








- 今日真题
京东2018秋招数据分析工程师笔试题(来源:牛客网) - 题型
客观题:单选18道,不定项选择12道
主观题:编程2道 - 完成时间
120分钟 - 牛客网评估难度系数
3颗星
写到「数据分析真题日刷」第七套真题,博客喜迎粉丝啦,开心,我的博文被人发现啦~
❤️ 「更多数据分析真题」
1. 有一个文件user.txt,每行一条user记录,共若干行,下面哪个命令可以实现“统计出现次数最多的前3个user及其次数”?
A. cat user.txt | sort | uniq -c | sort -rn | top -n 3
B. cat user.txt | count -n | sort -rn | head -n 3
C. uniq -c user.txt | sort -nr | top -n 3
D. sort user.txt | uniq -c | sort -rn | head -n 3
正确答案:D
「民间解析」
首先sort进行排序,将重复的行都排在了一起,然后使用uniq -c将重复的行的次数放在了行首,在用sort -rn进行反向和纯文本排序,这样就按照重复次数从高到低进行了排列,最后利用head -n 3 输出行首的三行。
来源:https://www.nowcoder.com/test/question/done?tid=24999724&qid=163505
作者:凯里欧文1
2. MySQL中t表存在如下数据
+---+---+
| a | b |
+---+---+
| 1 | 2 |
+---+---+
执行如下更新SQL:update t set b = 5 and a= 2 where a = 1之后,a和b值为:
A. a = 2, b = 5
B. a = 1, b = 5
C. a =1 , b = 0
D. a = 1, b = 5
正确答案:C
「民间解析」
正确的更新语句应该是
update t set b = 5, a= 2 where a = 1
题目中用了 and 连接两个更新赋值
相当于对b赋了个bool值, 即
update t set b = (5 and a= 2) where a = 1
而a=1 故以上真值为0, 所以出现了 a=1, b=0的结果
来源:https://www.nowcoder.com/test/question/done?tid=24999724&qid=163506#summary
作者:最爱土豆
3. 某网游全天平均在线人数为6000人,玩家每次登录后平均在线时长为2小时。请你估计一下,平均下来每分钟约有多少个玩家登录?
A. 50
B. 6000
C. 12000
D. 72000
正确答案:A
「民间解析」
2个小时120分钟,6000/120=50
来源:https://www.nowcoder.com/test/question/done?tid=24999724&qid=163507#summary
作者:一阵风吹过
4. 有关linux线程的描述,正确的是( )。
A. 线程自己拥有很少的资源,但它可以使用所属进程的资源
B. 由于同一进程中的多个线程具有相同的地址空间,所以它们间的同步和通信也易于实现
C. 进程创建与线程创建的时空开销不相同
D. 线程是资源分配的基本单位,进程是资源调度的基本单位
正确答案:A B C
?进程和线程
- 「进程(process)」
狭义定义:进程就是一段程序的执行过程。
广义定义:进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元,在传统的操作系统中,进程既是基本的分配单元,也是基本的执行单元。- 「线程」
通常在一个进程中可以包含若干个线程,当然一个进程中至少有一个线程,不然没有存在的意义。**线程可以利用进程所拥有的资源,在引入线程的操作系统中,通常都是把进程作为分配资源的基本单位,而把线程作为独立运行和独立调度的基本单位,**由于线程比进程更小,基本上不拥有系统资源,故对它的调度所付出的开销就会小得多,能更高效的提高系统多个程序间并发执行的程度。- 「进程与线程的区别」
进程和线程的主要差别在于它们是不同的操作系统资源管理方式。进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。
来源:https://www.cnblogs.com/fuchongjundream/p/3829508.html
「题目解析」
D错误,进程作为分配资源的基本单位,而把线程作为独立运行和独立调度的基本单位。
- 强烈参考
- 《进程、线程、多线程相关总结》https://www.cnblogs.com/fuchongjundream/p/3829508.html
5. 进程会在各个状态之间切换,下面哪些是不可能的
A. 运行→就绪
B. 运行→等待
C. 等待→运行
D. 等待→就绪
正确答案:C
「题目解析」
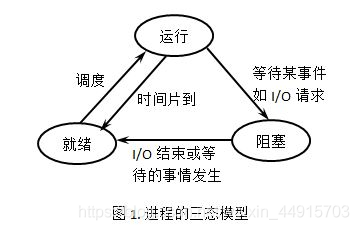
来源:https://www.cnblogs.com/xiawen/p/3328033.html
- 强烈参考
- 《进程的三态、五态模型【转】》https://www.cnblogs.com/xiawen/p/3328033.html
6. 某二叉树有2000个结点,则该二叉树的最小高度为()
A. 10
B. 11
C. 12
D. 13
正确答案:B
「题目解析」
一棵深度为k,且有2^k-1个节点的二叉树,称为满二叉树。
思路:2^k - 1 = 2000,解k;
因为2^10 = 1024, 2 ^ 11 = 2048,所以10层不够,高度至少为11。
7. 若一序列进栈顺序为a1,a2,a3,a4,问存在多少种可能的出栈序列( )
A. 12
B. 13
C. 14
D. 15
正确答案:C
?栈
进栈出栈就像一个盒子,先一个个放入盒内,而拿出的时候只有先从上面拿,才能再拿下面。
栈(stack)又名堆栈,它是一种运算受限的线性表。其限制是仅允许在表的一端进行插入和删除运算。这一端被称为栈顶,相对地,把另一端称为栈底。向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
作者:darkfantastic
来源:https://blog.csdn.net/weixin_40409754/article/details/79747126
「民间解析」
- 解法1
(1)每次留一个数,有4种可能
(2)每次留两个数,有6种可能
(3)每次留三个数,有3种可能
(4)每次留四个数,有1种可能
来源:https://www.nowcoder.com/test/question/done?tid=24999724&qid=163511#summary
作者:凯里欧文1- 解法2
使用卡特兰公式:n=(2n)!/n!*(n+1)!
