







首先放一张transformer论文中的模型架构图,transformer架构主要由输入部分(输入序列和目标序列的向量表示与位置编码相加)、N层编码器、N层解码器以及输出部分(输出线性层与softmax层)四大部分组成。
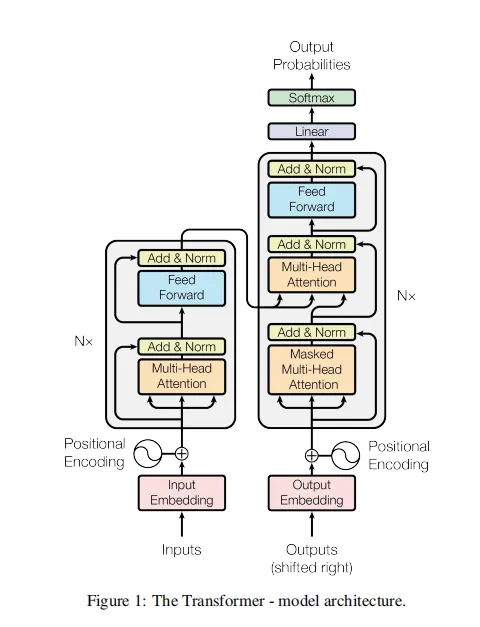
1、输入部分
Input Embedding:输入序列的向量表示
Output Embedding:目标序列的向量表示
Positional Encoding:位置编码,为输入序列的每个位置生成位置向量,以便模型能够理解序列中的位置信息。
2、N层编码器:这N个编码器的结构都是相同的,参数不同。
由N个编码器层堆叠而成。
每个编码器由两个子层连接结构组成:第一个子层是一个全局多头注意力子层,第二个子层是一个前馈全连接子层。每个子层后都接有一个归一化层和一个残差连接。
3、N层解码器:这N个解码器的结构都是相同的,参数不同。
由N个解码器层堆叠而成。
每个解码器层由三个子层连接结构组成:第一个子层是一个带掩码的多头注意力层,第二个子层是一个交叉多头注意力层(连接编码器和解码器),第三个子层是一个前馈全连接子层。每个子层后都接有一个归一化层和一个残差连接。
4、输出部分
线性层:将解码器输出的向量转换为最终的输出维度。
Softmax层:将线性层的输出转换为概率分布,以便进行最终的预测
下面将讨论transformer架构中的重要概念,帮助理解。
1、位置编码
transformer的注意力机制计算可以并行化,但是失去了单词之间的序列关系,不同的序列关系表达的语义不同。位置编码保存了单词在序列中的相对位置或绝对位置,所以将词向量和位置编码相加来作为输入。
位置编码用PE表示,PE的维度与词向量一样。PE可以通过训练得到,也可以使用某种公式计算得到。在Transformer中采用了后者,计算公式如下:
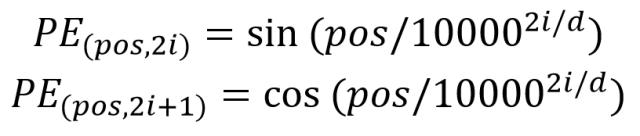
其中,pos表示单词在句子中的位置,d表示PE的维度(与词向量一样),2i表示偶数维度,2i+1表示奇数维度。将单词的词向量和位置编码相加,就可以得到单词的表示向量x,x就是transformer的输入。
2、残差连接和归一化层

其中 X表示 Multi-Head Attention 或者 Feed Forward 的输入,MultiHeadAttention(X) 和 FeedForward(X) 表示输出 (输出与输入 X 维度是一样的,所以可以相加)。
- 残差连接 (Residual Connection):这是指将输入直接加到当前层的输出上,以避免深层网络中梯度消失或爆炸的问题。通过这种连接,信息可以更直接地流过网络,从而加速训练过程。

