







介绍
今天接上文,来实现一个Storm数据流处理综合案例的第二部分,Storm集群向Kafka集群源源不断读取数据,通过MyBatis写入到MySQL数据库,并部署为远程模式
准备工作
代码编写
思路:Storm集群从Kafkatopic主题获取数据,解析后写入MySQL,注意我们使用MyBatis工具与数据库交互
项目结构
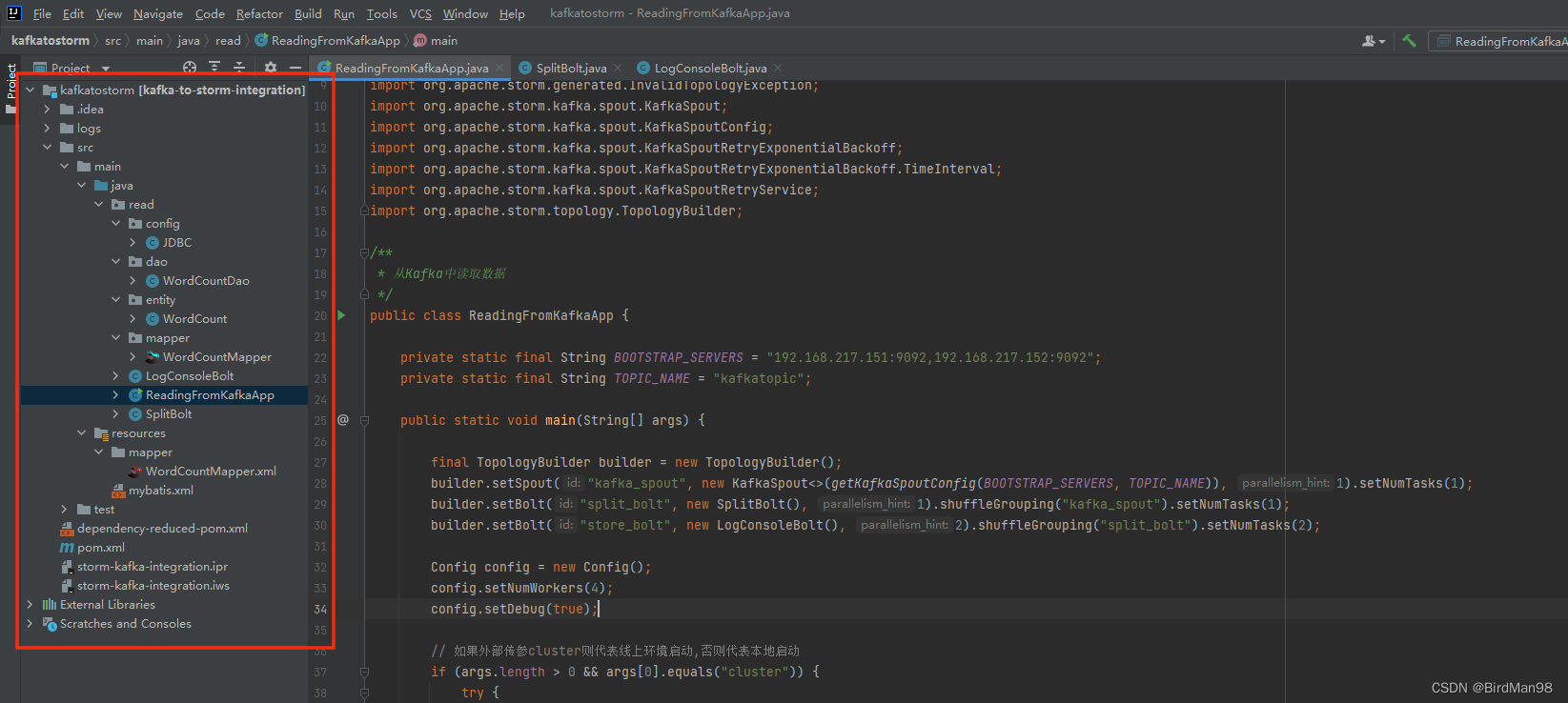
项目文件
POM
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.zj</groupId>
<artifactId>kafka-to-storm-integration</artifactId>
<version>1.0</version>
<properties>
<storm.version>1.2.2</storm.version>
<kafka.version>2.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>${storm.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>4.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.2</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
<!--使用shade进行打包-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<configuration>
<createDependencyReducedPom>true</createDependencyReducedPom>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.sf</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.dsa</exclude>
<exclude>META-INF/*.RSA</exclude>
<exclude>META-INF/*.rsa</exclude>
<exclude>META-INF/*.EC</exclude>
<exclude>META-INF/*.ec</exclude>
<exclude>META-INF/MSFTSIG.SF</exclude>
<exclude>META-INF/MSFTSIG.RSA</exclude>
</excludes>
</filter>
</filters>
<artifactSet>
<excludes>
<exclude>org.apache.storm:storm-core</exclude>
</excludes>
</artifactSet>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Topology