来源:https://www.nowcoder.com/test/question/done?tid=24999724&qid=163511#summary
作者:天上的星星
8. 有2个关系模式:
订单表:R(订单号,日期,客户名称,收货人)
订单明细表:S(订单号,商品编码,单价,数量)
若要检索2017/1/1到2017/12/31期间,订购商品的总金额超过20000元的客户名称和总金额,则SQL查询语句是
A. SELECT 客户名称,单价*数量 AS 总金额 FROM R,S WHERE 日期 BETWEEN "2017-1-1"AND "2017-12-31" AND 单价*数量>20000
B. SELECT 客户名称, SUM(单价*数量) AS 总金额 FROM R,S WHERE R.订单号= S.订单号 AND日期 BETWEEN "2017-1-1" AND "2017-12-31" GROUP BY 客户名称 HAVING 单价*数量>20000
C. SELECT 客户名称, SUM (单价*数量) AS 总金额 FROM R,S WHERE R.订单号= S.订单号 AND 日期 BETWEEN "2017-1-1" AND "2017-12-31" GROUP BY 客户名称 HAVING SUM(单价*数量)>20000
D. SELECT 客户名称,单价*数量 AS 总金额 FROM R,S WHERE R.订单号= S.订单号 AND 日期 BETWEEN "2017-1-1" AND "2017-12-31" GROUP BY 客户名称 HAVING 单价*数量>20000
正确答案:C
「题目解析」
- 两张表通过关键字 “订单号” 连接;
- 总金额 用 SUM (单价*数量) 计算;
- 按照 “客户名称”分组统计,因此 GROUP BY 客户名称;
- 「订购商品的总金额超过20000元」,用HAVING限制总金额数量;
- 「检索2017/1/1到2017/12/31期间」,用BETWEEN。
9. 下列属于有监督学习算法的是:()
A. 谱聚类
B. 主成分分析PCA
C. 主题模型LDA
D. 线性判别分析LDA
正确答案:D
? 谱聚类
谱聚类是从图论中演化出来的算法,后来在聚类中得到了广泛的应用。它的主要思想是把所有的数据看做空间中的点,这些点之间可以用边连接起来。距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,通过对所有数据点组成的图进行切图,让切图后不同的子图间边权重和尽可能的低,而子图内的边权重和尽可能的高,从而达到聚类的目的。
- 与传统的聚类算法相比,它具有能在任意形状的样本空间上聚类且收敛于全局最优解的优点。
?主题模型
LDA(Latent dirichlet allocation)[1]是有Blei于2003年提出的三层贝叶斯主题模型,通过无监督的学习方法发现文本中隐含的主题信息,目的是要以无指导学习的方法从文本中发现隐含的语义维度-即“Topic”或者“Concept”。
传统判断两个文档相似性的方法是通过查看两个文档共同出现的单词的多少,如TF-IDF等,这种方法没有考虑到文字背后的语义关联,可能在两个文档共同出现的单词很少甚至没有,但两个文档是相似的。
举个例子,有两个句子分别如下:
“乔布斯离我们而去了。”
“苹果价格会不会降?”
可以看到上面这两个句子没有共同出现的单词,但这两个句子是相似的,如果按传统的方法判断这两个句子肯定不相似,所以在判断文档相关性的时候需要考虑到文档的语义,而语义挖掘的利器是主题模型,LDA就是其中一种比较有效的模型。
在主题模型中,主题表示一个概念、一个方面,表现为一系列相关的单词,是这些单词的条件概率。形象来说,主题就是一个桶,里面装了出现概率较高的单词,这些单词与这个主题有很强的相关性。
怎样才能生成主题?对文章的主题应该怎么分析?这是主题模型要解决的问题。
作者:huagong_adu
来源:https://blog.csdn.net/huagong_adu/article/details/7937616
?主成分分析PCA ? 线性判别分析LDA
PCA是一种无监督的数据降维方法,与之不同的是LDA是一种有监督的数据降维方法。
从几何的角度来看,PCA和LDA都是讲数据投影到新的相互正交的坐标轴上。只不过在投影的过程中他们使用的约束是不同的,也可以说目标是不同的。
- PCA是将数据投影到方差最大的几个相互正交的方向上,以期待保留最多的样本信息。样本的方差越大表示样本的多样性越好,在训练模型的时候,我们当然希望数据的差别越大越好。否则即使样本很多但是他们彼此相似或者相同,提供的样本信息将相同,相当于只有很少的样本提供信息是有用的。样本信息不足将导致模型性能不够理想。这就是PCA降维的目标:将数据投影到方差最大的几个相互正交的方向上。
- LDA降维的目标:将带有标签的数据降维,投影到低维空间同时满足三个条件:
- 尽可能多地保留数据样本的信息(即选择最大的特征是对应的特征向量所代表的的方向)。
- 寻找使样本尽可能好分的最佳投影方向。
- 投影后使得同类样本尽可能近,不同类样本尽可能远。
作者:Lavi_qq_2910138025
来源:https://blog.csdn.net/liuweiyuxiang/article/details/78874106
- 强烈参考
- 《转:谱聚类(spectral clustering)原理总结》https://www.cnblogs.com/lm3306/p/9308107.html
- 《文本主题模型之LDA》https://blog.csdn.net/u010417185/article/details/80833212
- 《主题模型-LDA浅析》 https://blog.csdn.net/huagong_adu/article/details/7937616
- 《线性判别分析(LDA)》 https://blog.csdn.net/liuweiyuxiang/article/details/78874106
10. 统计网站的注册用户年龄,已知均值是25岁,标准差为2,则用户年龄在21-29岁的概率至少是多少?
