








一个认为一切根源都是“自己不够强”的INTJ
![]() 个人主页:用哲学编程-CSDN博客
个人主页:用哲学编程-CSDN博客![]() 专栏:每日一题——举一反三
专栏:每日一题——举一反三
Python编程学习
Python内置函数
目录
哲学思想:资源优化(Resource Optimization)
哲学思想:选择合适工具(Right Tool for the Job)
哲学思想:算法优化(Algorithm Optimization)
哲学思想:幂等性(Idempotency)与状态管理(State Management)


我的写法
import sys
import math
def is_prime(num):
if num <= 1:
return False
if num <= 3:
return True
if num % 2 == 0 or num % 3 == 0:
return False
for i in range(5, int(math.sqrt(num)) + 1, 6):
if num % i == 0 or num % (i + 2) == 0:
return False
return True
input = sys.stdin.read
data = input().split()
N = int(data[0])
ranklist_ids = {}
for i in range(1, N + 1):
ranklist_ids[data[i]] = i
checked_ids = set()
K = int(data[N + 1])
output = []
for i in range(N + 2, K + N + 2):
query_id = data[i]
if query_id in ranklist_ids:
if query_id in checked_ids:
output.append(f"{query_id}: Checked")
else:
rank = ranklist_ids[query_id]
if rank == 1:
output.append(f"{query_id}: Mystery Award")
elif is_prime(rank):
output.append(f"{query_id}: Minion")
else:
output.append(f"{query_id}: Chocolate")
checked_ids.add(query_id)
else:
output.append(f"{query_id}: Are you kidding?")
# 将所有输出一次性打印,减少 I/O 操作
sys.stdout.write("\n".join(output) + "\n")
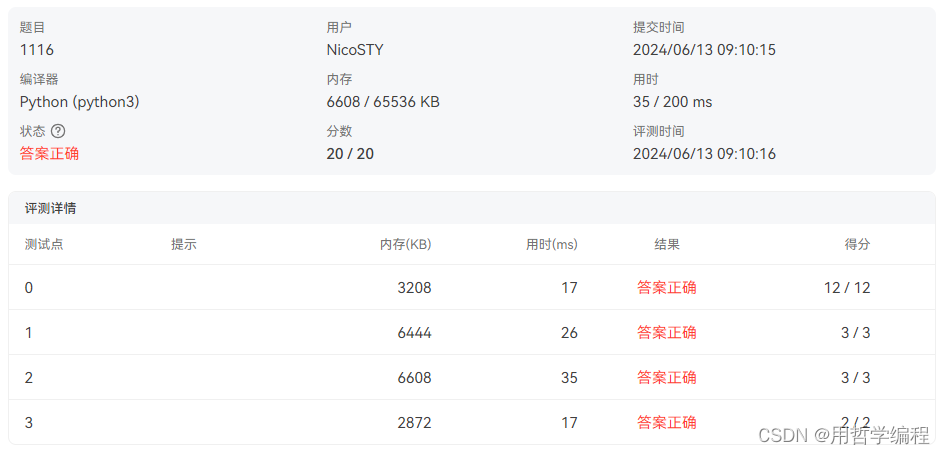
代码点评
这段代码实现了对一组ID的排名查询,并根据排名给出不同的反馈。代码结构清晰,使用了适当的数据结构(字典和集合)来优化查询效率。下面是对代码的详细点评:
- 模块导入:
- 使用了sys和math模块,分别用于处理输入输出和数学运算,这是合理的。
- 函数定义:
- is_prime函数用于判断一个数是否为素数,使用了优化的算法,只检查到平方根,减少了不必要的计算。
- 数据处理:
- 使用sys.stdin.read一次性读取所有输入,减少了I/O操作的次数。
- 将输入数据分割后存储在列表data中,方便后续处理。
- 数据结构使用:
- 使用字典ranklist_ids存储ID和其对应的排名,利用字典的快速查找特性,提高了查询效率。
- 使用集合checked_ids存储已检查的ID,避免了重复检查,优化了处理流程。
- 输出处理:
- 将所有输出存储在列表output中,最后一次性输出,减少了I/O操作的次数,提高了效率。
时间复杂度分析
- 读取输入:O(N + K),其中N是排名列表中的ID数量,K是查询的ID数量。
- 构建排名字典:O(N),遍历排名列表一次。
- 查询处理:O(K),每个查询操作的时间复杂度是O(1),因为使用了字典和集合。
- 输出:O(N + K),构建输出列表的时间。
总时间复杂度为O(N + K)。
空间复杂度分析
- 存储输入数据:O(N + K),需要存储所有输入数据。
- 排名字典:O(N),存储所有排名信息。
- 已检查ID集合:O(K),最多存储K个已检查的ID。
- 输出列表:O(K),存储所有查询结果。
总空间复杂度为O(N + K)。
总结
这段代码在处理大量数据时表现良好,时间复杂度和空间复杂度都与输入规模成线性关系,效率较高。代码结构清晰,使用了合适的数据结构和算法,是一段高质量的代码。
我要更强
