









预热
比较喜欢的一段话:不经一番寒彻骨,怎得梅花扑鼻香,学习是枯燥的请大家坚持!
这篇文章的是向丁奇老师学习的。不懂的自己搜一下哈!
阅读这篇文章大概需要20分钟!
大家好,我是一位农民工(码农),也是一位打算冲击一线互联网大厂的码农。目前从事的是Java后端开发,写作分享经验是我的兴趣,我想帮助更多未来可期但是现在迷茫的人!
欢迎大家来到走向一线大厂的大门!开局前,先上几句SQL大家先热热身!
explain SELECT ID FROM t_apimonitoring
explain SELECT * FROM t_apimonitoring
explain SELECT ID FROM t_apimonitoring where ID=20
explain SELECT * FROM t_apimonitoring where ID>7000
大概就是这四句啦,都是比较基础的。分别是查询性能监控表的所有数据,查询所有ID数据,查询ID为20的数据,查询ID大于7000的所有数据。最后再一一论证是如何查询的!
工作大概半年了,我见过很多同事打开SQL面板,很大的概率是非常熟练的先输入了一遍select * from 表名然后一堆数据就出来了。以及去年大厂热点话题 <谁在写select * 给我滚蛋>。大家有没有想过为什么会这样呢?
开始
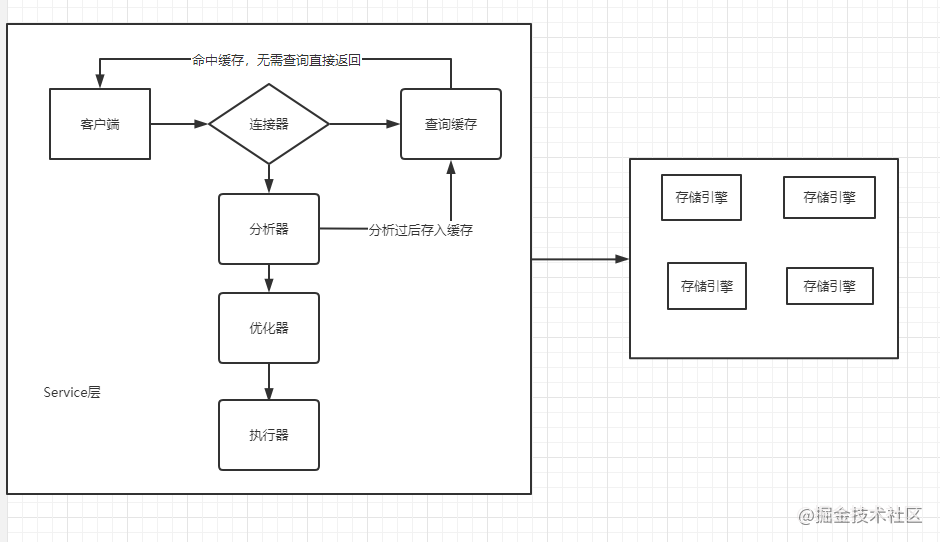
首先MySQL大体可以分为,Service层,存储引擎层两个部分。
连接器: 校验用户身份信息,校验当前用户的SQL语句权限,管理SQL连接的通道
分析器: 词法分析,语法分析。用于处理客户端的SQL语句,分析处理完之后写入缓存,如果下次命中的话直接返回提高查询效率。
优化器: 生成执行计划,索引选择(这里可以完美解释我上面抛出的SQL执行问题)
执行器: 调用操作存储引擎,捞取数据。
存储引擎: 后面会详细讲一些扩展引擎,第三方引擎,大数据量引擎等。这里会简单介绍一下Innodb与myisam
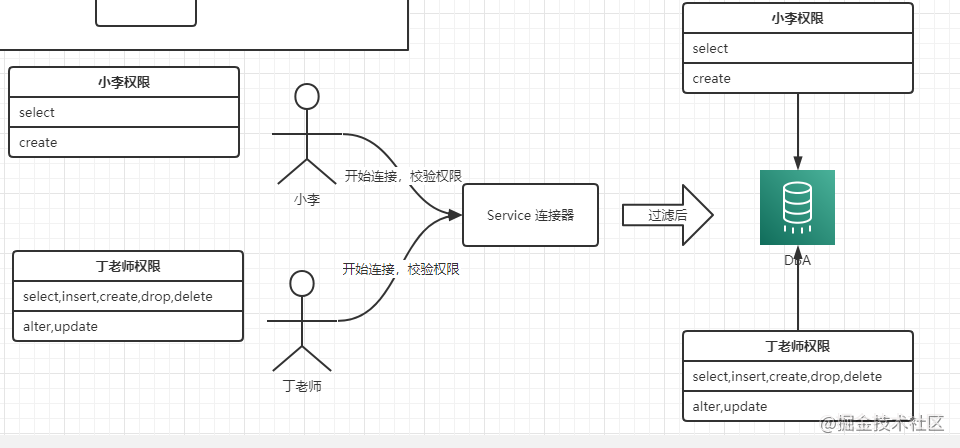
连接器
- 通过这个指令建立连接
mysql -h 127.0.0.1 -P 3306 -u root -p 123456 - 通过分配后的权限,每个用户可以操作相应的事情
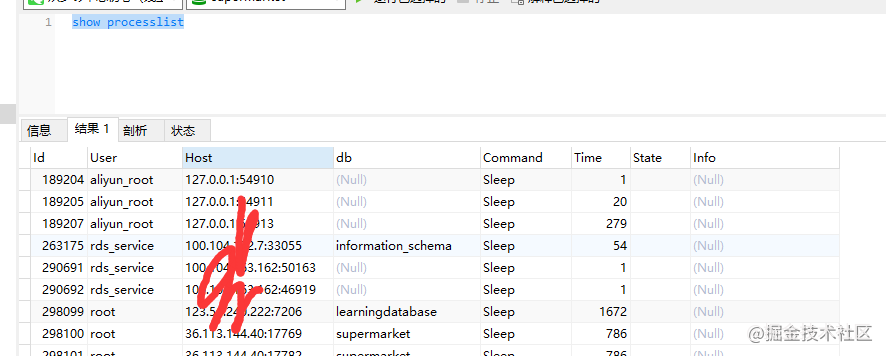
- 建立连接之后可以通过
show processlist查询连接状态。其中的 Command 列显示为“Sleep”的这一行,就表示现在系统里面有一个空闲连接。客户端如果太长时间没动静,连接器就会自动将它断开。这个时间是由参数 wait_timeout 控制的,默认值是 8 小时。
4.数据库连接又分为两种连接方式,一种是长连接,一种是短连接。长连接的意思就是建立连接之后,如果客户端的有请求操作则一种使用同一个连接进行交互处理。短连接的意思就是建立连接之后,并且客户端执行完自己的需求之后,就关闭了连接。
结论: 数据库建立连接这个过程是比较复杂的,所以建立尽量减少使用短连接的方式,也就是尽量使用长连接
弊端: 全部使用长连接后,你可能会发现,有些时候 MySQL 占用内存涨得特别快,这是因为 MySQL 在执行过程中临时使用的内存是管理在连接对象里面的。这些资源会在连接断开的时候才释放。所以如果长连接累积下来,可能导致内存占用太大,被系统强行杀掉(OOM),从现象看就是 MySQL 异常重启了。怎么解决这个问题呢?你可以考虑以下两种方案。定期断开长连接。使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。如果你用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行 mysql_reset_connection 来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