package read;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.kafka.spout.KafkaSpout;
import org.apache.storm.kafka.spout.KafkaSpoutConfig;
import org.apache.storm.kafka.spout.KafkaSpoutRetryExponentialBackoff;
import org.apache.storm.kafka.spout.KafkaSpoutRetryExponentialBackoff.TimeInterval;
import org.apache.storm.kafka.spout.KafkaSpoutRetryService;
import org.apache.storm.topology.TopologyBuilder;
/**
* 从Kafka中读取数据
*/
public class ReadingFromKafkaApp {
private static final String BOOTSTRAP_SERVERS = "192.168.217.151:9092,192.168.217.152:9092";
private static final String TOPIC_NAME = "kafkatopic";
public static void main(String[] args) {
final TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka_spout", new KafkaSpout<>(getKafkaSpoutConfig(BOOTSTRAP_SERVERS, TOPIC_NAME)), 1).setNumTasks(1);
builder.setBolt("split_bolt", new SplitBolt(), 1).shuffleGrouping("kafka_spout").setNumTasks(1);
builder.setBolt("stat_store_bolt", new StatAndStoreBolt(), 2).shuffleGrouping("split_bolt").setNumTasks(2);
Config config = new Config();
config.setNumWorkers(4);
config.setDebug(true);
// 如果外部传参cluster则代表线上环境启动,否则代表本地启动
if (args.length > 0 && args[0].equals("cluster")) {
try {
StormSubmitter.submitTopology("StormClusterReadingFromKafkaClusterApp", config, builder.createTopology());
} catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) {
e.printStackTrace();