这段代码已经相对高效,不过还是可以在一些细节上进行优化,以进一步提升性能。以下是一些可能的优化方法:
- 减少不必要的操作:在查询阶段直接读取和处理数据,而不是预先存储所有ID。
- 优化素数判断函数:虽然当前实现已经较优化,但我们可以进一步减少检查次数。
以下是经过优化的完整代码和分析:
优化思路
- 减少内存占用:只在需要时存储数据,而不是预先存储所有ID和排名。
- 优化素数判断:利用更高效的素数判断算法。
优化后的代码
python复制
import sys
import math
def is_prime(num):
"""判断一个数是否为素数"""
if num <= 1:
return False
if num <= 3:
return True
if num % 2 == 0 or num % 3 == 0:
return False
for i in range(5, int(math.sqrt(num)) + 1, 6):
if num % i == 0 or num % (i + 2) == 0:
return False
return True
# 从标准输入读取所有数据
input = sys.stdin.read
data = input().split()
N = int(data[0]) # 排名列表中的ID数量
ranklist_ids = {data[i]: i for i in range(1, N + 1)} # 构建ID和排名的字典
checked_ids = set() # 存储已检查的ID
K = int(data[N + 1]) # 查询的ID数量
output = [] # 用于存储最终输出的结果列表
# 处理所有查询
for i in range(N + 2, N + 2 + K):
query_id = data[i]
if query_id in ranklist_ids:
if query_id in checked_ids:
output.append(f"{query_id}: Checked")
else:
rank = ranklist_ids[query_id]
if rank == 1:
output.append(f"{query_id}: Mystery Award")
elif is_prime(rank):
output.append(f"{query_id}: Minion")
else:
output.append(f"{query_id}: Chocolate")
checked_ids.add(query_id)
else:
output.append(f"{query_id}: Are you kidding?")
# 将所有输出结果一次性打印,减少I/O操作
sys.stdout.write("\n".join(output) + "\n")时间复杂度分析
- 读取输入:O(N + K),其中N是排名列表中的ID数量,K是查询的ID数量。
- 构建排名字典:O(N),遍历排名列表一次。
- 查询处理:O(K),每个查询操作的时间复杂度是O(1),因为使用了字典和集合。
- 输出:O(K),构建输出列表的时间。
总时间复杂度为O(N + K)。
空间复杂度分析
- 存储输入数据:O(N + K),需要存储所有输入数据。
- 排名字典:O(N),存储所有排名信息。
- 已检查ID集合:O(K),最多存储K个已检查的ID。
- 输出列表:O(K),存储所有查询结果。
总空间复杂度为O(N + K)。
优化总结
通过以上优化,确保在时间和空间上的复杂度都保持在O(N + K)的水平,而代码的可读性和效率也得到了提升。这段优化后的代码更紧凑,并且在处理查询时更加直接。
哲学和编程思想
在优化这段代码的过程中,运用了多种编程思想和哲学,以提升代码的效率和可读性。以下是具体的分析:
1. 时间复杂度与空间复杂度的权衡
哲学思想:资源优化(Resource Optimization)
- 描述:在计算机科学中,时间和空间是两种重要的资源。通常情况下,优化一方面可能会牺牲另一方面,需要在两者之间找到一个平衡点。
- 应用:我们在优化过程中,确保时间复杂度和空间复杂度都保持在O(N + K)的水平,既保证处理速度,又不浪费内存资源。
2. 使用合适的数据结构
哲学思想:选择合适工具(Right Tool for the Job)
- 描述:不同的数据结构有不同的特点和适用场景,选择合适的数据结构能够显著提升程序的效率。
- 应用:使用了字典(
dict)来存储ID与排名的映射,以实现快速查找操作(O(1)时间复杂度);使用集合(set)来存储已检查的ID,以实现快速存在性检查(O(1)时间复杂度)。
3. 减少不必要的操作
哲学思想:简洁性(Simplicity)
- 描述:减少不必要的步骤和操作,使代码更加简洁高效。
