









「牛客网SQL实战二刷」是个系列学习笔记博文,今天解析7道SQL题目~ 第55 - 61题。
每篇笔记的格式大致为,三大板块:
- 大纲
- 题目(题目描述、思路、代码、相关参考资料/答疑)
- 回顾
❤️「往期回顾」
一、大纲
| 题号 | 知识点 |
|---|---|
| 55 | LIMIT,OFFSET |
| 56 | LEFT JOIN |
| 57 | NOT EXISTS |
| 58 | 求交集 |
| 59 | CASE WHEN |
| 60 | 表复用计算累加和 |
| 61 | 表复用计算行数 |
二、题目
55. 分页查询employees表,每5行一页,返回第2页的数据
- 题目描述
分页查询employees表,每5行一页,返回第2页的数据
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
- 思路
转化一下题意,「每5行一页,返回第2页的数据」,即返回第6~10条记录,用LIMIT 搭配 OFFSET 使用。
- 代码
SELECT * FROM employees LIMIT 5 OFFSET 5;
?Limit 与offset
举个例子,LIMIT 3 OFFSET 1, 这意味着,跳过第1条记录(即从第2条记录开始),返回接下来3条记录。即最终得到,原本的第2,3,4条记录。
- 举一反三
《牛客网SQL实战二刷 | Day1》第2题。
- 参考资料
《SQLite Limit 子句》https://www.runoob.com/sqlite/sqlite-limit-clause.html
56. 获取所有员工的emp_no
- 题目描述
获取所有员工的emp_no、部门编号dept_no以及对应的bonus类型btype和recevied,没有分配具体的员工不显示
CREATE TABLE `dept_emp` ( `emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
create table emp_bonus(
emp_no int not null,
recevied datetime not null,
btype smallint not null);
- 输出描述
| e.emp_no | dept_no | btype | recevied |
|---|---|---|---|
| 10001 | d001 | 1 | 2010-01-01 |
| 10002 | d001 | 2 | 2010-10-01 |
| 10003 | d004 | 3 | 2011-12-03 |
| 10004 | d004 | 1 | 2010-01-01 |
| 10005 | d003 | ||
| 10006 | d002 | ||
| 10007 | d005 | ||
| 10008 | d005 | ||
| 10009 | d006 |
- 思路
表dept_emp 左连接 表emp_bonus。
- 代码
SELECT de.emp_no, de.dept_no, eb.btype, eb.recevied
FROM dept_emp AS de LEFT JOIN emp_bonus AS eb ON
de.emp_no = eb.emp_no;
57. 使用含有关键字exists查找未分配具体部门的员工的所有信息。
- 题目描述
使用含有关键字exists查找未分配具体部门的员工的所有信息。
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
- 输出描述
| emp_no | birth_date | first_name | last_name | gender | hire_date |
|---|---|---|---|---|---|
| 10011 | 1953-11-07 | Mary | Sluis | F | 1990-01-22 |
- 思路
- 本题用 EXISTS 关键字的方法如下:意为在 employees 中挑选出令(SELECT emp_no FROM dept_emp WHERE emp_no = employees.emp_no)不成立的记录,也就是当 employees.emp_no=10011的时候。反之,把NOT去掉,则输出 employees.emp_no=10001~10010时的记录。
- 由于 OJ系统没有限制我们只能使用 EXISTS 关键字,因此还能用 NOT IN 关键字替换,即在employees 中选出 dept_emp 中没有的 emp_no。
作者:wasrehpic
来源:https://www.nowcoder.com/questionTerminal/c39cbfbd111a4d92b221acec1c7c1484?f=discussion
- 代码
- 方法一、NOT EXISTS
SELECT * FROM employees
WHERE NOT EXISTS (SELECT emp_no FROM dept_emp WHERE emp_no = employees.emp_no)
- 方法二、NOT IN
SELECT * FROM employees
WHERE emp_no NOT IN (SELECT emp_no FROM dept_emp)
58. 获取employees中的行数据,且这些行也存在于emp_v中
- 题目描述
存在如下的视图:
create view emp_v as select * from employees where emp_no >10005;