}
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LocalReadingFromKafkaApp",
config, builder.createTopology());
}
}
private static KafkaSpoutConfig<String, String> getKafkaSpoutConfig(String bootstrapServers, String topic) {
return KafkaSpoutConfig.builder(bootstrapServers, topic)
// 除了分组ID,以下配置都是可选的。分组ID必须指定,否则会抛出InvalidGroupIdException异常
.setProp(ConsumerConfig.GROUP_ID_CONFIG, "kafkaSpoutTestGroup")
.setProp(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG, 200)
// 定义重试策略
.setRetry(getRetryService())
// 定时提交偏移量的时间间隔,默认是15s
.setOffsetCommitPeriodMs(10000)
.setFirstPollOffsetStrategy(KafkaSpoutConfig.FirstPollOffsetStrategy.LATEST)
.setMaxUncommittedOffsets(200)
.build();
}
// 定义重试策略
private static KafkaSpoutRetryService getRetryService() {
return new KafkaSpoutRetryExponentialBackoff(TimeInterval.microSeconds(500),
TimeInterval.milliSeconds(2), Integer.MAX_VALUE, TimeInterval.seconds(10));
}
}
SplitBolt
package read;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.HashMap;
import java.util.Map;
/**
* 切分从Kafka获取的数据
*/
public class SplitBolt extends BaseRichBolt {
private OutputCollector collector;
private String[] words;
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple tuple) {
try {
String line = tuple.getStringByField("value");
System.out.println("received from kafka : " + line);
words = line.split("\t");