A. 60%
B. 65%
C. 70%
D. 75%
正确答案:D
?切比雪夫不等式
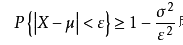
「题目解析」
P { |X - 25| < 4 } >= 1 - 2^2 / 4 ^2 = 0.75
- 参考资料
《基本极限定理(切比雪夫不等式,大数定律,中心极限定理)》https://blog.csdn.net/CSDN___CSDN/article/details/81704930
11. 假设A国人的平均身高为170cm,标准差为10cm,平均体重为65KG,标准差为5kg,身高与体重均符合正态分布,它们之间的线性相关系数为0.5,那么身高为186cm的A国人平均体重为:
A. 65kg
B. 69kg
C. 73kg
D. 77kg
正确答案:B
(待解析~)
12. 一个序列为(13,18,24,35,47,50,63,83,90,115,124),如果利用二分法查找关键字为90的,则需要几次比较 ?
A. 1
B. 2
C. 3
D. 4
正确答案:B
「题目解析」
第一次在50处二分,90大于50;
第二次在50到124这段二分,找到90。
13. 已知一个二叉树前序遍历和中序遍历分别为ABDEGCFH和DBGEACHF,则该二叉树的后序遍历为?
A. DGEBHFCA
B. DGEBHFAC
C. GEDBHFCA
D. ABCDEFGH
正确答案:A
?二叉树(重复出现的知识点)
「题目解析」
前序遍历和中序遍历可以唯一确定一个二叉树,二叉树为
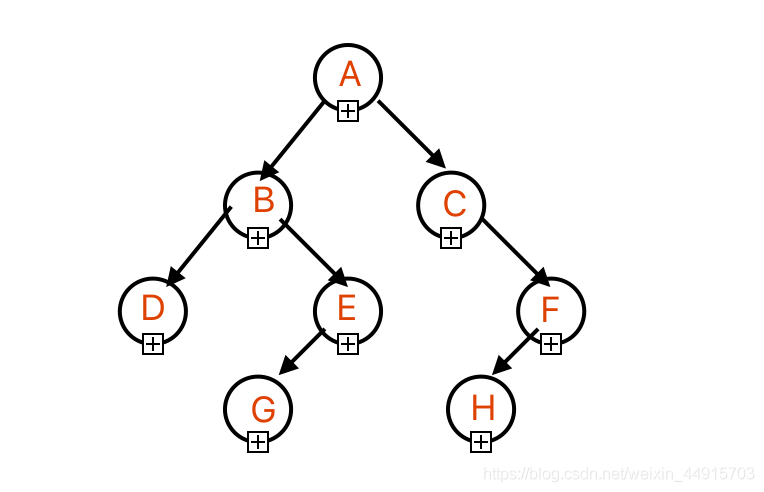
- 举一反三
- 《京东2019春招京东数据分析类试卷》第2题;
- 《网易2018校园招聘数据分析工程师笔试卷》第1题;
- 《京东2019校招数据分析工程师笔试题》第9题;
14. 一个医院的病人,40%来自甲地,60%来自乙地,甲地病人为A病的概率为1%,乙地病人为A病的概率为2%,现在这个医院一个得A病的人,来自甲地的概率为?
A. 0.15
B. 0.25
C. 0.4
D. 0.5
正确答案:B
?贝叶斯公式(重复出现的知识点)
「题目解析」
已知P(甲) = 0.4,P(乙)=0.6,P(A|甲)=0.01,P(A|乙)=0.02,则
P(A) = 0.4 * 0.01 + 0.6 * 0.02 = 0.016
P(甲|A)=P(A|甲) * P(甲) / P(A)=0.25
- 举一反三
- 《京东2019春招京东数据分析类试卷》第26题;
- 《网易2018校园招聘数据分析工程师笔试卷》第9题;
- 《京东2019校招数据分析工程师笔试题》第57题;
15. 在贝叶斯线性回归中, 假定似然概率和先验概率都为高斯分布, 假设先验概率的高斯准确率参数为a, 似然概率的高斯准确率参数为b, 则后验概率相当于平方误差+L2正则,则其正则化参数为
A. a + b
B. a / b
C. a^2 + b^2
D. a^ 2 / (b^2)
官方答案:A
民间答案:C
(求解答~)
16. 以下关于准确率,召回, f1-score说法错误的是:
A. 准确率为TP/(TP+FP)
B. 召回率为TP/(TP + FN)
C. f1-score为 2TP/(2TP + FP + FN)
D. f1-score为 准确率*召回率/(准确率+召回率)
正确答案:D
「题目解析」
f1-score 是 准确率和召回率的调和平均值;f1-score为 2 * 准确率*召回率/(准确率+召回率)。
?分类器的评价指标
- ROC曲线 接收者操作特征(receiveroperating
characteristic),roc曲线上每个点反映着对同一信号刺激的感受性。 横轴:(1-Specificity)
纵轴:Sensitivity(正类覆盖率)Specificity = TN / Total actual negative Sensitivity = TP / Total
actual positive = TP / (TP+FN)
AUC
ROC曲线与轴围成的面积Recall
Recall 即 Sensitivity = TP / Total actual positivePrecision
Precision = TP / Total predicted positiveAccuracy
Accuracy = (TP+TN) / TotalF1:
Precision和Recall的调和均值 2/ F1 = 1/Precision + 1/Recall
- 举一反三
《小红书2019年校园招聘数据分析岗位在线笔试第一批》第4题。
17. 在MySQL中,与语句SELECT * FROM user WHERE age NOT BETWEEN 30 AND 70;等价的是()
A. SELECT * FROM user WHERE age<=30 OR age>=70;
B. SELECT * FROM user WHERE age<30 OR age>70;
C. SELECT * FROM user WHERE age>=30 OR age<=70;
D. SELECT * FROM user WHERE age>30 OR age<70;
正确答案:B
「题目解析」
BETWEEN 30 AND 70 等价于 小于30或大于70。
18. 把14,27,71,50,93,39按顺序插入一棵树,插入的过程不断调整使树为平衡排序二叉树,最终形成平衡排序二叉树高度为?
