







只在dancetrack上复现(Windows 系统,显卡4090, torch1.13.1+cu117)
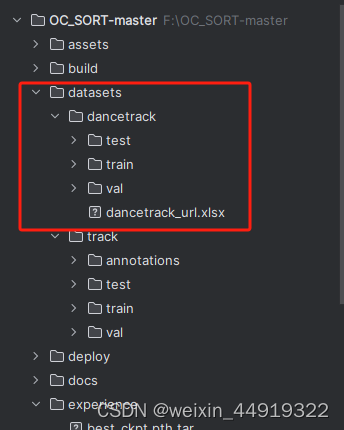
1. 下载dancetrack数据并解压,存放位置如下图
2. 安装环境
参考:ocsort 复现_oc-sort 个人数据集-CSDN博客
3. 将标签转为COCO格式
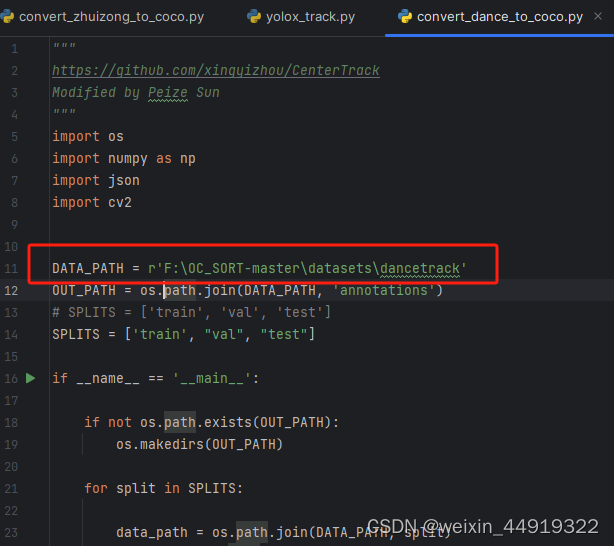
更改路径DATA_PATH为存放文件夹的绝对路径,右击run下面代码,
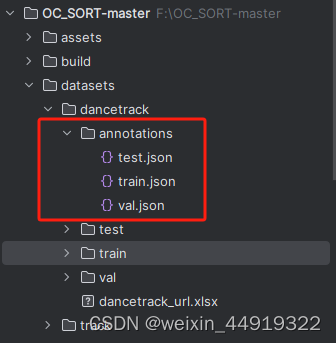
得到COCO格式的标签
4. 修改训练参数
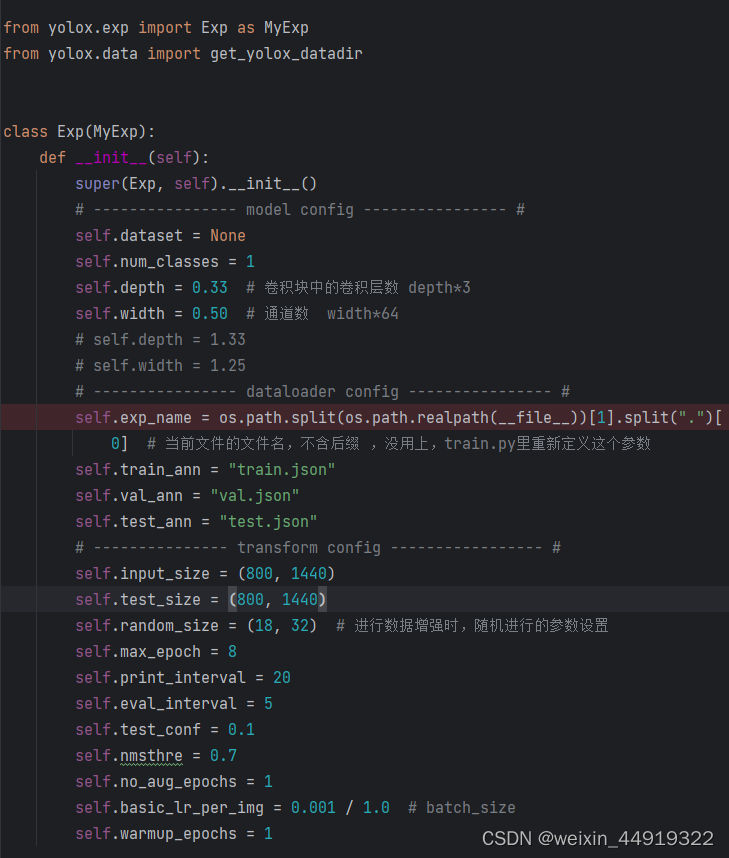
如果要更改网络的深度和宽度
self.depth = 1.33
self.width = 1.25
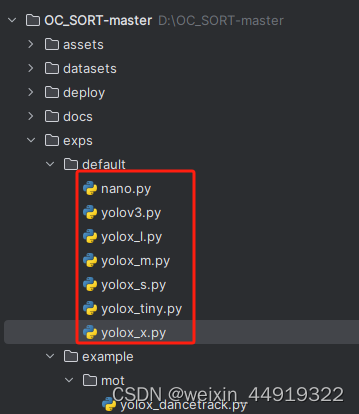
参数在下图红框文件中
5. 训练
修改训练文件train.py的参数
def make_parser():
parser = argparse.ArgumentParser("YOLOX train parser")
parser.add_argument("-expn", "--experiment-name", type=str, default=r"F:\OC_SORT-master\experience")
parser.add_argument("-n", "--name", type=str, default='yolox_x', help="yolox_x")
# distributed
parser.add_argument(
"--dist-backend", default="nccl", type=str, help="distributed backend"
)
parser.add_argument(
"--dist-url",
default=None,
type=str,
help="url used to set up distributed training",
)
parser.add_argument("-b", "--batch-size", type=int, default=4, help="batch size") # 64
parser.add_argument(
"-d", "--devices", default=None, type=int, help="device for training"
)
parser.add_argument(
"--local_rank", default=0, type=int, help="local rank for dist training"
)
parser.add_argument("-f", "--exp_file", default=r"F:\OC_SORT-master\exps\example\mot\yolox_track.py",