for(String word : words){
collector.emit(new Values(word));
}
// 必须ack,否则会重复消费kafka中的消息
collector.ack(tuple);
} catch (Exception e) {
e.printStackTrace();
collector.fail(tuple);
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
StatAndStoreBolt
该Bolt通过MyBatis将处理好的数据写入到MySQL中,其中每10秒将数据写入一次数据库
package read;
import lombok.SneakyThrows;
import org.apache.storm.shade.org.apache.commons.collections.MapUtils;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import read.dao.WordCountDao;
import read.entity.WordCount;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 打印从Kafka中获取的数据并实时写入到MySQL
*/
public class StatAndStoreBolt extends BaseRichBolt {
Map<String, Integer> counters;
private OutputCollector collector;
// 记录最初时间
private long begin = System.currentTimeMillis();
@SneakyThrows
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.counters = new HashMap<String, Integer>();
this.collector = collector;
}
@SneakyThrows
public void execute(Tuple tuple) {
long cost = System.currentTimeMillis();
// 每10秒写一次数据库
if (cost - begin > 10000 && MapUtils.isNotEmpty(counters)) {
System.err.println(counters);
updateWordCount(counters);
// 重置最初时间
begin = System.currentTimeMillis();
}
try {
String word = tuple.getStringByField("word");
//计数
if(!counters.containsKey(word)){
counters.put(word, 1);
}else{
Integer c = counters.get(word) + 1;
counters.put(word, c);
