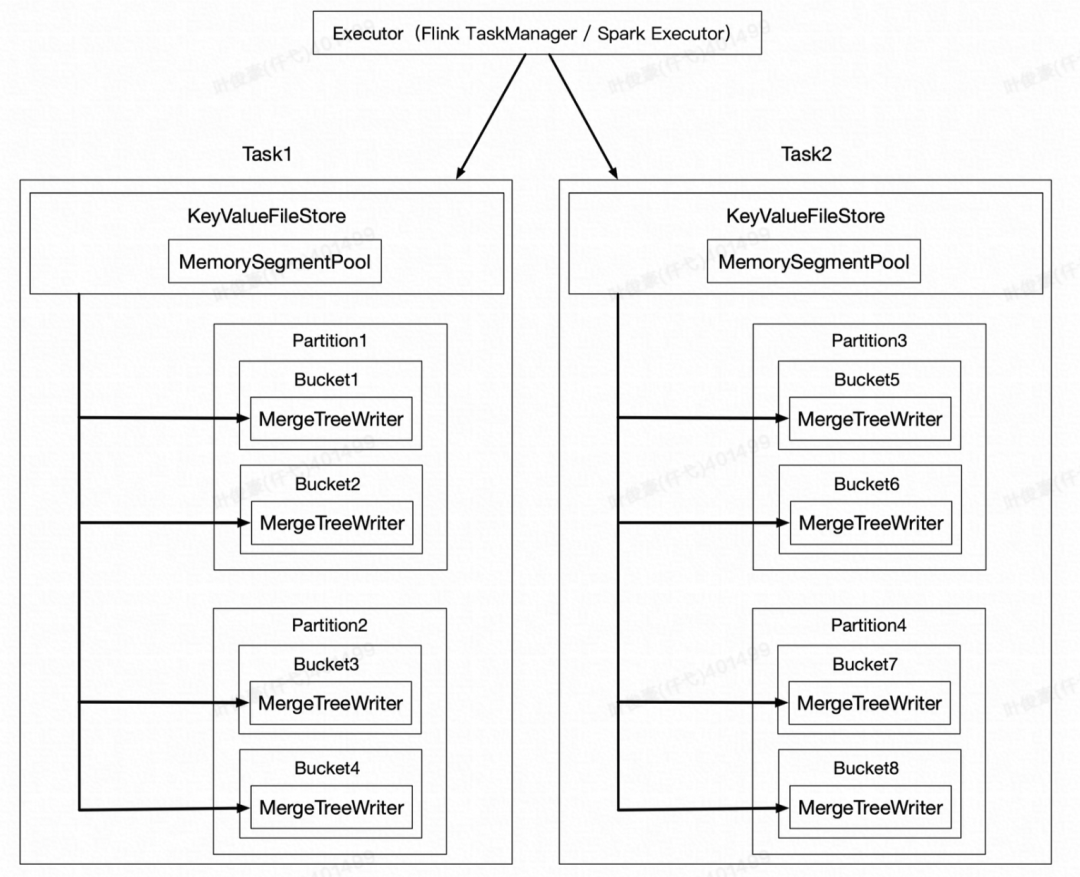
每个 Task 中都有一个 Writers,两级 Map,第一级 Map 的 Key 是 Partition,第二级 Map 的 Key 是 BucketNum,最后的 Value 是 LsmWriter。

Memory Resource
1、Paimon 自己申请堆内存,自己管理,自己释放。
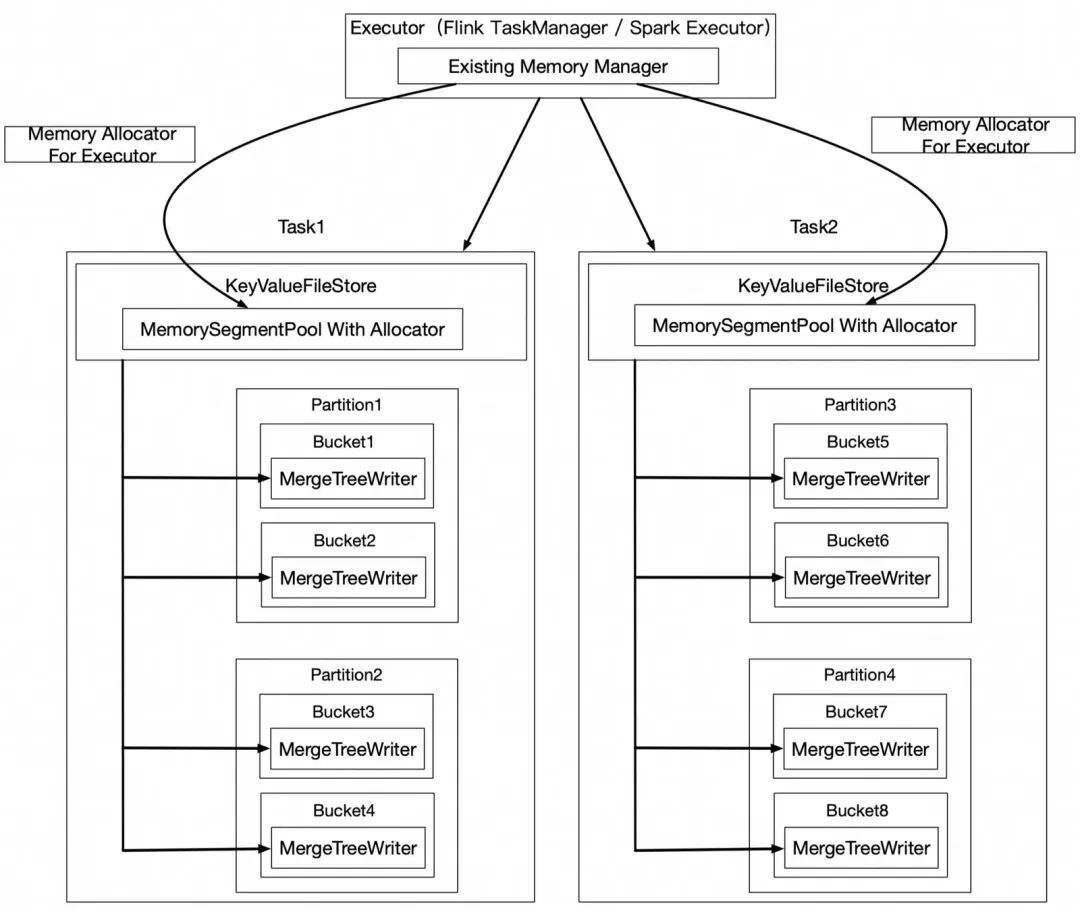
2、借助计算框架的内存管理技术,用堆外内存。
Process
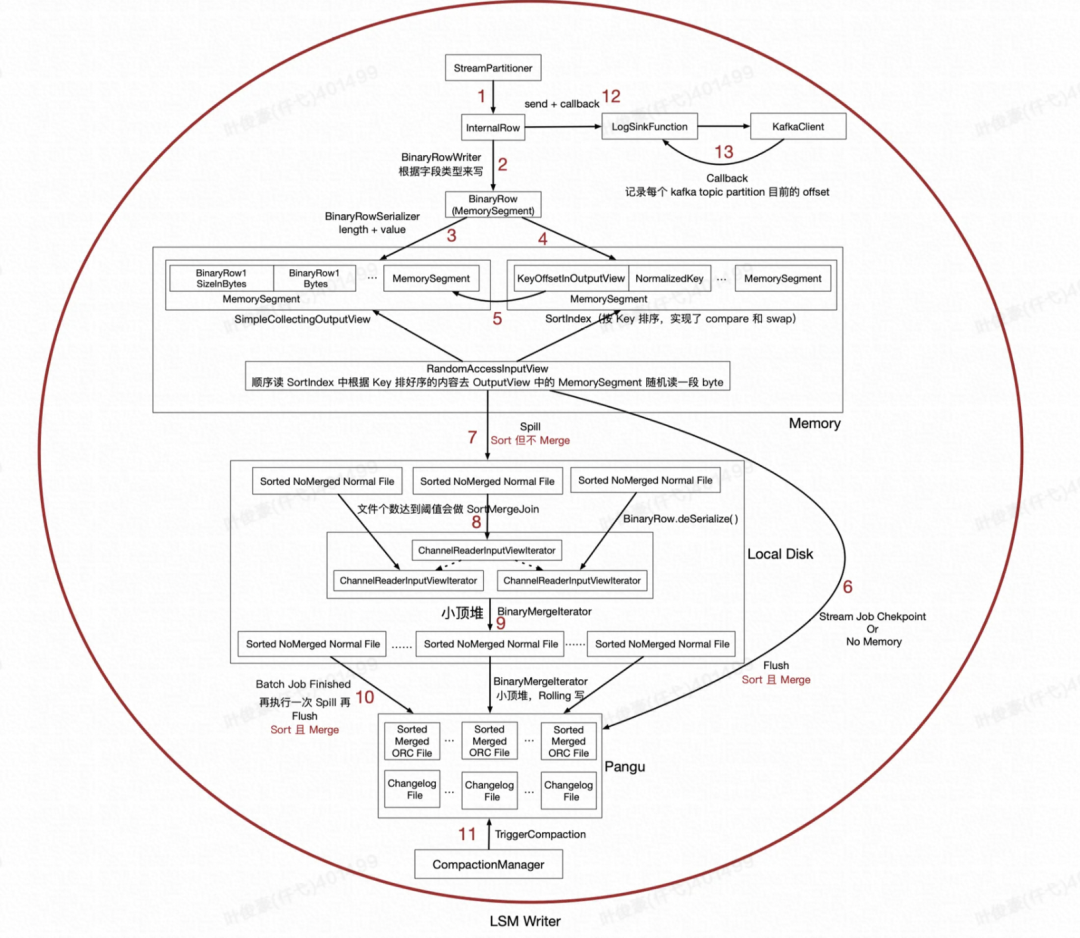
1、根据主键的 Hash 值决定数据发往下游哪个 Task。
2、将数据转化成 BinaryRow 格式。
3、将数据写入 DataBufffer(很多MemorySegment)中。
4、将数据的 Key 和数据在 DataBufffer 中的 Offset 记录到 SortIndex(很多MemorySegment)中。
5、SortIndex 的会记录每个 Key 在 DataBufffer 中的 Offset。
6、流作业遇到 Checkpoint 或者 Checkpoint 时,会将内存数据 Flush 到 Pangu,这中间会先对 SortIndex 中的数据进行排序,然后顺序扫 SortIndex 中的数据,根据 Offset 去到 DataBufffer 随机读取 byte[ ],获取 DataBufffer 中的数据。这期间对相同 Key 的多条记录会调用 Merge Function,整合成一条记录。
7、批作业或者对象存储的场景,内存不够的时候会将 DataBufffer 中的记录进行 Spill 到本地磁盘文件。
8、本地磁盘文件多个会进行 SortMergeJoin 操作,多个文件合并成少数文件。
9、多个合并的文件,进一步合并成大文件。
10、当批作业执行完成以后,先执行一遍 Spill,然后类似第 6 步,执行 Sort 且 Merge 的操作。
11、检查时候需要执行 Compaction。
05
Commit 节点
两阶段提交的第一阶段
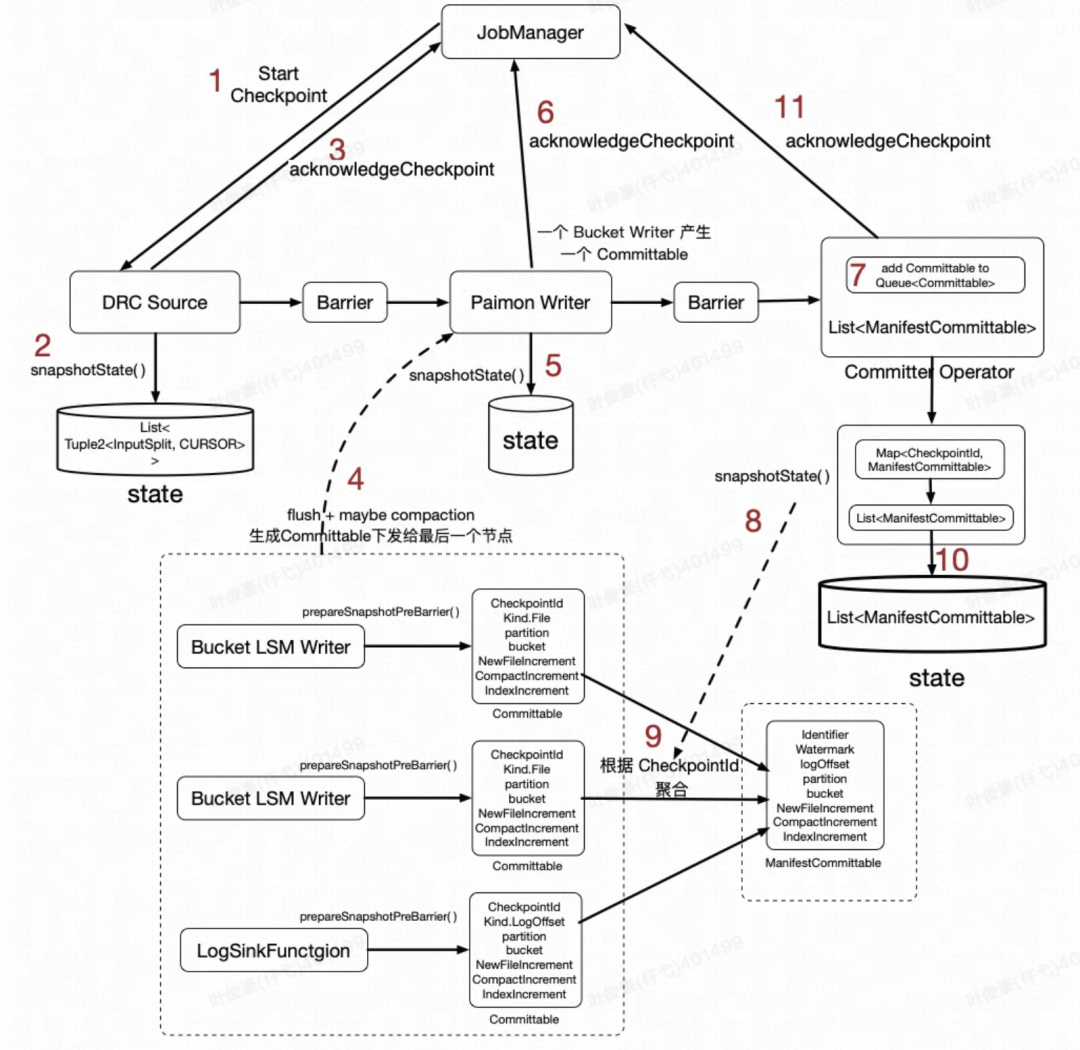
1、Flink JobManager 周期性向各 Source Task 发送执行 Checkpoint 的 RPC 调用。
2、Source 节点把状态写入 Flink State,这里是位点信息。
3、Source 节点写完状态会发 RPC 给 JobManager,“告诉它”我这个 Task 做完了 Checkpoint。
4、Barrier 从 Source 节点往下发到 Paimon Writer 节点,Paimon Writer 节点会将数据 Flush 到 Pangu,并且可能会执行 Compaction。Paimon Writer 在 prepareSnapshotPreBarrier 函数中会将文件信息封装到 Committable 中发往下一个节点,每个 LSM Writer 对应一个 Committable。最后一个节点 CommitterOperator 会在内存中缓存所有 Committable。
5、Paimon Writer 将信息写入 State,目前主键表的写入,Paimon Writer 这里没有 State。
6、Paimon Writer 节点做完了 Checkpoint,会发 RPC 给 JobManager,“告诉它”我这个 Task 做完了 Checkpoint。
7、Barrier 从 Paimon Writer 节点继续发往最后一个节点 CommitterOperator。
8、最后一个节点 CommitterOperator 收到要做 Checkpoint 的信号时,开始执行 snapshotState 相关逻辑。
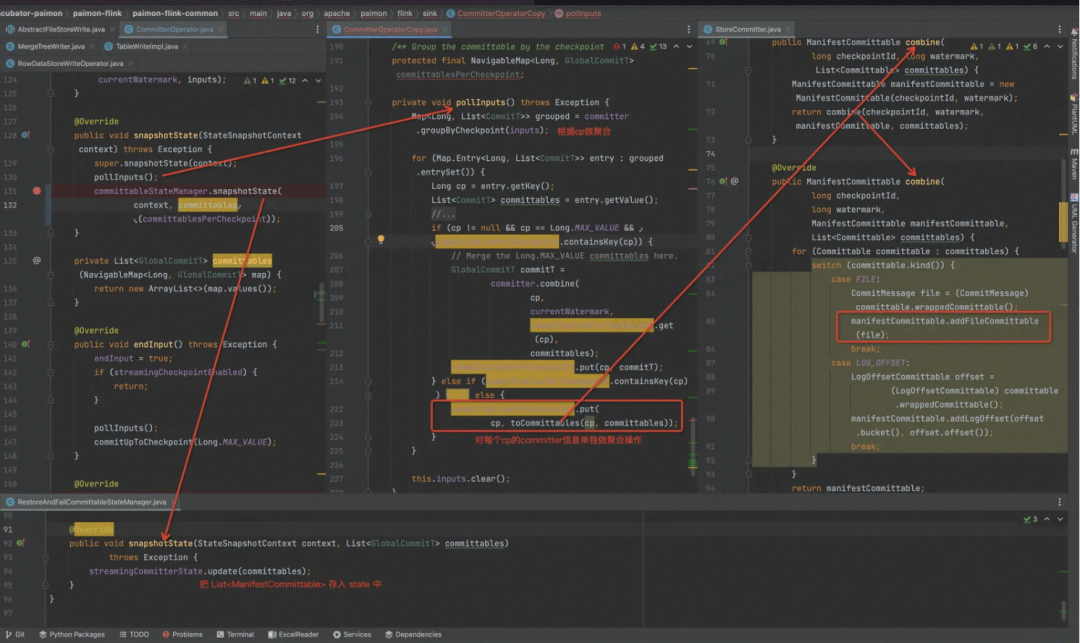
9、CommitterOperator 执行 snapshotState,首先把内存中的所有 Committable 根据 CheckpointId 来做聚合成一些ManifestCommittable。
10、将 List<ManifestCommittable> 写入 State,为啥是 List?因为在做这轮 Checkpoint 时,可能以前的 Checkpoint 没有成功,所以内存里堆积了以前 Checkpoint 对应的一些 Committable。也有可能在做这轮 Checkpoint 时,由于后面提交 DFS 文件时做的比较慢,新一轮的 Checkpoint 也来了。
11、CommitterOperator 节点做完了 Checkpoint,会发 RPC 给 JobManager,“告诉它”我这个 Task 做完了 Checkpoint。
到这个阶段,这轮 Checkpoint 其实就算做完了,这个 State 版本就可以用于容错恢复了。
两阶段提交的第二阶段
1-3、JobManager 收到了所有 Task 都做完了这一轮 Checkpoint 信号以后,会挨个回调 Task 的 notifyCheckpointComplete 函数。
4、CommitterOperator 会把内存中记录的(也是 State 中的)所有ManifestCommittable 往 DFS 提交,一个 ManifestCommittable 对应最多两个 Snapshot,取决于这次 Checkpoint Paimon Writer 是否发生了 Compaction。
5、整理元数据,整理Snapshot,原子性的把 Snapshot 提交到 DFS。如果文件系统的 Rename 操作不支持原子性,或者提交到别的非 DFS 系统的话,这里是需要引入一个 Catalog 锁来辅助实现原子性的提交。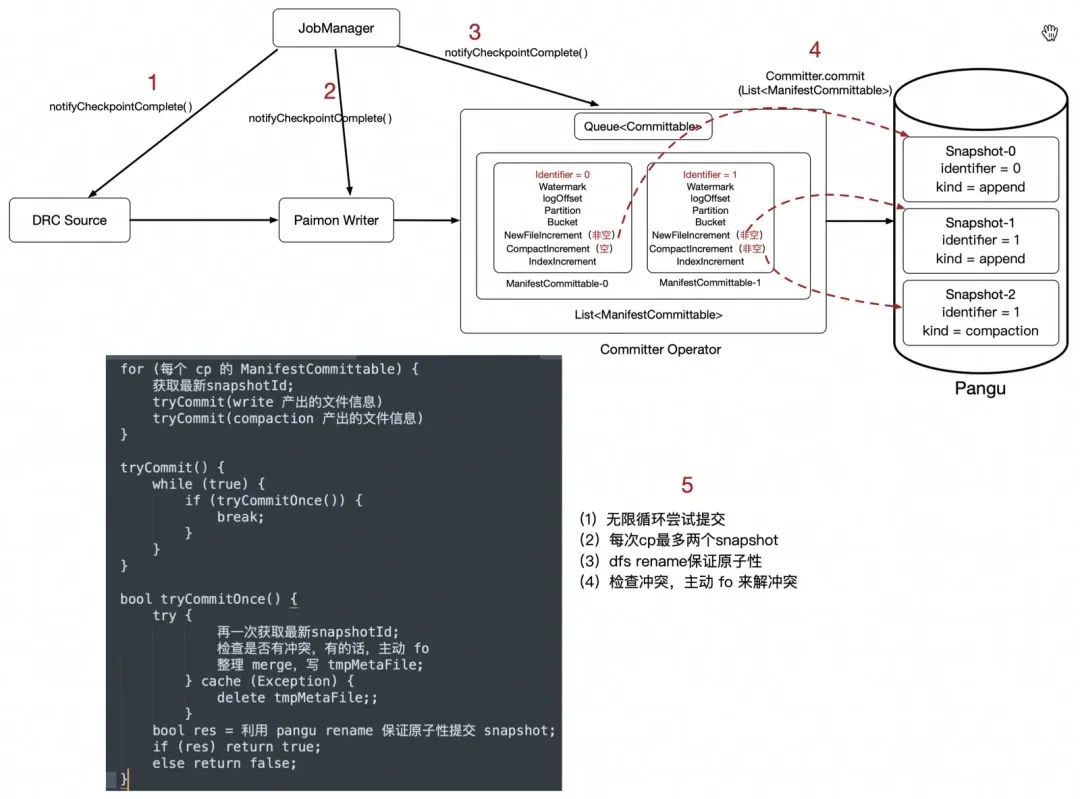
06
容错
第一阶段出错
假设第一阶段出错就直接回到上一个 Checkpoint。
第二阶段出错
IO,网络等原因导致作业 Failover
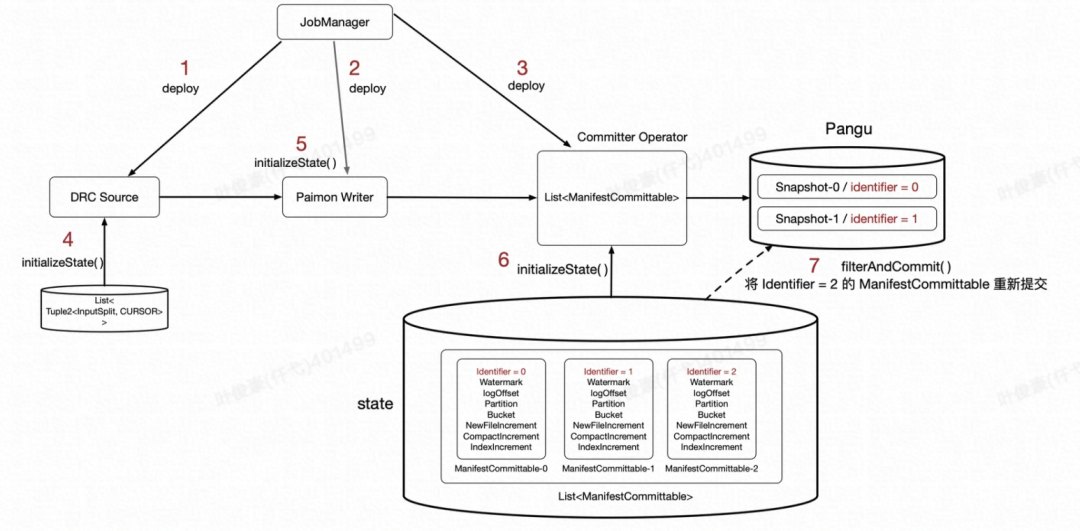
解法就是作业重启后继续尝试提交,过滤掉已经提交过的 Snapshot。
1-3、作业 Failover 的过程是先 Cancel 掉这个作业,然后再重新调度各 Task,所以会先 Deploy 各个 Task。
4、Source 节点将状态从 Pangu 读出来执行 Recover 操作。
5、Paimon Writer 节点将状态从 Pangu 读出来执行 Recover 操作。
6、CommitterOperator 节点将状态从 Pangu 读出来执行 Recover 操作。
7、根据 State 中的数据及 DFS 上的 Snapshot 版本号,来过滤出 Failover 之前没有完成的 Commit,这里继续尝试提交。
8、完成之后,会主动触发一次 Faiover,让所有 Writer 能基于这次最新的提交继续工作。
多个作业同时 Compaction 冲突,如何解?
