







Text-to-image Diffusion Model文本到图像扩散模型综述
论文地址:https://arxiv.org/pdf/2303.07909.pdf
1.Introduction
Text-to-image模型发展如下图所示:
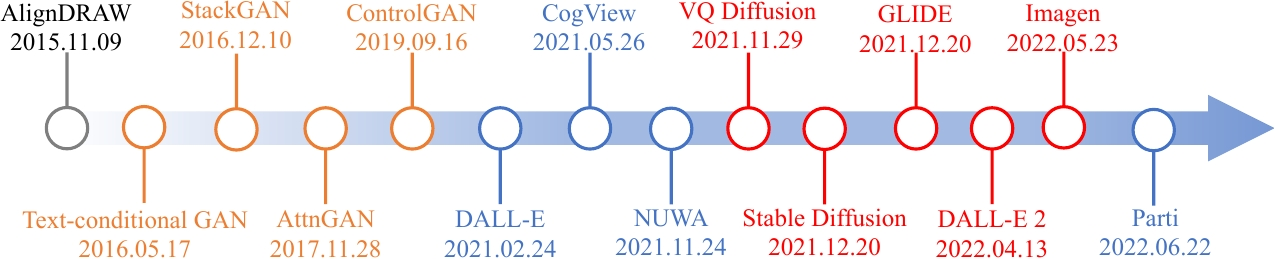
开创性工作:AlignDRAW
小规模数据域--基于Gan的方法(黄色):Text-conditional GAN
大规模数据域–自回归方法(蓝色):DALL-E和Parti。自回归的性质使得这些方法计算成本高且误差累积
最新模型–基于diffusion方法(红色):diffusion model
2.diffusion model
Diffusion models(DMs),也被称为diffusion probabilistic models,是一系列生成模型,是用变分推理训练的马尔可夫链。DM的学习目标是为样本生成保留一个有噪声扰动数据的过程,即扩散过程。
denoising diffusion probabilistic model (DDPM)去噪扩散概率模型出现于2020年,其出现主要归功于两个早期尝试:2019年研究的基于分数的生成模型(score-based generative models,SGM)和早在2015年出现的扩散概率模型(score-based generative models,DPM)。
2.1 扩散概率模型(DPM)
DPM是第一个通过估计将数据映射到简单分布的逆转马尔可夫扩散链来建模概率分布的工作。具体来说,DPM 定义了一个前向(推理)过程,该过程将复杂的数据分布转换为更简单的数据分布,然后通过反转该扩散过程来学习映射。
2.2 基于分数的生成模型(SGM)
SGM提出用各种大小的随机高斯噪声扰动数据,以对数概率密度梯度作为得分函数,生成降低噪声水平的样本,并通过估计噪声数据分布的得分函数来训练模型。
2.3 去噪扩散概率模型(DDPMs)
定义为参数化马尔可夫链,在推理过程中从有限转换的噪声中生成图像。在训练过程中,转换核是在用噪声扰动自然图像的相反方向上学习的,其中噪声被添加到每一步的数据中,并被估计为优化目标。
(1)正向传递(Forward pass)
在前向传递中,DDPM 是一个马尔可夫链,其中高斯噪声在每个步骤中添加到数据中,直到图像被破坏。给定数据分布 x0 ∼ q(x0),DDPM 连续生成 xT 和 q(xt | xt−1)。

其中 T 和 βt 分别是扩散步骤和超参数。为了简单起见,只讨论高斯噪声作为转换核的情况,在等式中表示为 N。
当

可以在任意步骤 t 获得噪声图像,如下所示

(2)反向传递(Reverse pass)
从pθ(T)开始,希望生成的pθ(x0
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4252
4252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









