




我们很高兴地宣布,Apache Fluss 0.8 (incubating) 版本现已正式发布!
这是我们进入 Apache 软件基金会孵化器后的首个版本,标志着 Apache Fluss 在构建强大实时分析流式存储平台的道路上迈出了关键一步。
过去四个月中,Fluss 社区取得了显著进展,累计完成近 400 次代码提交,持续拓展了流分析和湖流一体生态系统的边界。本次版本在稳定性上完成了诸多优化,在生态集成、引擎性能和流处理能力等方面实现了重大突破,主要亮点包括:
湖流一体能力全面增强,完整支持了 Apache Iceberg 和 Lance
支持 Delta Joins[1],这一革命性创新通过最小化 Flink 状态、最大化处理速度,重新定义了流处理的效率标准
支持集群配置热更新,以及表配置热更新
Apache Fluss 0.8 标志着流处理进入全新时代: 以 实时、统一 为核心,为驱动下一代数据平台而打造,凭借 低延迟性能、强扩展能力 与 简洁架构 构建现代流处理基础设施。
01
稳定性
本次版本中,我们大幅提升了 Apache Fluss 在大规模生产环境下的稳定性和可靠性。 通过阿里巴巴集团内多个业务单元的持续验证,尤其是在双11流量洪峰期间的大规模压测表现丝滑。我们解决了超过 35 个稳定性相关问题。 这些改进显著增强了 Fluss 在核心业务流式场景中的健壮性。
主要改进:
优雅停机[2]:Fluss 支持集群的滚动升级,这个版本我们为 TabletServer 引入了优雅停机机制,在 Shutdown 旧版本 TabletServer 过程中主动迁移 Leader 节点,确保滚动升级期间读写延迟不受影响
加速 Coordinator 事件处理:通过异步处理和批量 ZooKeeper 操作优化 Coordinator 的事件处理机制,所有事件现在都能在毫秒级完成处理
加快 Coordinator 恢复速度:通过并行化初始化,在生产规模基准测试中将 Coordinator 启动时间从 10 分钟缩短到仅 20 秒,大幅提高服务可用性和恢复速度
优化服务端监控指标:细化指标粒度和上报逻辑,Metric 数据量减少 90%,同时保持完整的可观测性
增强元数据读取性能:通过强化服务端本地缓存和引入异步 ZooKeeper 操作,解决客户端大规模重启期间的元数据瓶颈,元数据请求延迟从 >10 秒降至毫秒级,确保高负载下客户端的稳定重连
凭借这些基础的稳定性改进,Fluss 0.8 现已具备应对极高压力实时工作负载的能力,包括支持双11购物节。
02
Iceberg 湖流一体
Fluss 0.8 的一大亮点是引入了 基于 Apache Iceberg 的湖流一体, 将 Iceberg 从面向批处理的表格式演进为支持持续更新的湖仓平台。Apache Fluss 作为 实时数据摄取和存储层,将最新数据和更新写入 Iceberg,并保证有序性和 Excactly Once 语义。
通过这一能力,Fluss 上的实时数据可以自动分层到 Apache Iceberg 表中,在一份数据上同时支持分区、分桶等表语义。 更重要的是,Fluss 通过 原生支持 Upsert 和 Delete 以及 内置的 Compaction 服务,解决了 Iceberg 长期以来在数据更新方面的局限性。 该内置服务可自动合并小文件,持续维护 Iceberg 快照的最优状态。
核心优势:
统一架构:Fluss 负责亚秒级流式读写,Iceberg 存储压缩后的历史数据
原生更新和删除:Fluss 高效应用数据变更并分层到 Iceberg,无需额外的Merge任务
内置 Compaction 服务:自动维护快照,无需依赖外部工具
高效历史数据回填:支持从 Iceberg 快速回填历史数据用于流式处理
降低存储成本:冷数据自动分层到 Iceberg,热数据保留在 Fluss,避免数据重复存储
降低数据延迟:通过 Fluss 和 Iceberg 之间的 Union Read 能力,让 Iceberg 表的数据新鲜度达到亚秒级
# Iceberg 配置datalake.format: iceberg# Iceberg Catalog 配置(以 Hadoop Catalog 为例)datalake.iceberg.type: hadoopdatalake.iceberg.warehouse: /path/to/iceberg您可以在 Iceberg 湖仓文档[3] 中找到更多详细说明。
03
基于 Lance 的实时多模态 AI 分析