这里的冲突是指,多个 Job 同时写一个 LSM 树的话,两种情况可能会产生冲突。
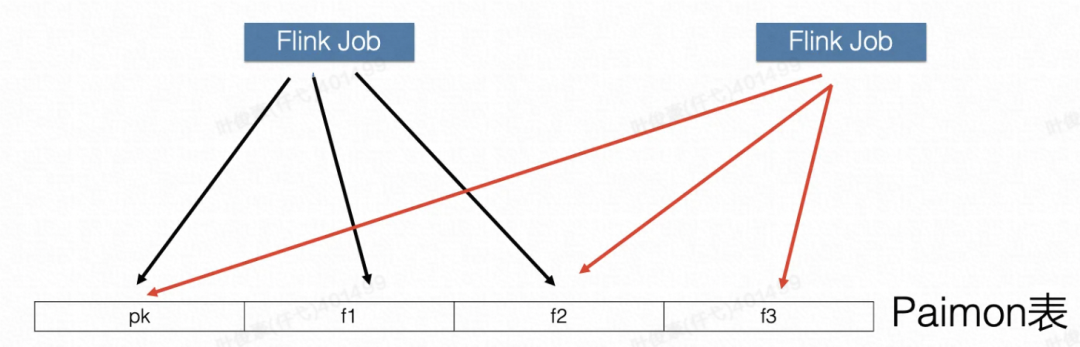
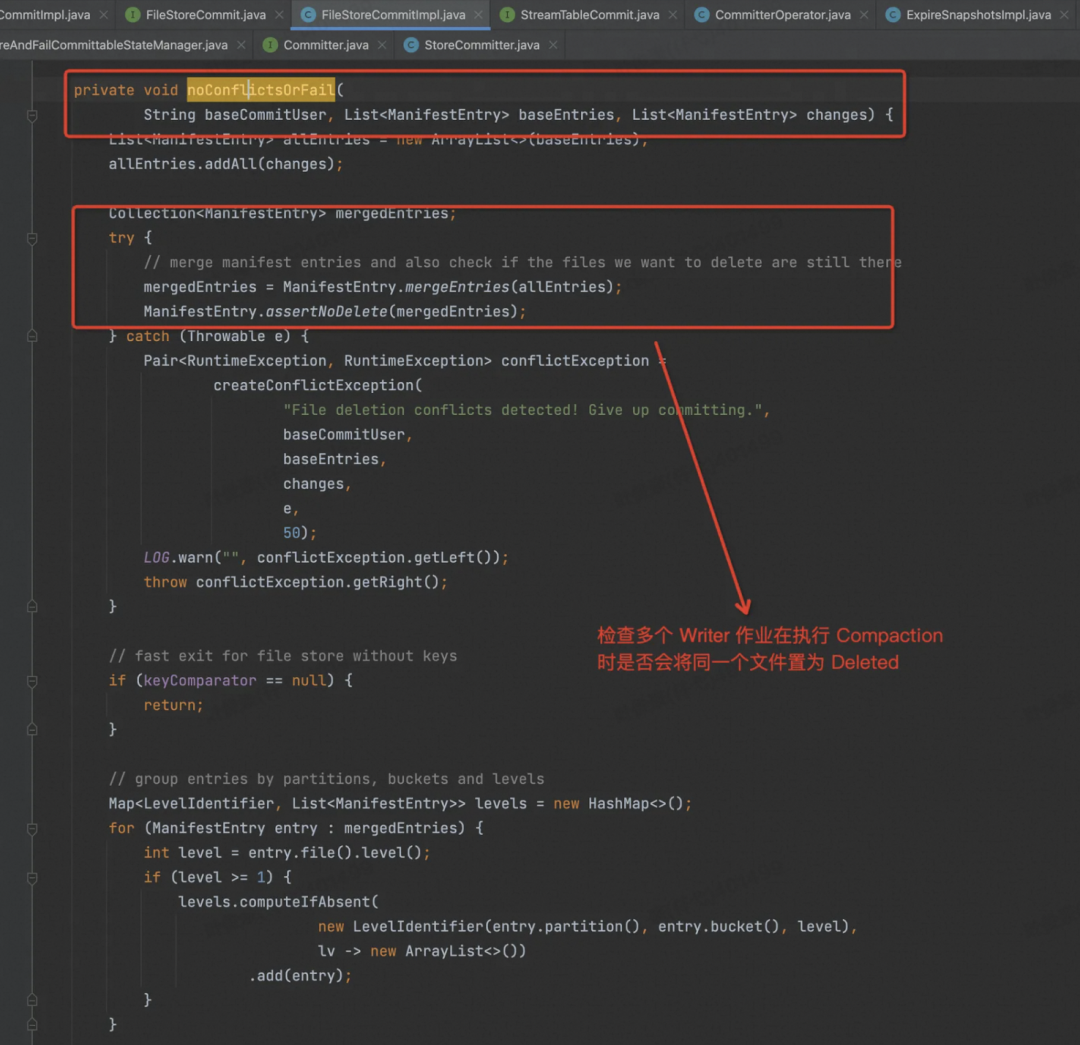
1、多个 Job 都在做 Compaction 时,有可能把同一个文件置为 Delete。
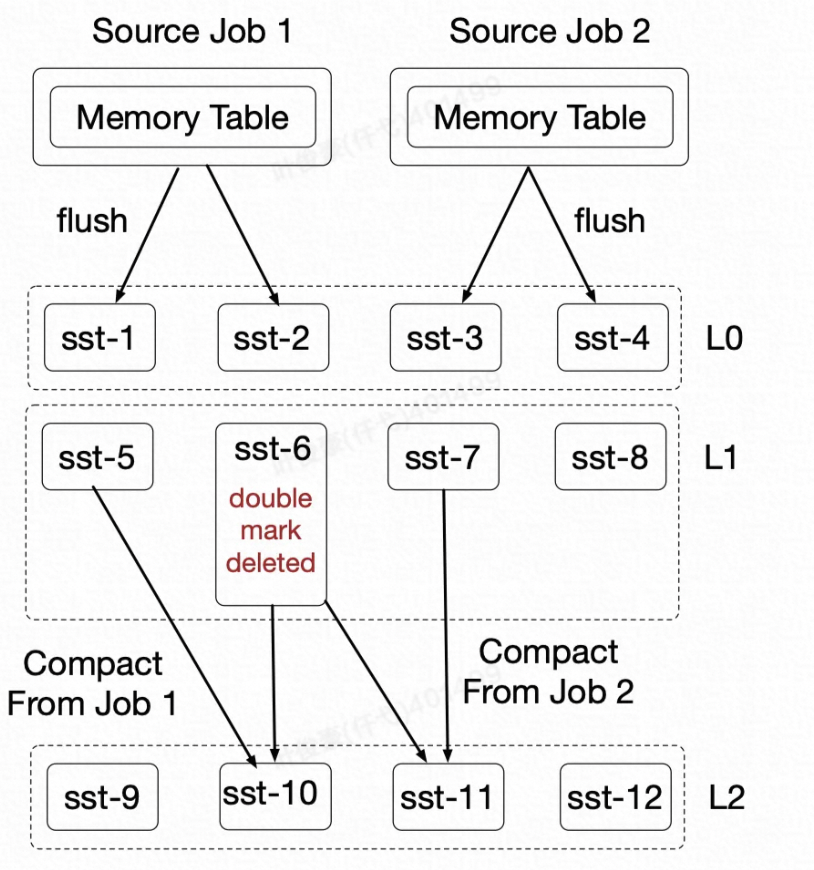
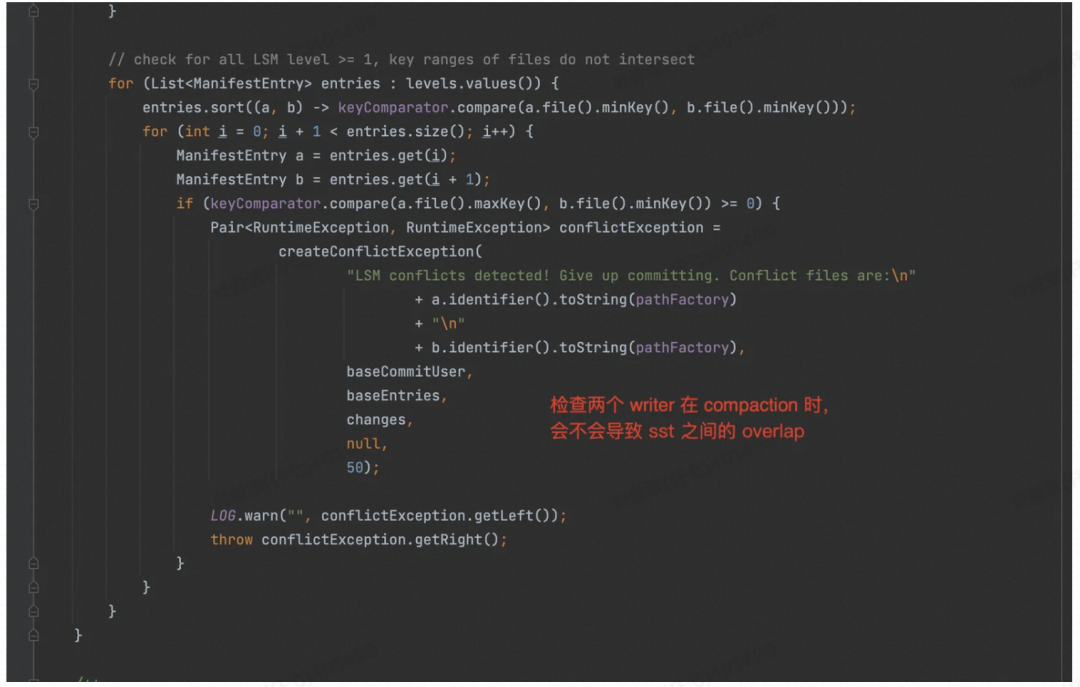
2、多个 Job 都在做 Compaction 时,有可能在 L1 层产生的多个 SST 之间有 Overlap。
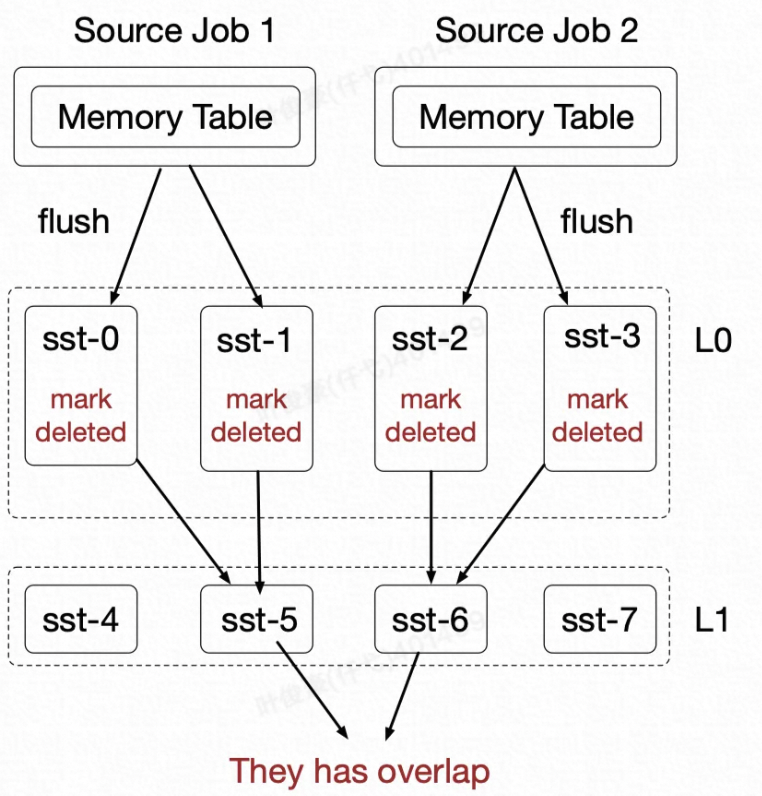
遇到以上两种冲突情况,目前 Paimon 的做法是主动触发作业的 Failover,等作业重新启动以后,丢弃这次 Compaction 的 Commit,只将 Append 的 Commit 进行 Commit。也就是我保证数据不丢且不错,只是这次 Compaction 的 Snapshot 我不要了。
由于故意触发 Failover 及 Inline Compaction 会影响作业吞吐,所以当多个 Job 写同一张 Paimon 表时,建议起一个专门做 Compaction 的作业来做 Compaction,Batch 是做 Major Compaction,Stream 是周期性的做 Minor Compaction。
07
源码详解
StreamPartitioner
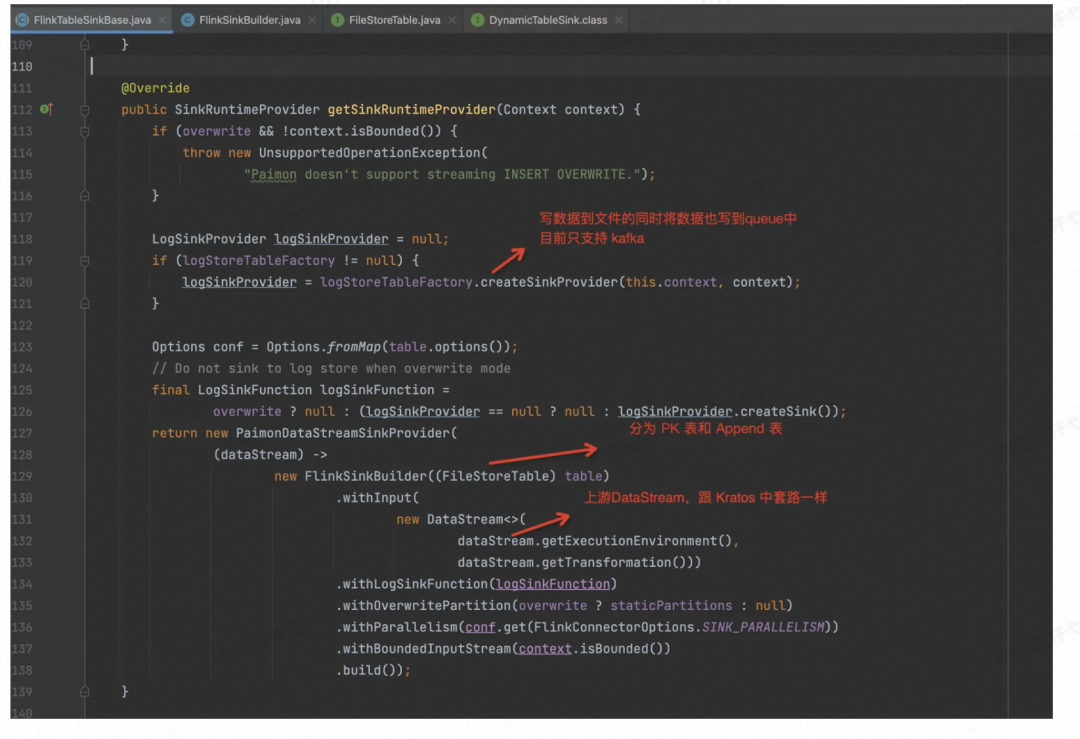
跟众多 Sink Connector 一样,核心入口位于:
org.apache.paimon.flink.sink.FlinkTableSinkBase#getSinkRuntimeProvider,实现的 Interface 是 Flink 框架中的 DynamicTableSink。
走读固定 Bucket 数的 PaimonTable 的写入逻辑,自定义了数据 Partition 方式。
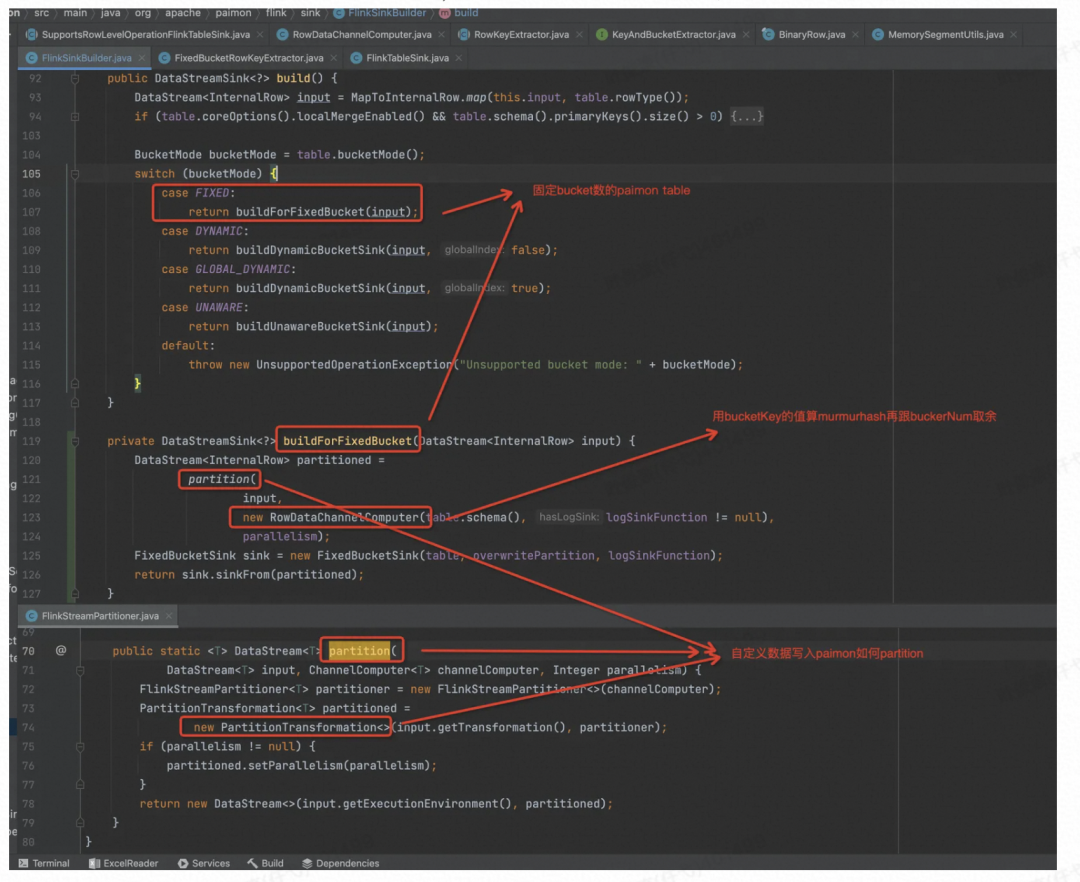
对 BucketKey 算 MurmurHash,再对 BucketNum 取余来决定数据发往下游哪个并发中。