type=str,
help="plz input your expriment description file",
)
parser.add_argument(
"--resume", default=False, action="store_true", help="resume training"
)
parser.add_argument("-c", "--ckpt", default=r'F:\OC_SORT-master\pretrained\yolox_x.pth', type=str,
help="checkpoint file")
parser.add_argument(
"-e",
"--start_epoch",
default=None,
type=int,
help="resume training start epoch",
)
parser.add_argument(
"--num_machines", default=1, type=int, help="num of node for training"
)
parser.add_argument(
"--machine_rank", default=0, type=int, help="node rank for multi-node training"
)
parser.add_argument(
"--fp16",
dest="fp16",
default=True,
action="store_true",
help="Adopting mix precision training.",
)
parser.add_argument(
"-o",
"--occupy",
dest="occupy",
default=False,
action="store_true",
help="occupy GPU memory first for training.",
)
parser.add_argument(
"opts",
help="Modify config options using the command-line",
default=None,
nargs=argparse.REMAINDER,
)
return parser
右击运行即可。
复现自己的数据(Windows 系统,显卡4090, torch1.13.1+cu117)
1.准备自己的数据,准备数据的标签为yolov5格式
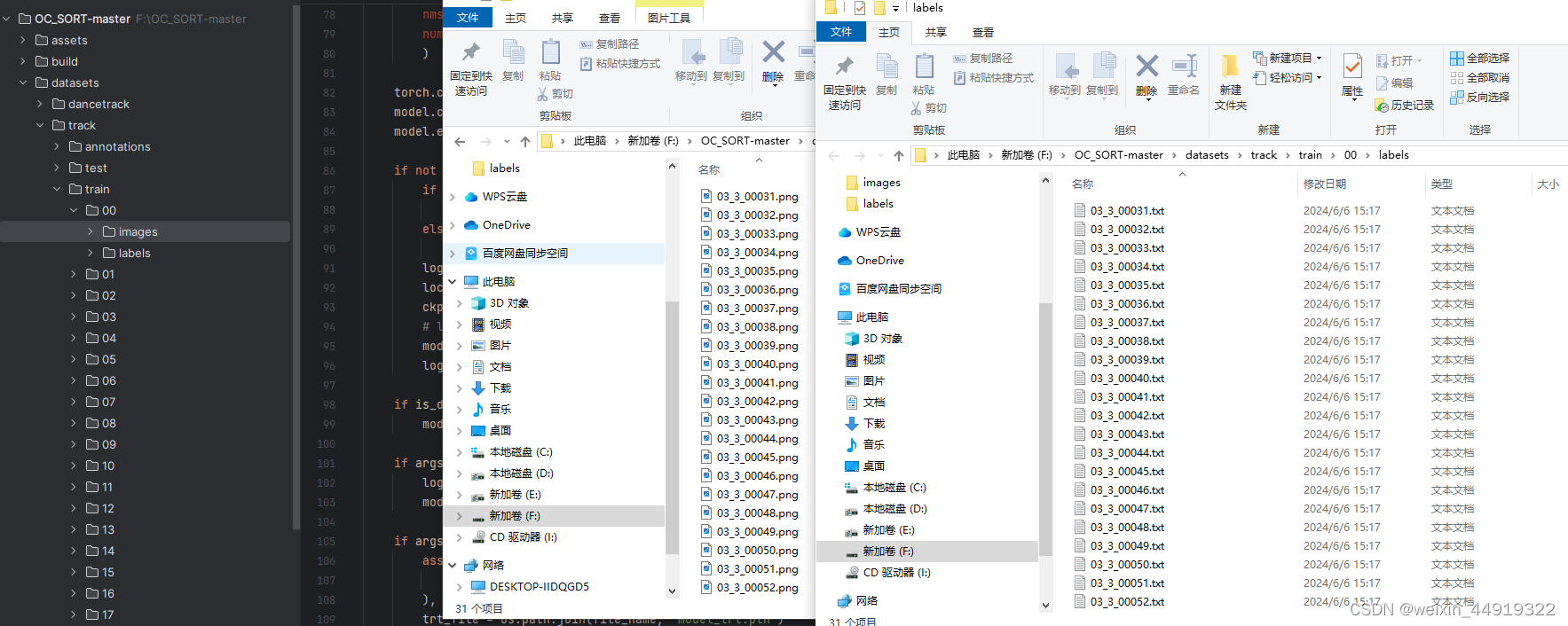
数据存放如下图, 每个文件中的图像序列为一个连续的视频采集
2. 将标签转为COCO格式
更改路径,右击运行
import os
import numpy as np
import json
import cv2
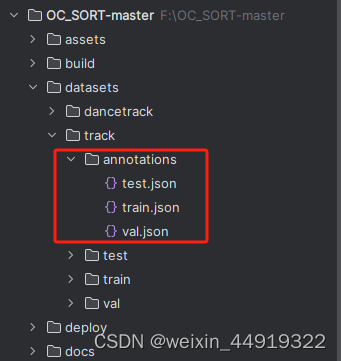
DATA_PATH = r'F:\OC_SORT-master\datasets\track'
OUT_PATH = os.path.join(DATA_PATH, 'annotations')
