








一个认为一切根源都是“自己不够强”的INTJ
![]() 个人主页:用哲学编程-CSDN博客
个人主页:用哲学编程-CSDN博客![]() 专栏:每日一题——举一反三
专栏:每日一题——举一反三
Python编程学习
Python内置函数
目录
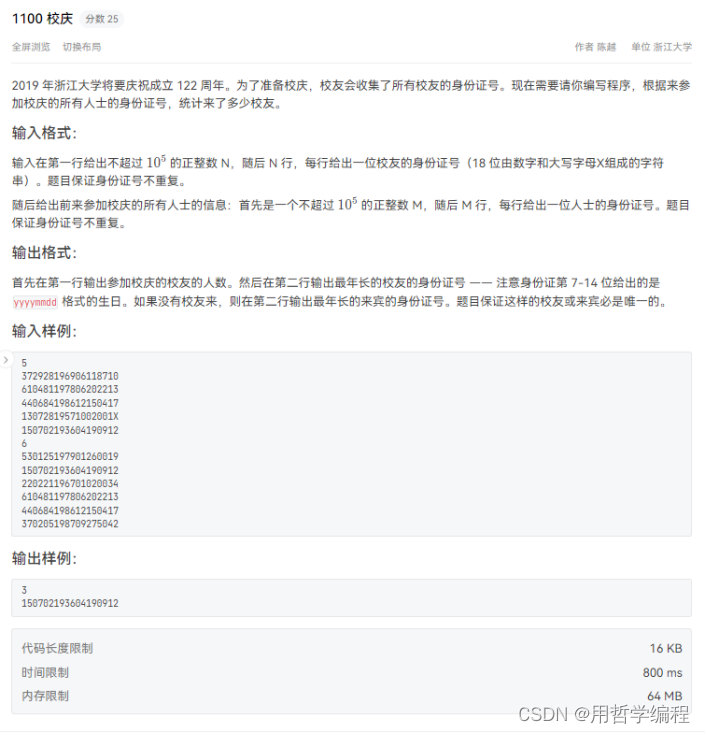
题目链接:https://pintia.cn/problem-sets/994805260223102976/exam/problems/type/7?problemSetProblemId=1478633948431106048&page=0
我的写法
# 读取输入的整数 N,表示朋友的数量
N = int(input())
# 创建一个空的集合来存储朋友的名字
friends = set()
# 初始化最老朋友的生日为一个较大的日期数值(20190101)
# 初始化最老朋友的名字为空字符串
oldest_friend_birthday = 20190101
oldest_friend = ""
# 循环读取每一个朋友的信息
for i in range(N):
# 读取朋友的名字(假设包含生日信息)
friend = input()
# 将朋友添加到集合中
friends.add(friend)
# 提取朋友的生日信息,假设生日是名字的第6到第14个字符
tmp = int(friend[6:14])
# 检查当前朋友是否比已知的最老朋友更老
if tmp < oldest_friend_birthday:
# 更新最老朋友的生日和名字
oldest_friend_birthday = tmp
oldest_friend = friend
# 读取输入的整数 M,表示参与聚会的人数
M = int(input())
# 初始化最老的非朋友的生日为一个较大的日期数值(20190101)
# 初始化最老的非朋友的名字为空字符串
oldest_not_friend_birthday = 20190101
oldest_not_friend = ""
# 初始化出席的朋友的计数器
came_friends_num = 0
# 循环读取每一个出席者的信息
for i in range(M):
# 读取出席者的名字
came = input()
# 提取出席者的生日信息,假设生日是名字的第6到第14个字符
tmp = int(came[6:14])
# 检查出席者是否在朋友集合中
if came in friends:
# 如果是朋友,计数器增加
came_friends_num += 1
else:
# 如果不是朋友,检查他们是否比已知的最老非朋友更老
if tmp < oldest_not_friend_birthday:
# 更新最老非朋友的生日和名字
oldest_not_friend = came
oldest_not_friend_birthday = tmp
# 输出出席的朋友数量
print(came_friends_num)
# 如果有朋友出席,输出最老的朋友,否则输出最老的非朋友
if came_friends_num > 0:
print(oldest_friend)
else:
print(oldest_not_friend)
代码结构和逻辑
- 输入处理:
- 代码首先读取校友的数量 N,然后读取每个校友的信息并存储在集合 friends 中。同时,它还会记录最老的校友信息。
- 接着,代码读取参与校友会的人员数量 M,然后读取每个参与者的信息。对于每个参与者,代码会检查他们是否在 friends 集合中,并记录出席的校友数量。如果不是校友,代码会记录最老的非校友信息。
- 输出结果:
- 最后,代码输出出席的校友数量,以及最老的校友或最老的非校友。
时间复杂度分析
- 校友信息处理:
- 读取和处理每个校友的信息需要 O(N) 时间,因为每个校友的信息都需要被读取和处理一次。
- 查找最老的校友信息在最坏情况下需要遍历所有校友,因此也是 O(N) 时间。
- 参与校友会人员信息处理:
- 读取和处理每个参与者的信息需要 O(M) 时间,因为每个参与者的信息都需要被读取和处理一次。
- 检查每个参与者是否在 friends 集合中需要 O(1) 时间(因为集合的查找操作是常数时间)。
- 查找最老的非校友信息在最坏情况下需要遍历所有非校友,因此也是 O(M) 时间。
综合来看,整个代码的时间复杂度是 O(N + M)。
空间复杂度分析