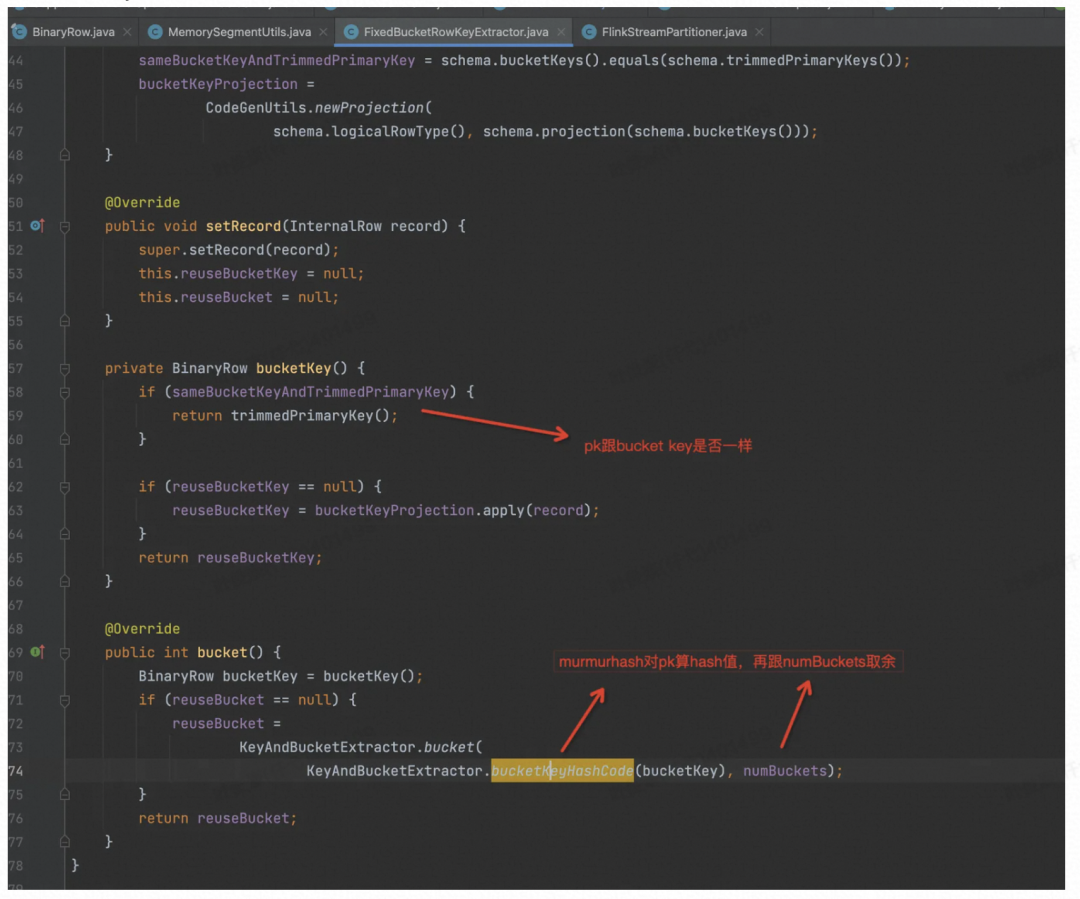
最终生成DataStreamSink的地方
org.apache.paimon.flink.sink.FlinkSink#sinkFrom(org.apache.flink.streaming.api.datastream.DataStream<T>)
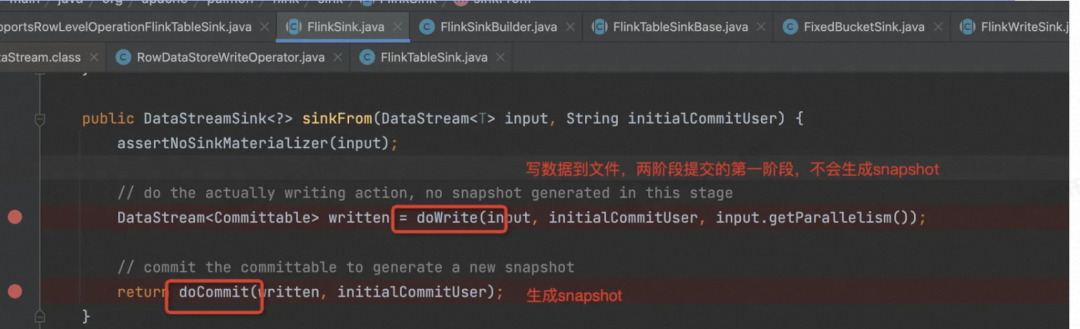
生成 Write + Commit 算子
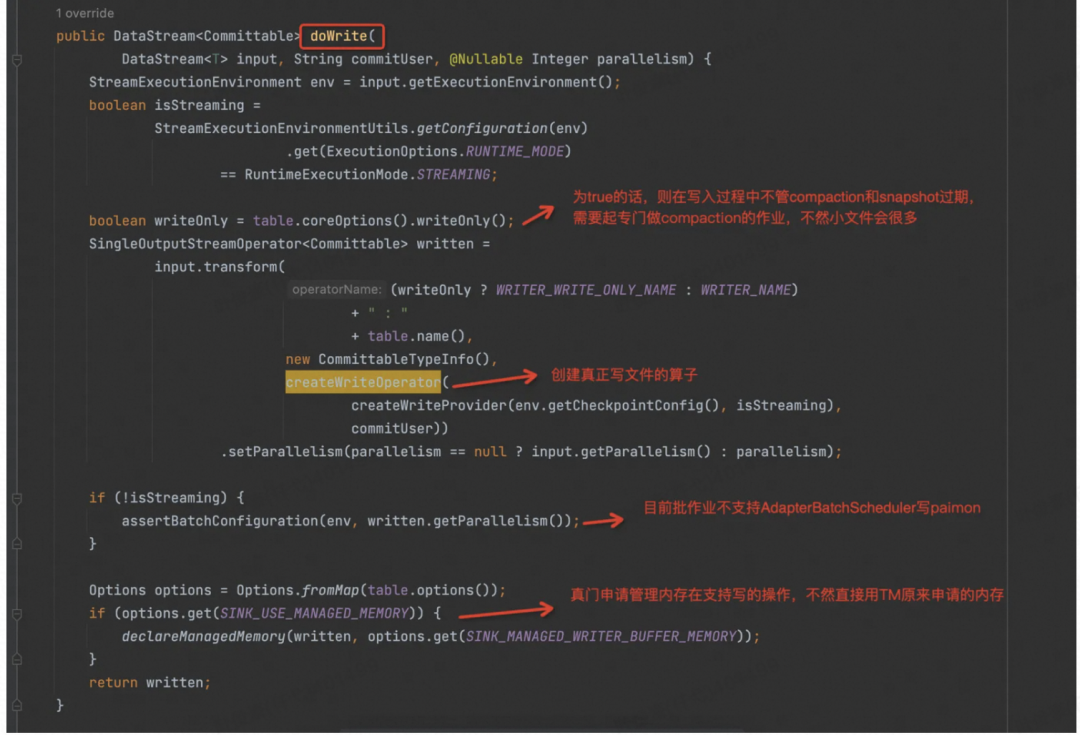
doWrite 方法里面各种流批检查,参数检查,强制关掉 Flink 的 AdapterBatchScheduler,再调用 createWriteOperator 方法。
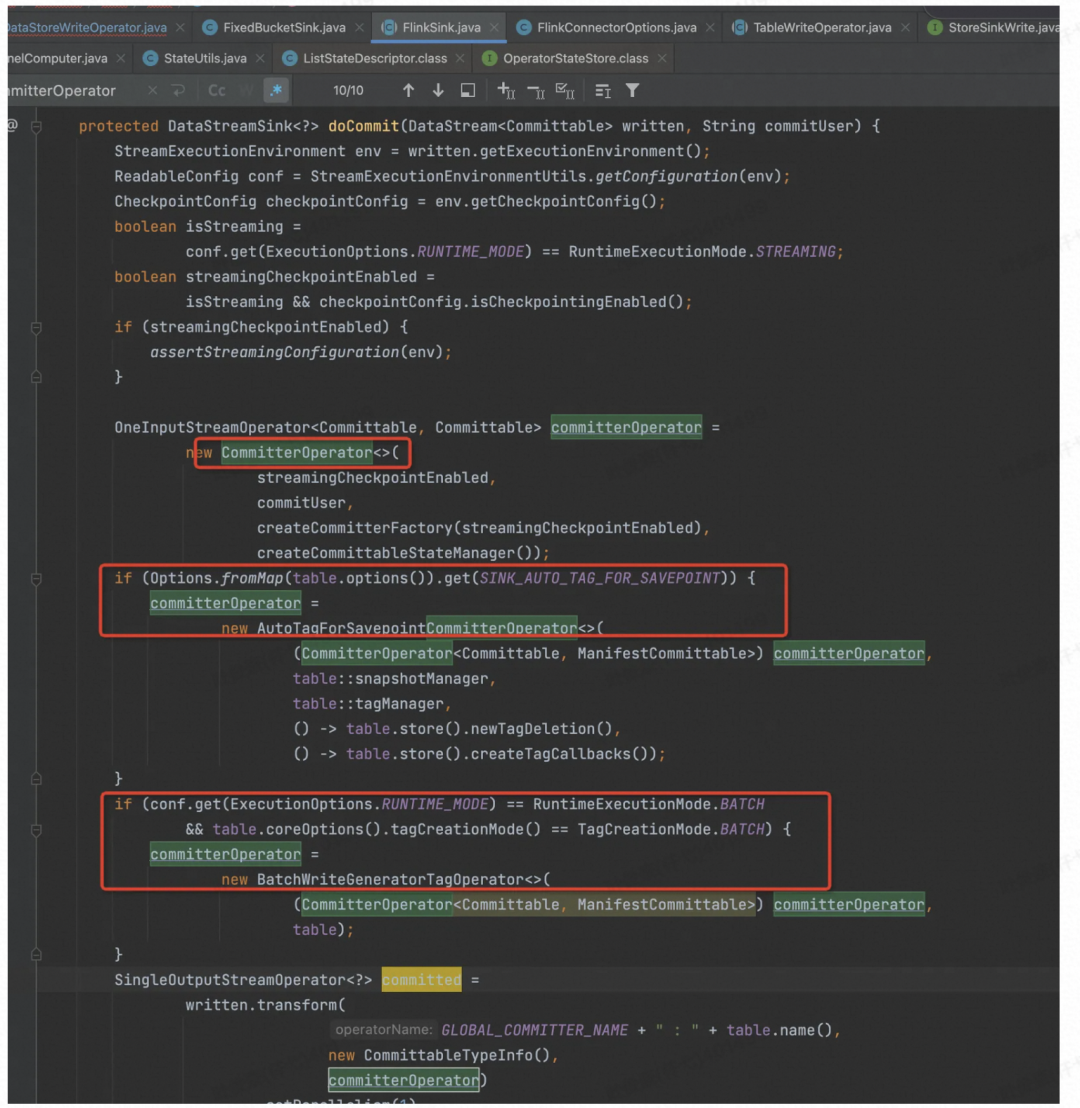
committerOperator,是一个独立的算子,在作业中是一个独立的节点,1个并发,做两阶段提交的,每次做 Checkpoint,这个算子都会接收到 Bucket 数的 Record。本来这个功能应该放到 Flink JobManager 去做的,但是目前 JobManager 那套 Corrdinator 不太成熟,坑比较多,所以我觉得目前这个实现方式是一个折中方案。
Write 内存
先看 doWrite 方法。
跟下去,发现 Flink 写入 Paimon 的核心 Operator 是 org.apache.paimon.flink.sink.RowDataStoreWriteOperator,它是预提交算子,会将数据 Flush 到磁盘,但不会执行Commit 操作,也就是不会生成 Snapshot。
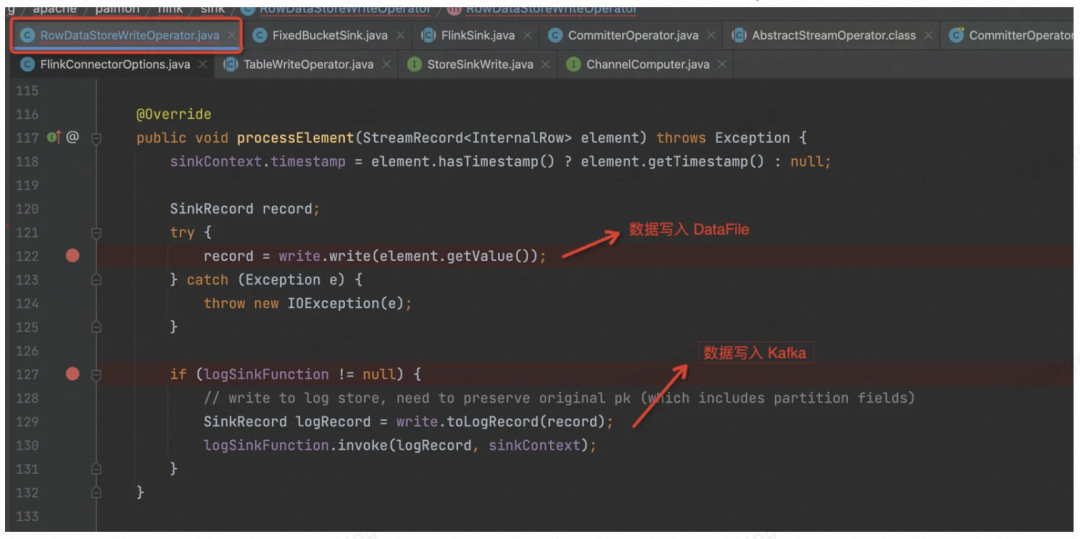
主键表会调用到 MergeTreeWriter
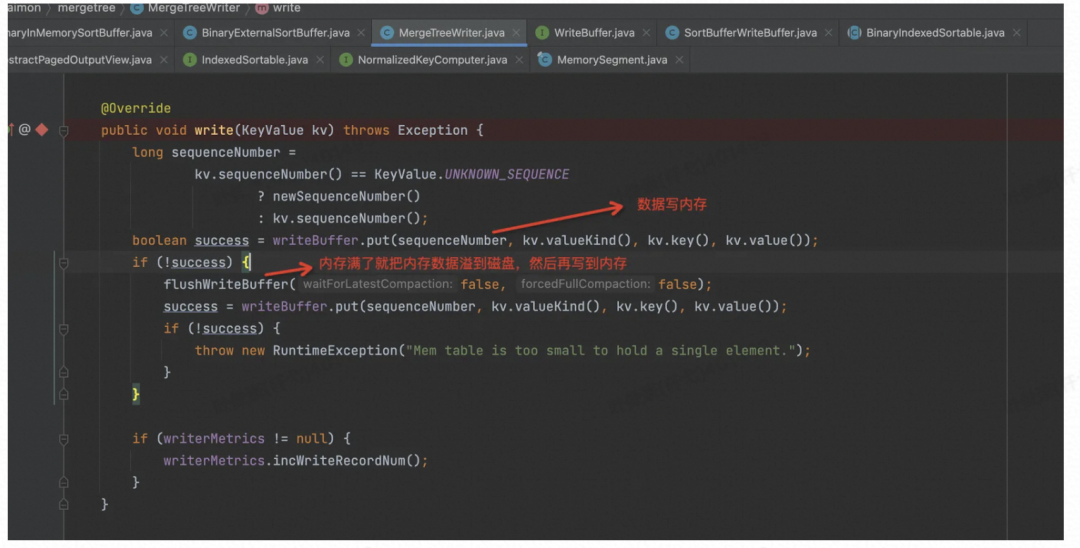
写入内存的话,是通过BinaryExternalSortBuffer 和 BinaryInMemorySortBuffer 搭配完成的。
Sink 到文件系统且 Streaming 的话,就只会用到 BinaryInMemorySortBuffer。
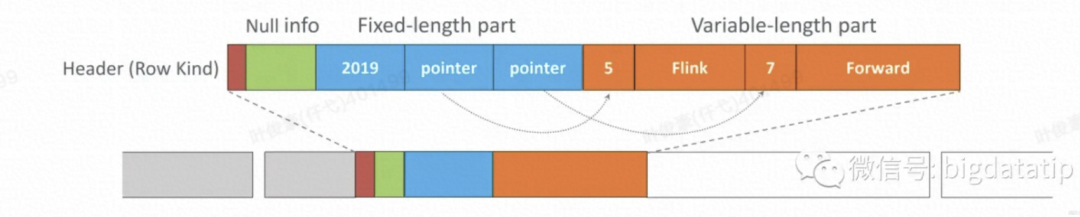