- 归一化层 (Layer Normalization):归一化层用于规范化每一层的输出,以便加速训练并提高模型的稳定性。在 Transformer 中使用的是层归一化 (LayerNorm),Layer Normalization 会将每一层神经元的输出都转成均值方差都一样的,使得数据的分布保持稳定。
3、前馈神经网络
Feed Forward 层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,对应的公式如下。
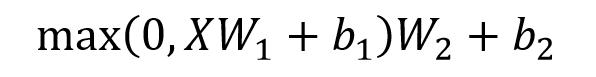
X是输入,Feed Forward 最终得到的输出矩阵的维度与X一致。
4、三种注意力层
在Transformer架构中,有三种不同的注意力层:
编码器中的全局多头注意力层
解码器中的交叉多头注意力层
解码器中的掩码多头注意力层也叫做因果注意力层
如下图所示:
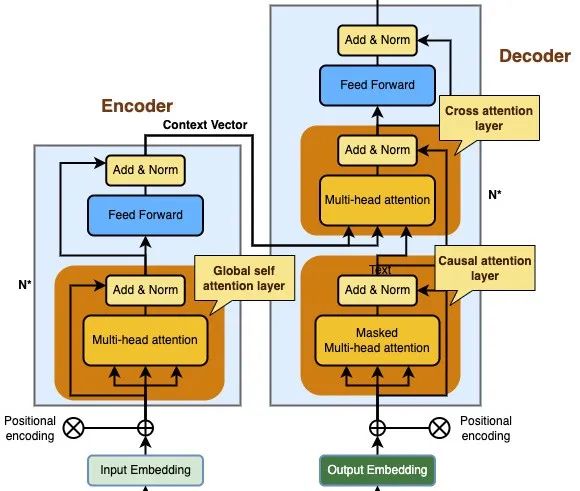
4.1、全局多头注意力层
全局多头注意力层是Transformer编码器的一部分,它的作用是负责计算整个输入序列的注意力向量。
它允许每个序列元素直接访问其他所有序列元素,只需将整个输入序列的向量表示通过线性变化得到Q,K,V矩阵即可,所有注意力向量可以并行计算。
Q=输入序列在查询(Query)空间的投影
K=输入序列在键(Key)空间的投影
V=输入序列在值(Value)空间的投影
4.2、掩码多头注意力层
掩码多头注意力层(Masked Multi-Head Attention)是多头注意力(Multi-Head Attention)的一种变体,目的是为了防止解码器在生成当前输出词时“看到”未来的词。具体来说,它通过掩码(masking)机制来限制注意力机制的计算范围,使得每个位置只能关注其前面的位置(包括当前的位置),而不能看到未来的词。这样,解码器在生成每个词时,始终只能利用已经生成的部分信息。
目的: 掩码多头注意力的关键目的是确保自回归生成过程的因果性(causality)。解码器生成序列时,必须逐步生成每个词,且每次只能依赖已经生成的词,而不能提前“窥探”未来的词。这一约束对于很多任务(如机器翻译和文本生成)非常重要,因为如果解码器能够看到未来的词,就可能导致生成不符合实际顺序的结果,破坏了生成过程的自然性。
掩码操作:
- 在计算注意力得分时,掩码操作会起作用。掩码的目的是确保当前位置不能看到未来的位置。
- 在计算查询和键之间的相似度时,会应用一个上三角矩阵的掩码。这个矩阵的上三角部分会被填充为负无穷(
-∞),而下三角部分(即当前位置及其之前的词)会保留为0。这样,掩码之后的结果经过Softmax时,未来位置的得分会变为零,从而避免了未来词对当前词的影响。
Q=目标序列在查询(Query)空间的投影
K=目标序列在键(Key)空间的投影
V=目标序列在值(Value)空间的投影
4.3、交叉多头注意力层
在Transformer中,交叉注意力层位于字面上的中心位置,它连接了编码器和解码器,是在模型中使用注意力最直接的方式。
要实现这一点,需要将目标序列作为查询,将上下文序列作为键/值传递
Q=解码器中因果注意力层的输出向量在查询(Query)空间的投影
K=编码器的输出向量在键(Key)空间的投影
V=编码器的输出向量在值(Value)空间的投影
5、线性层
Transformer 中的线性层一般指的是一个 全连接层(Fully Connected Layer),它通常用于将模型内部的隐层表示(如来自解码器的输出)转换为实际任务所需的输出空间。
5.1、原理
线性层的核心是一个权重矩阵和一个偏置项。在解码器的输出向量通过线性层时,线性变换会根据权重矩阵对输入向量进行线性映射,公式为:
output=XW+b
其中:
- X 是输入的解码器输出。
- W 是权重矩阵。
- b 是偏置项。
5.2、为什么需要线性层
- 从隐藏层到输出空间: 任务的输出空间(如词汇表大小)通常要大于隐藏层的维度。线性层的作用就是将这些隐藏层的表示转换成模型所需的具体输出(例如,生成词汇分布或预测下一个单词)。
隐藏层维度(hidden_dim):在transformer架构中,隐藏层的维度通常是一个设计超参数。通常它的大小(如512,1024等)是根据任务的复杂性、训练数据的量以及硬件能力等因素来选择的。
输出空间(词汇表大小):对于自然语言处理任务,任务的输出空间通常对应词汇表的大小,例如,翻译任务中的词汇表可能有几千到几万的词。
- 概率分布: 对于生成任务(如翻译、文本生成等),解码器的每个时间步输出一个向量,表示该位置生成某个词的概率。通过线性层的输出,可以得到一个大小为词汇表大小的向量,其中每个元素表示对应词的概率(通常通过 softmax 函数进一步处理得到概率分布)。
6、softmax层
Softmax函数是一种常用的激活函数,通常用于多分类任务的最后一层。它的作用是将一个实数向量转换成概率分布,所有输出的值介于 0 和 1 之间,并且所有输出值的总和为 1。
Softmax的公式如下:
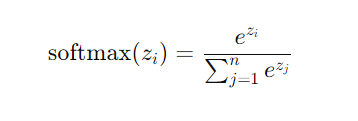
其中:
- zi 是输入向量中的第 i个元素。
- ezi是指数函数(自然对数底 e 的幂)。
- ∑j=1nezj\sum_{j=1}^{n} e^{z_j}∑j=1nezj 是所有输入元素的指数和,其中 n 是输入向量的维度。
解释:
- Softmax 对每个输入值 ziz_izi 计算一个指数值,这样可以确保所有输出值都为正数,并且它们对输入值的相对大小敏感。
- 然后,每个 ziz_izi 被它对应的指数值除以所有输入值的指数和,这样所有的输出值就变成了概率,且概率和为 1。
举个例子:
假设我们有 一个包含 3 个元素的输入向量 z=[2.0,1.0,0.1]。
1、计算每个元素的指数:
e的2.0次方=7.389
e的1.0次方=2.718
e的0.1次方=1.105
2、计算所有指数的总和:
总和=7.389+2.718+1.105=11.212
3、计算softmax输出:
softmax(z1)=7.389/11.212=0.659
softmax(z2)=2.718/11.212=0.243
softmax(z3)=1.105/11.212=0.098
因此softmax输出为:
[0.659,0.243,0.098]
这个输出表示输入向量中的每个元素对应的类别概率,和为1


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