# SPLITS = ['train', 'val', 'test']
SPLITS = ['train', "val", "test"]
if __name__ == '__main__':
if not os.path.exists(OUT_PATH): # 创建标签json输入根目录
os.makedirs(OUT_PATH)
for split in SPLITS:
data_path = os.path.join(DATA_PATH, split) # 读取训练验证测试的根目录
out_path = os.path.join(OUT_PATH, '{}.json'.format(split)) # 输出训练验证测试的json标签文件
out = {'images': [], 'annotations': [], 'videos': [],
'categories': [{'id': 1, 'name': 'lizi'}]} # 标签中的类别字典
seqs = os.listdir(data_path) # 训练验证测试数据的序列名字
image_cnt = 0
ann_cnt = 0
video_cnt = 0
for seq in sorted(seqs): # 序列排序
print('序列: ', seq)
video_cnt += 1 # video sequence number.
out['videos'].append({'id': video_cnt, 'file_name': seq}) # video字典视频的id和序列名字
seq_path = os.path.join(data_path, seq) # 序列的路径
img_path = os.path.join(seq_path, 'images') # 序列中图片的路径
# ann_path = os.path .join(seq_path, 'gt/gt.txt') # 图像标签的路径
images = os.listdir(img_path)
num_images = len([image for image in images if 'png' in image]) # 一个序列图片的数量
for i, image_name in enumerate(os.listdir(img_path)):
image_path = os.path.join(img_path, image_name)
file_name = os.path.join(os.path.join(seq, 'images'), image_name)
img = cv2.imread(image_path)
# print("帧数: ", i)
image_id = int(image_cnt*0.05)+1
# print("图片id: ", image_id)
height, width = img.shape[:2]
image_info = {'file_name': file_name, # image name.