}
// 必须ack,否则会重复消费kafka中的消息
collector.ack(tuple);
} catch (Exception e) {
e.printStackTrace();
collector.fail(tuple);
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
public void updateWordCount(Map<String, Integer> counters) {
List<WordCount> wordCounts = new ArrayList<>();
for (Map.Entry<String, Integer> item : counters.entrySet()) {
WordCount wc = new WordCount();
wc.setWord(item.getKey());
wc.setCount(item.getValue());
wordCounts.add(wc);
}
WordCountDao.saveOrUpdateBatch(wordCounts);
}
}
部署MySQL
我们在服务器上部署一台MySQL数据库
数据库表结构如下:
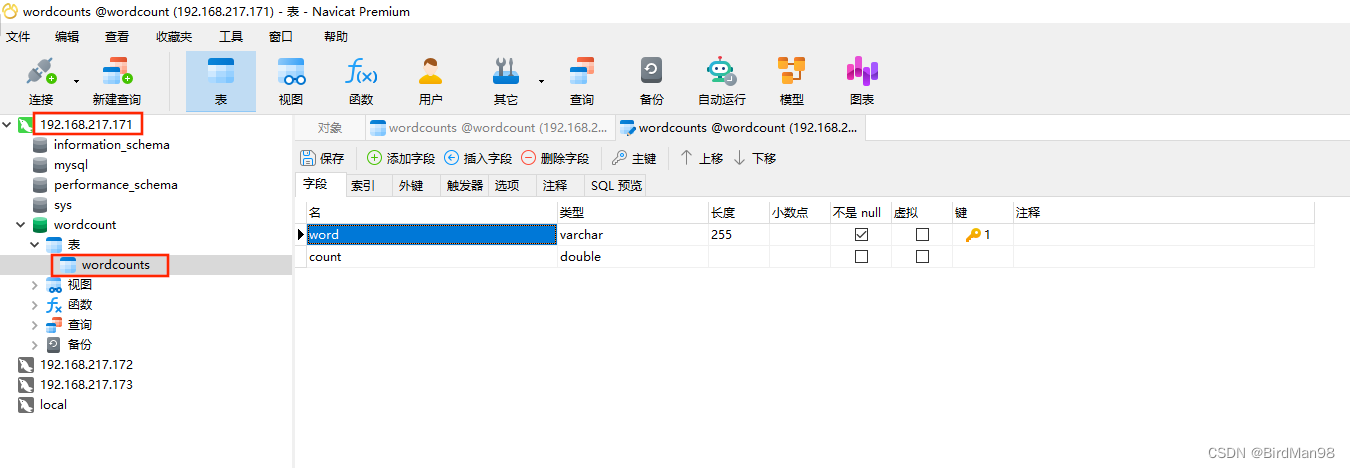
整合MyBatis
mybatis.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="mysql">
<environment id="mysql">
<!--配置事务管理器 -->
<transactionManager type="JDBC"></transactionManager>
<!-- 配置数据源-->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://192.168.217.171:3306/wordcount?useSSL=false&useUnicode=true&characterEncoding=utf8&
serverTimezone=Asia/Shanghai"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<!--指明映射文件的位置。-->
<mappers>
<mapper resource="mapper/WordCountMapper.xml"></mapper>
</mappers>
</configuration>
SqlSessionConfig
该配置类会读取mybatis.xml文件获取相应的配置信息,生成SqlSessionFactory工厂
package read.config;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.IOException;
import java.io.Reader;
public class SqlSessionConfig {
public static SqlSessionFactory GetConn() {