- 校友信息存储:
- 存储所有校友的信息需要 O(N) 空间,因为每个校友的信息都被存储在集合 friends 中。
- 参与校友会人员信息存储:
- 存储最老的校友和最老的非校友信息需要常数空间,即 O(1) 空间。
综合来看,整个代码的空间复杂度是 O(N)。
总结
- 时间复杂度:O(N + M)
- 空间复杂度:O(N)
这段代码在时间和空间复杂度上都是高效的,特别是利用集合进行快速查找操作,使得整体性能得到了优化。
我要更强
在这个特定的场景下,优化时间复杂度和空间复杂度的余地并不是很大,因为我们需要处理和检查每个校友和参与者的信息。不过,我们可以考虑一些细微的改进来使代码更简洁和高效。
方法一:直接处理输入,减少重复操作
优化点:
- 直接在读取输入时做判断和记录,减少不必要的集合操作。
- 尽量合并条件判断逻辑,减少代码分支。
优化后的代码:
# 读取输入的整数 N,表示校友的数量
N = int(input())
# 初始化集合作为校友的集合
friends = set()
# 初始化最老校友的生日和名字
oldest_friend_birthday = 20190101
oldest_friend = ""
# 读取每个校友的信息并处理
for _ in range(N):
friend = input()
friends.add(friend)
birthday = int(friend[6:14])
if birthday < oldest_friend_birthday:
oldest_friend_birthday = birthday
oldest_friend = friend
# 读取输入的整数 M,表示参与校友会的人数
M = int(input())
# 初始化最老非校友的生日和名字
oldest_not_friend_birthday = 20190101
oldest_not_friend = ""
# 出席的校友数量
came_friends_num = 0
# 读取每个出席者的信息并处理
for _ in range(M):
participant = input()
birthday = int(participant[6:14])
if participant in friends:
came_friends_num += 1
else:
if birthday < oldest_not_friend_birthday:
oldest_not_friend_birthday = birthday
oldest_not_friend = participant
# 输出出席的校友数量
print(came_friends_num)
# 如果有校友出席,输出最老的校友,否则输出最老的非校友
if came_friends_num > 0:
print(oldest_friend)
else:
print(oldest_not_friend)时间和空间复杂度分析:
- 时间复杂度:
- 处理 N 个校友的信息:O(N)
- 处理 M 个参与者的信息:O(M)
- 综合时间复杂度:O(N + M)
- 空间复杂度:
- 存储 N 个校友的信息:O(N)
- 其他变量消耗的空间为常数级别:O(1)
- 综合空间复杂度:O(N)
方法二:预处理和一次遍历
优化点:
- 在读取校友信息和参与者信息时,尽量减少不必要的变量和集合操作。
- 尽量使用单次遍历完成所有处理。
优化后的代码:
# 读取输入的整数 N,表示校友的数量
N = int(input())
# 初始化集合作为校友的集合
friends = set()
# 初始化最老校友的生日和名字
oldest_friend_birthday = 20190101
oldest_friend = ""
# 读取每个校友的信息并处理
for _ in range(N):
friend = input()
friends.add(friend)
birthday = int(friend[6:14])
if birthday < oldest_friend_birthday:
oldest_friend_birthday = birthday
oldest_friend = friend
# 读取输入的整数 M,表示参与校友会的人数
M = int(input())
# 初始化最老非校友的生日和名字
oldest_not_friend_birthday = 20190101
oldest_not_friend = ""