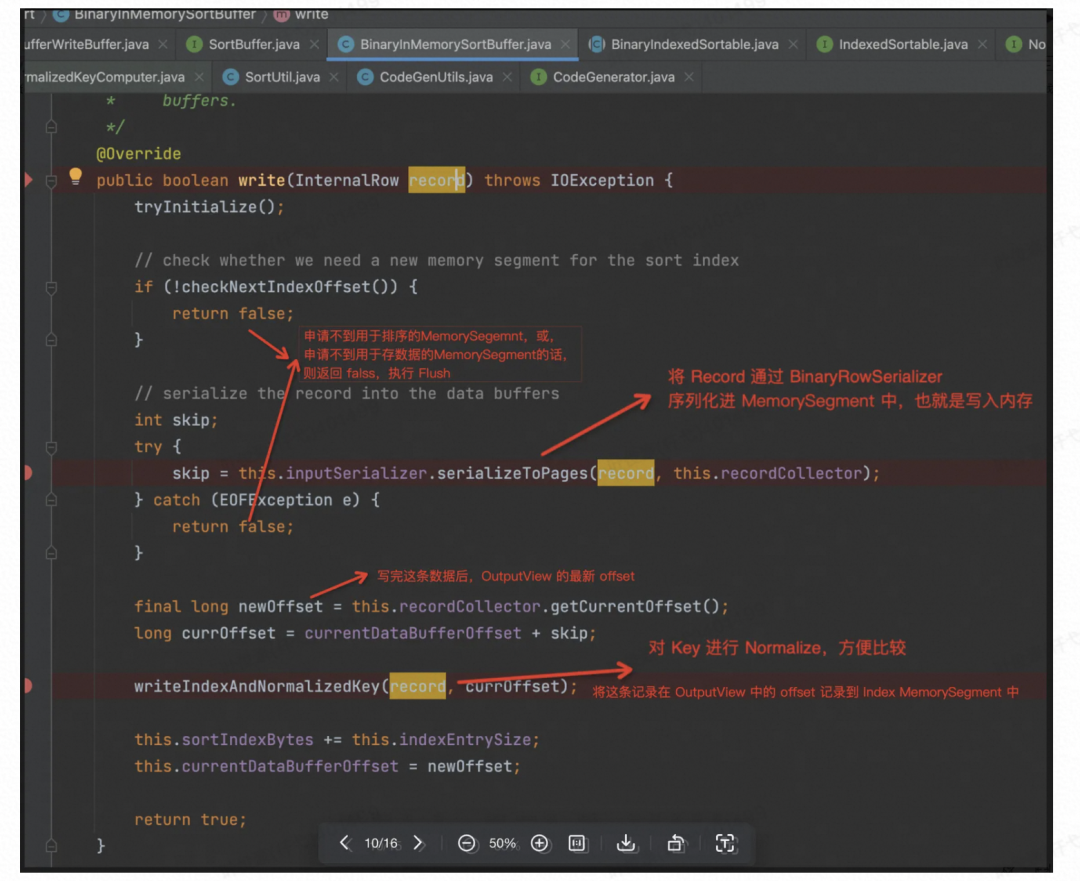
先看 Record 是如何序列化进入 Data Buffer 的,也就是 BinaryRowSerializer.serializeToPages() 的实现
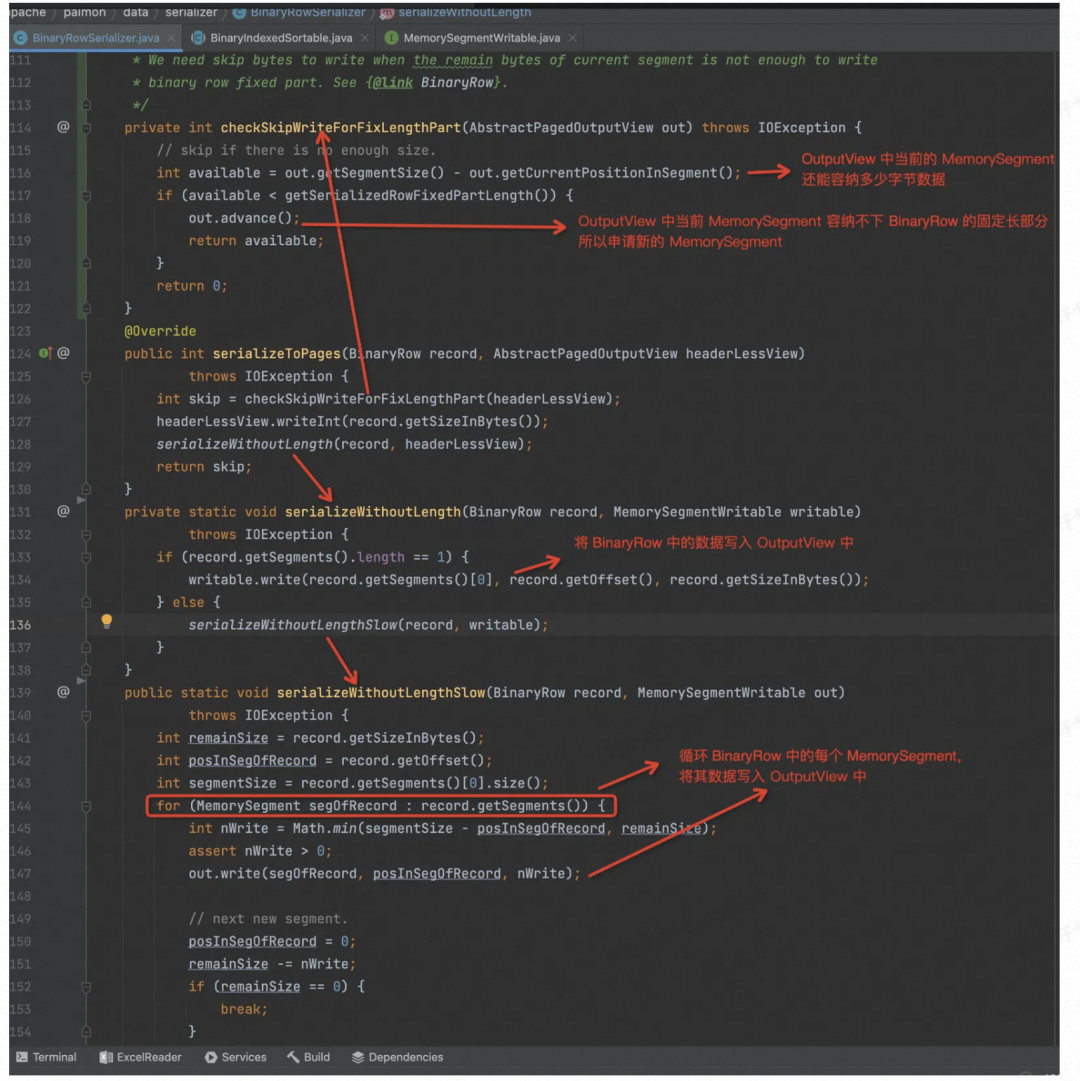
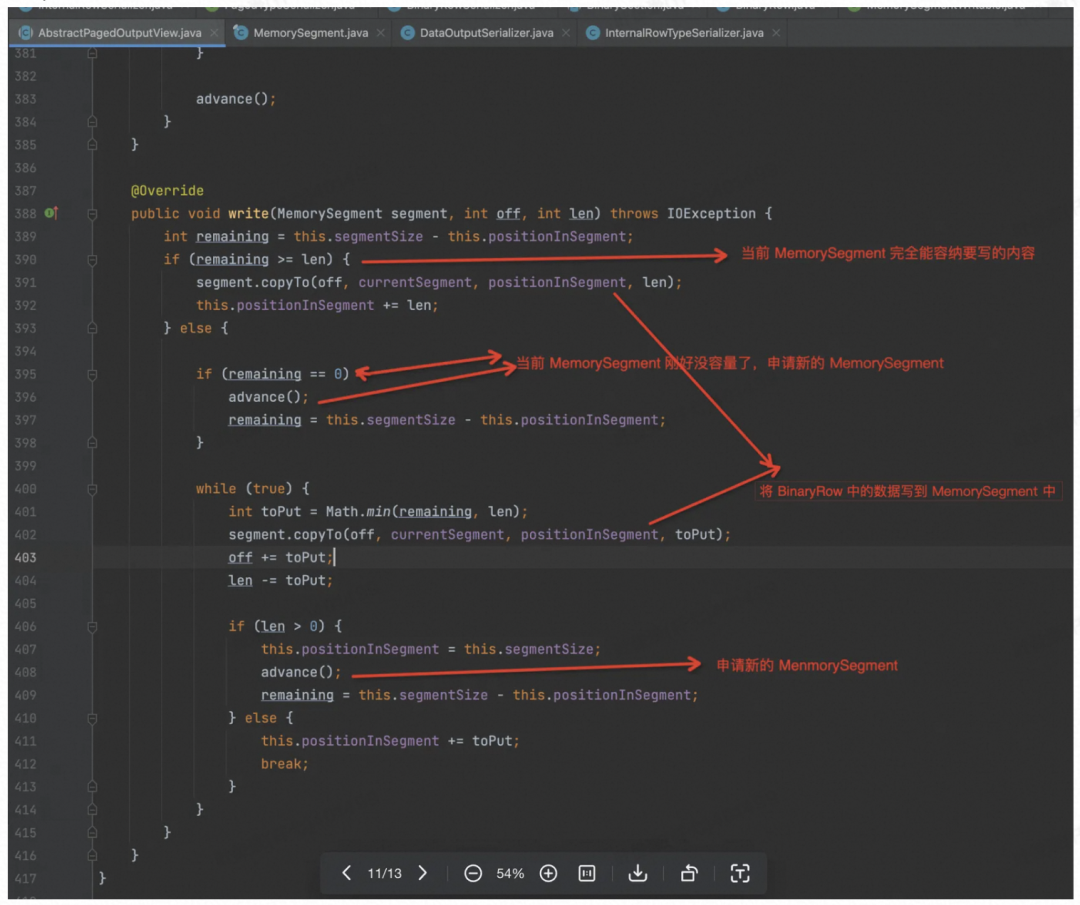
OutputView 的 Write 实现逻辑如下:
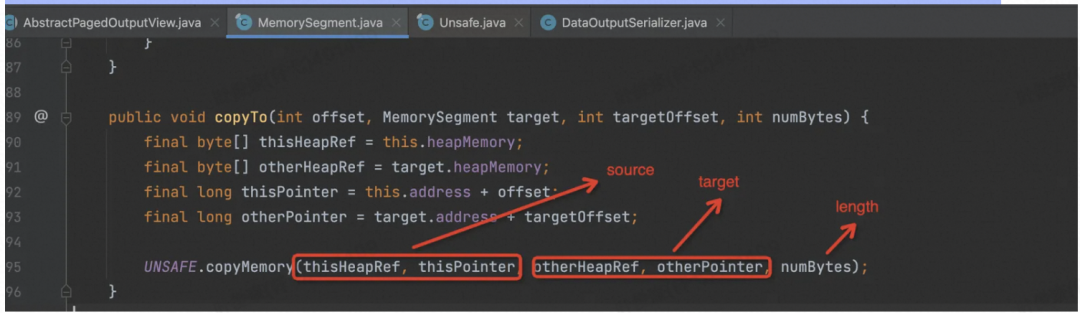
然后是 MemorySegment 的 CopyTo 的实现,最后调用的是 sun.misc.Unsafe 中的 native 函数,C++实现。
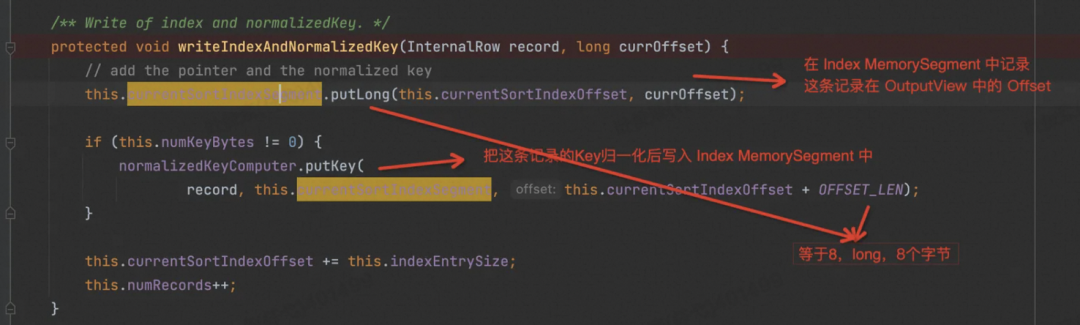
再看 writeIndexAndNormalizedKey( ) 的实现,如下。
读内存数据写到 Disk 或 Pangu(DFS)
如果是对象存储或者批作业,内存不满的话,则会用外部排序。
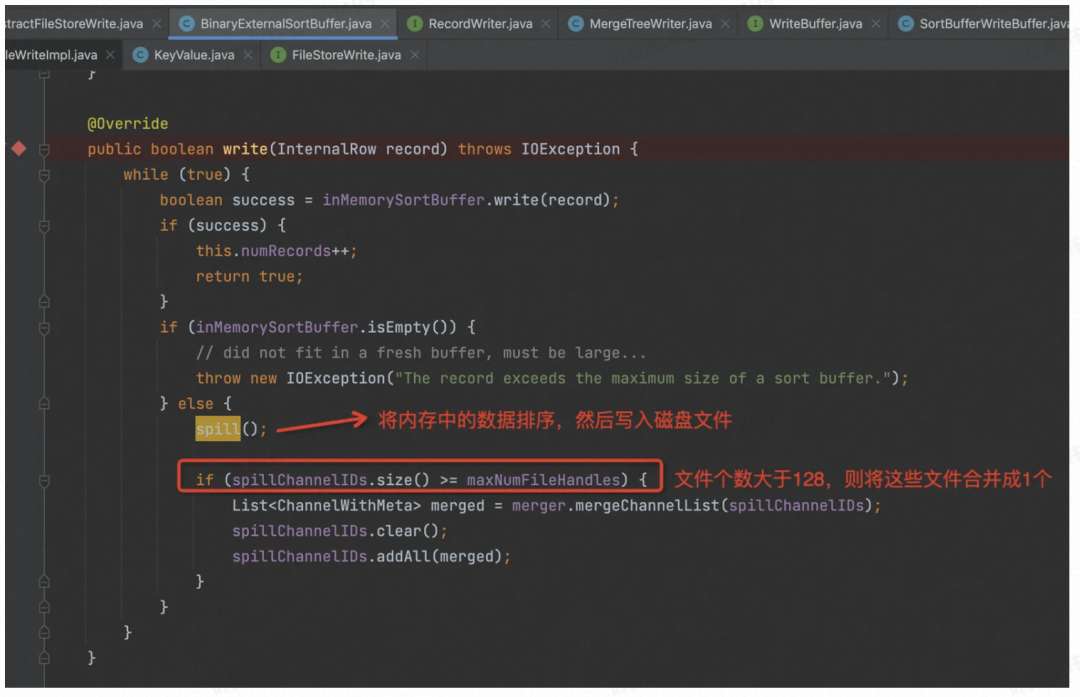
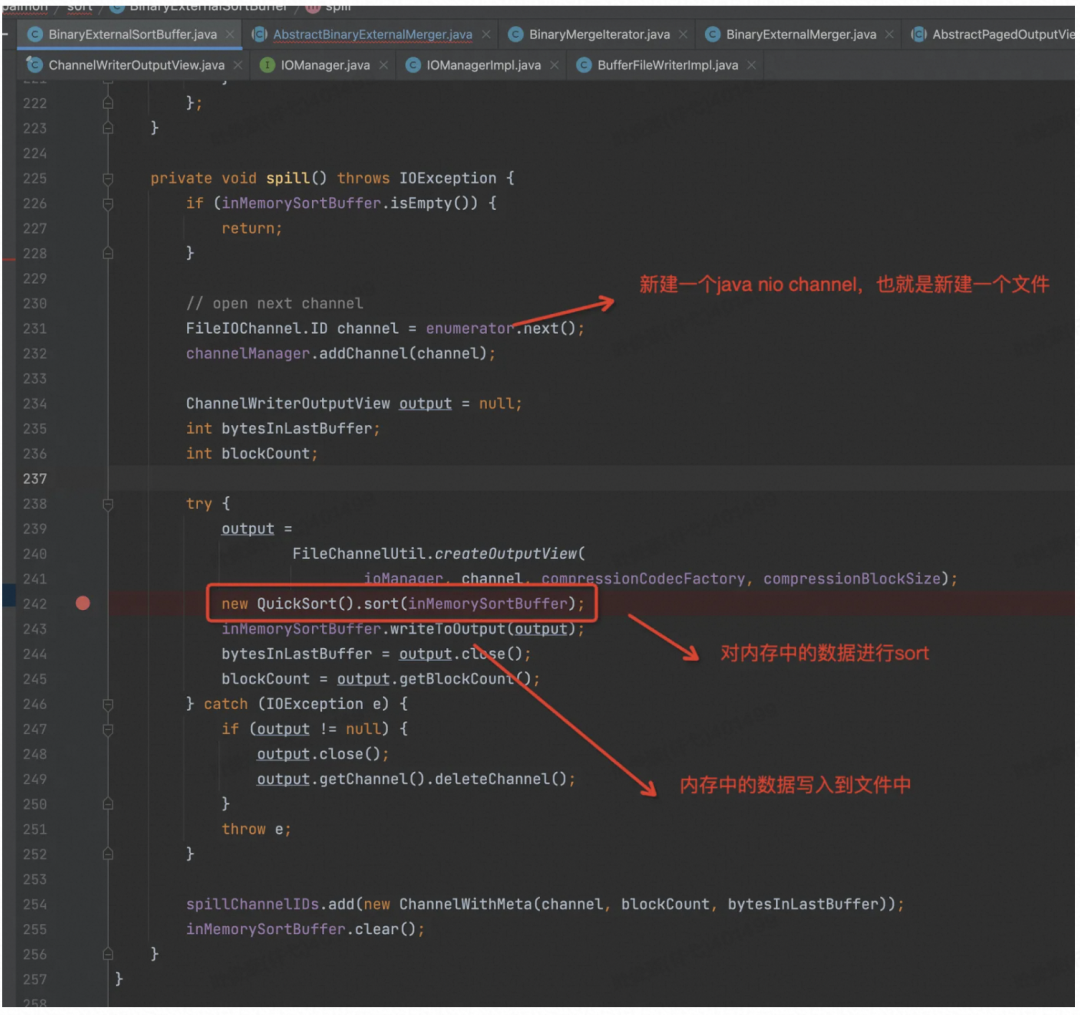
Spill 的话要先把内存中的数据排序,走 Merge 逻辑,然后顺序写入到文件中。
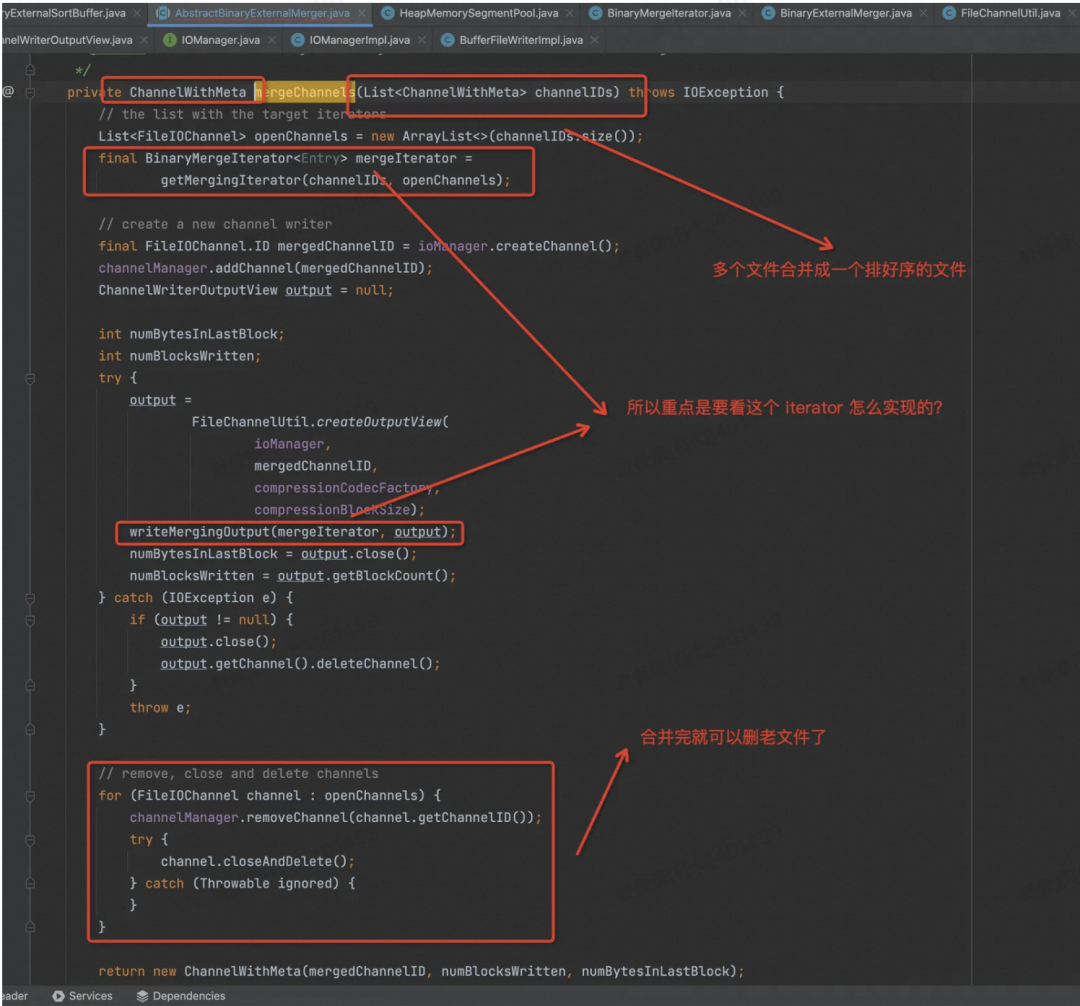
当文件数大于配置的时候,会对多个有序文件进行合并成 1 个或多个,具体几个看配置,目前的配置是 128 个文件合并成 1 个。
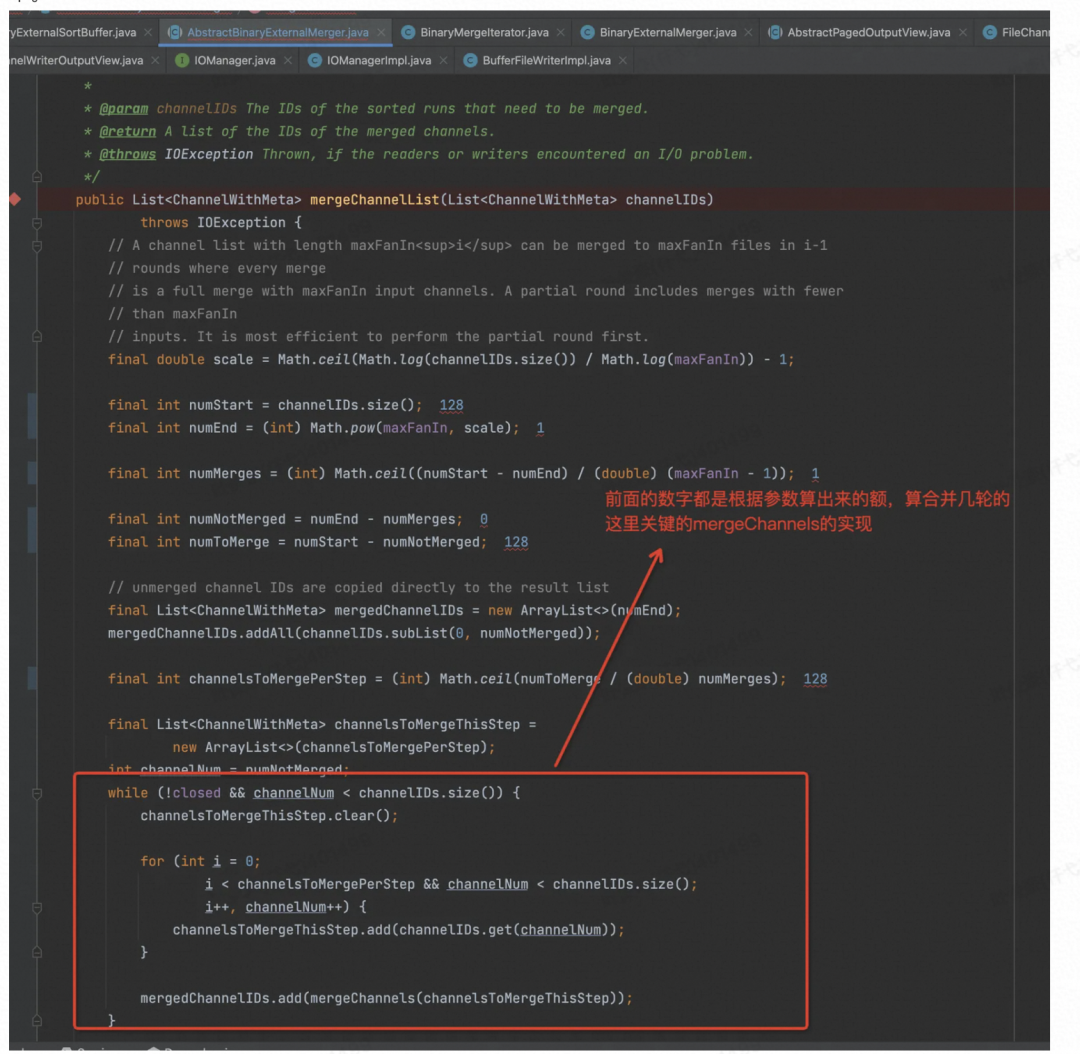
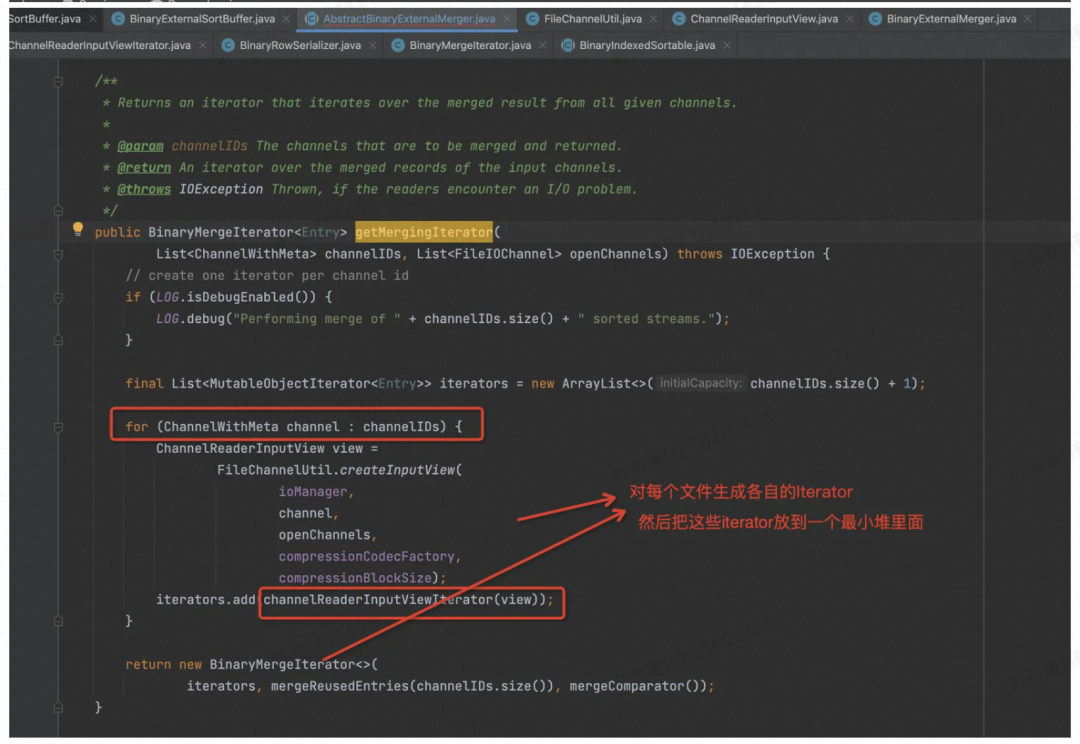
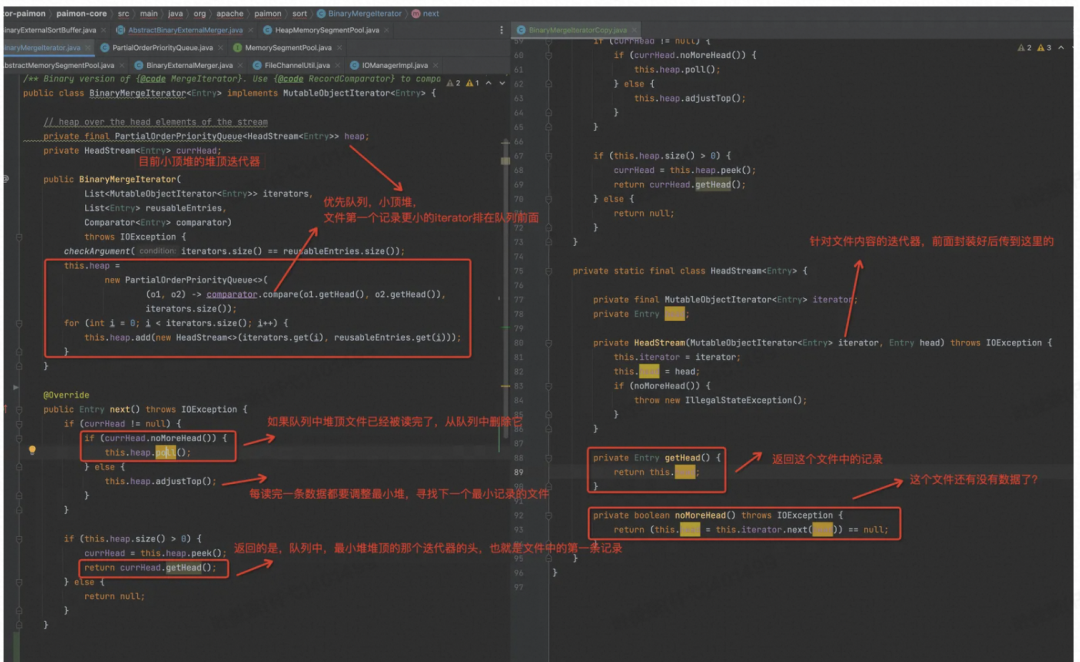
所以重点要看 mergeChannels 函数中的实现了,这里面最重要的就是要看迭代器怎么实现的了,SortMergeJoin 的具体实现都在这个 BinaryMergeIterator 类中了。
具体到 BinaryMergeIterator 里面,其实就是小顶堆里面各元素装的是文件的迭代器,实现了比较函数,然后不停 Next,就可以按顺序获取各个文件中目前最小的记录了,返回回去合并到同一个文件中。