Reader reader = null;
try {
reader = Resources.getResourceAsReader("mybatis.xml");
return new SqlSessionFactoryBuilder().build(reader);
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
WordCountMapper
该接口定义了MyBatis访问数据库的接口方法
package read.mapper;
import org.apache.ibatis.annotations.Param;
import read.entity.WordCount;
import java.util.List;
public interface WordCountMapper {
List<WordCount> selectAll();
void saveOrUpdateBatch(@Param("wordCountList") List<WordCount> wordCountList);
}
WordCountDao
该类会获取SqlSessionConfig配置类的SqlSessionFactory和WordCountMapper的接口方法,生成具体与数据库交互的Session
package read.dao;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import read.config.SqlSessionConfig;
import read.entity.WordCount;
import read.mapper.WordCountMapper;
import java.util.List;
public class WordCountDao {
/**
* 获取所有查询信息
* @return
*/
public static List<WordCount> selectAll(){
SqlSessionFactory factory = SqlSessionConfig.GetConn();
SqlSession session = factory.openSession();
WordCountMapper db = session.getMapper(WordCountMapper.class);
List<WordCount> list = db.selectAll();
session.commit();
session.close();
return list;
}
/**
* 批量更新或插入
* @param wordCountList
*/
public static void saveOrUpdateBatch(List<WordCount> wordCountList) {
SqlSessionFactory factory = SqlSessionConfig.GetConn();
SqlSession session = factory.openSession();
