







二. gStore基础操作(命令行)
2.1 初始化系统数据库
只要下载并编译gStore系统的代码,就会自动创建一个名为system(真实目录名称system.db)的数据库。这是管理系统统计信息的数据库,包括所有用户和所有数据库。您可以使用gquery命令查询此数据库,但禁止使用编辑器对其进行修改。system 数据库为gStore内置的系统数据库,该数据库无法删除,用于保存系统相关信息,尤其是已构建的数据库信息,如果 system 数据库损坏,可能导致 ghttp 无法启动,因此gStore提供了初始化系统数据库功能
命令行模式(ginit)
ginit用于初始化数据库
$ bin/gbuild -db dbname -f filename
命令参数:如果没有写任何的数据库名称,则重新初始化的 system 数据库中将没有其他数据库信息
示例:
$ bin/ginit -db [db_name1],[db_name2],[...]
参数含义:
dbname:数据库名称
filename:带“.nt”或者".n3"后缀的文件所在的文件路径
2.2 创建数据库
创建数据库操作是gStore最重要的操作之一,也是用户安装gStore后需要做的第一个操作,gStore提供
多种方式进行数据库创建操作。
命名行模式(gbuild)
gbuild命令用于从RDF格式文件创建新的数据库,使用方式:
$ bin/gbuild -db dbname -f filename
参数含义:
例如,我们从lubm.nt构建一个名为“lubm2.db”的数据库,可以在数据文件夹中找到。
$ bin/gbuild -db lubm2 -f ./data/lubm/lubm.nt
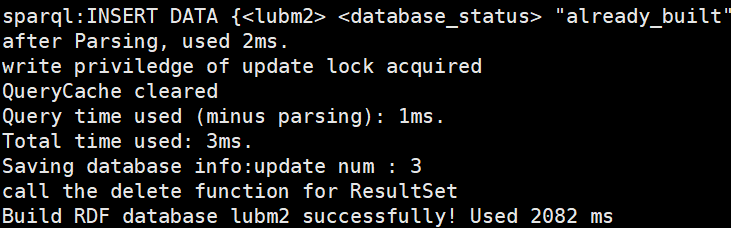
此时说明数据库已经构建完成!
注意: 不能以空的RDF数据集来创建数据库
不能直接 cd 到 bin 目录下,而要在gStore安装根目录执行gbuild操作
使用本地数据创建数据库:
-
首先将数据以RDF的格式写入到以.nt结尾的文件中,如下所示
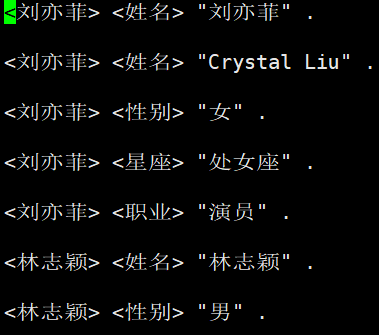
-
采用gbuild命令创建数据库
$ bin/gbuild -db test -f ./data/test/test.nt
2.3 数据库列表
gshow用于获取所有可用数据库列表信息。
$ bin/gshow
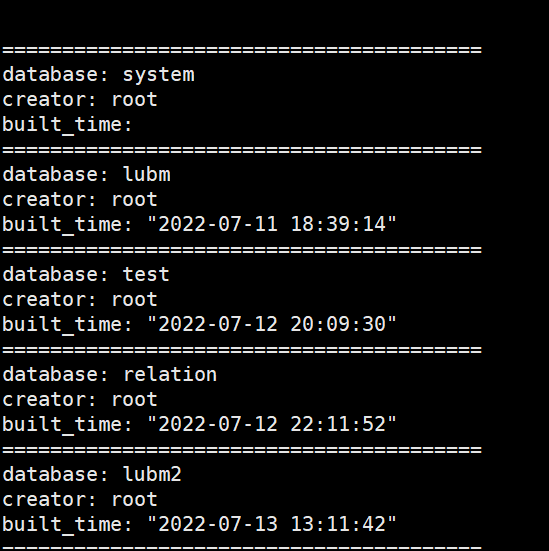
2.4 数据库状态查询
gmonitor用于获取指定数据库的统计信息。
$ bin/gmonitor -db db_name
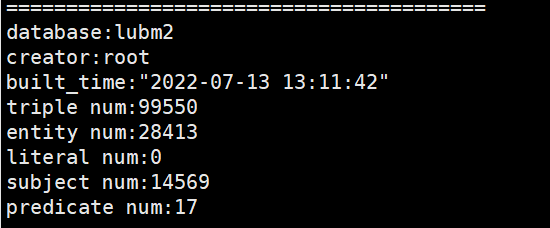
2.5 数据库查询
数据库查询是gStore最重要的功能之一,gStore支持W3C定义的SPARQL 1.1查询语言,用户可以通
过如下几种方式使用gStore数据库查询功能。
命令行模式(gquery)
gquery用于使用包含SPARQL查询的文件查询现有数据库。(每个文件包含一个精确的SPARQL语句,
SPARQL语句不仅可以进行查询操作,还可以进行增加和删除操作)
-
查询名为db_name的数据库,输入以下命令:
bin/gquery -db db_name -q query_file
参数含义:
db_name: 数据库名称
query_file:以“.sql”结尾的SPARQL语句存放的文件路径(其他后缀名也可以)
例如执行:
bin/gquery -db test -q ./data/test/test_q2.sql
得到结果:

-
了解gquery的详细使用,可以输入以下命令进行查看:
bin/gquery --help -
进入gquery控制台命令:
bin/gquery -db dbname-
使用 help 看到所有命令的基本信息
-
输入 quit 以退出gquery控制台。
-
对于 sparql 命令, 使用 sparql query_file 执行SPARQL查询语句,query_file为存放SPARQL语句的文件路径。当程序完成回答查询时,它会再次显示命令提示符。
-
程序显示命令提示符(“gsql>”),也可以在此处输入命令:
-
bin/gquery -db db_name -q query_file
db_name: 数据库名称
query_file:以“.sql”结尾的SPARQL语句存放的文件路径(其他后缀名也可以)
2.6 数据库导出
gexport用于导出某个数据库。
用法:
bin/gexport -db db_name -f path
命令参数:
db_name:数据库名称
path:导出到指定文件夹下(如果为空,则默认导出到gStore根目录下)
删除数据库功能可以删除指定数据库,有如下三种形式
2.6 删除数据库(gdrop)
gdrop用于删除某个数据库。
用法:
$ bin/gdrop -db db_name
命令参数:
db_name:数据库名称
删除数据库,不应该只是输入 rm -r db_name.db 因为这不会更新名为的内置数据库 system 。相
反,你应该输入 bin/gdrop -db db_name 。
插入RDF数据是gStore常规操作,用户可以通过如下几种方式来执行数据插入操作。
2.7 新增数据
命令行模式(gadd)–文件
gadd用于将文件中的三元组插入现有数据库。
用法:
$ bin/gadd -db db_name -f rdf_triple_file_path
参数含义:
db_name:数据库名称
rdf_triple_file_path:带".nt"或者".n3"后缀的文件路径
注意:
gadd主要用于RDF文件数据插入
不能直接 cd 到 bin 目录下,而要在gStore安装根目录执行 gadd 操作
命令行模式(gquery)—SPARQL语句
SPARQL定义中可以通过 insert data 指令来实现数据插入,基于此原理,用户也可以通过编写
SPARQL插入语句,然后使用gStore的 gquery 工具来实现数据插入,其中SPARQL插入语句示例如下:
insert data {
<张三> <性别> "男"^^<http://www.w3.org/2001/XMLSchema#String>.
<张三> <年龄> "28"^^<http://www.w3.org/2001/XMLSchema#Int>.
<张三> <好友> <李四>.
}
通过 {} 可以包含多条RDF数据,注意每条RDF数据都要以 . 结尾
由于可以使用数据库查询功能实现数据插入,因此也同样可以使用如下功能来进行数据插入。
2.8 删除数据
命令行模式(gsub)–文件删除
gsub用于从现有数据库中删除文件中的三元组。
用法:
bin/gsub db_name rdf_triple_file_path
参数含义:
rdf_triple_file_path:带".nt"或者以“.n3"后缀的所要删除的数据文件路径
命令行模式(gquery)—SPARQL语句
SPARQL定义中可以通过 delete data 指令来实现数据插入,基于此原理,用户也可以通过编写
SPARQL插入语句,然后使用gStore的 gquery 工具来实现数据插入,其中SPARQL插入语句示例如下:
delete data {
<张三> <性别> "男"^^<http://www.w3.org/2001/XMLSchema#String>.
<张三> <年龄> "28"^^<http://www.w3.org/2001/XMLSchema#Int>.
<张三> <好友> <李四>.
}
通过 {} 可以包含多条RDF数据,注意每条RDF数据都要以 . 结尾
另外SPARQL中还可以通过 delete where 语句来实现根据子查询结构删除数据,如下所示。
delete where
{
<张三> ?x ?y.
}
该语句表示删除 张三 实体的所有信息(包括属性和关系)
由于可以使用数据库查询功能实现数据插入,因此也同样可以使用如下功能来进行数据插入。
2.9 高级环路查询
查询是否存在包含结点 u 和 v 的一个环。
cyclePath(u, v, directed, pred_set)
cycleBoolean(u, v, directed, pred_set)
用于 SELECT 语句中,与聚合函数使用语法相同。
参数:
u , v :变量或结点 IRI
directed :布尔值,为真表示有向,为假表示无向(图中所有边视为双向)
pred_set :构成环的边上允许出现的谓词集合。若设置为空 {} ,则表示允许出现数据中的所有谓词
返回值
cyclePath :以 JSON 形式返回包含结点 u 和 v 的一个环(若存在)。若 u 或 v 为变量,对
变量的每组有效值返回一个环。
cycleBoolean :若存在包含结点 u 和 v 的一个环,返回真;否则,返回假。
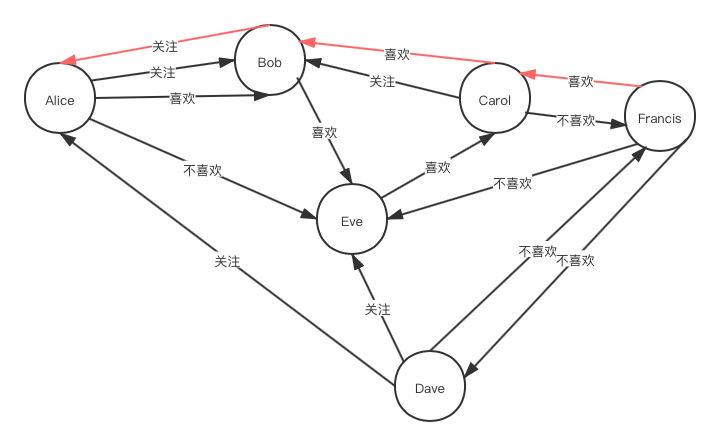
下面的查询询问是否存在包含 Carol 、一个 Francis 不喜欢的人(示例数据中即为 Dave 或 Eve ),且
构成它的边只能由“喜欢”关系标记的有向环:
结果如下:

如果希望输出一个满足以上条件的环,则使用下面的查询:
SELECT (cyclePath(?x, <Carol>, true, {<喜欢>}) as ?y)
WHERE
{
<Francis> <不喜欢> ?x .
}
结果如下,可见其中一个满足条件的环由 Eve 喜欢 Carol - Carol 喜欢 Bob - Bob 喜欢 Eve 顺次构成:
(为方便阅读,省略了字符串最外层的双引号和内部双引号的转义)
{ "paths":
[
{ "src":"<Eve>", "dst":"<Carol>", "edges":
[{"fromNode":2,"toNode":3,"predIRI":"<喜欢>"}, {"fromNode":3,"toNode":1,"predIRI":"<喜欢>"},{"fromNode":1,"toNode":2,"predIRI":" <喜欢>"}], "nodes": [{"nodeIndex":1,"nodeIRI":"<Bob>"},{"nodeIndex":3,"nodeIRI":"<Carol>"}, {"nodeIndex":2,"nodeIRI":"<Eve>"}]
}
]
}
若使用命令行测试上述sparql语句,得不到json答案,因此开启ghttp服务,使用接口测试工具测试环路查询结果。
-
cyclePath查询结果

-
cycleBoolean查询结果

最短路径查询
查询从结点 u 到结点 v 的最短路径。
shortestPath(u, v, directed, pred_set)
shortestPathLen(u, v, directed, pred_set)
用于 SELECT 语句中,与聚合函数使用语法相同。
参数
u , v :变量或结点 IRI
directed :布尔值,为真表示有向,为假表示无向(图中所有边视为双向)
pred_set :构成最短路径的边上允许出现的谓词集合。若设置为空 {} ,则表示允许出现数据中的所
有谓词
返回值
shortestPath :以 JSON 形式返回从结点 u 到 v 的一条最短路径(若可达)。若 u 或 v 为
变量,对变量的每组有效值返回一条最短路径。
shortestPathLen :返回从结点 u 到 v 的最短路径长度(若可达)。若 u 或 v 为变量,对变
量的每组有效值返回一个最短路径长度数值。
下面的查询返回从 Francis 到一个 Bob 喜欢、关注或不喜欢,且没有被 Francis 不喜欢的人(示例数据
中即为 Alice)的最短路径,边上的关系可以是喜欢或关注
SELECT (shortestPath(<Francis>, ?x, true, {<喜欢>, <关注>}) AS ?y)WHERE{ <Bob> ?pred ?x . MINUS { <Francis> <不喜欢> ?x . }}
结果如下:(为方便阅读,省略了字符串最外层的双引号和内部双引号的转义)
{ "paths":[{ "src":"<Francis>", "dst":"<Alice>", "edges": [{"fromNode":4,"toNode":3,"predIRI":"<喜欢>"}, {"fromNode":3,"toNode":1,"predIRI":"<喜欢>"},{"fromNode":1,"toNode":0,"predIRI":" <关注>"}], "nodes": [{"nodeIndex":0,"nodeIRI":"<Alice>"}, {"nodeIndex":1,"nodeIRI":"<Bob>"},{"nodeIndex":3,"nodeIRI":"<Carol>"}, {"nodeIndex":4,"nodeIRI":"<Francis>"}] }]}
如果希望只输出最短路径长度,则使用下面的查询:
SELECT (shortestPathLen(<Francis>, ?x, true, {<喜欢>, <关注>}) AS ?y)WHERE{ <Bob> ?pred ?x . MINUS { <Francis> <不喜欢> ?x . }}
结果如下:(为方便阅读,省略了字符串最外层的双引号和内部双引号的转义)
{"paths":[{"src":"<Francis>","dst":"<Alice>","length":3}]}
若使用命令行测试上述sparql语句,得不到json答案,因此开启ghttp服务,使用接口测试工具测试环路查询结果。
-
shortestPath查询结果