Write Pangu(DFS)
再看真正生成 ORC 文件, Flush 的地方,最后调用的是 org.apache.orc.Writer,直接写成 ORC 格式的文件,生成的所有文件的信息缓存在内存中,供算子在进行 Checkpoint 的时候将所有的 Flush下发到下游算子(提交算子),下发是在 prepareSnapshotPreBarrier 方法中进行的,所以会在下游算子进行 Checkpoint 之前接收所有的 Flush 信息。
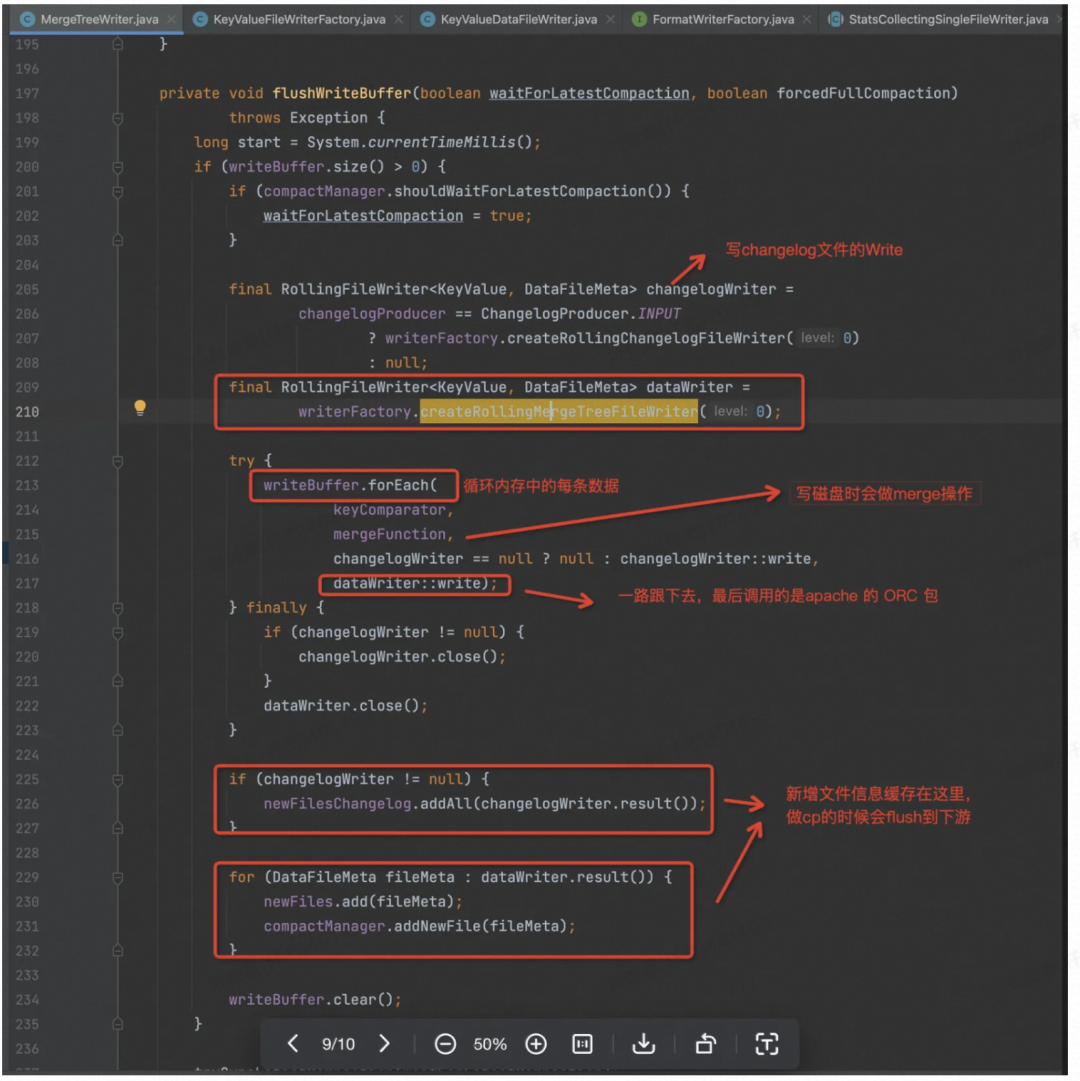
先看 213 行的 writeBuffer.forEach( ),这里如果 Changelog 是 input 的话,每条记录会原封不动写进 Changelog 中。如果是写 DataFile 的话则会对相同的 PK 记录调用 Merge。
那我们看下是如何从内存中按序把记录 Scan 出来的。
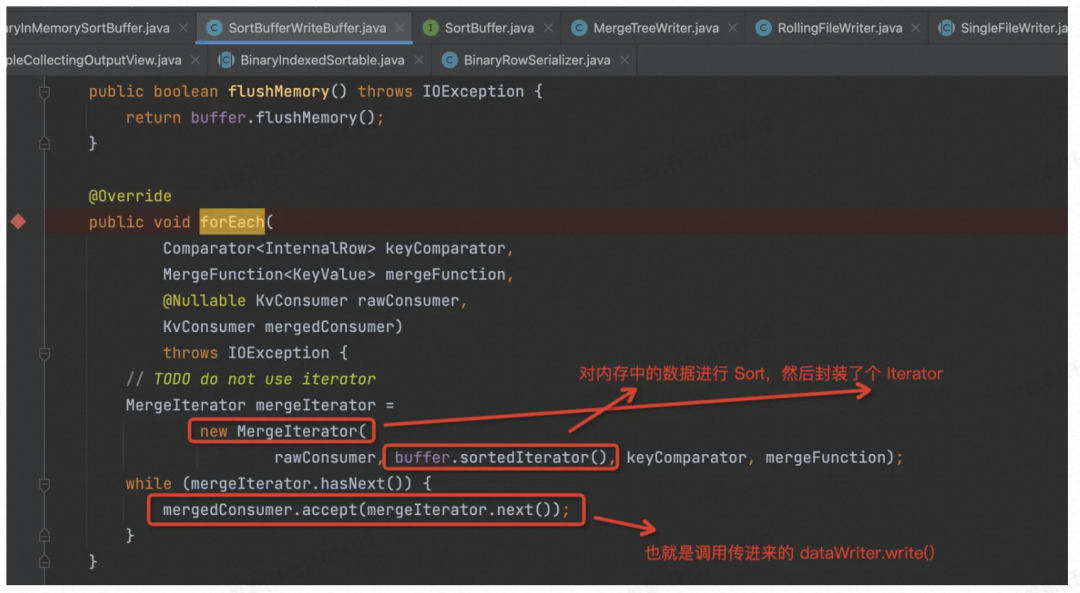
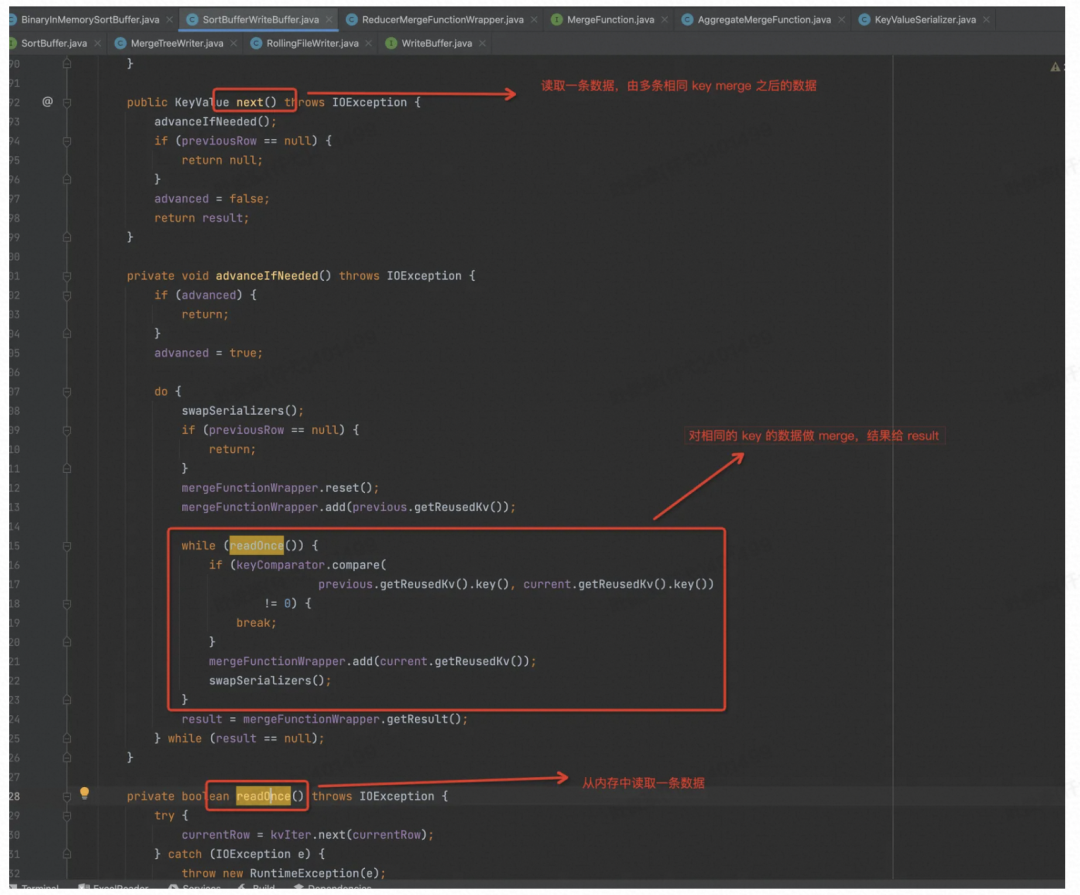
从这里的实现可以看到,readOnce( ) 中读出来的数据要保证是按序排序好的,这些代码才有意义。继续跟进 kvIter
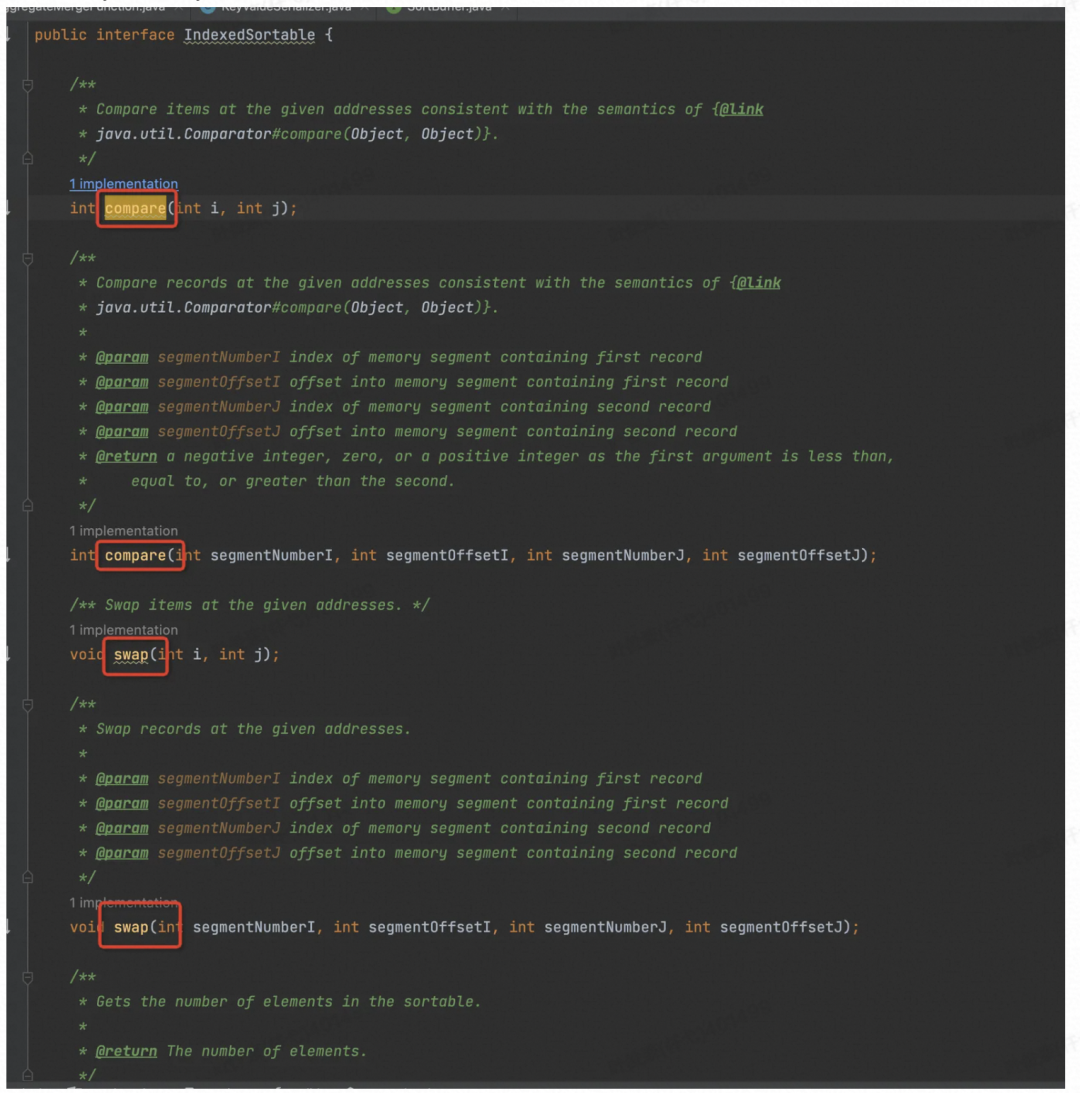
看到 BinaryInMemorySortBuffer 实现了可排序接口,所以可以用快排排序。
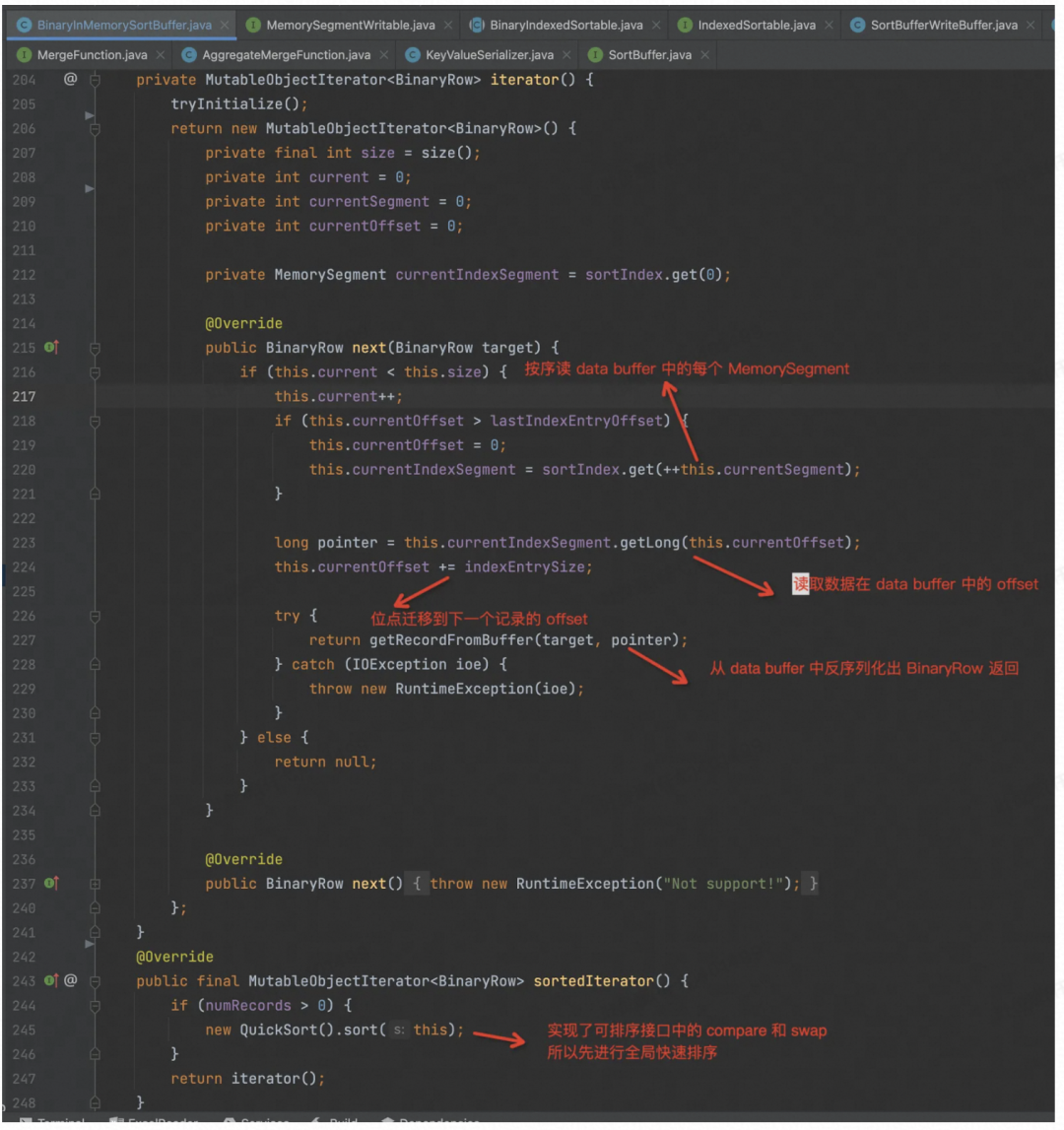
再看如何从 DataBuffer 中反序列化出 BinaryRow 的。
首先根据 index MemorySegment 中记录的 Offset,去 Data Buffer 中定位出真正的那个 MemorySegment 以及在其之上的 Offset。
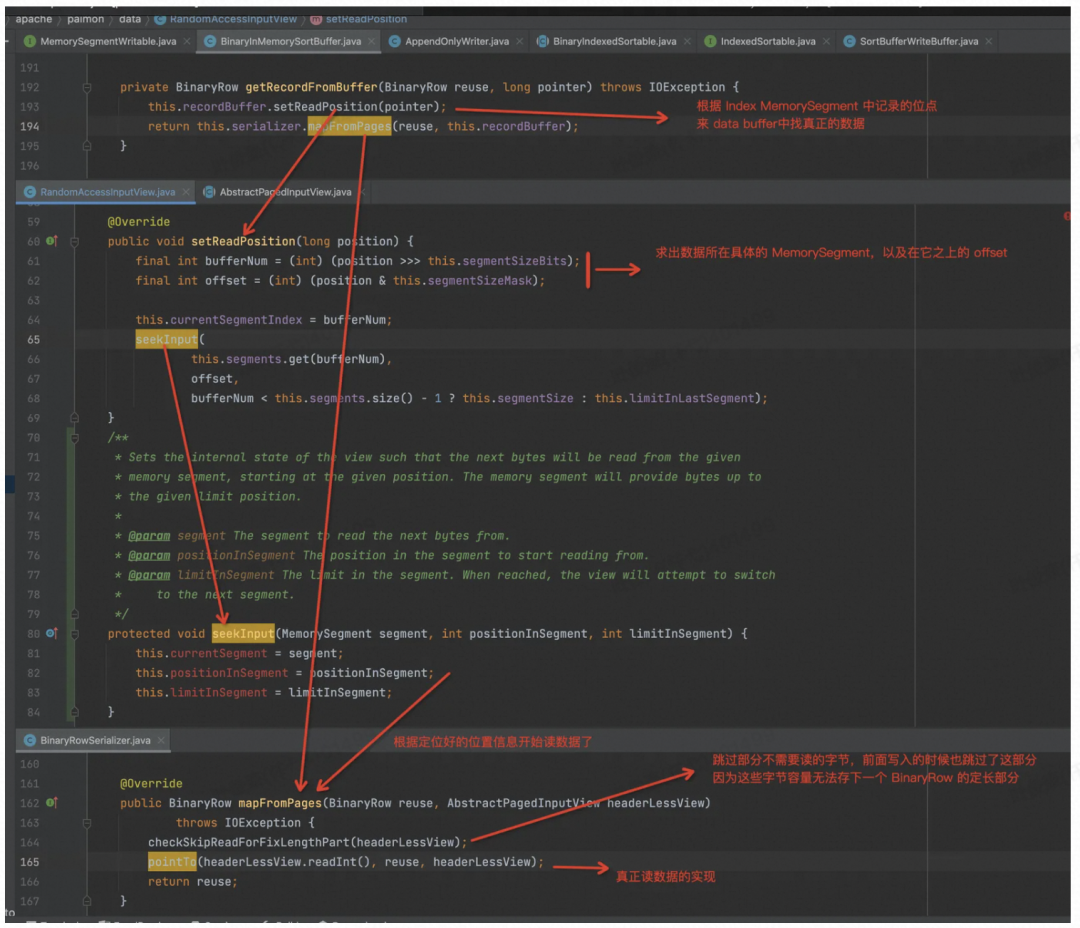
根据要读取的 length,及目标 MemorySegment,来读取数据,赋值给 BinaryRow
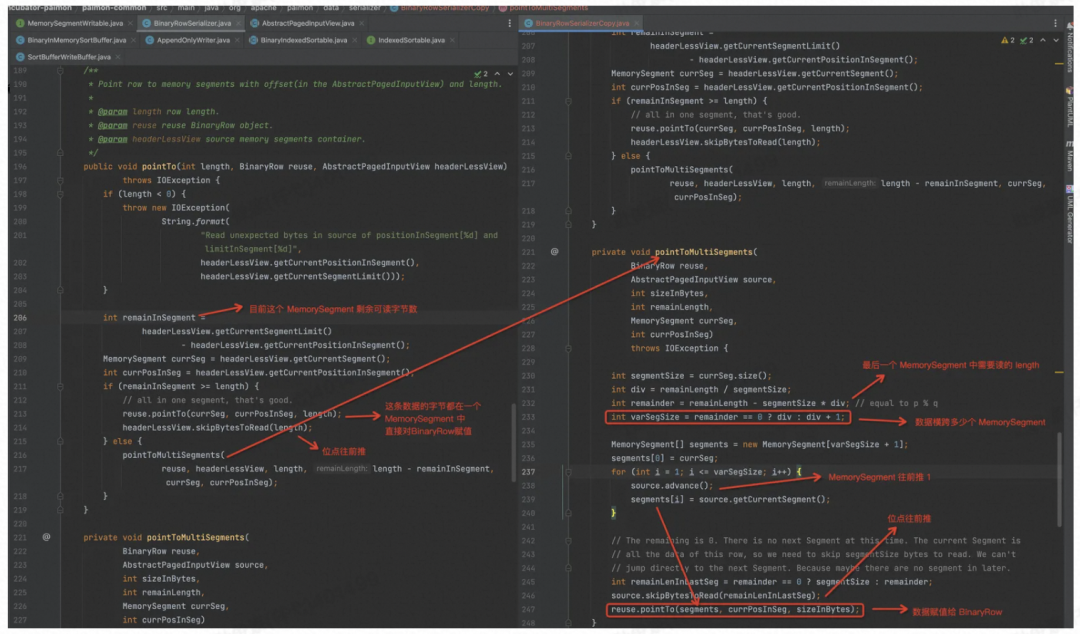
这样数据就排序好,经过 Merge,然后通过 Iterator,返回给 DataWrite 来执行 write( ) 操作,接着往下看