Fluss 0.8 的另一项重大增强是新增了 Lance[4] 湖流一体的支持, Lance 是一种专为 AI 和机器学习工作负载设计的现代化列式向量数据格式。这一集成让 Apache Fluss 成为多模态数据与 AI 的实时摄取平台,不仅能处理传统的表格数据流,还能处理 AI 系统中的 Embedding(嵌入向量)、向量数据以及非结构化特征。 通过这一能力,Fluss 可以持续摄取多模态数据,并持续地将数据分层存储到 Lance 表中,保证数据的有序性和新鲜度, 实现流式数据管道与下游机器学习或检索应用之间的快速同步。
核心优势:
统一的多模态数据摄取:实时将表格数据、向量数据和 Embedding 数据流式写入 Lance
AI Ready的存储:特征向量和 Embedding 数据持续更新,随时可用于模型训练或推理
低延迟分析和检索:数据持续快速更新,Lance 数据可立即用于实时搜索和推荐
架构大幅简化:无需在流系统和向量数据库之间构建复杂的 ETL 管道
通过无缝集成,Fluss 的高吞吐流式引擎与 Lance 的高效列式存储相结合,实现了统一的多模态数据管理。
datalake.format: lancedatalake.lance.warehouse: s3://<bucket>datalake.lance.endpoint: <endpoint>datalake.lance.allow_http: truedatalake.lance.access_key_id: <access_key_id>datalake.lance.secret_access_key: <secret_access_key>请参阅 LanceDB 博客文章[5] 了解完整集成信息。您也可以在 Lance 湖仓文档[6] 中找到更多详细说明。
04
Flink 2.1
Apache Fluss 现已完全兼容 Apache Flink 2.1,与最新的 Flink 运行时和 API 实现无缝集成。 这一更新进一步强化了 Fluss 作为统一流式存储层的定位,为基于 Flink 构建的现代数据管道提供稳定可靠的性能保障。
Delta Join
Delta Join 是迈向零状态流式 Join 时代的关键一步。本次版本引入了 Apache Flink 对 Delta Join 的支持。 通过将状态外部化到 Fluss 表中,Flink 只需在数据增量上执行 Join 操作,无需维护大量状态。 这种架构使 CPU 和内存使用量降低了 高达 80%,正如早期用户(如淘宝实践)的生产案例所示, 系统消除了超过 100TB 的状态,并将 Checkpoint 时长从 90 秒缩短到仅 1 秒。由于所有数据都原生存储在 Fluss 表中, 无需任何状态初始化;作业可以即刻启动、保持轻量,在大规模实时分析场景下实现极致效率。
以下是淘宝搜索与推荐系统团队对 Delta Join 与双流 Join 的性能对比测试(CPU、内存、状态大小、Checkpoint 间隔)。
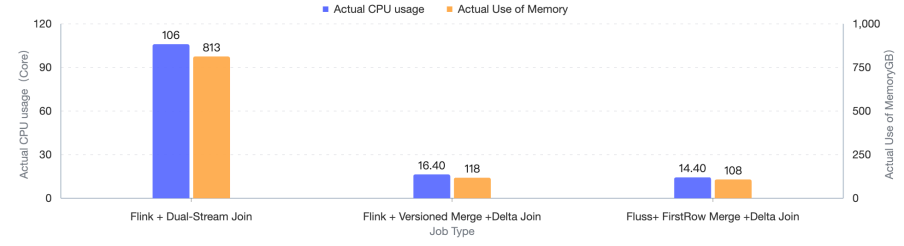
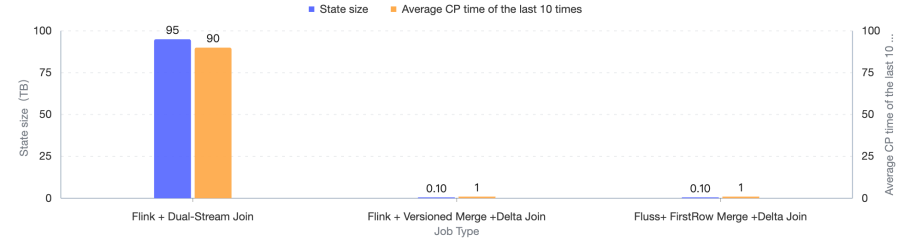
您可以在 Delta Join 文档[7] 中找到更多详细说明。
Materialized Table
Apache Fluss 0.8 引入了对 Flink Materialized Table 的支持,可在 Fluss 流之上实现低延迟的物化表。 Flink Materialized Table 将 SQL 查询转换为按目标新鲜度(如秒级或分钟级)持续或定期刷新的结果表。 以 Fluss 作为底层流数据源,用户可以声明式地构建实时更新的表,无需编写复杂的调度逻辑。 这种集成实现了批流的深度统一:Fluss 提供高吞吐、低延迟的数据流,Flink 持续维护衍生表供分析查询、 API 调用和下游任务使用,从而构建实时一致的数据管道,同时将运维成本降至最低。 这一能力进一步强化了批流一体化。
-- 1. 创建一个具有 10 秒新鲜度的 Materialized TableCREATE MATERIALIZED TABLE fluss.dw.sales_summaryFRESHNESS = INTERVAL '10' SECONDAS SELECT product, SUM(quantity) AS total_sales, CURRENT_TIMESTAMP() AS last_updatedFROM fluss.dw.sales_detailGROUP BY product;
