







python使用的编码格式,防止源码中出现中文或其他语言时出现的乱码问题。
#coding:utf-8
在开头定义一些变量,并赋给变量初始值(初始值是自己定义的,可以随项目要求任意赋值)。
# 每条新闻最大长度
MAX_SEQUENCE_LENGTH = 100
# 词向量空间维度
EMBEDDING_DIM = 200
# 验证集比例
VALIDATION_SPLIT = 0.16
# 测试集比例
TEST_SPLIT = 0.2
(1)加载文本
open(‘文件名.txt’,‘r’) .read()读取文本文件,返回的是str字符串;而open(‘文件名.txt’,‘rb’).read()读取二进制文件,返回的是bytes。读取.html文件时使用的是’rb’。
decode()以encoding指定的编码格式解码字符串,默认编码为字符串编码Unicode,Unicode的容量极大,其他的编码几乎都有在上面有映射。open(‘文件名.txt’,‘rb’) .read()输出乱码,需对文本文档进行解码。如下图所示。

split() 通过指定分隔符对字符串进行切片,默认为空字符,包括空格、换行(\n)、制表符(\t)等。此文本文档中为’\n’。
all_texts所有文本由训练文本和测试文本组成;all_labels所有标签由训练标签和测试标签组成。
print('(1) load texts...')
train_texts = open('train_contents.txt', 'rb').read().decode().split('\n')
train_labels = open('train_labels.txt', 'rb').read().decode().split('\n')
test_texts = open('test_contents.txt', 'rb').read().decode().split('\n')
test_labels = open('test_labels.txt', 'rb').read().decode().split('\n')
all_texts = train_texts + test_texts
all_labels = train_labels + test_labels
(2)变量转换
Keras是由纯python编写的基于theano/tensorflow的深度学习框架。keras.preprocessing.text为文本预处理模块,Tokenizer类用于对文本语料进行向量化,将文本中的词语替换为该词在词汇表中的索引。
keras.preprocessing.sequence为序列预处理模块,keras只能接受长度相同的序列输入,pad_sequences函数是将序列转化为经过填充以后的一个长度相同的新序列。
tensorflow.keras.utils为工具模块,to_categorical就是将类别向量转换为二进制(只有0和1)的矩阵类型表示。
numpy用来存储和处理大型矩阵。
print( '(2) doc to var...')
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
import numpy as np
word_index方法将单词(字符串)映射为它们的排名或者索引。


#构建一个tokenizer对象
tokenizer = Tokenizer()
#学习出所有文本的字典
tokenizer.fit_on_texts(all_texts)
#将所有文本转为序列
sequences = tokenizer.texts_to_sequences(all_texts)
#创建单词索引对象
word_index = tokenizer.word_index
#输出单词索引对象的长度
print('Found %s unique tokens.' % len(word_index))
#创建处理好的数据对象data,通过填充pad将序列变为相同长度,maxlen为序列的最大长度,长于此长度则被截断,短于此长度则以pad填充
data = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)
#np.asarray将所有标签(结构数据)转换为ndarray类型,asarray不会copy出新的副本占用内存
labels = to_categorical(np.asarray(all_labels))
#输出data矩阵,labels矩阵的维度大小
print('Shape of data tensor:', data.shape)
print('Shape of label tensor:', labels.shape)
(3)划分数据集
print('(3) split data set...' )
#len(data)date第一维长度,即句子个数,
p1 = int(len(data)*(1-VALIDATION_SPLIT-TEST_SPLIT))
p2 = int(len(data)*(1-TEST_SPLIT))
x_train = data[:p1]
y_train = labels[:p1]
x_val = data[p1:p2]
y_val = labels[p1:p2]
x_test = data[p2:]
y_test = labels[p2:]
print('train docs: '+str(len(x_train)))
print( 'val docs: '+str(len(x_val)))
print ('test docs: '+str(len(x_test)))
(4)训练模型
keras.layers网络层,Dense全连接层(对上一层的神经元进行全部连接,实现特征的非线性组合);input输入层用来初始化;Flatten层把多维的输入一维化,常用在从卷积层到全连接层的过渡;Dropout将在训练过程中每次更新参数时随机断开一定百分比(rate)的输入神经元,用于防止过拟合。
Conv1D一维卷积层,MaxPooling1D一维池化层, Embedding嵌入层将正整数(下标)转换为具有固定大小的向量, GlobalMaxPooling1D一维全局池化层。
keras.models模型模块,Sequential序贯模型是函数式模型的简略版,为最简单的线性、从头到尾的结构顺序,不分叉。
print ('(4) training model...')
from keras.layers import Dense, Input, Flatten, Dropout
from keras.layers import Conv1D, MaxPooling1D, Embedding, GlobalMaxPooling1D
from keras.models import Sequential
#创建model对象
model = Sequential()
#add()方法添加,Embedding()字典长度,即输入数据最大下标+1,设置维度大小和最大长度
model.add(Embedding(len(word_index) + 1, EMBEDDING_DIM, input_length=MAX_SEQUENCE_LENGTH))
#随机断开0.2的输入神经元
model.add(Dropout(0.2))
#250表示输出空间的维度,3表示窗口大小,valid表示不填充,激活函数为relu,步长为1
model.add(Conv1D(250, 3, padding='valid', activation='relu', strides=1))
#最大池化窗口为3
model.add(MaxPooling1D(3))
#Flatten层将2维向量压缩到1维
model.add(Flatten())
#通过两层 Dense(全连接层)将向量长度收缩到 12 上,对应新闻分类的 12 个类(其实只有 11 个类,标签 0 没有用到)Dense()输出空间的维数
model.add(Dense(EMBEDDING_DIM, activation='relu'))
#label.shape[1]为label类别
model.add(Dense(labels.shape[1], activation='softmax'))
#输出模型各层的参数状况
model.summary()
#调用compile方法配置该模型的学习流程,loss损失函数,optimizer优化器,metrics用于监控训练,包含评估模型在训练和测试时的网络性能的指标。
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['acc'])
print (model.metrics_names)
#epoch两轮迭代
model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=2, batch_size=128)
#保存加载模型
model.save('cnn.h5')
(5)测试模型
print ('(5) testing model...')
print (model.evaluate(x_test, y_test))
模型结果:
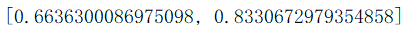
lstm模型代码仅有训练模型处不同
model = Sequential()
model.add(Embedding(len(word_index) + 1, EMBEDDING_DIM, input_length=MAX_SEQUENCE_LENGTH))
model.add(LSTM(200, dropout=0.2, recurrent_dropout=0.2))
model.add(Dropout(0.2))
model.add(Dense(labels.shape[1], activation='softmax'))
model.summary()
模型结果如下:
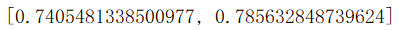















 1491
1491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









