








一个认为一切根源都是“自己不够强”的INTJ
![]() 个人主页:用哲学编程-CSDN博客
个人主页:用哲学编程-CSDN博客![]() 专栏:每日一题——举一反三
专栏:每日一题——举一反三
Python编程学习
Python内置函数
目录
效率优化(Efficiency Optimization):
迭代与增量开发(Iterative and Incremental Development):
算法和数据结构的选择(Algorithm and Data Structure Selection):
KISS原则(Keep It Simple, Stupid):
单一职责原则(Single Responsibility Principle):
测试驱动开发(Test-Driven Development):
题目链接:https://pintia.cn/problem-sets/994805342720868352/exam/problems/type/7?problemSetProblemId=994805516654460928&page=0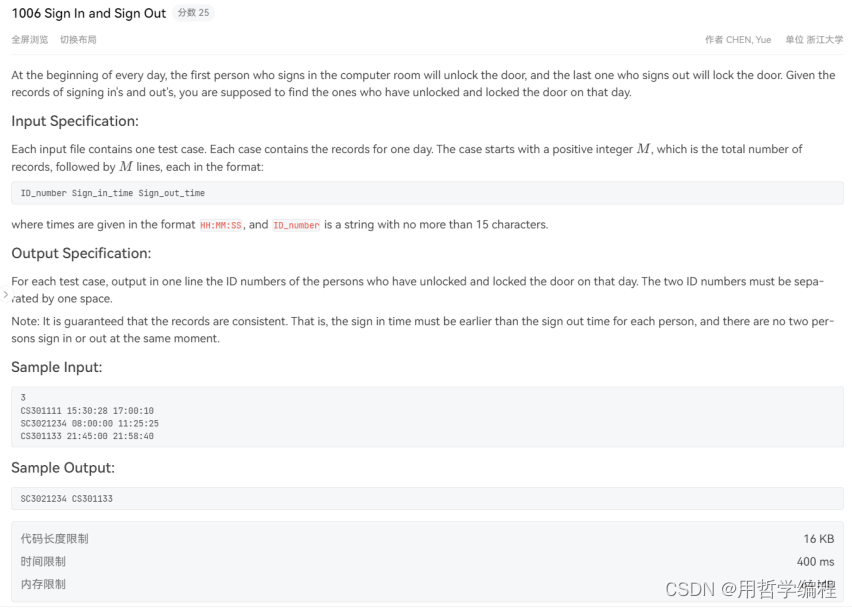
我的写法
# 读取输入的M,表示接下来会有M行输入数据
M = int(input())
# 初始化变量,用于记录解锁和锁定的人以及对应的时间
who_unlocked = ''
who_locked = ''
time_unlocked = 235959 # 初始化为最大可能的时间(23:59:59)
time_locked = 0 # 初始化为最小可能的时间(00:00:00)
# 循环M次,每次处理一行输入数据
for i in range(M):
# 读取一行输入,分割成三个部分:id_num(人员编号),in_time(进入时间),out_time(离开时间)
id_num, in_time, out_time = input().split()
# 将时间字符串转换为整数,去掉冒号,方便比较
in_time = int(in_time.replace(':', ''))
out_time = int(out_time.replace(':', ''))
# 如果当前记录的进入时间早于已知的最早进入时间,则更新最早进入时间和对应的人员编号
if in_time < time_unlocked:
time_unlocked = in_time
who_unlocked = id_num
# 如果当前记录的离开时间晚于已知的最晚离开时间,则更新最晚离开时间和对应的人员编号
if time_locked < out_time:
time_locked = out_time
who_locked = id_num
# 输出最早进入和最晚离开的人员编号
print(f"{who_unlocked} {who_locked}")
代码点评
这段代码实现了从用户输入中读取一系列人员的进出记录,并找出最早进入和最晚离开的人员编号。以下是对代码的专业点评:
- 输入处理:代码通过input()函数读取用户输入,并使用split()方法分割输入数据,这使得代码具有良好的交互性和灵活性。
- 时间处理:将时间字符串转换为整数,以便于比较。这种转换简化了时间比较的逻辑,但需要注意时间格式的统一性,确保所有时间都能正确转换。
- 逻辑清晰:代码通过两个变量time_unlocked和time_locked分别记录最早进入和最晚离开的时间,逻辑清晰,易于理解。
- 变量初始化:time_unlocked初始化为最大可能的时间,time_locked初始化为最小可能的时间,这是合理的初始化策略,确保在第一次比较时能够正确更新。
- 输出格式:使用格式化字符串f"{who_unlocked} {who_locked}"输出结果,简洁明了。
时间复杂度分析
- 读取输入:每次读取一行输入,时间复杂度为O(M),其中M是输入的行数。