A. 3
B. 4
C. 5
D. 6
正确答案:A
?平衡二叉树
- 二叉排序树(Binary Sort Tree)
或者是一颗空树;或者是具有以下性质的二叉树:
(1)若它的左子树不为空,则左子树上的所有值均小于它根节点上的值;
(2)若它的右子树不为空,则右子树上的值均大于根结点的值;
(3)它的左右子树也分别为二叉排序树- 平衡二叉树(Balanced Binary Tree或Height—Balanced Tree)
又称AVL树,它或者是一颗空树,或者是具有下列性质的二叉树:它的左右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值不超过1。若将二叉树节点的平衡因子BF(Balanced Factor)定义为该节点的左子树的深度减去它的右子树的深度,则平衡二叉树的所有节点的平衡因子只可能是-1,0或1。若有一个节点的平衡因子的绝对值大于一,则该二叉树就是不平衡的
作者:学习中呢
来源:https://blog.csdn.net/m0_37402140/article/details/77941031
「题目解析」
根据定义,个人尝试构造如下平衡二叉树,
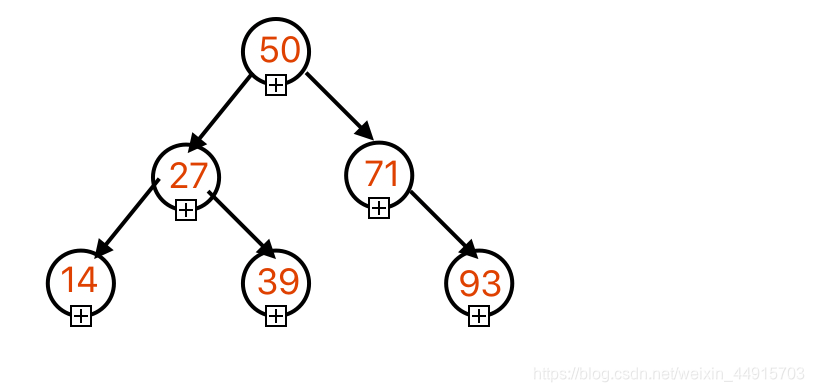
初学,如有错误,欢迎评论指正~
- 参考推荐
- https://zhidao.baidu.com/question/2016335253560660588.html
- 《二叉排序树和平衡二叉树》https://blog.csdn.net/m0_37402140/article/details/77941031
- 《平衡二叉树,AVL树之图解篇》https://www.cnblogs.com/suimeng/p/4560056.html
19. 现有testfile文件内容如下所示
12
12
213
5434
3123
123
34
对所有数字求和,以下做法正确的是:
A. awk 'BEGIN{sum}{sum+$1}END{print sum}' testfile
B. awk 'BEGIN{sum =0}{sum+=$1}END{print sum}' testfile
C. awk '{sum+$1}END{print sum}' testfile
D. awk '{sum+=$1}END{print sum}' testfile
正确答案:B D
?awk命令形式
awk [-F|-f|-v] ‘BEGIN{} // {command1; command2} END{}’ file
awk ' pattern {action} '
- 参考资料
- 《awk 用法(使用入门)》https://www.cnblogs.com/emanlee/p/3327576.html
- 《awk用法详解》https://www.cnblogs.com/ginsonwang/p/5102668.html
20. 以下关于HTTP说法正确是的:
A. HTTP POST方式比GET更安全
B. HTTP GET请求提交参数没有长度限制
C. HTTP POST请求提交参数没有长度限制
D. HTTP GET和POST请求提交参数都没有长度限制
正确答案:A C
?HTTP GET ? POST
- HTTP
超文本传输协议(HTTP)的设计目的是保证客户机与服务器之间的通信。
HTTP 的工作方式是客户机与服务器之间的请求-应答协议。
举例:客户端(浏览器)向服务器提交 HTTP 请求;服务器向客户端返回响应。响应包含关于请求的状态信息以及可能被请求的内容。- GET - 从指定的资源请求数据。
- POST - 向指定的资源提交要被处理的数据
来源:http://www.w3school.com.cn/tags/html_ref_httpmethods.asp