再看 217 行的 dataWriter:write( )
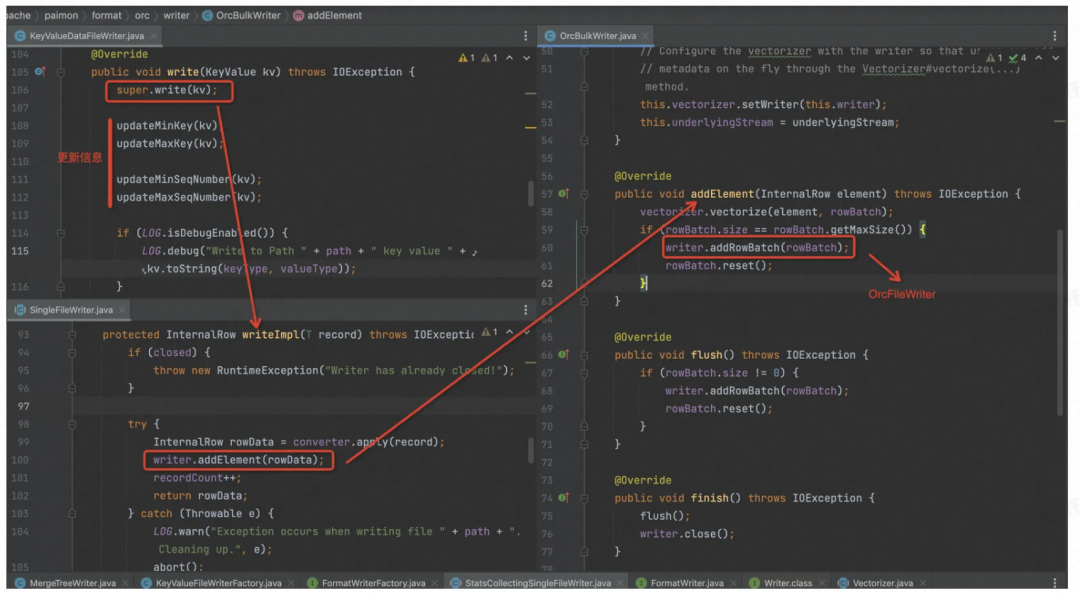
所以对于 Flush 操作,以 ORC 文件格式举例,最后调用的是 org.apache.orc.Writer,直接写成 ORC 格式的文件,生成的所有文件的信息缓存在内存中,供算子在进行 Checkpoint 的时候将所有的 Flush下发到下游算子(提交算子),下发是在 prepareSnapshotPreBarrier 方法中进行的,所以会在下游算子进行 Checkpoint 之前接收所有的 Flush 信息。
Write Kafka
写文件的过程分析完了,我们再看一下写 Kafka 的过程,Paimon 跟 Flink 一起包装了 Kafka 的 Client,在 Paimon 这里只是简单的调用和声明回调的逻辑。
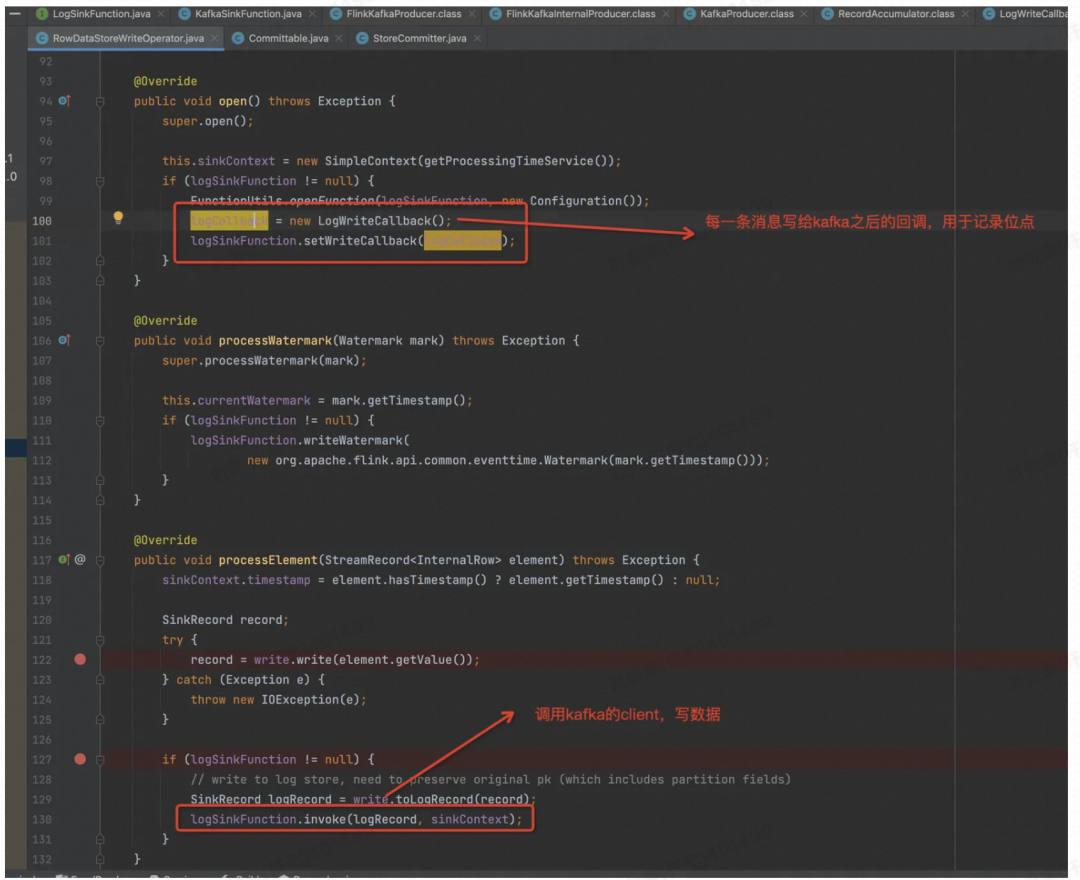
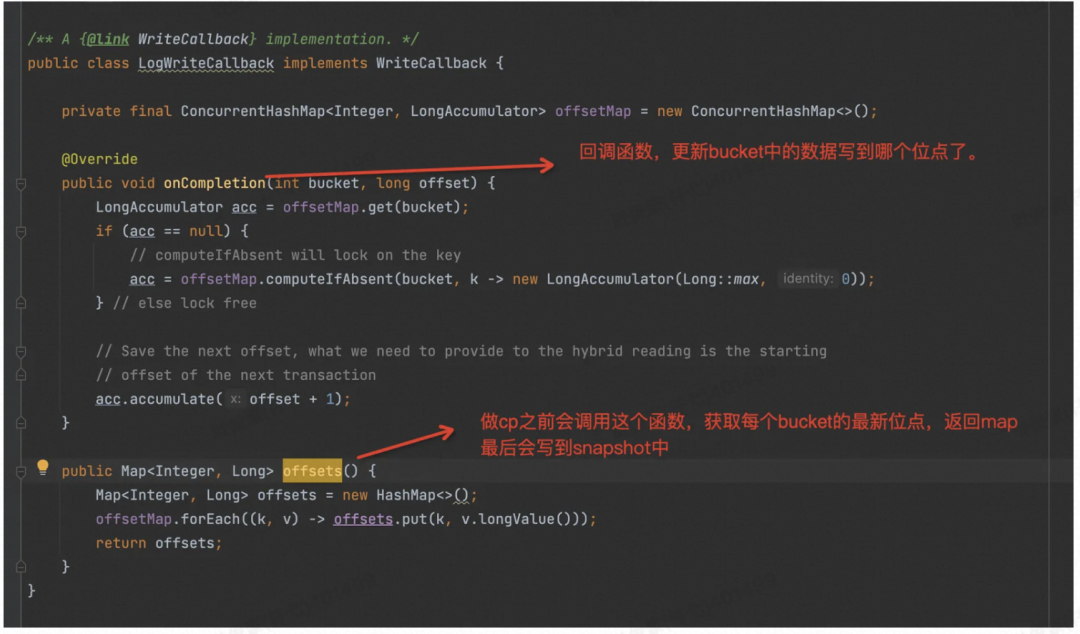
Commit
最后再看doCommit 方法,它是一个并发为 1 的 Task。
首先在 Write 节点(PrepareCommitOperator的子类),做 Checkpoint 之前,Flink 框架会调用 prepareSnapshotPreBarrier( ) 函数,发给下游(CommitOperator节点)
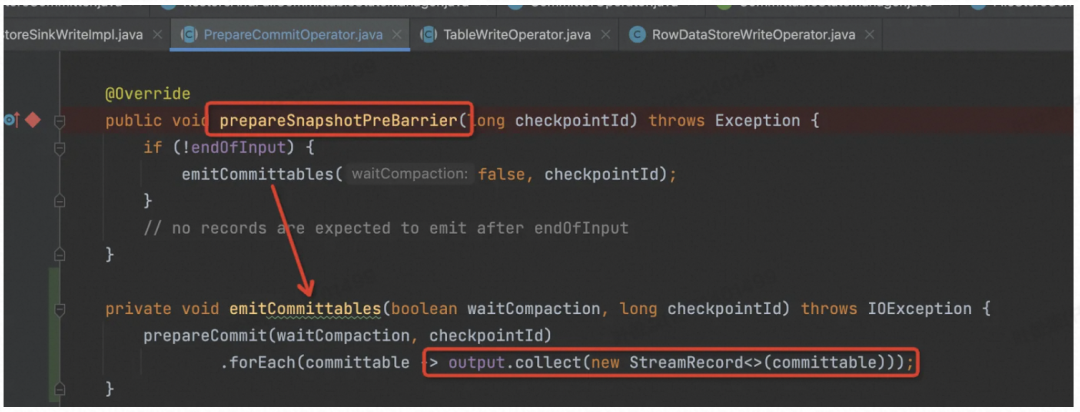
调用 write 的 prepareCommit 函数,获取所有 Write 的 CommitMessage。
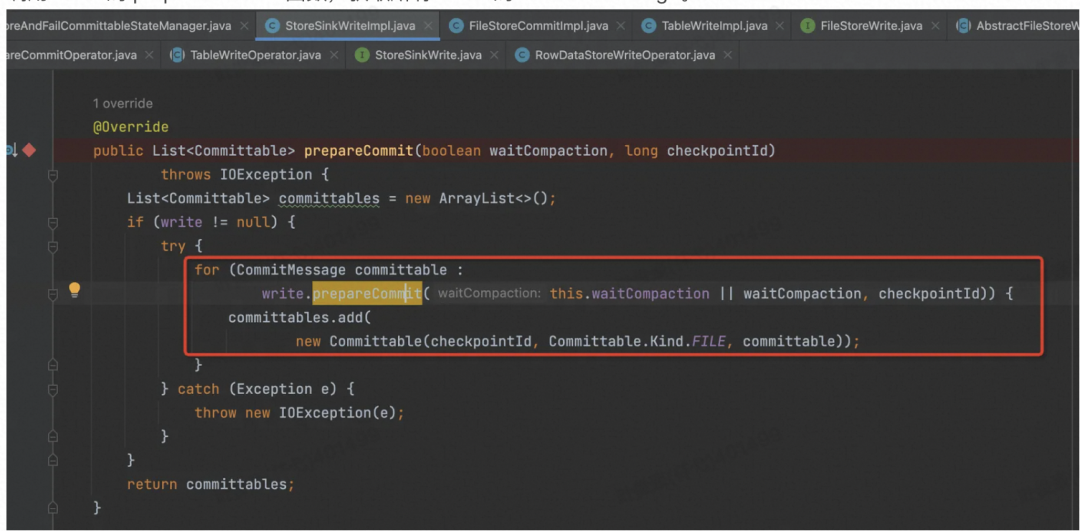
这里主要目的是要把 CommitMessage 发给下游。
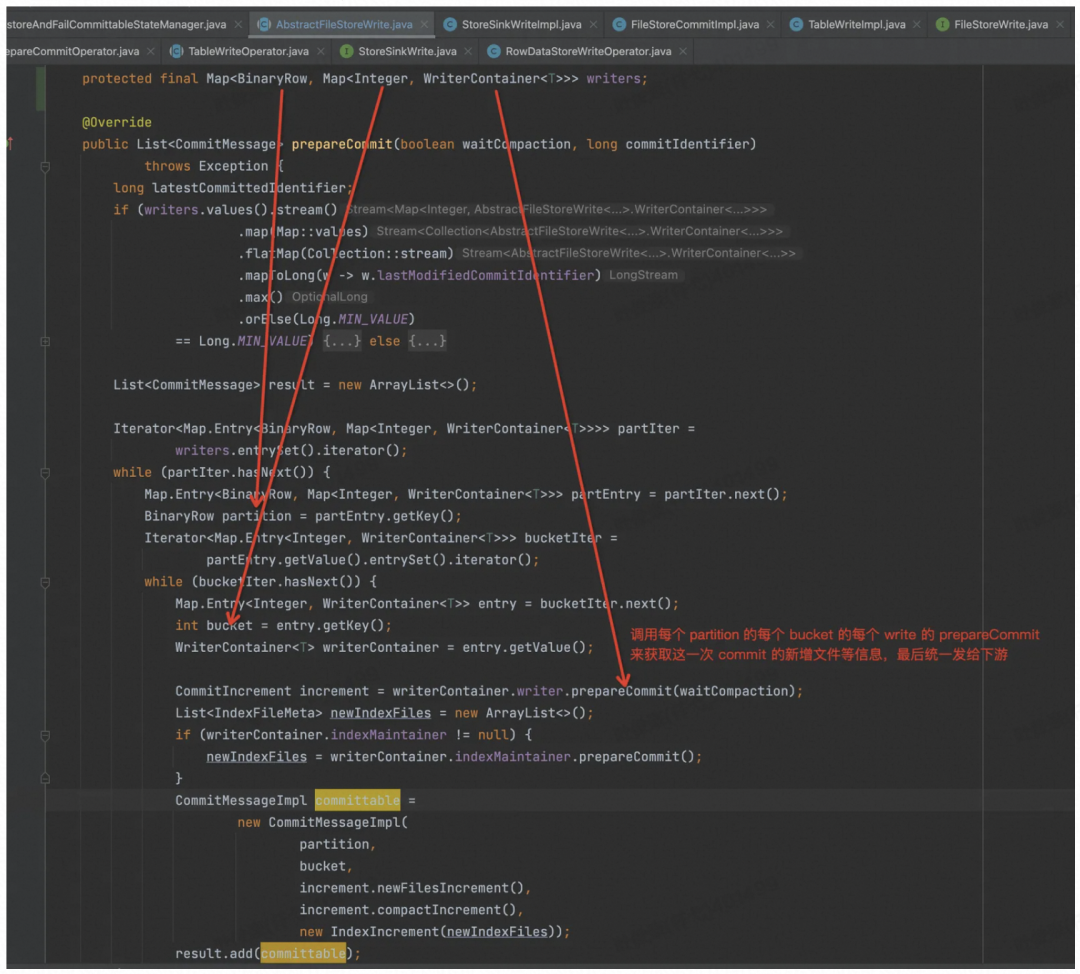
针对每个 Bucket,其实都是一个 LSM Tree,都是通过 MergeTreeWrite 来实现的。
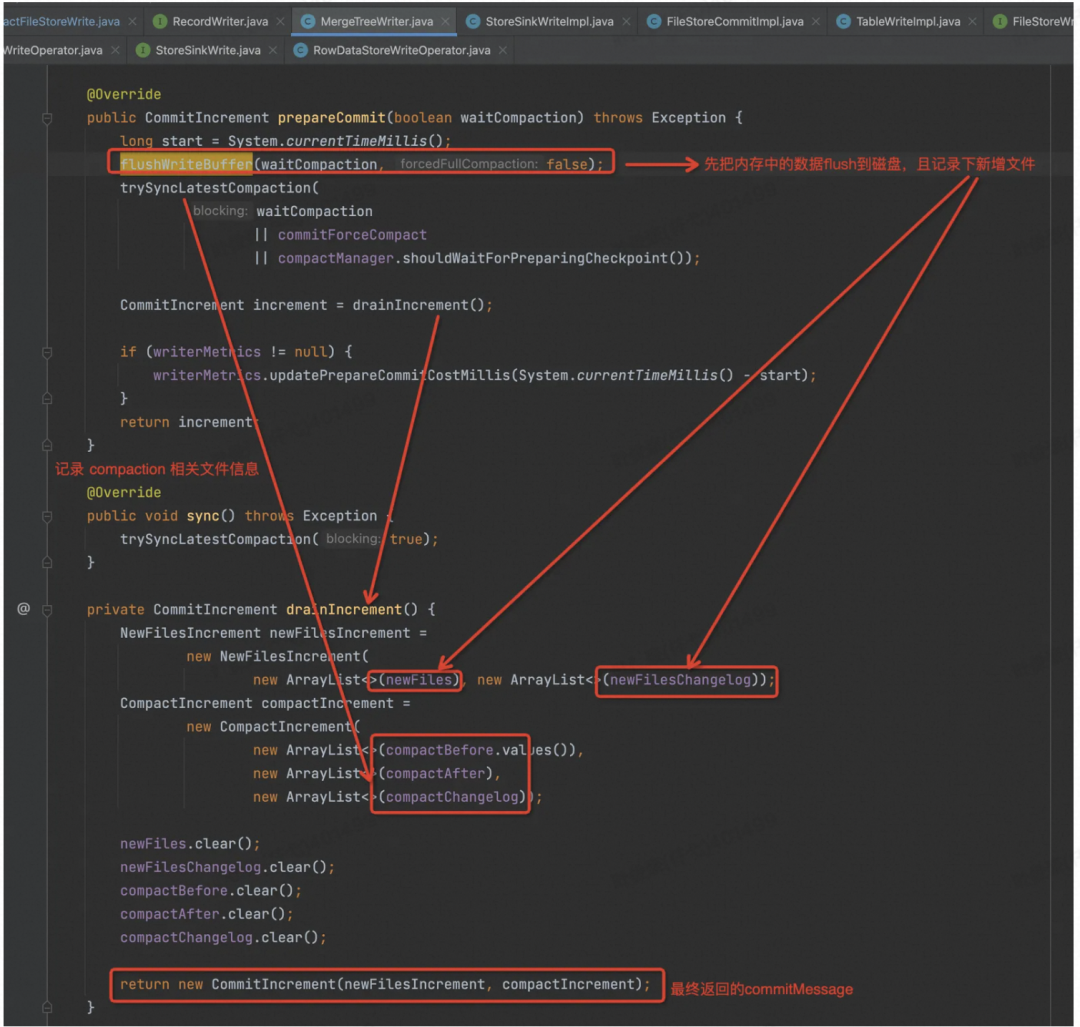
会先强制 Flush 内存的数据到磁盘,还会同步最后一次 Compaction 的信息,把新增文件信息全部记录下来封装到一个对象中返回。
再看最后一个节点 CommitterOperator,会收到上游发送的各个 Bucket Writer 的新增文件信息,缓存到 Queue 中。
