







6.Storm 集成kafka
-
LineSplitBolt 做语句切分的Bolt
package com.gcc.kafkawordcount; import org.apache.storm.topology.BasicOutputCollector; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseBasicBolt; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; public class LineSplitBolt extends BaseBasicBolt { /** * 处理数据的业务逻辑 * 切分每行的数据 * @param input * @param collector */ @Override public void execute(Tuple input, BasicOutputCollector collector) { //首先获取到一行数据 String line =input.getString(0); System.out.println("LineSplitBolt.execute----"+line); //对line进行切分 if(line!=null&&line.length()>0){ //开始切分 String []words=line.split(" "); //将切分之后的单词发送到下一个Bolt for (String word : words) { //继续向后传递信息 collector.emit(new Values(word)); } } } /** * 如果需要向下传递数据,需要提前定义数据格式 * @param declarer */ @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); } } -
OuputBolt:对切分后的单词进行统计
package com.gcc.kafkawordcount; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.BasicOutputCollector; import org.apache.storm.topology.IRichBolt; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseBasicBolt; import org.apache.storm.tuple.Tuple; import java.util.HashMap; import java.util.Map; public class OuputBolt extends BaseBasicBolt { //声明一个容器 存在以前的统计结果 private Map<String,Integer> map=new HashMap<>(); @Override public void execute(Tuple input, BasicOutputCollector collector) { //获取单词 String word=input.getStringByField("word"); //判断这个单词是否统计过 if(map.containsKey(word)){ //最新统计数量 int count=map.get(word); count++; //重新设置到map map.put(word,count); }else{ map.put(word,1); } System.out.println("OutBolt本次执行完:"+this+"单词【"+word+"】数量【"+map.get(word)+"]"); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { } } -
Topology 其中包含连接zookeeper配置,以及Spout使用了kafka的Spout,从kafka的主题上消费数据
package com.gcc.kafkawordcount; import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.StormSubmitter; import org.apache.storm.generated.AlreadyAliveException; import org.apache.storm.generated.AuthorizationException; import org.apache.storm.generated.InvalidTopologyException; import org.apache.storm.generated.StormTopology; import org.apache.storm.kafka.*; import org.apache.storm.spout.SchemeAsMultiScheme; import org.apache.storm.topology.TopologyBuilder; import org.apache.curator.framework.CuratorFrameworkFactory; import java.util.UUID; public class WordCountTopology { public static void main(String[] args){ // zookeeper连接串 String zkConnString = "hadoop102:2181,hadoop103:2181,hadoop104:2181"; // 连接broker BrokerHosts hosts = new ZkHosts(zkConnString); // kafka主题 String topicName = "wordCountTopic"; // 准备spout配置 SpoutConfig spoutConfig = new SpoutConfig(hosts, topicName, "/" + topicName, UUID.randomUUID().toString()); spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme()); // kafkaSpout KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig); // 准备topology TopologyBuilder builder = new TopologyBuilder(); // 设置选择spout builder.setSpout("kafkaSpout", kafkaSpout); // 设置选择bolt builder.setBolt("LineSplitBolt", new LineSplitBolt()).shuffleGrouping("kafkaSpout"); builder.setBolt("outBolt", new OuputBolt()).shuffleGrouping("LineSplitBolt"); Config config = new Config(); StormTopology topology = builder.createTopology(); if(args.length>0){ try { StormSubmitter.submitTopology(args[0],config,topology); } catch (AlreadyAliveException e) { e.printStackTrace(); } catch (InvalidTopologyException e) { e.printStackTrace(); } catch (AuthorizationException e) { e.printStackTrace(); } }else{ //本地模式启动集群 LocalCluster localCluster = new LocalCluster(); localCluster.submitTopology("storm-kafka",config,topology); } } }-
程序运行步骤:
1.使用脚本或命令行 启动zookeeper
2.启动storm
3.使用脚本或者命令行启动kafka
4.Kafka上创建主题wordCountTopic
bin/kafka-topics.sh --zookeeper hadoop102:2181 hadoop103:2181 hadoop104:2181 --create --replication-factor 1 --partitions 1 --topic wordCountTopic5.启动kafka生产者,可以实时产生消息
bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic wordCountTopic6.可以在IDEA上使用本地集群模式启动
-
-
同样可以将程序打成jar包,在服务器上运行,但是在服务器上运行storm集成kafka项目中遇到问题:
问题1 :
java.lang.NoClassDefFoundError: org/json/simple/JSONValue
说明这个类的声明找不到,也就是相关的依赖打包时没有添加进来,本人没找到原因,因此手动找到相关依赖的jar包,将其添加到storm安装目录的lib目录下。
每次运行都发现了相关的依赖包没添加,将其添加到lib目录。
问题2 :
Caused by: java.lang.NoClassDefFoundError: Could not initialize class org.apache.log4j.Log4jLoggerFactoryog4j-over-slf4j.jar 和 slf4j-log4j12.jar 在同一个classpath下就会出现这个错误。使用
<exclusions>将slf4j-log4j12.jar从相关的jar中移除。问题3:
java.lang.NoClassDefFoundError: org/apache/curator/connection/ConnectionHandlingPolicy
在storm的lib目录下已经有curator依赖,但是仍然报错,寻找IDEA相关类,发现ConnectionHandlingPolicy的curator的版本位4.0.1,而lib目录下是2.x,说明版本过低,有些类缺失了,修改版本。注意在修改curator-framework的版本的时候,里面包含两个jar包,不要导成了-resource的jar包
问题4:
Caused by: org.apache.zookeeper.KeeperException$UnimplementedException:
这个问题解决了很久,最后发现,storm-kafka中依赖的zookeeper版本是3.4.14,但是在lib目录下,我引入的zookeeper版本是3.5.7,版本不对,导致zookeeper启动错误。因此将storm的lib目录下的zookeeper改成3.4.14.
最后,示例代码运行成功
在kafka的生产者上实时输入句子:以空格分割,storm程序可以将其读取并统计单词个数。
kafka生产者:

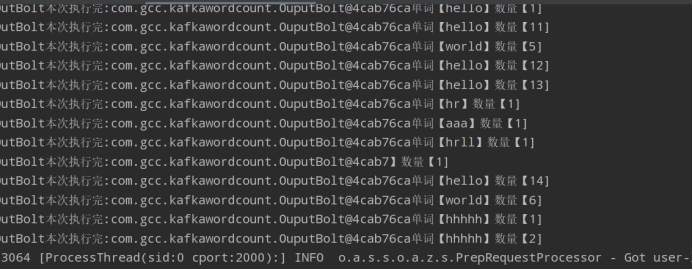
统计结果:
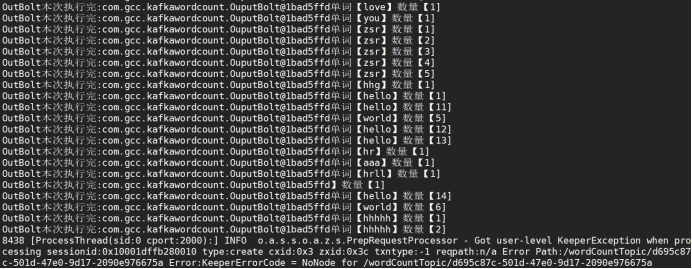















 373
373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