'id': image_id, # image number in the entire training set.
'frame_id': i+1, # image number in the video sequence, starting from 1.
# 'prev_image_id': int(i - 1) if i > 0 else -1,
# image number in the entire training set.
# 'next_image_id': int(i + 1) if i < num_images - 1 else -1,
'video_id': video_cnt,
'height': height,
'width': width}
out['images'].append(image_info)
if split != 'test':
label_path = image_path.replace('png', 'txt').replace('images', 'labels')
# print(label_path)
frame_id = i
track_id = seq # 序列名
category_id = 1 # 目标类别
if os.path.exists(label_path):
ann_cnt += 1
with open(label_path, 'r') as file:
for line in file:
parts = line.strip().split()
bbox_norm = [float(x) for x in parts[1:5]]
# 转换为COCO的bbox格式(x_min, y_min, width, height)
bbox = [(bbox_norm[0] - bbox_norm[2] / 2) * width,
(bbox_norm[1] - bbox_norm[3] / 2) * height,
bbox_norm[2] * width,
bbox_norm[3] * height
]
print("标签id: ", ann_cnt, "对应图片的帧数: ", frame_id, "序列: ", track_id)
ann = {
'id': ann_cnt,
'category_id': category_id,
'image_id': image_id,
'track_id': int(video_cnt-1),
'bbox': bbox,
'conf': float(1),
'iscrowd': 0,
'area': bbox[2] * bbox[3],
}
out['annotations'].append(ann)
image_cnt += num_images
print('loaded {} for {} images and {} samples'.format(split, len(out['images']), len(out['annotations'])))
json.dump(out, open(out_path, 'w'))
运行结束
3. 修改训练参数
复制一份yolox_dancetrack.py改名字为yolox_track.py,根据自己数据的属性更改其中参数
CTRL+f 搜索dancetrack更改为track。
4.后续训练按照dancetrack进行
5.测试,按照说明运行
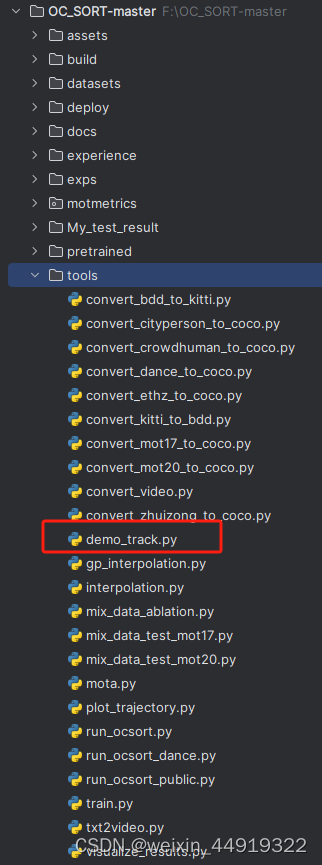
更改运行demo时的参数,
import argparse
def make_parser():
parser = argparse.ArgumentParser("OC-SORT parameters")
parser.add_argument("--expn", type=str, default=r'F:\OC_SORT-master\My_test_result')
parser.add_argument("-n", "--name", type=str, default=None, help="model name")
# distributed
parser.add_argument("--dist-backend", default="nccl", type=str, help="distributed backend")
parser.add_argument("--output_dir", type=str, default=None)
parser.add_argument("--dist-url", default=None, type=str, help="url used to set up distributed training")
parser.add_argument("-b", "--batch-size", type=int, default=1, help="batch size")
parser.add_argument("-d", "--devices", default=None, type=int, help="device for training")
parser.add_argument("--local_rank", default=0, type=int, help="local rank for dist training")
parser.add_argument("--num_machines", default=1, type=int, help="num of node for training")
parser.add_argument("--machine_rank", default=0, type=int, help="node rank for multi-node training")
parser.add_argument("-f", "--exp_file", default=r'F:\OC_SORT-master\exps\example\mot\yolox_track.py',
type=str,
help="pls input your expriment description file",
)
parser.add_argument(
"--fp16", dest="fp16",
default=True,
action="store_true",
help="Adopting mix precision evaluating.",
)
parser.add_argument("--fuse", dest="fuse", default=True, action="store_true",
help="Fuse conv and bn for testing.", )
parser.add_argument("--trt", dest="trt", default=False, action="store_true",
help="Using TensorRT model for testing.", )
parser.add_argument("--test", dest="test", default=False, action="store_true", help="Evaluating on test-dev set.", )
parser.add_argument("--speed", dest="speed", default=False, action="store_true", help="speed test only.", )
parser.add_argument("opts", help="Modify config options using the command-line", default=None,