WordCountMapper db = session.getMapper(WordCountMapper.class);
db.saveOrUpdateBatch(wordCountList);
session.commit();
session.close();
}
}
WordCountMapper.xml
该文件为MyBatis编写与数据库交互的具体SQL代码的地方
具体实现了全量查询和批量更新或插入的接口功能
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace:命名空间。目前取值没有要求,建议取当前文件的完整路径名,省略xml-->
<mapper namespace="read.mapper.WordCountMapper">
<select id="selectAll" resultType="read.entity.WordCount">
select * from wordcounts
</select>
<insert id="saveOrUpdateBatch" parameterType="list">
insert into wordcounts (`word`, `count`) values
<foreach collection="wordCountList" item="item" index="index" separator=",">
(#{item.word},#{item.count})
</foreach>
ON DUPLICATE KEY UPDATE
`word` = values(`word`),
`count` = values(`count`)
</insert>
</mapper>
远程部署
打包
使用shade打包
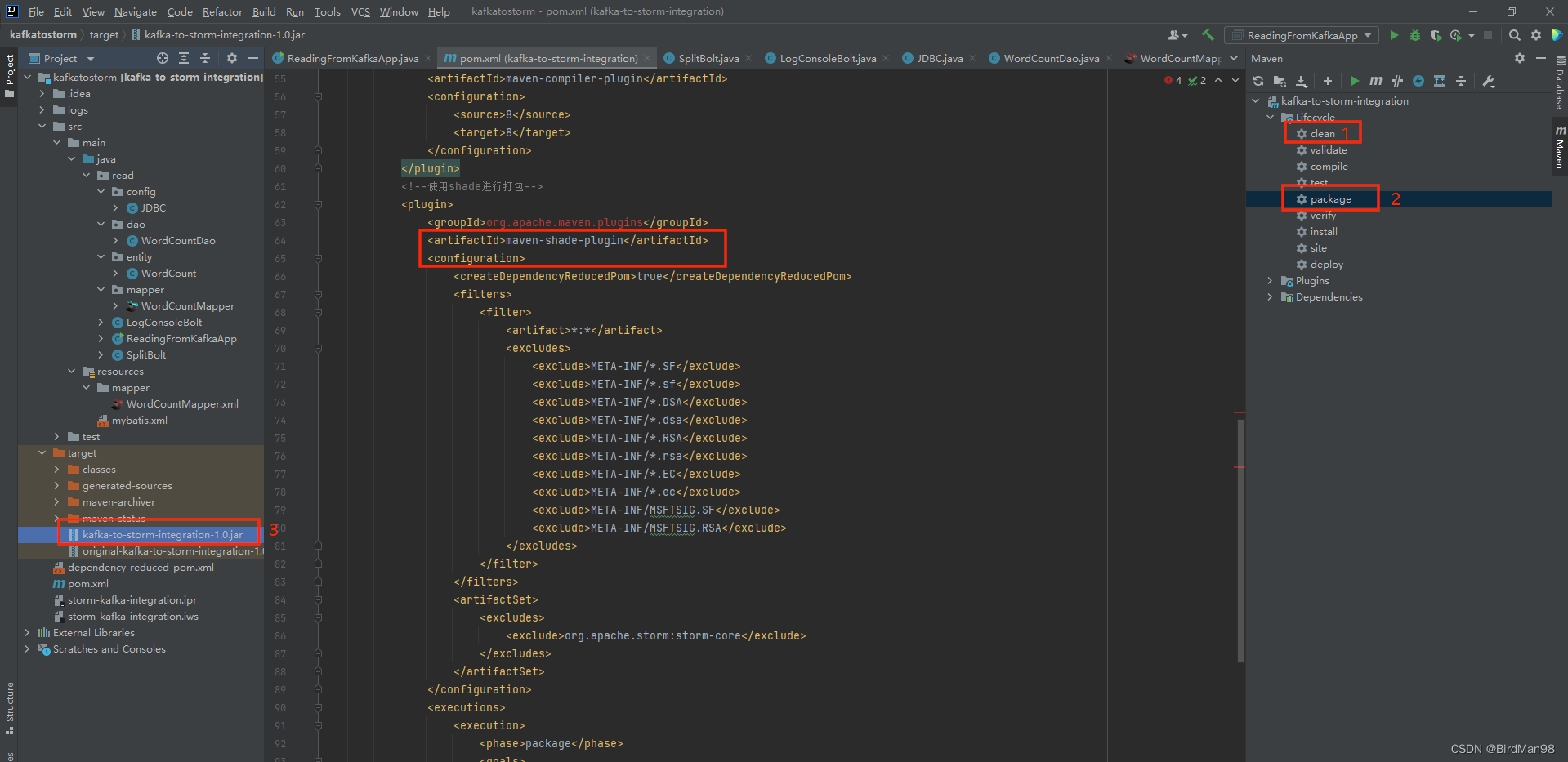
上传文件
文件只需上传到Nimbus节点即可
使用Nimbus节点启动Topology
storm jar kafka-to-storm-integration-1.0.jar read.ReadingFromKafkaApp cluster
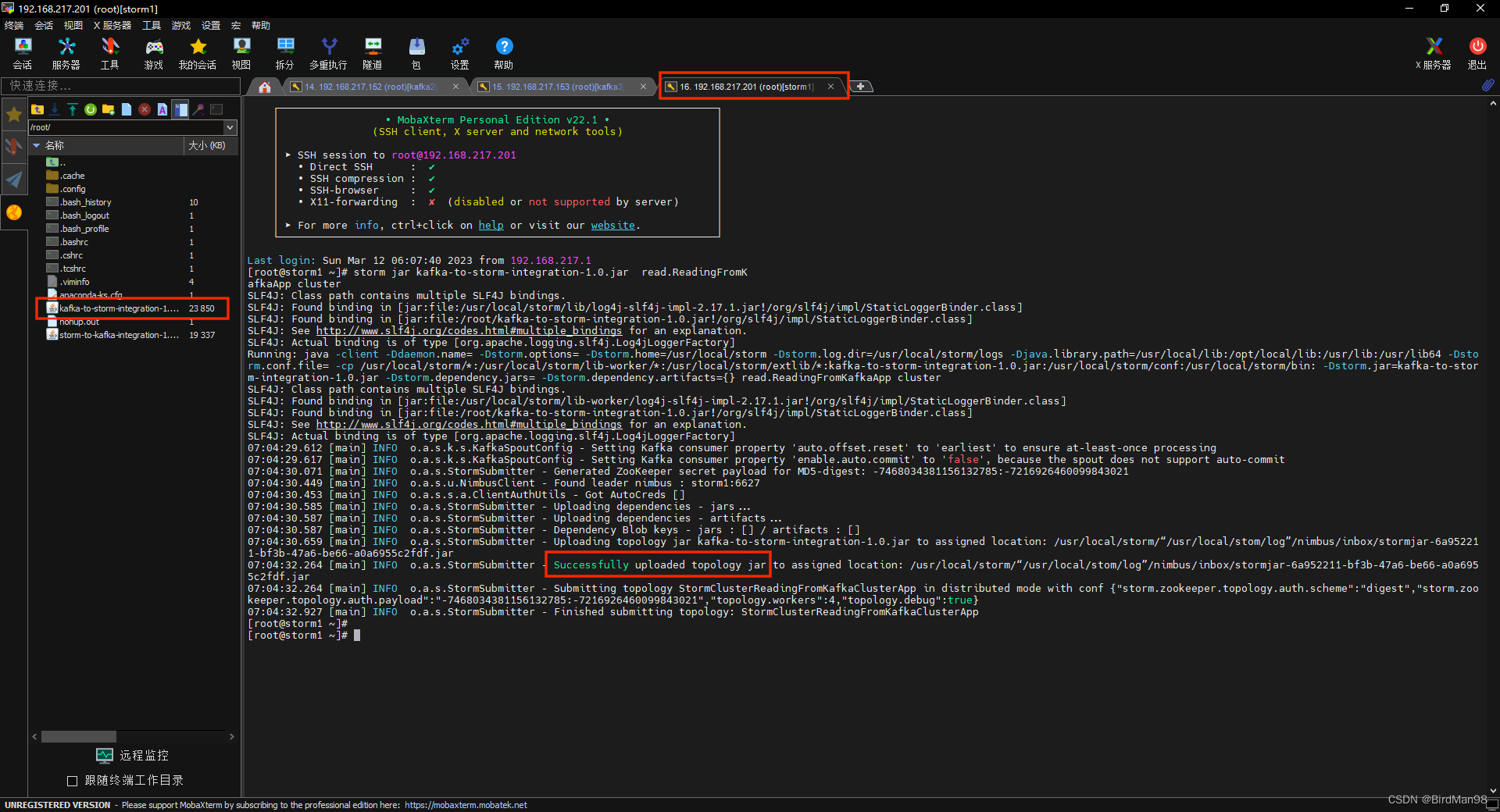
UI查看
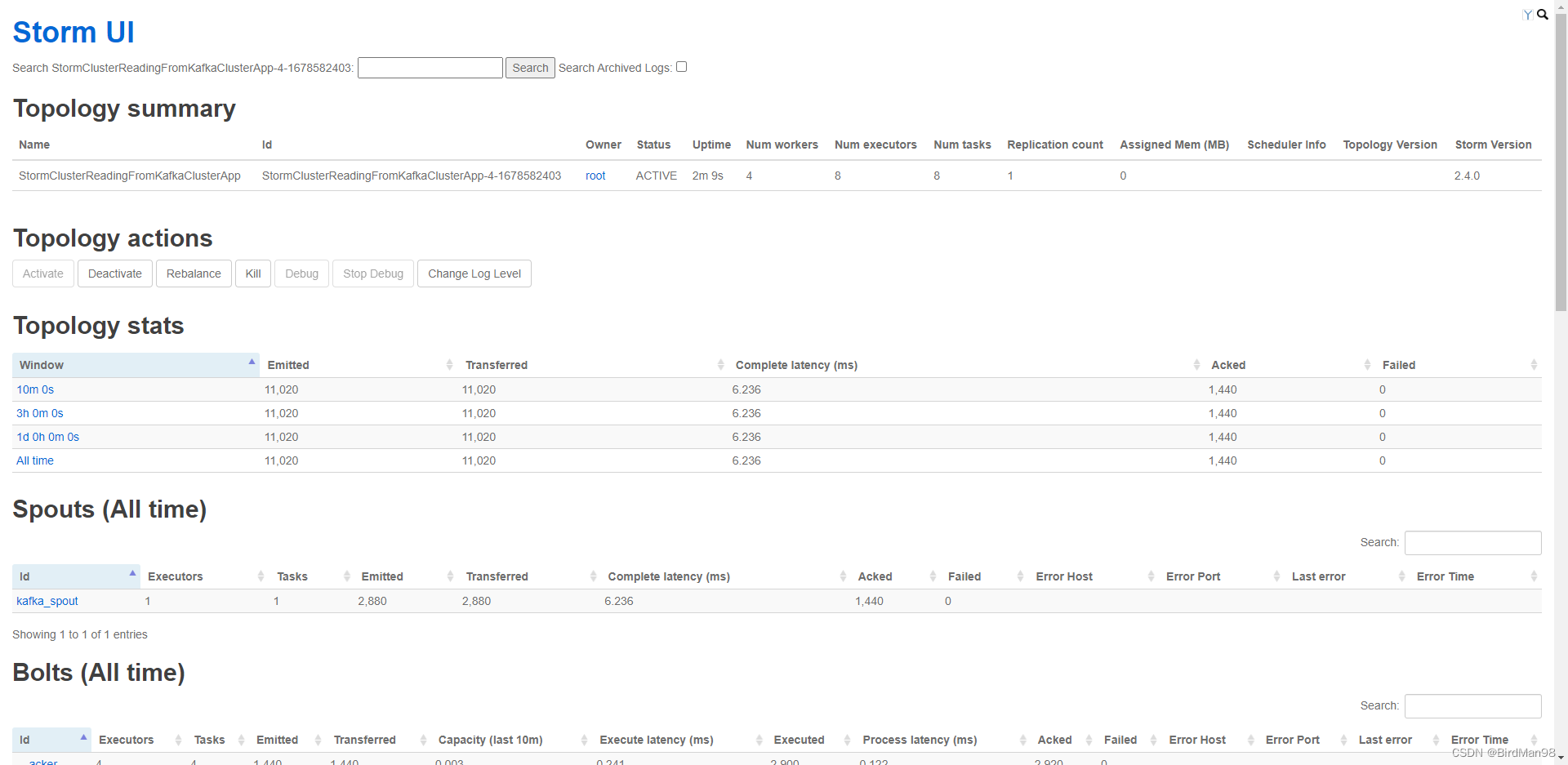
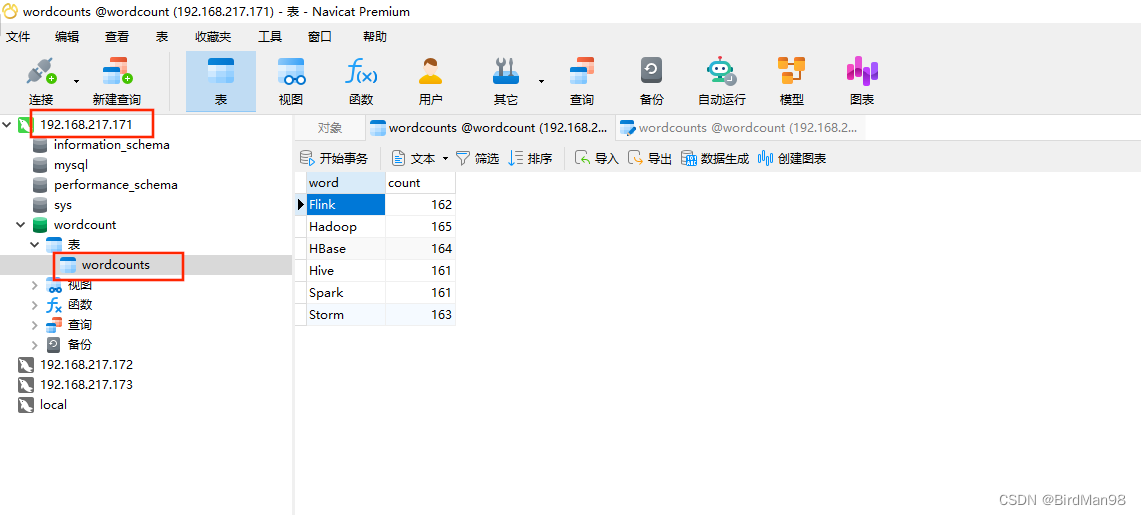
验证测试
思路:查看服务器上的MySQL是否收到了数据
附:日志查看
Nimbus节点
cd /usr/local/storm/logs
tail -100f nimbus.log
Supervisor节点
cd /usr/local/storm/logs
tail -100f supervisor.log
UI
cd /usr/local/storm/logs
tail -100f ui.log

















 695
695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