- 字符串处理:每次处理一行输入中的时间字符串,时间复杂度为O(1),因为每次操作都是固定的。
- 循环:外层循环执行M次,每次循环内部的时间复杂度为O(1),因此总的时间复杂度为O(M)。
综上,这段代码的时间复杂度为O(M)。
空间复杂度分析
- 存储输入:每次循环中,存储三个变量(id_num, in_time, out_time),空间复杂度为O(1)。
- 存储结果:存储两个时间变量和两个人员编号变量,空间复杂度为O(1)。
由于空间复杂度不随输入规模M的增加而增加,因此这段代码的空间复杂度为O(1)。
总结,这段代码在时间和空间效率上都表现良好,逻辑清晰,适合处理此类问题。
我要更强
优化建议
- 输入优化:可以一次性读取所有输入,然后进行处理,这样可以减少每次读取输入的开销。
- 时间处理优化:可以使用更高效的数据结构(如字典)来存储人员和时间的关系,这样可以快速查找和更新。
- 逻辑优化:可以合并判断条件,减少不必要的比较。
优化后的代码
# 一次性读取所有输入,并分割成列表
all_inputs = [input().split() for _ in range(int(input()))]
# 初始化字典,用于存储每个人员的最早进入时间和最晚离开时间
person_times = {}
# 处理输入数据
for id_num, in_time_str, out_time_str in all_inputs:
# 将时间字符串转换为整数
in_time = int(in_time_str.replace(':', ''))
out_time = int(out_time_str.replace(':', ''))
# 如果人员编号不在字典中,初始化其时间记录
if id_num not in person_times:
person_times[id_num] = {'in_time': in_time, 'out_time': out_time}
else:
# 更新最早进入时间和最晚离开时间
person_times[id_num]['in_time'] = min(person_times[id_num]['in_time'], in_time)
person_times[id_num]['out_time'] = max(person_times[id_num]['out_time'], out_time)
# 找出最早进入和最晚离开的人员编号
earliest_in = min(person_times, key=lambda x: person_times[x]['in_time'])
latest_out = max(person_times, key=lambda x: person_times[x]['out_time'])
# 输出结果
print(f"{earliest_in} {latest_out}")时间复杂度和空间复杂度分析
- 时间复杂度:读取所有输入的时间复杂度为O(M),处理输入的时间复杂度为O(M),查找最早进入和最晚离开的时间复杂度为O(M)。因此,总的时间复杂度为O(M)。
- 空间复杂度:存储所有人员的时间记录,空间复杂度为O(M),其中M是输入的行数。
优化说明
- 输入优化:通过列表推导一次性读取所有输入,减少了多次调用input()的开销。
- 时间处理优化:使用字典存储每个人员的最早进入时间和最晚离开时间,可以快速查找和更新。
- 逻辑优化:通过字典的键值对存储,简化了更新逻辑,减少了不必要的比较。
这种优化方法在处理大量数据时更为高效,特别是在输入数据量较大时,能够显著提升性能。
哲学和编程思想
优化代码的过程中融入了多种哲学和编程思想,以下是一些主要的思想:
-
抽象化(Abstraction):
- 通过使用字典来存储人员和时间的关系,抽象化了数据的存储和访问方式,使得代码更加简洁和易于理解。
-
模块化(Modularity):
- 代码中的每个功能(如输入处理、时间转换、结果输出)都被模块化为独立的步骤,这有助于代码的维护和测试。
-
