








一个认为一切根源都是“自己不够强”的INTJ
![]() 个人主页:用哲学编程-CSDN博客
个人主页:用哲学编程-CSDN博客![]() 专栏:每日一题——举一反三
专栏:每日一题——举一反三
Python编程学习
Python内置函数
目录
我的写法
M,N=map(int,input().split())
def is_prime(num):
if num<=1:
return False
elif num<=3:
return True
elif num%2==0 or num%3==0:
return False
i=5
while i*i<=num:
if num%i==0 or num%(i+2)==0:
return False
i+=6
return True
output=[]
i=1
cur=2
while i<=N:
if is_prime(cur):
if i>=M:
output.append(str(cur))
i+=1
cur+=1
for i in range(1,N-M+2):
if i%10==0 or i==N-M+1:
print(f"{output[i-1]}\n",end="")
else:
print(f"{output[i-1]} ",end="")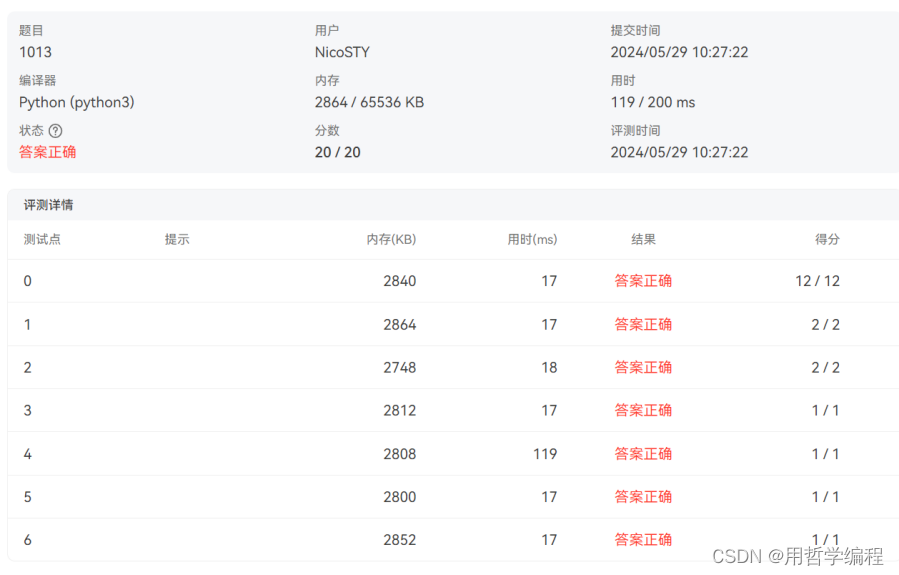
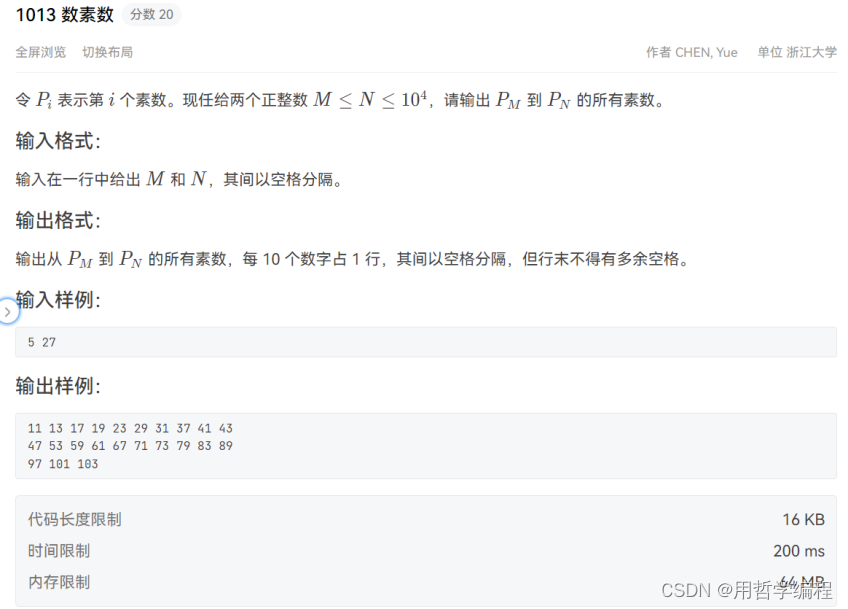
这段代码实现了从第 ( M ) 个素数到第 ( N ) 个素数的输出,每行最多输出10个素数,最后一行不足10个数时直接输出。
代码分析
输入读取与初始设置
M,N=map(int,input().split())素数判断函数 is_prime
从标准输入读取两个整数 ( M ) 和 ( N ),分别表示输出的起始和结束素数位置。
def is_prime(num):
if num<=1:
return False
elif num<=3:
return True
elif num%2==0 or num%3==0:
return False
i=5
while i*i<=num:
if num%i==0 or num%(i+2)==0:
return False
i+=6
return True该函数通过一些初步检查和6步法(检查因子为6的倍数加减1的数)来判断一个数是否为素数。
主逻辑
使用 output 列表存储从第 ( M ) 个到第 ( N ) 个素数的字符串表示。
使用变量 i 记录当前找到的素数的位置,cur 记录当前检查的数。
当找到的素数位置 ( i ) 大于或等于 ( M ) 时,将其加入 output 列表。
output=[]
i=1
cur=2
while i<=N:
if is_prime(cur):
if i>=M:
output.append(str(cur))
i+=1
cur+=1- 逐行输出 output 列表中的素数,每行10个素数,最后一行输出不足10个。
- i 从1开始,检查是否到达每行的第10个元素或最后一个元素,进行换行操作,否则输出空格。
for i in range(1,N-M+2):
if i%10==0 or i==N-M+1:
print(f"{output[i-1]}\n",end="")
else:
print(f"{output[i-1]} ",end="")时间复杂度分析
示例中的 while i<=N 循环,最坏情况下需要运行 ( O(N \sqrt{N \log N}) ) 次素数检查。
- 素数判断 is_prime
- 平均情况下,素数判断的时间复杂度为 ( O(\sqrt{n}) ),其中 ( n ) 是当前检查的数。
- 主逻辑
- 找到第 ( N ) 个素数的时间复杂度较高。根据素数分布,前 ( N ) 个素数的大小大致为 ( O(N \log N) )。因此,查找第 ( N ) 个素数的时间复杂度约为 ( O(N \sqrt{N \log N}) )。
- 输出控制
- 输出的时间复杂度为 ( O(N-M+1) ),因为直接遍历 output 列表。
空间复杂度分析