查询缓存
建立连接之后,就可以开始我们的操作了,比如写一些SQL语句了。MySQL拿到一个SQL请求后,会先检查缓存中是否已经执行过这条语句了,如果当前存在就直接返回这是最有的查询方式,效率也是非常高的,但是在实践中往往不建议使用缓存,因为缓存内有一个机制,当这个表发生更新的时候就会清空缓存,在真正的操作中一般都会多次更新操作的。所以就算存了缓存也用不上,除非有一些系统设置表,用户表等一些冷门的表才建议使用缓存。
使用手法:将参数query_cache_type设置成DEMAND,这样对于默认的SQL都不使用查询缓存,而真正对于一些系统设置类的静态表可以在SQL上添加以下指令实现缓存效率。
mysql> select SQL_CACHE * from T where ID=10;
分析器
分析器要做的事情主要是‘词法分析’和‘语法分析’
如果没有命中缓存就说明走到这一步了.我们看到的一串字符串,真正在执行的时候不会执行一段字符串的,所以分析器的作用就是提取字符串的指令,比如开头的SQL指令。字符串select会转换成一个查询语句,字符串t_apimonitoring会转换成表t_apimonitoring,字符串ID会转换成列ID。
转换成SQL语言之后就开始进行语法分析了,分析SQL语法是否有错误,如果没有错误的话下一步继续执行,如果有错误的话我们只需要关注use near大概就能解决一切了,所以SQL还是非常强大方便的。
> 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'from where ss per_user' at line 1
优化器
经过分析器已经转一个字符串转换成一个SQL语句了。优化器所要做的事情就是,寻找匹配索引达到最优查询效率。
这里是t1表跟t2表进行关联,查询t1表中的c字段为10的数据并且也查询t2表中的d字段为20的共同数据。如果换一个说法这里是t2表跟t1表进行关联,查询t2表中的d字段为20的数据并且查询t1表中的c字段为10的数据的共同数据。这两个说法都是对的。但是对于SQL来说,寻找不同的索引能极大的提高性能。
mysql> select * from t1 join t2 using(ID) where t1.c=10 and t2.d=20;
执行器
分析器处理了要做什么,优化器处理了要怎么做,最后可以执行SQL语句了。在执行SQL的时候会有一步procheck验证权限的步骤,这一步我估计会有很多人会比较懵,一开始连接不也是校验权限吗。其实这两步的权限是不一样的。一开始是校验用户的大权限,执行器这里验证的是用户中对每个表的操作权限。如果有就开始调用引擎接口,如果没有就返回权限错误。
以下列SQL为例,执行SQL的步骤就是会先捞取表中的第一条数据,并且判断ID是不是为10,如果不是就跳过,继续重复操作一直找到ID为10的数据为止然后返回结果集给客户端
mysql> select * from T where ID=10;
你会在数据库的慢查询日志中看到一个 rows_examined 的字段,表示这个语句执行过程中扫描了多少行。这个值就是在执行器每次调用引擎获取数据行的时候累加的。在有些场景下,执行器调用一次,在引擎内部则扫描了多行,因此引擎扫描行数跟 rows_examined 并不是完全相同的。我们后面会专门有一篇文章来讲存储引擎的内部机制,里面会有详细的说明。
结尾
感谢各位小伙伴看完这篇文章,这篇文章大概介绍了一下SQL的运行过程。是不是又自信了一点呢?
不经一番寒彻骨,怎得梅花扑鼻香,学习是枯燥的请大家坚持!学习群:1076570504














 703
703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