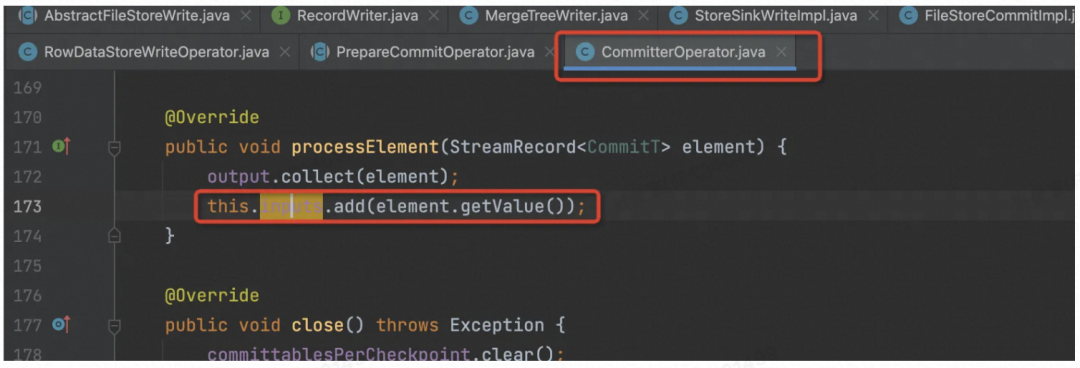
在做 Checkpoint 时,将多个 ManifestCommittable 的信息统一写入到 Flink State 中。
流作业处理有限数据源时,Task 结束的时候会发一个 checkpointId = Long.max 的数据下去,在 pollInput( ) 函数里面会将这些特殊情况的 checkpointId 合并在一起处理,而不是报错。
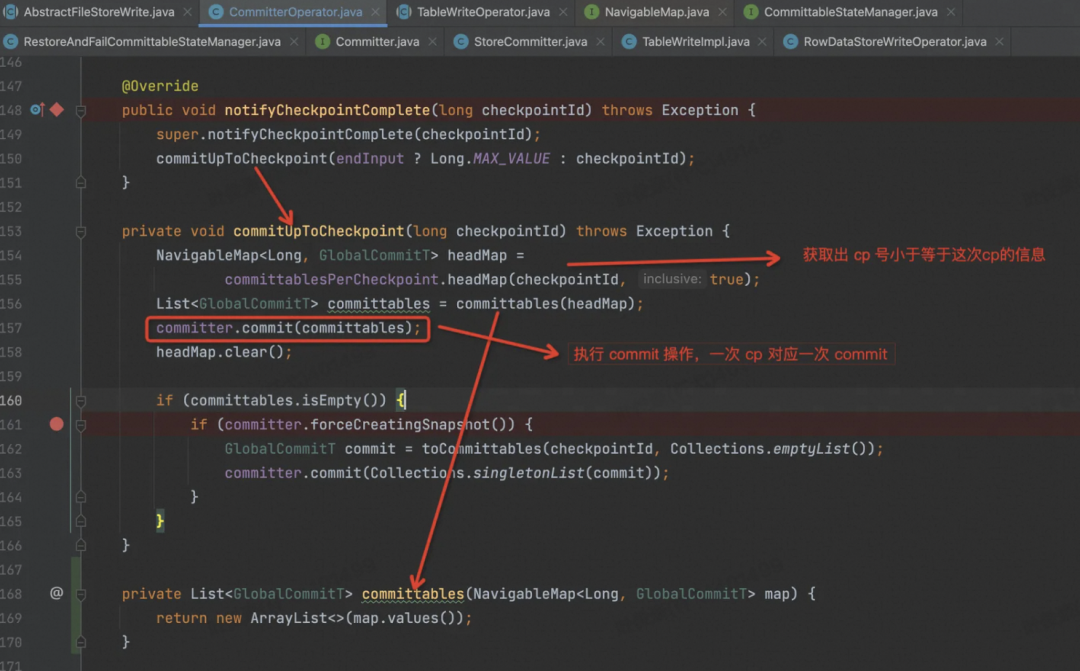
当 Checkpoint 完成了,Flink 框架会 Rpc 调用回来,会调用 notifyCheckpointComplete( ) 函数,"告诉" Task Checkpoint 做完了,这时候 Paimon 就可以创建 Snapshot 啦。
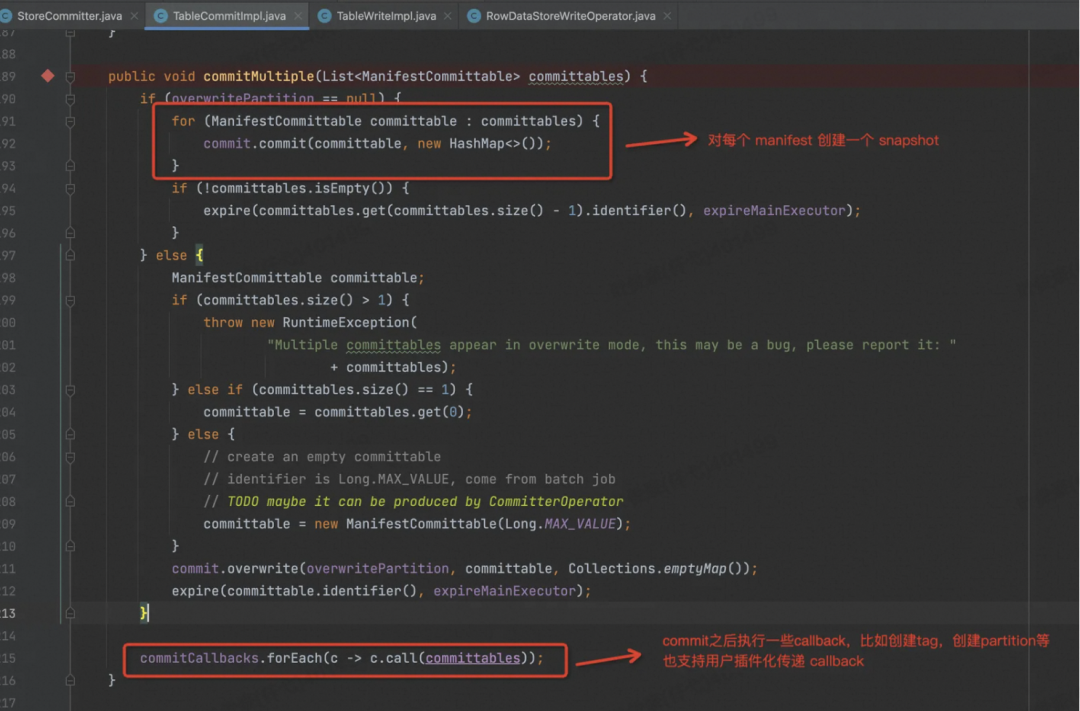
对每个 Manifest信息来创建 Snapshot。
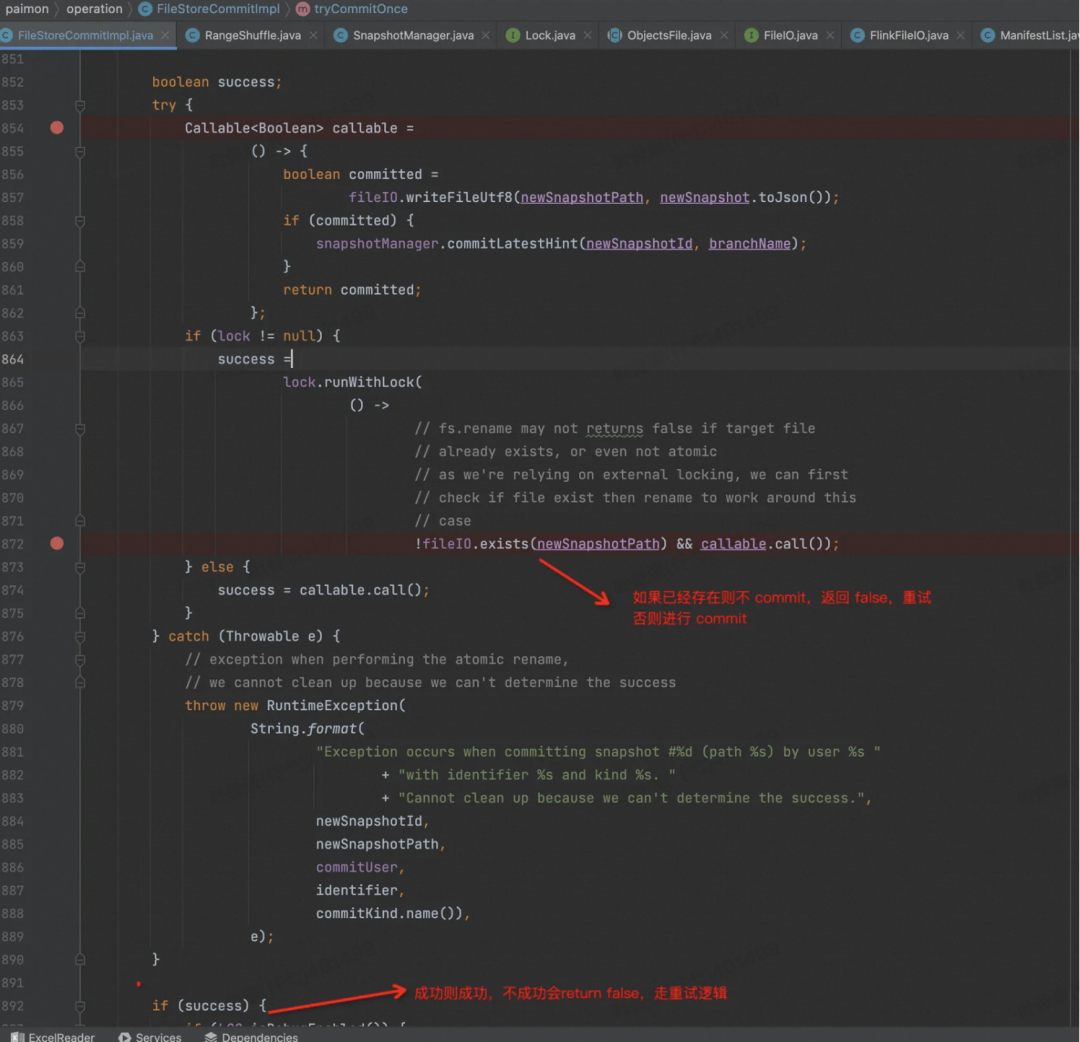
剩下的逻辑都在 org.apache.paimon.operation.FileStoreCommitImpl 中,这个类里面重点实现了原子性提交一次 Snapshot 的逻辑。
首先根据 Commit 信息做一些冲突检查,两个 Writer 同时写的情况
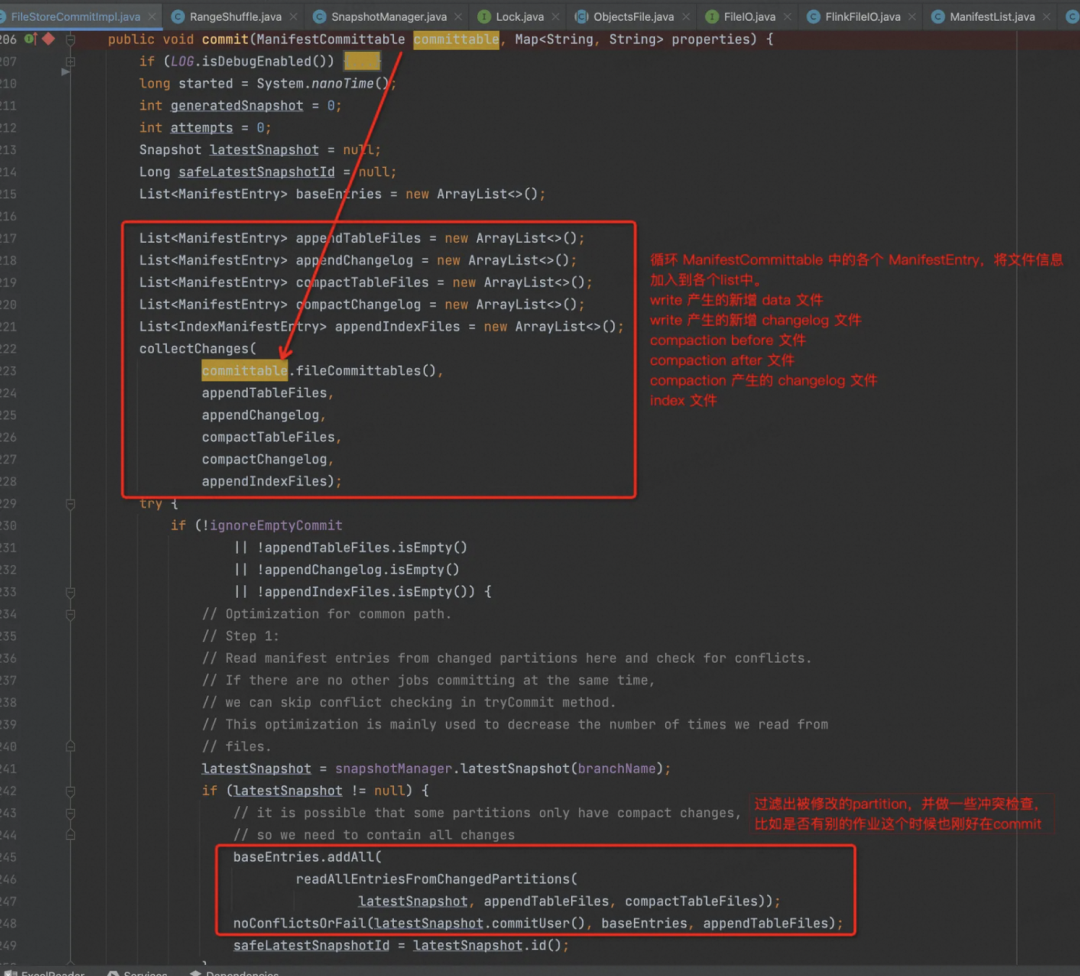
检查冲突:
其次,正如官网所述,一次 Commit 最多产生两个 Snapshot,一个是 Write 的,一个是 Compaction 的,如下图。
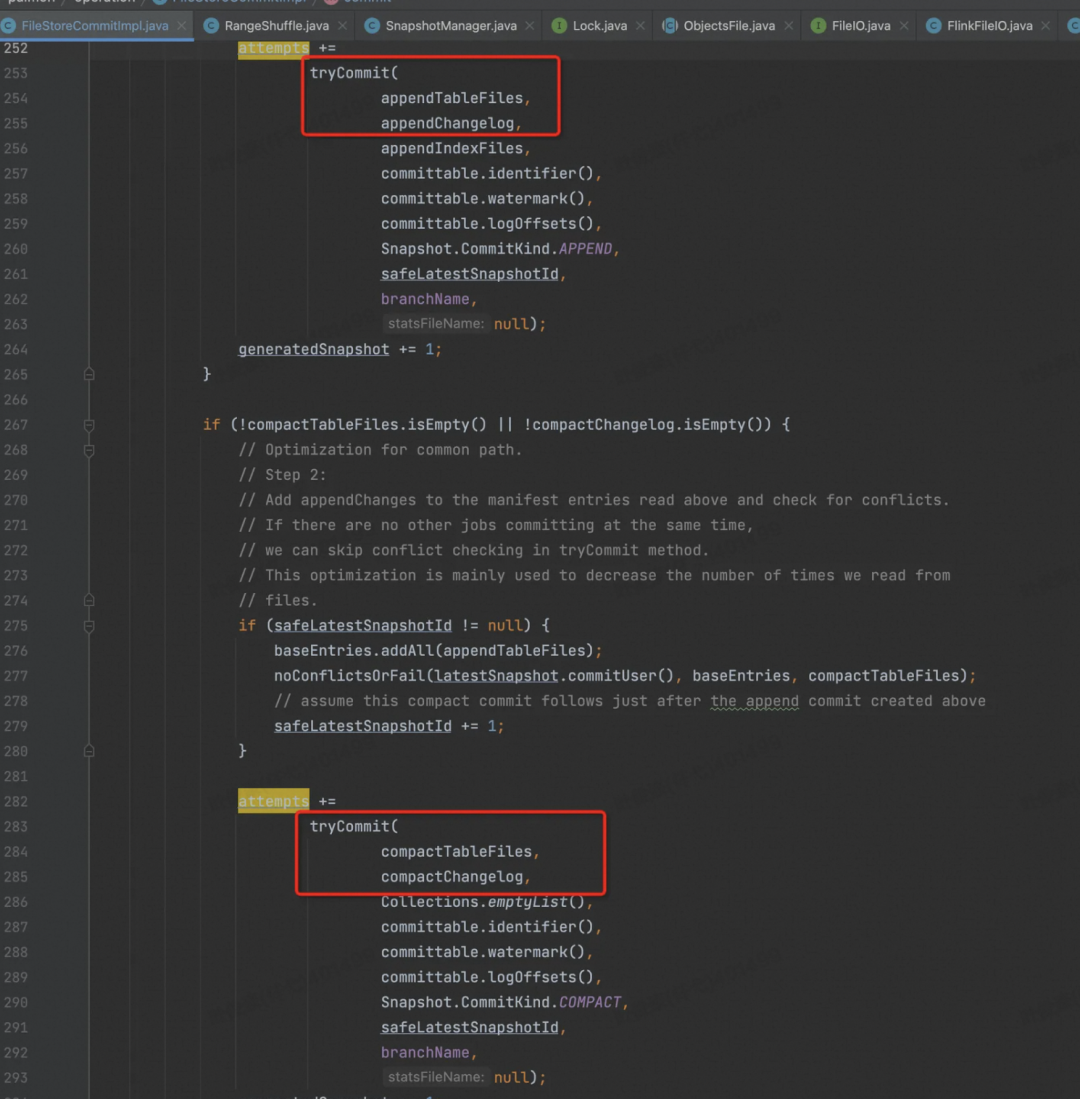
然后,开始尝试 Commit,无限循环,直到成功,或者抛出异常,走 Flink Failover 逻辑
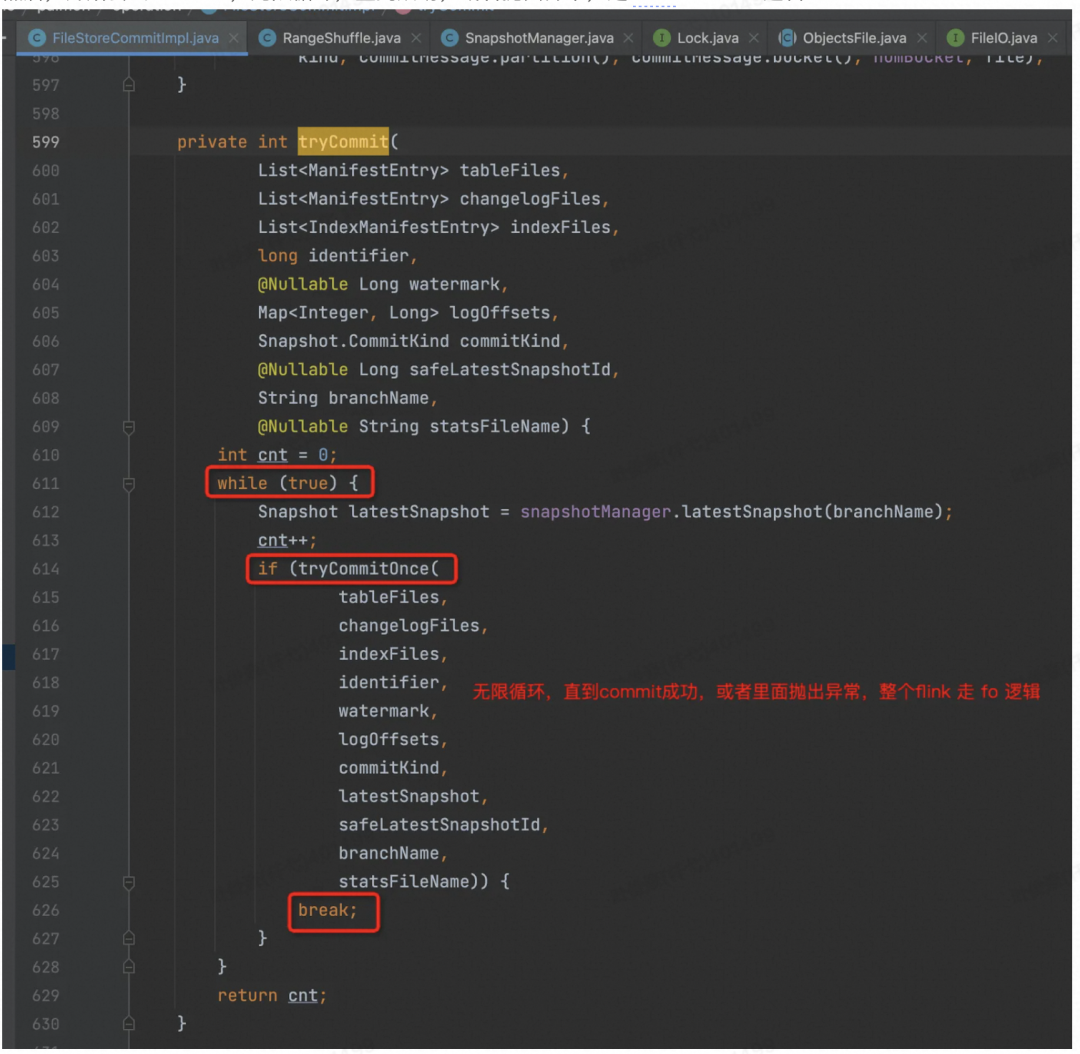
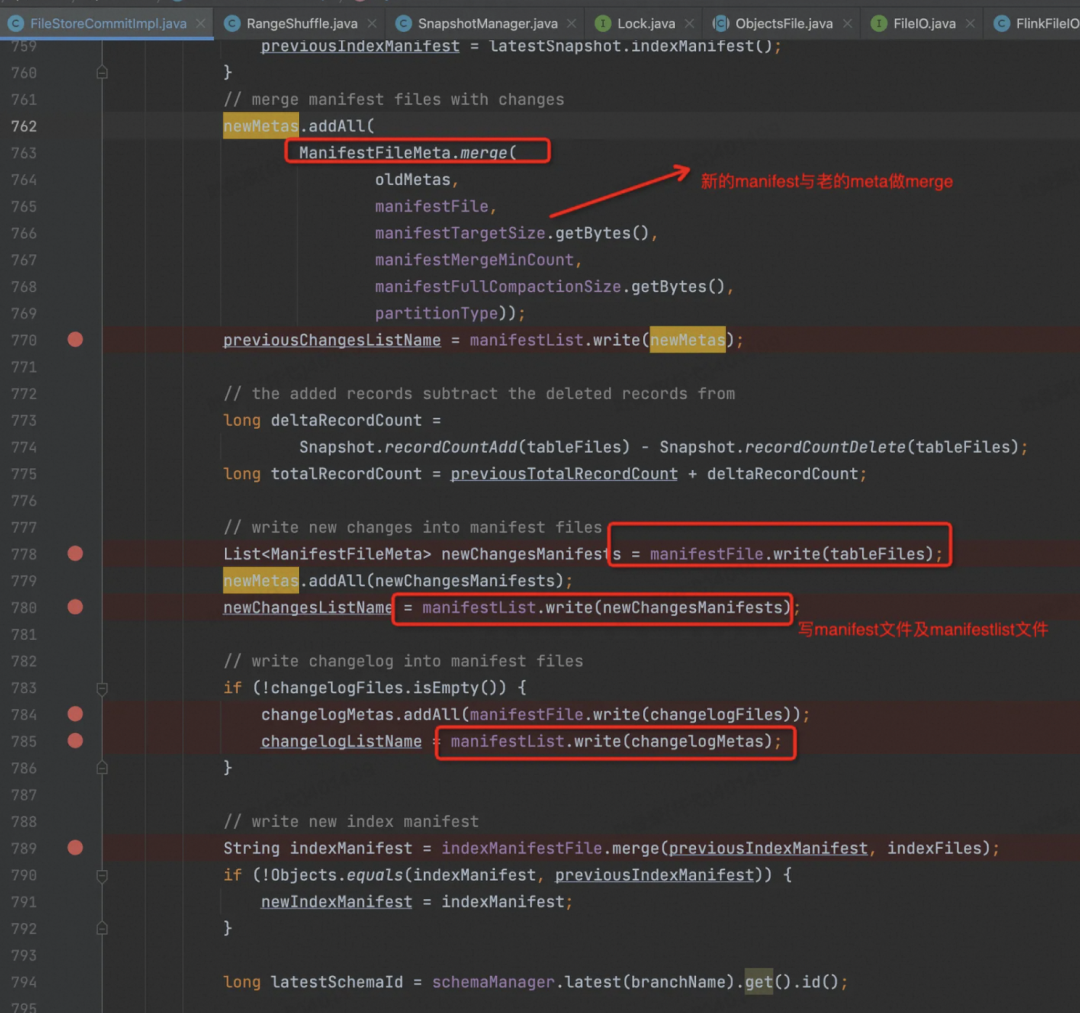
写 Meta 相关文件,写之前要对新老 Meta 做一次 Merge。
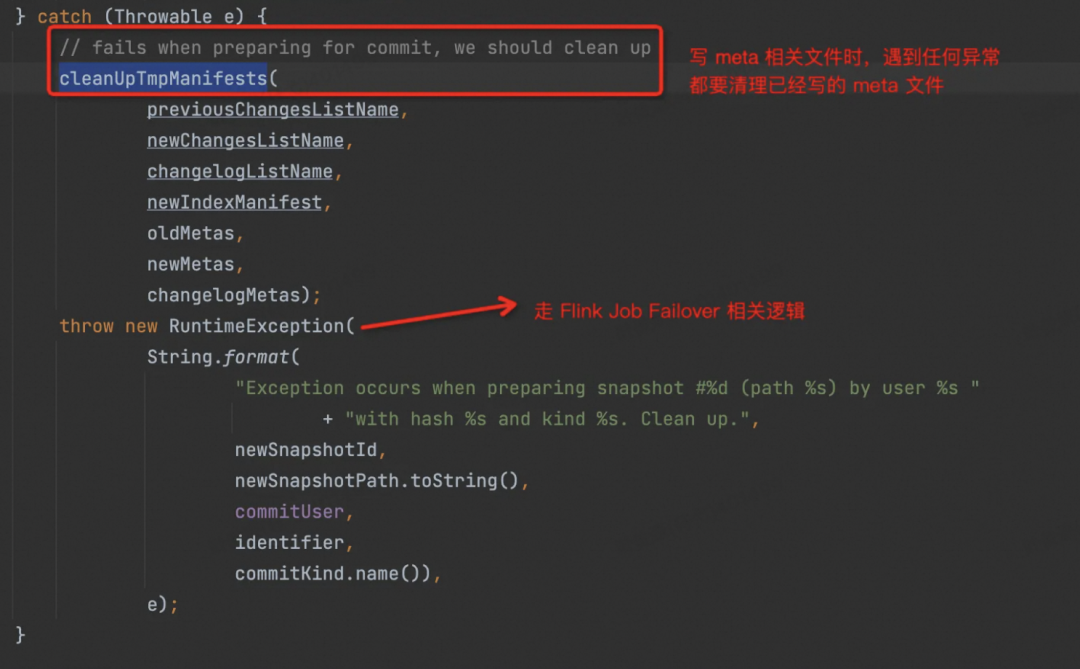