-- 2. 暂停 Materialized Table 的数据刷新ALTER MATERIALIZED TABLE dwd_orders SUSPEND;
-- 3. 恢复 Materialized Table 的数据刷新ALTER MATERIALIZED TABLE dwd_orders RESUME-- 通过 WITH 子句设置表选项WITH( 'sink.parallelism' = '10' );您可以在 Materialized Table 文档[8] 中找到更多详细说明。
05
动态配置
从 Fluss 0.8 版本开始,支持对部分 集群级配置 和 表级配置 进行动态更新,无需重启集群或重建表。这使运维人员和开发者能够实时调整系统行为,提升运维灵活性,同时最大程度降低停机时间。
动态集群配置
Fluss 现在支持运行时更新集群配置参数。通过 API 应用后,这些更改会立即在整个集群中生效。
Admin admin = connection.getAdmin();Collection<AlterConfig> configsToUpdate = Arrays.asList( new AlterConfig("datalake.format", "paimon", AlterConfigOpType.SET));admin.alterClusterConfigs(configsToUpdate)动态表配置
Fluss 现在支持使用 ALTER TABLE ... SET 语句动态更新表配置,支持所有客户端配置(如 scan.startup.mode)以及部分存储配置(如 table.datalake.enabled)。
-- 为该表启用湖流一体ALTER TABLE my_table SET ('table.datalake.enabled' = 'true');当执行 ALTER TABLE ... SET 命令更新表的存储选项时,Fluss 集群会验证并立即应用新配置,更新后的配置会传播到所有 TabletServer 和 CoordinatorServer 组件,确保后续行为的一致性。该功能对于性能调优、适配数据模式变化或满足数据治理要求等场景非常实用,而且全程无需中断服务。
您可以在 更新配置文档[9] 中找到更多详细说明。
06
Helm Charts
本次版本还引入了 Helm Charts,用户现在可以使用 Helm 部署和管理完整的 Fluss 集群。 Helm Chart 将配置、清单和依赖打包成单个版本化的发布包,大幅简化了集群的部署、升级和扩容流程。 这让在 Kubernetes 上运行 Fluss 变得更快、更可靠,同时也更容易与现有的 CI/CD 和可观测性体系集成,显著降低了团队在生产环境中采用 Fluss 的门槛。
您可以在 使用 Helm 部署文档[10] 中找到更多详细说明。
07
Java 版本升级
自 Fluss 0.8 版本起,项目默认的 Java 语言版本已从 Java 8 升级至 Java 11,官方发布的二进制包也改用 Java 11 编译。因此,部署 Fluss 集群或使用 Fluss Connector/Client 时,最低要求为 Java 11。另外我们推荐在生产环境中使用 Java 17 运行 Fluss 服务,以获得更好的性能与长期支持。
目前 Fluss 源码仍保留对 Java 8 的源码兼容性。若您因特殊需求必须在 Java 8 环境中运行 Fluss,可自行从源码构建。但请注意:Java 8 支持已被标记为废弃(deprecated),将在未来版本中正式移除。
08
生态系统
Apache Fluss 社区正在积极拓展 Fluss 的生态体系,突破 JVM 生态边界,推出面向 Rust 和 Python 的 原生客户端,实现与现代数据和 AI 工作流的无缝集成。 我们建立了 官方仓库(https://github.com/apache/fluss-rust) 来托管 Rust 和 Python 客户端,并在性能、安全性和开发者体验方面都进行了精心打磨:
Rust 客户端:基于异步 I/O、零拷贝列式流(通过 Apache Arrow)以及 Rust 的内存安全保障构建,该客户端可与 DuckDB 和 StarRocks 等原生 OLAP 引擎实现高性能查询集成
Python 客户端:作为 Rust 客户端的原生绑定实现,Python 开发者可以直接在数据科学、机器学习和分析工作流中与 Fluss 的表和流进行交互