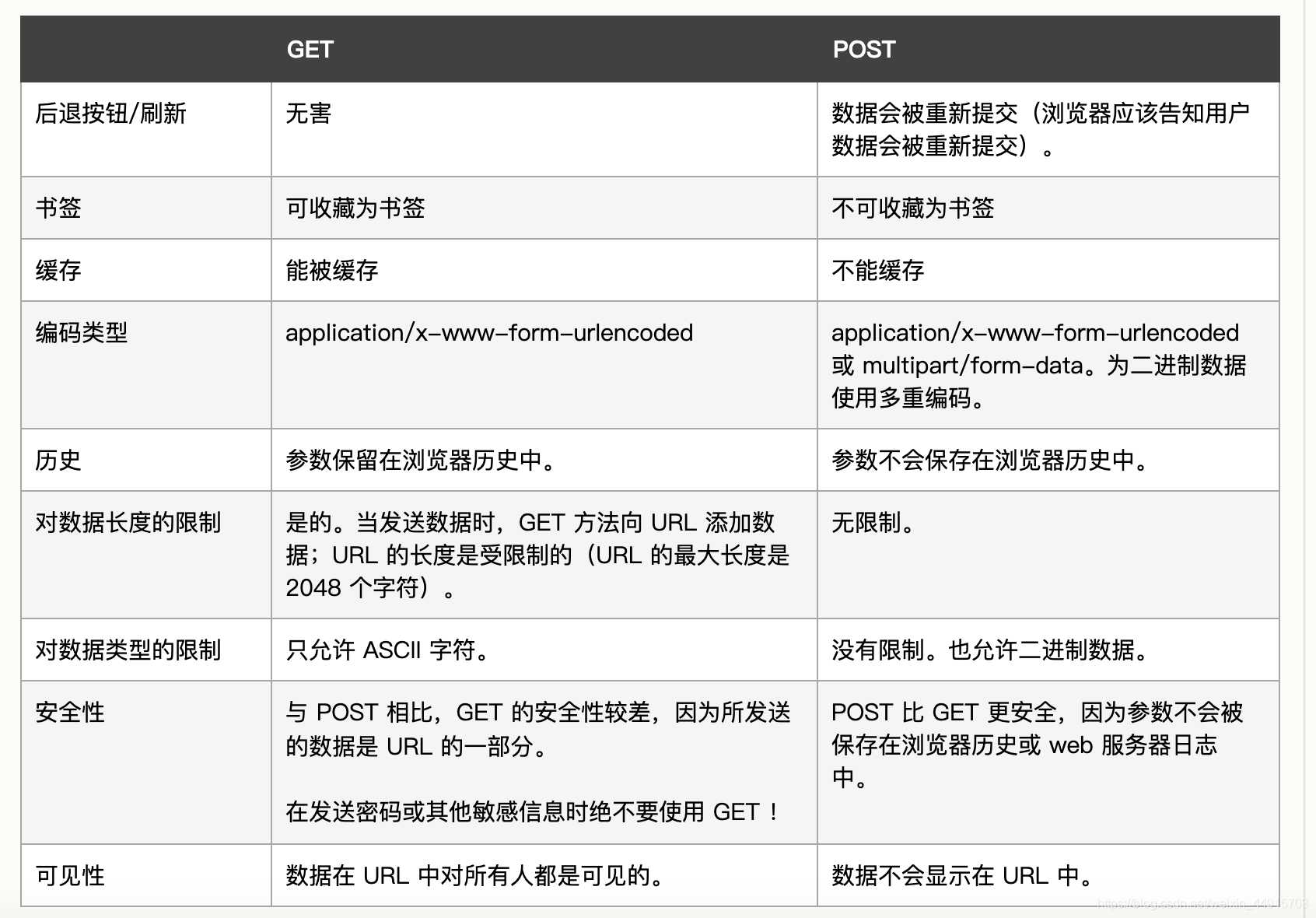
- 强烈参考
《HTTP 方法:GET 对比 POST》http://www.w3school.com.cn/tags/html_ref_httpmethods.asp
21. python代码如下:
foo = [1,2]
foo1 = foo
foo.append(3)
A. foo 值为[1,2]
B. foo 值为[1,2,3]
C. foo1 值为[1,2]
D. foo1 值为[1,2,3]
正确答案:B D
「民间解析」
第二行foo1 = foo,是将fool的地址赋予给fool,即foo与foo1指向内存中同一地址。
第三行当执行foo.append时,因为python中列表的值是可以变化的。所以就在原来的存放foo的内存地址改变了foo的值,由最初的[1, 2]变为[1, 2, 3]。由于foo1和foo 是指向同一地址空间的索引,所以当foo内存地址所存储的值被改变时,打印foo1时,foo1的值也变化了。
来源:https://www.nowcoder.com/test/question/done?tid=24999724&qid=163525#summary
作者:180827
22. 协同过滤经常被用于推荐系统, 包含基于内存的协同过滤, 基于模型的协同过滤以及混合模型, 以下说法正确的是
A. 基于模型的协同过滤能比较好的处理数据稀疏的问题
B. 基于模型的协同过滤不需要item的内容信息
C. 基于内存的协同过滤可以较好解决冷启动问题
D. 基于内存的协同过滤实现比较简单, 新数据可以较方便的加入
正确答案:A D
?协同过滤
先举个生活中的场景,你想听歌却不知道听什么的时候,会向你身边与你品位类似的朋友求助,从而获得他的推荐。协同过滤(Collaborative Filtering,简称CF)就像与你品味相近的朋友,通过对大量结构化数据进行计算,找出与你相似的其他用户(user)或与你喜欢的物品(item)相似的物品,从而实现物品推荐。
- 协同过滤分为两类:
(1) 基于用户的协同过滤(User-Based CF),即基于内存的协同过滤;
(2) 基于物品的协同过滤(Item-Based CF),即基于模型的协同过滤。
? 基于用户的协同过滤
基于用户的协同过滤又称为内存型协同过滤,需要将所有数据都保存在内存中进行计算;我们将一个用户和其他所有用户进行对比找到相似的人。
- 这种算法有两个弊端:
(1) 扩展性 随着用户年年的增加,其计算量也会增加,这种算法在只有几千个用户的情况下能够工作的很好,但达到一百万个用户时就会出现瓶颈;
(2) 稀疏性 大多数推荐系统中,物品的数量要远大于用户的数量,因此用户仅仅对一小部分物品进行评价,这就造成了数据的稀疏性。
来源:https://www.jianshu.com/p/74adaf07fa14
?基于物品的协同过滤
基于物品的协同过滤又称为基于模型的协同过滤,不需要保存所有的数据,而是通过构建一个物品相似度模型来获取结果。
来源:https://www.jianshu.com/p/74adaf07fa14
?冷启动
「冷启动」包含两个层面:
- 用户的冷启动
新的用户因为没有在产品上留下行为数据,自然无法得知他/她的喜好,从而做出靠谱的推荐。这时一般需要借助用户的背景资料,或者引导性地让用户选择,或者暂时用热门启动替代个性化推荐来解决,在线推荐系统可以做到在用户产生行为数据后立马更新推荐列表。- 物品的冷启动
主要适用于ItemBased的场景,即对一个物品推类似的物品,因为新物品还没有用户行为数据,自然也就没有办法通过协同过滤的方式进行推荐,这时一般会利用物品属性的相关程度来解决。作者:寻叶亭
来源:https://www.jianshu.com/p/03bf81f9f6d9
- 强烈参考
- 《第二章:基于物品(模型)的协同过滤》https://www.jianshu.com/p/74adaf07fa14