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
获取employees中的行数据,且这些行也存在于emp_v中。注意不能使用intersect关键字。
- 输出描述
| emp_no | birth_date | first_name | last_name | gender | hire_date |
|---|---|---|---|---|---|
| 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 |
| 10007 | 1957-05-23 | Tzvetan | Zielinski | F | 1989-02-10 |
| 10008 | 1958-02-19 | Saniya | Kalloufi | M | 1994-09-15 |
| 10009 | 1952-04-19 | Sumant | Peac | F | 1985-02-18 |
| 10010 | 1963-06-01 | Duangkaew | Piveteau | F | 1989-08-24 |
| 10011 | 1953-11-07 | Mary | Sluis | F | 1990-01-22 |
- 思路
根据题意,不能使用 INTERSECT 关键字,但由于视图 emp_v 的记录是从 employees 中导出的,因此要判断两者中相等的数据,只需要判断emp_no相等即可。
- 方法一:用 WHERE 选取二者 emp_no 相等的记录
- 方法二:由于emp_v的全部记录均由 employees 导出,因此可以投机取巧,直接输出 emp_v 所有记录
- 代码
- 方法一
SELECT em.* FROM employees AS em, emp_v AS ev WHERE em.emp_no = ev.emp_no;
- 方法二
SELECT * FROM emp_v;
- 方法三:OJ系统限制了,但是如果用INTERSECT实现
SELECT * FROM emp_v INTERSECT SELECT * FROM employees
- 举一反三
《牛客网SQL实战二刷 | Day8》第47题。
59. 获取有奖金的员工相关信息。
- 题目描述
获取有奖金的员工相关信息。
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
create table emp_bonus(
emp_no int not null,
recevied datetime not null,
btype smallint not null);
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL, PRIMARY KEY (`emp_no`,`from_date`));
给出emp_no、first_name、last_name、奖金类型btype、对应的当前薪水情况salary以及奖金金额bonus。 bonus类型btype为1其奖金为薪水salary的10%,btype为2其奖金为薪水的20%,其他类型均为薪水的30%。 当前薪水表示to_date=‘9999-01-01’
- 思路
用CASE WHEN条件判断。
- 输出描述
| emp_no | first_name | last_name | btype | salary | bonus |
|---|---|---|---|---|---|
| 10001 | Georgi | Facello | 1 | 88958 | 8895.8 |
| 10002 | Bezalel | Simmel | 2 | 72527 | 14505.4 |
| 10003 | Parto | Bamford | 3 | 43311 | 12993.3 |
| 10004 | Chirstian | Koblick | 1 | 74057 | 7405.7 |
- 代码
SELECT e.emp_no, e.first_name, e.last_name, eb.btype, s.salary,
(CASE eb.btype
WHEN 1 THEN 0.1 * s.salary
WHEN 2 THEN 0.2 * s.salary
ELSE 0.3 * s.salary
END ) AS bonus
FROM employees AS e INNER JOIN emp_bonus AS eb ON e.emp_no = eb.emp_no
INNER JOIN salaries AS s ON e.emp_no = s.emp_no AND s.to_date = '9999-01-01'
?CASE WHEN
Case具有两种格式。简单Case函数和Case搜索函数。
--简单Case函数
SELECT SUM(population),
CASE (country
WHEN '中国' THEN '亚洲'
WHEN '印度' THEN '亚洲'
WHEN '日本' THEN '亚洲'
WHEN '美国' THEN '北美洲'
WHEN '加拿大' THEN '北美洲'
WHEN '墨西哥' THEN '北美洲'
ELSE '其他'
END)
FROM Table_A
--Case搜索函数
UPDATE Personnel
SET salary =
CASE (WHEN salary >= 5000 THEN salary * 0.9
WHEN salary >= 2000 AND salary < 4600 THEN salary * 1.15
ELSE salary END);
-- 用一个SQL语句完成不同条件的分组
SELECT country,