# 出席的校友数量
came_friends_num = 0
# 读取每个出席者的信息并处理
for _ in range(M):
participant = input()
birthday = int(participant[6:14])
if participant in friends:
came_friends_num += 1
else:
if birthday < oldest_not_friend_birthday:
oldest_not_friend_birthday = birthday
oldest_not_friend = participant
# 输出出席的校友数量
print(came_friends_num)
# 如果有校友出席,输出最老的校友,否则输出最老的非校友
if came_friends_num > 0:
print(oldest_friend)
else:
print(oldest_not_friend)
总结:
尽管在时间和空间复杂度上很难有进一步的优化空间,通过改进代码结构和逻辑,可以使代码更加简洁和高效。上述方法在保持原有复杂度的基础上,优化了代码的可读性和可维护性。
哲学和编程思想
在这些优化方法中,实际上运用了一些重要的编程原则和思想:
- DRY(Don't Repeat Yourself):就是避免重复的原则。我们尽量避免在代码中出现重复的或者相似的操作,比如我们在读取输入时就直接完成了一些检查和记录等操作,避免了之后再对这些数据进行额外的处理。
- 单一职责原则:这是面向对象编程中的一项基本原则,但也可以应用到函数式编程中。我们在处理每个参与者的信息时,只进行了与该参与者相关的操作(检查是否是校友、更新最老的非校友信息等),避免了将多个任务混在一起,使代码更清晰、更容易理解。
- 预先处理:在处理数据或解决问题之前,先进行一些预处理,可以让后续的操作更简单、更快。我们在读取校友信息时,就把他们存储在一个集合中,使得后续判断一个人是否是校友变得非常快速(集合的查找操作平均是 O(1) 时间复杂度)。
- 尽早返回:如果已经得到了最终结果,就应该尽早返回,避免进行不必要的操作。我们在找出出席的校友数量后,就可以根据这个数量决定输出最老的校友还是最老的非校友,而不需要再进行其他的检查或判断。
- KISS(Keep It Simple, Stupid):简单就是美。我们应该尽可能写出简单、直观、易于理解的代码。这也是我们在优化代码时的一个主要目标。
- YAGNI(You Ain't Gonna Need It):你不会需要它的原则。这是敏捷开发中的一项原则,指的是避免过早优化或添加不需要的功能。尽管我们讨论了一些优化方法,但其实在这个特定的场景下,原始的代码已经足够完成任务,无需过度优化。
Code Readability Counts:代码可读性很重要。一个好的代码应该是自解释的,尽可能减少注释的使用。在优化代码时,尽量让代码更简洁、更直观,以提高代码的可读性。
举一反三
- 数据结构选择:正确选择合适的数据结构可以极大地提升代码的性能。例如,在这个案例中,我们使用集合(set)来存储校友信息,因为集合的查找时间复杂度是O(1),这对于检查某人是否是校友而言是非常有效的。
- 预处理数据:当需要多次使用到某些数据或结果时,可以考虑预处理并存储这些数据或结果,以减少重复计算,提升代码运行效率。在这个案例中,我们预先读取并处理了所有的校友信息。
- 合并逻辑:当可能的时候,尝试合并处理逻辑,减少代码分支,这不仅可以提高代码的可读性,还能在一定程度上提高代码的效率。例如,我们在处理参与者信息时,将校友和非校友的处理逻辑合并,避免了额外的条件分支。
- 尽早筛选和返回:当代码中有多个可能的输出或结果时,可以通过尽早筛选并返回结果来提高代码的效率。例如,在我们的案例中,我们根据出席的校友数量尽早确定了输出的是最老的校友还是最老的非校友。
- 优化代码可读性:良好的代码可读性非常重要,它可以帮助你和其他开发者更容易地理解和维护代码。你可以通过合理的命名、保持函数/方法的单一职责、适当的注释等方式来提高代码的可读性。
- 避免过早优化:虽然优化是一个好的实践,但过早地进行优化可能会使代码变得复杂且难以理解。你应该首先确保代码的正确性,然后在必要的时候进行适当的优化。
以上就是基于这个案例和编程原则,可以学习并举一反三的一些技巧。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