- 《三分钟了解协同过滤算法》http://www.woshipm.com/pd/934582.html
- 《协同过滤之冷启动》https://www.jianshu.com/p/03bf81f9f6d9
23. 以下有关SQL性能优化正确的是:
A. sql需要避免在索引字段上使用函数
B. 避免在WHERE子句中使用in,not in , 可以使用exist和not exist代替
C. 将对于同一个表格的多个字段的操作写到同一个sql中, 而不是分开成两个sql语句实现
D. 避免建立索引的列中使用空值
正确答案:A B C D
24. 如下哪些sql语句能查询出每门课都都大于80分的学生姓名,部分数据如下表(student_score)所示,
| stu_no | stu_name | sub_no | sub_name | score |
|---|---|---|---|---|
| 1 | 张三 | 001 | 语文 | 90 |
| 1 | 张三 | 002 | 数学 | 60 |
| 2 | 李四 | 001 | 语文 | 89 |
| 2 | 李四 | 002 | 数学 | 86 |
A. select distinct stu_name from student_score where stu_name not in (select distinct stu_name from student_score where score <= 80)
B. select stu_name from student_score group by stu_name having min(score) > 80
C. select distinct stu_name from student_score where score > 80
D. select stu_name from student_score group by sub_name having min(score) > 80
正确答案:A B
「民间解析」
A:子查询语句找出有(至少一门)成绩小于80的学生姓名,主语句要求学生姓名不在子查询的结果中,正确
B:分数最低的一门大于80,正确
C:有一门大于80,就被选中了,不对
D:sub_name应该换成stu_name,否则不对,会报错
来源:https://www.nowcoder.com/test/question/done?tid=24999724&qid=163528#summary
作者:为什么邮箱还是空的。。
25. 两个随机变量x,y,服从联合概率分布p(x,y), 以下等式成立的有

正确答案:A C
?全期望公式
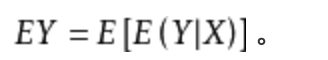
求方差,
var(X)=var[E(X|Y)]+E[var(X|Y)]
26. 东东从京京那里了解到有一个无限长的数字序列: 1, 2, 2, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 5, 5, …(数字k在该序列中正好出现k次)。东东想知道这个数字序列的第n项是多少,你能帮帮他么
「思路」
假设第n项为k,则一共有 1 + 2 + … + k = (1+k) * k / 2 项,这个数大于或等于n。解方程,解出k,并用ceil向上取整即可。
「我的代码」
import math
def fun(n):
k = math.sqrt(0.25+2*n)-0.5
return math.ceil(k)
n = int(input())
print(fun(n))
27. 东东对幂运算很感兴趣,在学习的过程中东东发现了一些有趣的性质: 9^3 = 27^2, 2^10 = 32^2