nargs=argparse.REMAINDER, )
# det args
parser.add_argument("-c", "--ckpt", default=r'F:\OC_SORT-master\experience\best_ckpt.pth.tar', type=str, help="ckpt for eval")
parser.add_argument("--conf", default=0.1, type=float, help="test conf")
parser.add_argument("--nms", default=0.7, type=float, help="test nms threshold")
parser.add_argument("--tsize", default=None, type=int, help="test img size")
parser.add_argument("--seed", default=None, type=int, help="eval seed")
# tracking args
parser.add_argument("--track_thresh", type=float, default=0.6, help="detection confidence threshold")
parser.add_argument("--iou_thresh", type=float, default=0.3, help="the iou threshold in Sort for matching")
parser.add_argument("--min_hits", type=int, default=3, help="min hits to create track in SORT")
parser.add_argument("--inertia", type=float, default=0.2, help="the weight of VDC term in cost matrix")
parser.add_argument("--deltat", type=int, default=3, help="time step difference to estimate direction")
parser.add_argument("--track_buffer", type=int, default=30, help="the frames for keep lost tracks")
parser.add_argument("--match_thresh", type=float, default=0.9, help="matching threshold for tracking")
parser.add_argument('--min-box-area', type=float, default=100, help='filter out tiny boxes')
parser.add_argument("--gt-type", type=str, default="_val_half", help="suffix to find the gt annotation")
parser.add_argument("--mot20", dest="mot20", default=False, action="store_true", help="test mot20.")
parser.add_argument("--public", action="store_true", help="use public detection")
parser.add_argument('--asso', default="iou", help="similarity function: iou/giou/diou/ciou/ctdis")
parser.add_argument("--use_byte", dest="use_byte", default=False, action="store_true", help="use byte in tracking.")
# for kitti/bdd100k inference with public detections
parser.add_argument('--raw_results_path', type=str, default="exps/permatrack_kitti_test/",
help="path to the raw tracking results from other tracks")
parser.add_argument('--out_path', type=str, default=r'F:\OC_SORT-master/output_test.mp4', help="path to save output results")
parser.add_argument("--dataset", type=str, default="mot", help="kitti or bdd")
parser.add_argument("--hp", action="store_true", help="use head padding to add the missing objects during \
initializing the tracks (offline).")
# for demo video
parser.add_argument("--demo_type", default="image", help="demo type, eg. image, video and webcam")
parser.add_argument("--path", default=r"F:\OC_SORT-master\datasets\track\test\27\images", help="path to images or video")
parser.add_argument("--camid", type=int, default=0, help="webcam demo camera id")
parser.add_argument(
"--save_result",
action="store_true",
default=True,
help="whether to save the inference result of image/video",
)
parser.add_argument(
"--aspect_ratio_thresh", type=float, default=1.6,
help="threshold for filtering out boxes of which aspect ratio are above the given value."
)
parser.add_argument('--min_box_area', type=float, default=10, help='filter out tiny boxes')
parser.add_argument(
"--device",
default="gpu",
type=str,
help="device to run our model, can either be cpu or gpu",
)
return parser
右击demo_track.py进行可得测试集结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