当然,在这过程中有任何异常,都会调用 cleanUpTmpManifests 来清理这些文件,抛出 RuntimeException,走Flink 的 Failover 逻辑。
再准备 Snapshot 相关信息,放到一个 Json 对象中。
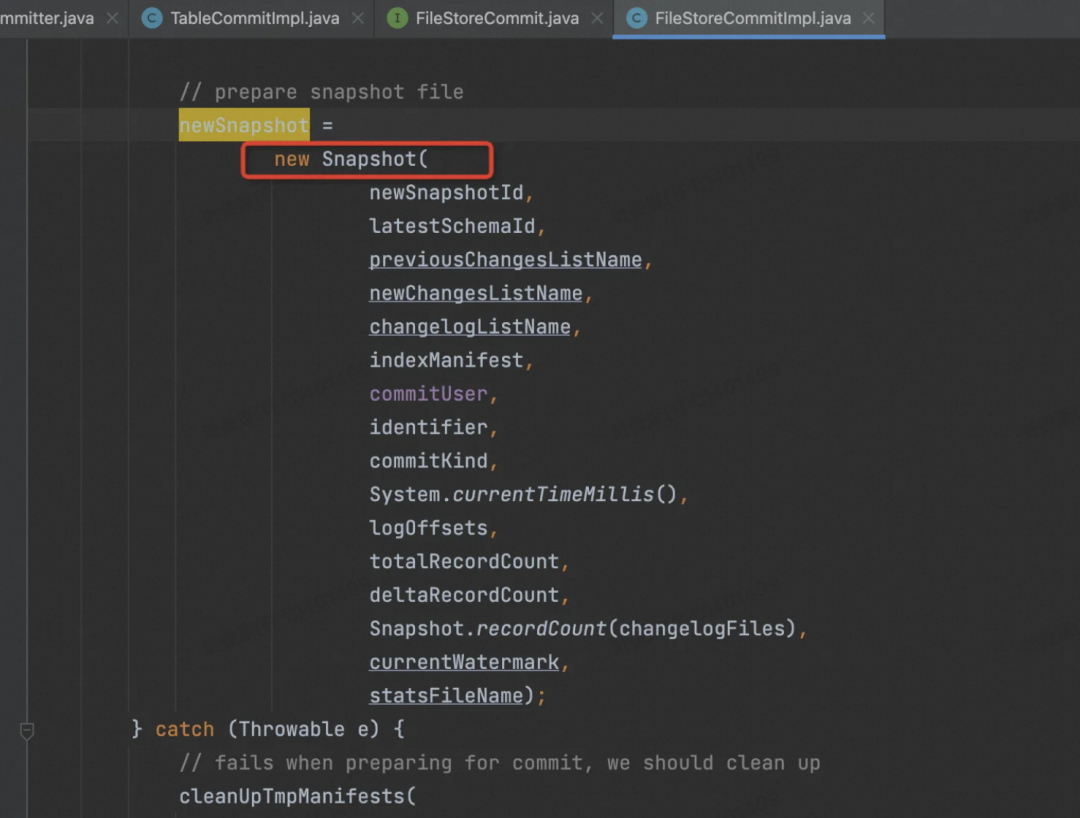
最后执行 Commit 操作,也就是把 Snapshot 信息持久化到磁盘上了。
Failover
最后再看 Failover 时,最后一个节点是如何处理的?
首先状态中会记录缓存在节点中的各个 GlobalCommittable,有多个的原因是因为有些之前的 Checkpoint 可能会是失败的,或者这次 Checkpoint 没有完成,新的 Checkpoint 又触发了。
这里会把比当前 CheckpointId 更小的 CheckpointId 对应的各个 GlobalCommittable 一起提交到外部系统(DFS / OSS)。
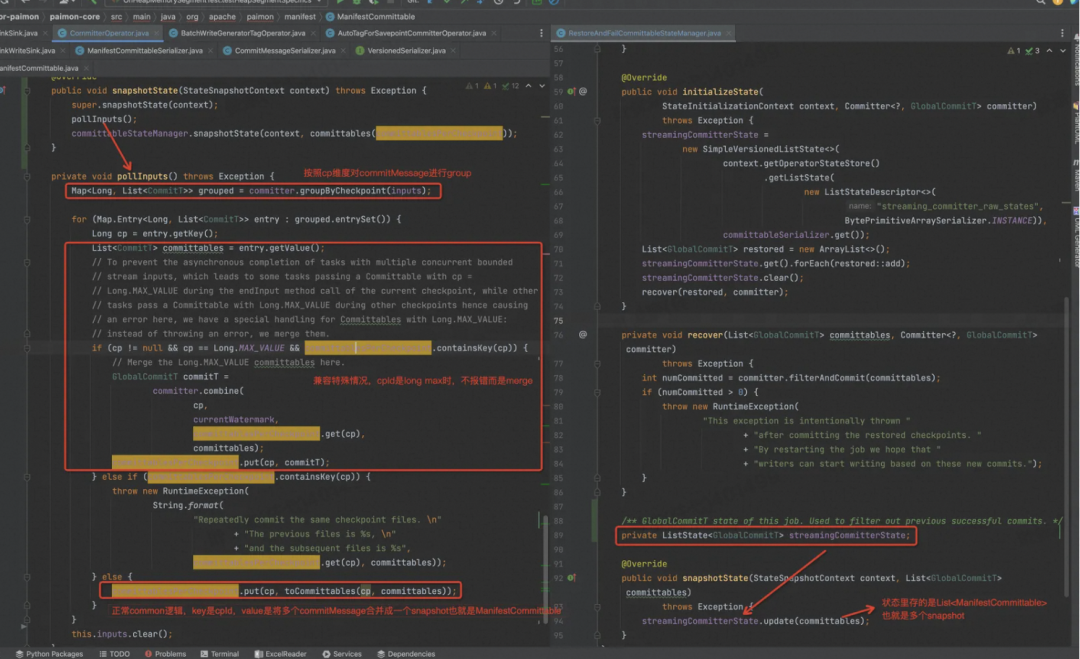
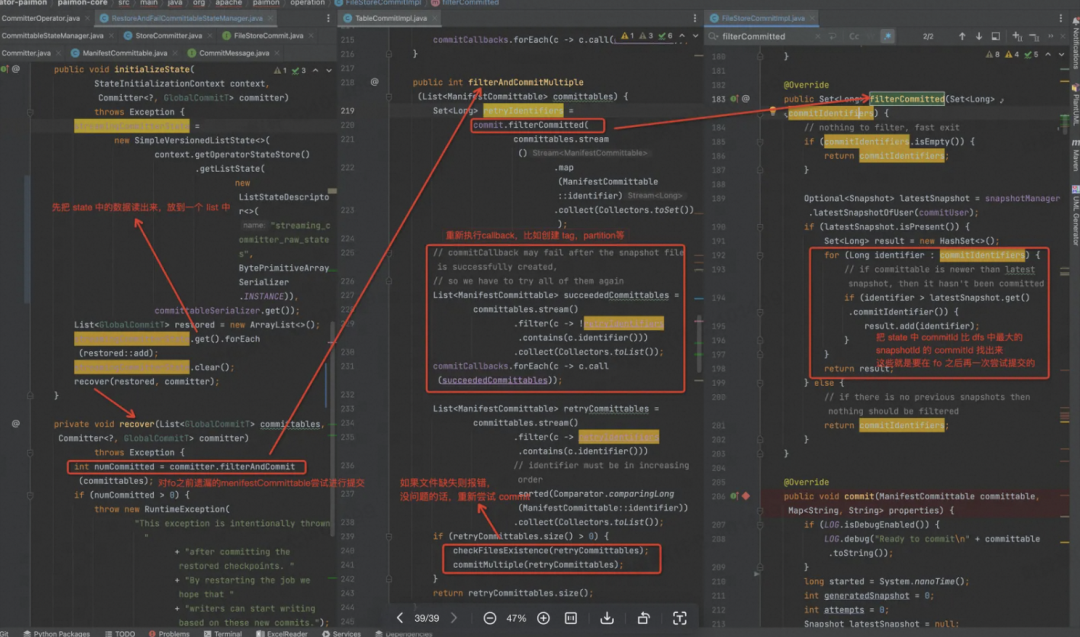
Failover 以后,Task 一起来就读取 State 中的数据,然后根据 DFS 中最大的 SnapshotId 就知道 State 中哪些MenifestCommittable 是没有来得及提交的,然后这里就尝试重新提交,也就是两阶段提交中第二阶段如果出错的话,怎么保证数据的一致性。
总结
总的来说,Paimon 代码质量还是可以的,考虑的也比较周全,后续会持续更新 Paimon 别的模块的解读。

活动推荐
阿里云基于 Apache Flink 构建的企业级产品-实时计算 Flink 版现开启活动:
新用户复制下方链接或者扫描二维码即可0元免费试用 Flink + Paimon
了解活动详情:https://free.aliyun.com/?pipCode=sc

▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」跳转阿里云实时计算 Flink ~
点击「阅读原文」跳转阿里云实时计算 Flink ~















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