东东对这个性质充满了好奇,东东现在给出一个整数n,希望你能帮助他求出满足 a^b = c^d(1 ≤ a,b,c,d ≤ n)的式子有多少个。
例如当n = 2: 11=11
11=12
12=11
12=12
21=21
22=22
一共有6个满足要求的式子
- 输入描述:
输入包括一个整数n(1≤n≤10^6) - 输出描述:
输出一个整数,表示满足要求的式子个数。因为答案可能很大,输出对1000000007求模的结果 - 输入示例:
2 - 输出示例:
6
「民间思路」
对等式取对数 bloga =dlogc ,b/d=logc/loga,logc/loga是有理分式,c和a一定可以表示成同一个底数的幂,所以外层循环就是对底数遍历,内循环对logc和loga遍历,相当于对c和a遍历但时间复杂度变为对数,对于每一个logc和loga,已知b/d求b和d的个数,其实就是n/(b和d最大公约数),所有加起来再考虑一下特殊情况就行了。
作者:北交大李国杰
链接:https://www.nowcoder.com/questionTerminal/0c564191e8c24f35a784a9363868ea09
「民间代码」
链接:https://www.nowcoder.com/questionTerminal/0c564191e8c24f35a784a9363868ea09
来源:牛客网
import math
def gcd(a,b):
a,b=min(a,b),max(a,b)
for i in range(1,a+1):
if a%i==0 and b%i==0:
cd=i
return cd
n=int(input())
mode=int(1e9+7)
rec=[0]*(n+1)
res=n*(2*n-1)%mode
for i in range(2,n+1):
if rec[i]:
continue
else:
rec[i]=1
lgn=round(math.log(n,i))
if pow(i,lgn)>n:
lgn = lgn-1
for lga in range(1,lgn):
rec[i**lga]=1
for lgc in range(lga+1,lgn+1):
res+=(n//(lgc//gcd(lga,lgc))*2)
res=res%mode
print(res)
28. 以下属于凸函数的是
A. e的x次方
B. x的a次方
C. log(x)
D. f(x, y) = x的平方/y
正确答案:A D
?凸函数
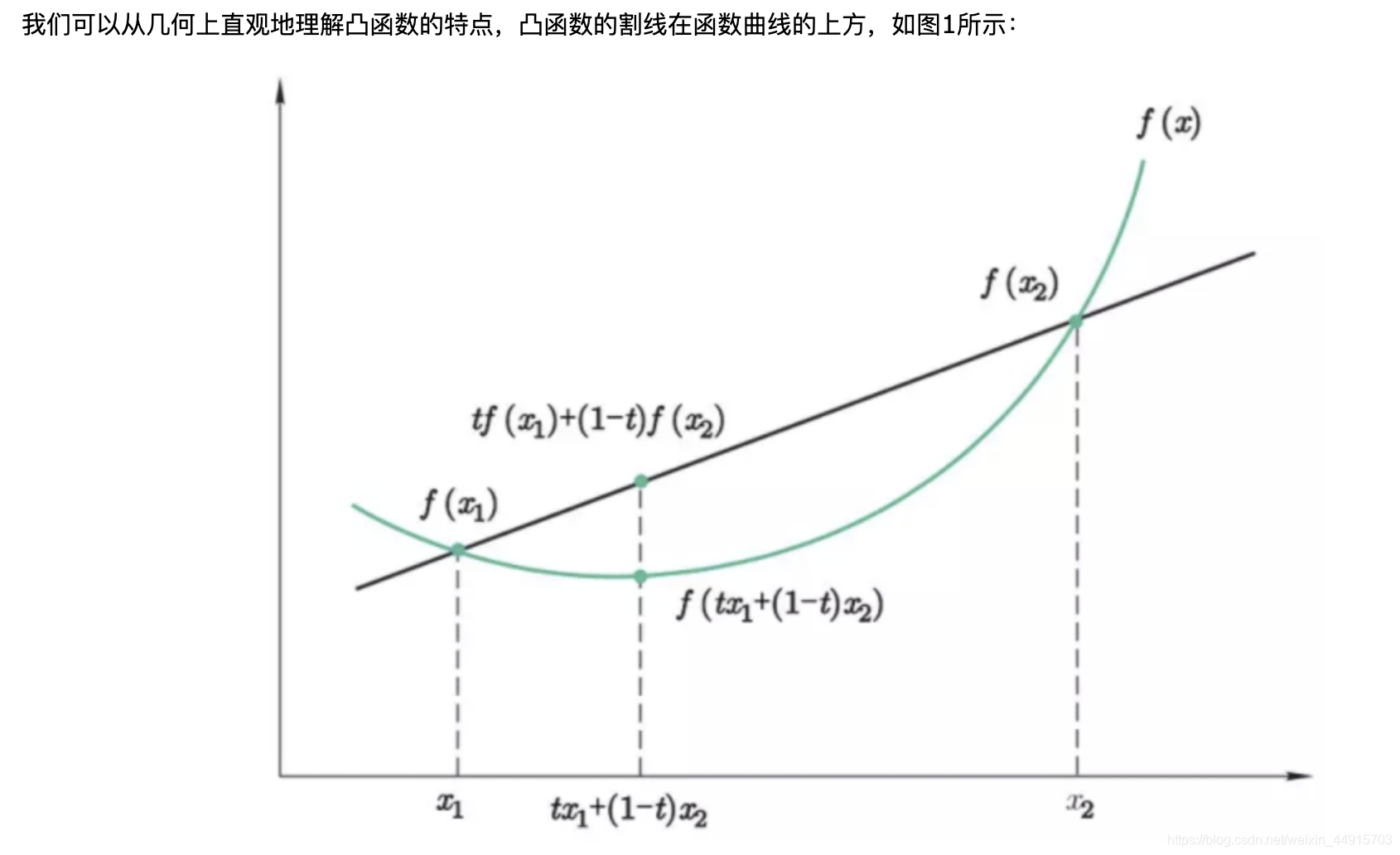
来源:https://www.cnblogs.com/always-fight/p/9377554.html
(待解析D~)
29. 以下关于二项分布说法正确的是
A. 二项分布是一种离散概率分布,表示在n次伯努利试验中, 试验k次才得到第一次成功的概率
B. 二项分布是一种离散概率分布,表示在n次伯努利试验中,有k次成功的概率
C. 当n很大时候,二项分布可以用泊松分布和高斯分布逼近
D. 当n很大时候,二项分布可以用高斯分布逼近,但不能用泊松分布逼近
正确答案:B C
?正态分布 ? 二项分布 ? 泊松分布
- 正态分布是所有分布趋于极限大样本的分布,属于连续分布;二项分布与泊松分布则都是离散分布。
- 二项分布的极限分布是泊松分布。泊松分布的极限分布是正态分布,即np=λ,当n很大时,可以近似相等。
来源:https://www.zybang.com/question/08b603a5dfae3b33c5ec2af82e9fdf6f.html
30. 在机器学习中,经常采用线性变换,将基变换为正交基, 下列矩阵式正交矩阵的是

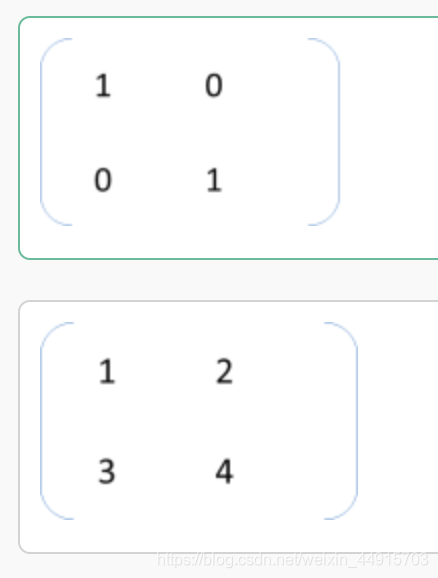
正确答案:A C
?正交矩阵
AAT=I,则A为正交矩阵。
31. 用浏览器访问www.jd.com时,可能使用到的协议有?