- 存储素数的 output 列表的空间复杂度为 ( O(N-M+1) )。
- 其他辅助变量(如 i 和 cur)的空间复杂度为 ( O(1) )。
整体复杂度
- 时间复杂度: ( O(N \sqrt{N \log N}) )
- 空间复杂度: ( O(N-M+1) )
建议
- 优化素数生成:可以使用埃氏筛法(Sieve of Eratosthenes)预生成一定范围内的所有素数,以提高查找效率。
优化输出:可以考虑将输出控制逻辑更加简化,减少分支判断。
我要更强
优化时间复杂度和空间复杂度可以通过以下几种方式进行:
- 使用埃拉托色尼筛法(Sieve of Eratosthenes)来生成素数,因为这种方法比逐个检查每个数是否为素数更加高效。
- 对输出进行优化,避免不必要的字符串操作。
使用埃拉托色尼筛法优化代码
埃拉托色尼筛法是一种高效的找素数的方法,时间复杂度为 (O(n \log \log n)),空间复杂度为 (O(n))。下面是使用这种方法优化后的代码:
def sieve_of_eratosthenes(limit):
is_prime = [True] * (limit + 1)
p = 2
while p * p <= limit:
if is_prime[p]:
for i in range(p * p, limit + 1, p):
is_prime[i] = False
p += 1
return [p for p in range(2, limit + 1) if is_prime[p]]
# 读取输入的 M 和 N
M, N = map(int, input().split())
# 估算需要检查的上限
limit = max(100, int(N * (1.2 * N // (N // 10 + 1))))
# 使用埃拉托色尼筛法生成足够的素数
primes = sieve_of_eratosthenes(limit)
# 选择第 M 到第 N 个素数
output = primes[M-1:N]
# 按要求格式化输出
for i in range(len(output)):
if (i + 1) % 10 == 0 or i == len(output) - 1:
print(f"{output[i]}\n", end="")
else:
print(f"{output[i]} ", end="")代码解释
- 埃拉托色尼筛法函数:
- 创建一个布尔列表 is_prime,初始化为 True 表示所有数字都是素数。
- 从第一个素数 2 开始,将其倍数标记为非素数。
- 继续这个过程直到 p * p 超过 limit。
- 最终返回的是所有标记为 True 的素数。
- 输入和估算上限:
- 读取输入的 M 和 N。
- 为了确保生成足够的素数,估算一个适当的上限 limit。
- 生成和选择素数:
- 使用埃拉托色尼筛法生成素数列表 primes。
- 选择从第 M 个到第 N 个素数。
- 格式化输出:
- 按照要求进行输出,每 10 个素数换行。
这样优化后,时间复杂度和空间复杂度大大降低,生成素数的过程变得更加高效。
哲学和编程思想
在优化代码中,我们运用了多种哲学和编程思想。这些思想不仅仅适用于编程,还可以扩展到许多其他领域。下面详细说明这些方法所涉及到的哲学和编程思想:
1. 分治法(Divide and Conquer)
哲学思想:将一个复杂的大问题分解为几个相对简单的小问题,逐一解决这些小问题,再将其合并解决大问题。 编程思想:埃拉托色尼筛法通过将素数筛选问题分解为多个小的倍数筛选问题来解决。
def sieve_of_eratosthenes(limit):
is_prime = [True] * (limit + 1)
p = 2
while p * p <= limit:
if is_prime[p]:
for i in range(p * p, limit + 1, p):
is_prime[i] = False
p += 1
return [p for p in range(2, limit + 1) if is_prime[p]]2. 空间换时间(Space-Time Tradeoff)