SUM( CASE WHEN sex = '1' THEN population ELSE 0 END), --男性人口
SUM( CASE WHEN sex = '2' THEN population ELSE 0 END) --女性人口
FROM Table_A GROUP BY country;
- 强烈参考
《【SQL】SQL中Case When的用法》https://www.cnblogs.com/HDK2016/p/8134802.html
?60. 统计salary的累计和running_total
- 题目描述
按照salary的累计和running_total,其中running_total为前两个员工的salary累计和,其他以此类推。 具体结果如下Demo展示。。
CREATE TABLE `salaries` ( `emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
- 输出描述
| emp_no | salary | running_total |
|---|---|---|
| 10001 | 88958 | 88958 |
| 10002 | 72527 | 161485 |
| 10003 | 43311 | 204796 |
| 10004 | 74057 | 278853 |
| 10005 | 94692 | 373545 |
| 10006 | 43311 | 416856 |
| 10007 | 88070 | 504926 |
| 10009 | 95409 | 600335 |
| 10010 | 94409 | 694744 |
| 10011 | 25828 | 720572 |
- 思路
复用 表salaries,限制s1的emp_no小于等于 s2的emp_no,再对s1的工资求和,即相当于累加。
- 代码
SELECT s2.emp_no, s2.salary, SUM(s1.salary) AS running_total
FROM salaries AS s1 INNER JOIN salaries AS s2
ON s1.emp_no <= s2.emp_no
WHERE s1.to_date = '9999-01-01' AND s2.to_date = '9999-01-01'
GROUP BY s2.emp_no
?61. 对于employees表中,给出奇数行的first_name
- 题目描述
对于employees表中,给出奇数行的first_name
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
- 输出描述
| first_name |
|---|
| Georgi |
| Chirstian |
| Anneke |
| Tzvetan |
| Saniya |
| Mary |
- 思路
- 和上一题相似的地方在于,也是表的复用,其实相当于我们自己写了语句计算row numbers;
- 「奇数行」,即行数除以2余1。
- 代码
SELECT e1.first_name FROM employees AS e1
WHERE (SELECT COUNT(*) FROM employees AS e2
WHERE e1.first_name <= e2.first_name)%2 == 1;
?SQLITE 创建rownumber
- 原表
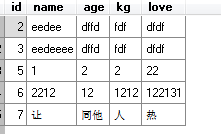
- 插入rownumber 代码实现
SELECT
( SELECT COUNT(distinct id) FROM [file] AS t2 WHERE t2.id <= t1.id) AS rowNum, id, name
FROM [file] t1
ORDER BY t1.id asc
- 新表
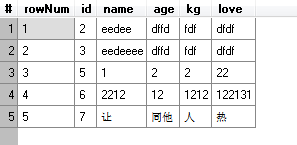
来源:http://www.onbno.com/ruanjiajiqiao/sqlite-none-row-number.html
- 强烈推荐
《sqlite没有行号(rownumber)的解决办法》 http://www.onbno.com/ruanjiajiqiao/sqlite-none-row-number.html
三、回顾
| 知识点 | 题号 |
|---|---|
| LIMIT,OFFSET | 55 |
| 表连接 | 56 |
| NOT EXISTS | 57 |
| 求交集 | 58 |
| CASE WHEN | 59 |
| 表复用 | 60,61 |
? 写在最后
Day10 是「牛客网SQL实战二刷」系列最后一天啦。坚持就是胜利,欧耶✌️
比起第一次做SQL题库,这次在前半部分查询语句的方面,明显进步很多。很多时候直接上手敲,就能通过了。不过,后半部分,大概从Day6开始,虽然代码变得短小和简单了,但是反而不那么熟悉,往往要辅助资料,也能敲出来。但我相信,这次「二刷题库」扎实了我的基础。
通过我做「真题」的体验,「数据库管理和操作」对「数据分析岗」真是非常非常非常关键和重要的了,是基础也是必须。真题里的SQL操作,结合上业务需要,比起题库里的题更具有应用性,比如「拼多多2020数据分析师真题」。我依旧有很多没见过的需求,我还有很多不会的和要掌握的。
可能还会三刷,可能接下来偏向分享「来源于真题中的,有业务背景的,对真实需求对数据库操作」。















 3121
3121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









