






希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率;
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位;
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行依次直接插入排序。
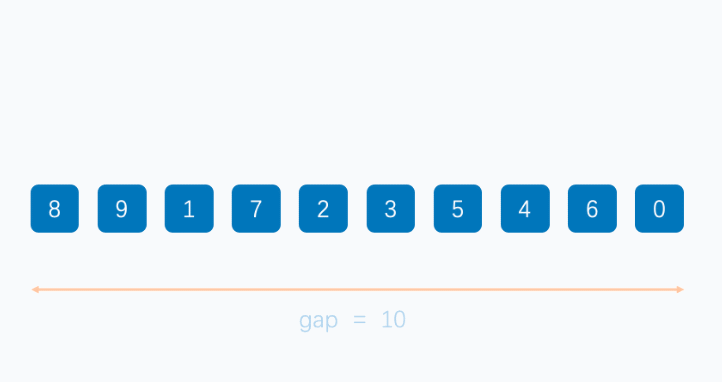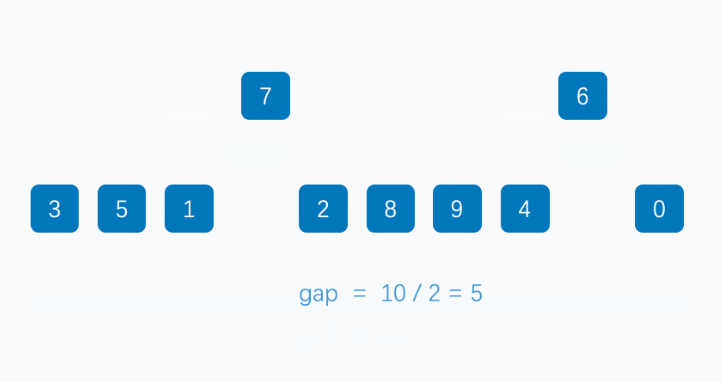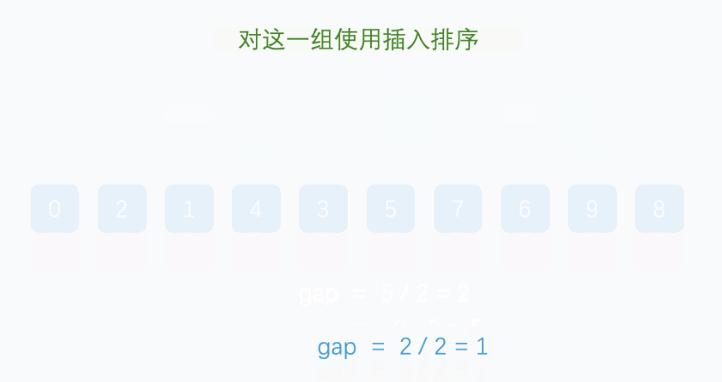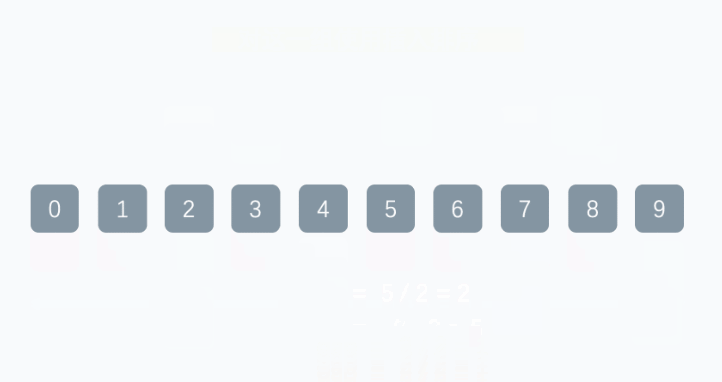
首先是分组:初始分组的间隔(gap)为序列长度的一半,gap依次减半。
gap1=
gap2=()/2=
......
直到gapn=1,此时就是对整个序列进行一次插入排序。图示如下:
每个group分别进行插入排序。
算法思想看图很容易理解,但是在代码实现的时候,踩了不少坑。
代码实现如下:
int shell_sort(int *a, int len) {
int gap=0, i=0, j=0, temp=0;
for (gap = (len / 2); gap > 0; gap /= 2)//用来决定每个gap,gap每个循环减半
{
for (i = gap; i < len; i++)
{
temp = a[i];
for (j = i; j - gap >= 0 && temp < a[j - gap]; j -= gap)
{
a[j] = a[j - gap];
//a[j-gap] = temp;
}
a[j] = temp;
printf("gap=%2d,i=%2d\n",gap,i);
printfFunc(a, len);
printf("\n");
}
}
return 0;
}来解释下每个循环都在干什么:
1、首先,第一个循环,来帮我们决定每一次分组,针对每次不同的gap,我们需要对里面的子序列进行插入排序。
2、第二个循环,其实就是控制序列的下标往后走。
这一步也是我想了很久才明白的。一开始将单纯的将a[0],a[0+gap],a[2*gap]......作为一个子序列来进行排序,导致进入误区。
遍历从gap下标开始,即a[gap],因为对于a[0]-a[gap-1]的序列,都是每个小group的第一个元素,我们让位它是有序的,所以从a[gap]开始遍历。
3、第三个for循环,用 j-gap 来表示同group的上一个元素,根据下标的移动与j-gap的间隔,无形中进行了同group的插入排序。
对于第三个循环外的 a[j] = temp 能不能放到循环里面呢?答案是否定的。
如果要放进循环里面,应当写:a[j-gap] = temp;
否则实现不了交换。
for (j = i; j - gap >= 0 && temp < a[j - gap]; j -= gap)
{
a[j] = a[j - gap];
//a[j-gap] = temp;
}
a[j] = temp;踩坑:(。。。。。。)
以下两个scanf的输入有点区别:
//1
for (auto i = 0; i < DATA_SIZE; i++)
{
scanf_s("%d", arr+i);
}
//2
scanf_s("%d,%d,%d,%d,%d", arr, arr+1, arr+2, arr+3, arr+4);第一种:
5 enter 4 enter........
第二种:
5,4,3,2,1......














 571
571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