A. MAC
B. HTTP
C. SMTP
D. ARP
E. RTSP
正确答案:A B D
(待解析~)
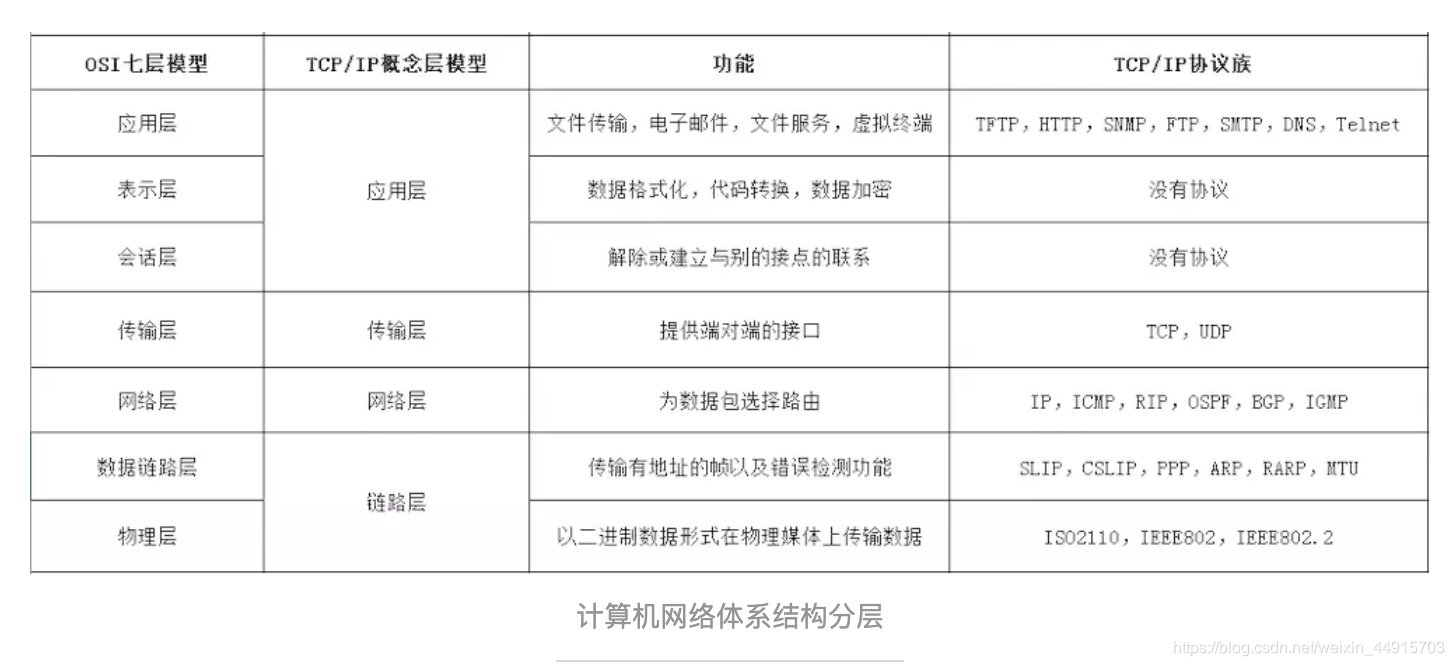
来源:https://www.jianshu.com/p/9f3e879a4c9c
- 举一反三
《京东2019校招数据分析工程师笔试题》第23题。
32. 有A,B 两个国家,人口比例为4:6,A国的犯罪率为0.1%,B国的为0.2%。现在有一个新的犯罪事件,发生在A国的概率是?
A. 0.15
B. 0.25
C. 0.35
D. 0.45
正确答案:B
「题目解析」
A国犯罪的期望 = 0.4 * 0.1%
犯罪的期望 = 0.4 * 0.1% + 0.6 * 0.2%
在A国犯罪的概率 = (0.4 * 0.1%) / (0.4 * 0.1% + 0.6 * 0.2%)=0.25














 123
123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