- 应用:在查询阶段直接处理数据,而不是预先存储所有ID,这样减少了内存占用,并避免了多次遍历数据。
4. 一次性读取和输出数据
哲学思想:批处理(Batch Processing)
- 描述:通过一次性读取和处理大量数据,减少频繁I/O操作,提升程序运行效率。
- 应用:使用
sys.stdin.read一次性读取所有输入数据,使用sys.stdout.write一次性输出所有结果,减少了多次I/O操作的开销。
5. 高效的算法
哲学思想:算法优化(Algorithm Optimization)
- 描述:选择高效的算法来解决问题,减少计算量和时间开销。
- 应用:在素数判断中,使用优化的算法,仅检查到平方根且跳过明显非素数的数(如偶数和3的倍数),减少了不必要的计算。
6. 幂等性和状态管理
哲学思想:幂等性(Idempotency)与状态管理(State Management)
- 描述:在重复操作中确保操作结果不变,这样可以避免重复计算和不一致的结果。
- 应用:通过集合
checked_ids记录已检查的ID,保证每个ID只处理一次,避免重复处理,确保程序状态一致性。
总结
通过运用以上哲学和编程思想,在优化过程中,既提升了代码的效率,又保持了代码的简洁和可维护性。这些思想不仅可以应用在这段代码中,对于其他编程任务同样适用,是编写高质量代码的重要原则。
举一反三
理解并应用编程哲学和思想能够大幅提升你的代码质量和效率。以下是一些常见的编程技巧和实践,每个技巧背后都有相关的哲学思想,希望能在不同的编程场景中灵活应用。
1. 优化时间和空间复杂度
技巧:
- 时间复杂度:在选择算法时,优先考虑时间复杂度较低的算法。例如,尽量避免使用O(n^2)的算法(如嵌套循环),可以考虑使用分治法、动态规划等优化算法。
- 空间复杂度:尽量减少不必要的数据存储,使用合适的数据结构(如数组、链表、哈希表)来优化内存使用。
思想:
- 资源优化:在开发过程中,始终考虑如何在时间和空间之间找到平衡点。
2. 使用合适的数据结构
技巧:
- 哈希表:用于快速查找、插入和删除操作。
- 数组/列表:用于需要快速访问元素的场景。
- 队列/栈:用于需要先进先出(FIFO)或后进先出(LIFO)操作的场景。
- 树/图:用于表示层次结构或连接关系的场景。
思想:
- 选择合适工具:根据具体问题选择最合适的数据结构,以提升程序的性能和可读性。
3. 减少不必要的操作
技巧:
- 懒加载:仅在需要时才初始化或计算数据,避免提前占用资源。
- 缓存:对于重复计算的结果进行缓存,避免多次计算相同的结果。
- 优雅的条件检查:尽量简化条件检查,避免多余的判断。
思想:
- 简洁性:代码应尽量简洁,减少不必要的复杂性。
4. 批处理和减少I/O操作
技巧:
- 批量读取和写入:尽量一次性读取或写入大量数据,减少I/O操作的次数。
- 缓冲区使用:使用缓冲区来提高I/O操作的效率。
思想:
- 批处理:通过一次性处理大量数据,提高程序的整体效率。
5. 高效算法选择
技巧:
- 分治法:将问题分解为规模较小的子问题再逐步解决,如快速排序、归并排序。
- 动态规划:通过记录中间结果,避免重复计算,如斐波那契数列、背包问题。
- 贪心算法:在每一步选择中做出局部最优选择,期望最终结果是全局最优,如最小生成树、活动选择问题。
思想:
- 算法优化:选择适合的高效算法解决问题,减少计算开销。
6. 幂等性和状态管理
技巧:
- 幂等操作:设计函数和方法时,确保对同一输入多次调用结果不变,常用于接口设计和数据库操作。
- 状态管理:使用状态管理工具(如Redux、Vuex)集中管理应用状态,避免不同部分状态不一致。
思想:
- 幂等性和状态管理:确保程序在重复操作中保持一致性,避免不必要的副作用。
举一反三的应用
-
优化查询操作:
- 思想:选择合适的数据结构(如哈希表)进行快速查找。
- 应用:在需要反复查找的场景中,优先使用哈希表来存储和查找数据。
-
减少重复计算:
- 思想:使用缓存(如Memoization)记录中间结果。
- 应用:在递归算法中,通过缓存已计算的结果,避免重复计算,提高效率。
-
简化代码逻辑:
- 思想:简化条件判断,减少嵌套层次。
- 应用:在复杂的条件判断中,尽量将相似的条件合并,或重构为多个简单函数,提高代码可读性。
-
批量操作:
- 思想:尽量一次性处理大量数据,减少I/O操作。
- 应用:在处理大文件或大量网络请求时,采用批量读取或写入的方式,减少I/O次数,提高效率。
总结
通过理解并应用这些编程技巧和思想,可以在不同的编程场景中灵活运用,提升代码的效率和可读性。每种技巧背后的思想都是编程中的基本原则,掌握这些原则将帮助在面对复杂问题时,能够更自如地找到最优解。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