-
shortestPathLen查询结果

2.10 可达性 / K 跳可达性查询
查询从结点 u 到结点 v 是否可达 / 是否 K 跳可达(即存在以 u 为起点、以 v 为终点,长度小于或等
于 K 的路径)。
kHopReachable(u, v, directed, k, pred_set)kHopReachablePath(u, v, directed, k, pred_set)
参数
u , v :变量或结点 IRI
k :若置为非负整数,则为路径长度上限(查询 K 跳可达性);若置为负数,则查询可达性
directed :布尔值,为真表示有向,为假表示无向(图中所有边视为双向)
pred_set :构成路径的边上允许出现的谓词集合。若设置为空 {} ,则表示允许出现数据中的所有谓
词
返回值
kHopReachable :若从结点 u 到结点 v 可达(或 K 跳可达,取决于参数 k 的取值),返回真;
否则,返回假。若 u 或 v 为变量,对变量的每组有效值返回一个真/假值。
kHopReachablePath :返回任意一条从结点 u 到结点 v 的路径(若可达)或K跳路径,即长度
小于或等于 k 的路径(若K跳可达,取决于参数 k 的取值)。若 u 或 v 为变量,对变量的每组有
效值返回一条路径(若可达)或K跳路径(若K跳可达)。
示例查询:起点为 Francis ,终点为一个 Bob 喜欢、关注或不喜欢,且没有被 Francis 不喜欢的人(示例数据中即为 Alice)。询问这两人之间是否通过喜欢或关注关系 2 跳或以内可达。
SELECT(kHopReachable(<Francis>,?x,true,2,{<喜欢>,<关注>}) as ?y)
where
{
<Bob> ?pred ?x .
minus {<Francis> <不喜欢> ?x .}
}
满足已知条件的最短路径为3:结果为false
接口返回结果如下:

另一方面,Francis 和 Alice 之间是可达的,只是最短路径长度超出了上述限制。因此若查询可达性(将
k 设置为负数),则会返回真:
SELECT(kHopReachable(<Francis>,?x,true,-1,{<喜欢>,<关注>}) as ?y)
where
{
<Bob> ?pred ?x .
minus {<Francis> <不喜欢> ?x .}
}

若希望返回一条两人之间满足条件的路径,则可以调用 kHopReachablePath 函数:
SELECT(kHopReachablePath(<Francis>,?x,true,-1,{<喜欢>,<关注>}) as ?y)
where
{
<Bob> ?pred ?x .
minus {<Francis> <不喜欢> ?x .}
}
此时结果可能为上述最短路径:
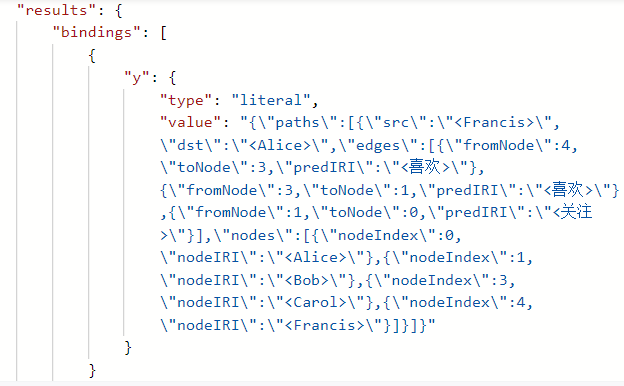














 145
145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