Rust 和 Python 客户端在独立仓库中维护,以便快速迭代和发布,因此不包含在 Fluss 0.8 的发布包中。 不过,社区正在积极推进客户端的稳定性,计划不久后发布。
09
升级说明
Fluss 社区始终致力于提供平滑的升级体验。本次升级在网络协议与存储格式层面保持兼容性,客户端与服务端均支持双向兼容,即:
0.7 版本的客户端可正常访问 0.8 版本的服务端,
0.8 版本的客户端也可兼容访问 0.7 版本的服务端。
另外,Fluss 0.8 是项目进入 Apache 孵化器后的首个正式发布版本,涉及包路径等变更。因此,依赖 Fluss SDK 的应用程序在升级至 0.8 时,需对代码进行相应适配。详情请参考 升级说明[11],了解升级过程中需要调整的配置和检查的问题。
10
贡献者名单
Apache Fluss 社区衷心感谢所有为本次版本做出贡献的开发者:
Alibaba-HZY, CaoZhen, CenterCode, CodeDrinks, David, Giannis Polyzos, Hemanth Savasere, Hongshun Wang, Jark Wu, Jensen, Junbo Wang, Kerwin, Leonard Xu, Liebing, Maggie Cao, Mahesh Sambaram, MehulBatra, Michael Koepf, Rafael Sousa, Rion Williams, Ron, Sergey Nuyanzin, SeungMin, Wang Cheng, XianmingZhou00, Xuyang, Yang Guo, Yang Wang, Yunchi Pang, ZijunZhao, Zmm, andybj0228, buvb, cxxwang, dependabot[bot], jackylee, leosanqing, naivedogger, ocean.wy, pisceslj, totalo, xiaochen, xiaozhou, xx789, yunhong, yuxia Luo
引用链接
[1] https://cwiki.apache.org/confluence/display/FLINK/FLIP-486%3A+Introduce+A+New+DeltaJoin
[2] https://fluss.apache.org/docs/maintenance/operations/graceful-shutdown/
[3] https://fluss.apache.org/docs/streaming-lakehouse/integrate-data-lakes/iceberg/
[4] https://github.com/lancedb/lance
[5] https://lancedb.com/blog/fluss-integration/
[6] https://fluss.apache.org/docs/streaming-lakehouse/integrate-data-lakes/lance/
[7] https://fluss.apache.org/docs/engine-flink/delta-joins/
[8] https://fluss.apache.org/docs/engine-flink/ddl/#materialized-table
[9] https://fluss.apache.org/docs/maintenance/operations/updating-configs/
[10] https://fluss.apache.org/docs/install-deploy/deploying-with-helm/
[11] https://fluss.apache.org/docs/maintenance/operations/upgrade-notes-0.8/
关于 Apache Fluss
Apache Fluss (Incubating) 是面向实时分析设计的下一代流存储,正在持续迭代中,欢迎关注项目动态,体验试用。如果你喜欢这个项目,欢迎在 GitHub 上点赞支持 ❤️ ⭐。
GitHub:https://github.com/apache/fluss


















 1403
1403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