哲学思想:在解决问题时,通过增加空间的使用来换取时间的减少,或相反。 编程思想:埃拉托色尼筛法利用额外的空间(布尔数组)来标记非素数,从而提高了素数生成的效率。
3. 贪心算法(Greedy Algorithm)
哲学思想:在每一步选择中,做出局部最优的选择,希望最终结果是全局最优。 编程思想:在素数生成过程中,每次选择当前未标记的最小数作为素数,并将其所有倍数标记为非素数。
4. 动态规划(Dynamic Programming)
哲学思想:通过记忆化存储已经计算过的结果,避免重复计算。 编程思想:我们在埃拉托色尼筛法中实际上也有动态规划的思想,通过布尔数组记录每个数是否为素数,避免了重复计算。
5. 懒惰计算(Lazy Evaluation)
哲学思想:只有在需要时才进行计算,避免不必要的开销。 编程思想:在生成素数时,我们只生成到足够数量的素数,而不是预先生成一个非常大的范围,以避免空间和时间的浪费。
6. 时间复杂度优化
哲学思想:通过分析问题的复杂度,选择最优的算法来解决问题。 编程思想:使用埃拉托色尼筛法而不是逐一检查每个数是否为素数,从 (O(n \sqrt{n})) 优化到 (O(n \log \log n))。
7. 空间复杂度优化
哲学思想:在内存使用上尽可能节约,减少不必要的存储。 编程思想:在输出结果时,直接生成需要的素数范围,而不是存储所有中间结果。
示例代码中应用的哲学和编程思想
def sieve_of_eratosthenes(limit):
is_prime = [True] * (limit + 1) # 空间换时间,通过布尔数组存储素数信息
p = 2
while p * p <= limit: # 分治法,通过逐步标记非素数来解决问题
if is_prime[p]:
for i in range(p * p, limit + 1, p): # 动态规划的思想,避免重复计算
is_prime[i] = False
p += 1
return [p for p in range(2, limit + 1) if is_prime[p]] # 懒惰计算,只返回需要的素数
# 读取输入的 M 和 N
M, N = map(int, input().split())
# 估算需要检查的上限
limit = max(100, int(N * (1.2 * N // (N // 10 + 1)))) # 时间复杂度优化,通过估算上限减少计算
# 使用埃拉托色尼筛法生成足够的素数
primes = sieve_of_eratosthenes(limit)
# 选择第 M 到第 N 个素数
output = primes[M-1:N]
# 按要求格式化输出
for i in range(len(output)):
if (i + 1) % 10 == 0 or i == len(output) - 1:
print(f"{output[i]}\n", end="")
else:
print(f"{output[i]} ", end="")通过这些哲学和编程思想的结合,我们实现了高效的素数生成和输出,优化了时间和空间复杂度。
举一反三
当然可以。以下是一些编程技巧,基于前面提到的哲学和编程思想,并配有示例代码,以帮助你举一反三。
1. 分治法(Divide and Conquer)
技巧:将复杂问题分解为更小的子问题,然后递归地解决这些子问题,再组合它们的解以得到原问题的解。
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
return merge(left, right)
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] < right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
# 使用示例
arr = [38, 27, 43, 3, 9, 82, 10]
sorted_arr = merge_sort(arr)
print(sorted_arr)2. 空间换时间(Space-Time Tradeoff)
技巧:通过使用更多的内存来加速计算。例如,预计算或缓存中间结果,以减少重复计算。