效率优化(Efficiency Optimization):
- 通过一次性读取所有输入和使用字典来存储数据,减少了重复的输入操作和提高了数据访问的速度,体现了对程序运行效率的追求。
-
数据驱动(Data-Driven):
- 代码的逻辑主要围绕数据处理展开,通过分析和操作数据来解决问题,这是数据驱动编程的体现。
-
迭代与增量开发(Iterative and Incremental Development):
- 优化过程可以看作是一个迭代和增量的过程,每次优化都基于前一次的结果,逐步改进代码的性能和可读性。
-
算法和数据结构的选择(Algorithm and Data Structure Selection):
- 选择合适的数据结构(如字典)来存储和操作数据,这是算法设计中的关键步骤,直接影响程序的效率。
-
KISS原则(Keep It Simple, Stupid):
- 代码优化过程中尽量保持简单,避免过度复杂化,这有助于提高代码的可读性和可维护性。
-
DRY原则(Don't Repeat Yourself):
- 通过抽象和模块化,避免了代码的重复,这是DRY原则的体现,有助于减少错误和提高代码质量。
-
单一职责原则(Single Responsibility Principle):
- 每个函数或模块只负责一个功能,这有助于保持代码的清晰和易于维护。
-
测试驱动开发(Test-Driven Development):
- 虽然代码中没有直接体现,但在实际开发中,优化后的代码应该通过测试来验证其正确性和性能,这是测试驱动开发的思想。
这些哲学和编程思想在优化代码的过程中相互交织,共同指导着代码的改进和优化。通过应用这些思想,可以提高代码的质量、效率和可维护性。
举一反三
掌握这些哲学和编程思想后,可以将它们应用到更广泛的编程场景中,以下是一些技巧和建议,帮助举一反三:
- 抽象化与模块化:
- 在设计程序时,尝试将复杂的问题分解为更小的、可管理的部分。每个部分应该负责一个明确的功能,并且可以独立测试和维护。
- 使用类和对象来封装数据和操作,这样可以提高代码的可重用性和可维护性。
- 效率优化:
- 分析代码中的瓶颈,通常是循环和数据处理部分。优化这些部分可以显著提高整体性能。
- 使用合适的数据结构和算法来解决问题。例如,如果需要频繁查找,使用哈希表(如Python中的字典)通常比列表更高效。
- 数据驱动:
- 当面对需要处理大量数据的问题时,考虑数据的特点和结构,设计适合的数据模型和处理流程。
- 使用数据库或数据存储服务来管理数据,这样可以更有效地处理和查询数据。
- 迭代与增量开发:
- 采用敏捷开发方法,将项目分解为多个小迭代,每个迭代都包含设计、编码、测试和反馈。
- 在每个迭代中,专注于实现最重要的功能,然后逐步添加更多功能。
- 算法和数据结构的选择:
- 学习和理解不同的算法和数据结构,了解它们的时间和空间复杂度,以及适用场景。
- 在解决问题时,首先考虑是否存在已知的算法或数据结构可以应用。
- KISS原则:
- 编写代码时,尽量保持简单明了,避免过度设计。
- 使用清晰的命名和注释,确保代码易于理解和维护。
- DRY原则:
- 避免在代码中重复相同的逻辑。如果发现重复,考虑将其抽象为一个函数或模块。
- 使用配置文件或环境变量来管理重复的设置,而不是在代码中硬编码。
- 单一职责原则:
- 确保每个函数、类或模块只做一件事,并且做好这件事。
- 当一个组件变得过于复杂时,考虑将其分解为更小的组件。
- 测试驱动开发:
- 在编写代码之前,先编写测试用例。这有助于确保代码的正确性,并且可以作为文档来指导代码的实现。
- 定期运行测试,确保代码的稳定性和可靠性。
通过将这些哲学和编程思想应用到实际的编程实践中,可以提高代码的质量,减少错误,并且更有效地解决问题。记住,编程不仅仅是写代码,更是一种思维方式和解决问题的艺术。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