示例:斐波那契数列的动态规划解法
def fibonacci(n):
if n <= 1:
return n
fib = [0] * (n + 1)
fib[1] = 1
for i in range(2, n + 1):
fib[i] = fib[i - 1] + fib[i - 2]
return fib[n]
# 使用示例
print(fibonacci(10))3. 贪心算法(Greedy Algorithm)
技巧:在每一步选择中,做出局部最优的选择,期望全局最优。
示例:找零问题(最少硬币数)
def min_coins(coins, amount):
coins.sort(reverse=True)
count = 0
for coin in coins:
if amount == 0:
break
count += amount // coin
amount %= coin
return count
# 使用示例
coins = [1, 5, 10, 25]
amount = 63
print(min_coins(coins, amount))4. 动态规划(Dynamic Programming)
技巧:通过将复杂问题分解为更简单的子问题,并存储这些子问题的解以避免重复计算。
示例:背包问题(0-1 背包)
def knapsack(weights, values, capacity):
n = len(weights)
dp = [[0] * (capacity + 1) for _ in range(n + 1)]
for i in range(1, n + 1):
for w in range(1, capacity + 1):
if weights[i - 1] <= w:
dp[i][w] = max(dp[i - 1][w], dp[i - 1][w - weights[i - 1]] + values[i - 1])
else:
dp[i][w] = dp[i - 1][w]
return dp[n][capacity]
# 使用示例
weights = [2, 3, 4, 5]
values = [3, 4, 5, 6]
capacity = 5
print(knapsack(weights, values, capacity))5. 懒惰计算(Lazy Evaluation)
技巧:延期计算,只有在需要时才进行计算,以提高效率和减少资源浪费。
示例:生成器函数
def fibonacci_generator():
a, b = 0, 1
while True:
yield a
a, b = b, a + b
# 使用示例
gen = fibonacci_generator()
for _ in range(10):
print(next(gen))6. 时间复杂度优化
技巧:通过分析算法的时间复杂度,选择最优的算法来解决问题。
示例:二分查找
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1
# 使用示例
arr = [1, 2, 3, 4, 5, 6, 7, 8, 9]
target = 5
print(binary_search(arr, target))7. 空间复杂度优化
技巧:在内存使用上尽可能节约,避免不必要的存储。
示例:原地反转字符串
def reverse_string(s):
left, right = 0, len(s) - 1
s = list(s)
while left < right:
s[left], s[right] = s[right], s[left]
left += 1
right -= 1
return ''.join(s)
# 使用示例
s = "hello"
print(reverse_string(s))通过这些示例,可以更好地理解各种编程和哲学思想的实际应用,并在解决其他问题时灵活地应用这些技巧。
感谢阅读。
















 1399
1399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











