







前言
遇到这种问题,总会让人感慨,中文互联网社区,真**坑
下载量化模型
hf-mirror上很多,随便搜个,比如:
https://hf-mirror.com/bartowski/DeepSeek-R1-Distill-Llama-8B-GGUF
克隆仓库
GIT_LFS_SKIP_SMUDGE=1 git clone https://hf-mirror.com/bartowski/DeepSeek-R1-Distill-Llama-8B-GGUF
下载其中Q4_K_M这个量化成4bit的模型
git lfs track DeepSeek-R1-Distill-Llama-8B-Q4_K_M.gguf
git lfs pull origin master --include="DeepSeek-R1-Distill-Llama-8B-Q4_K_M.gguf"
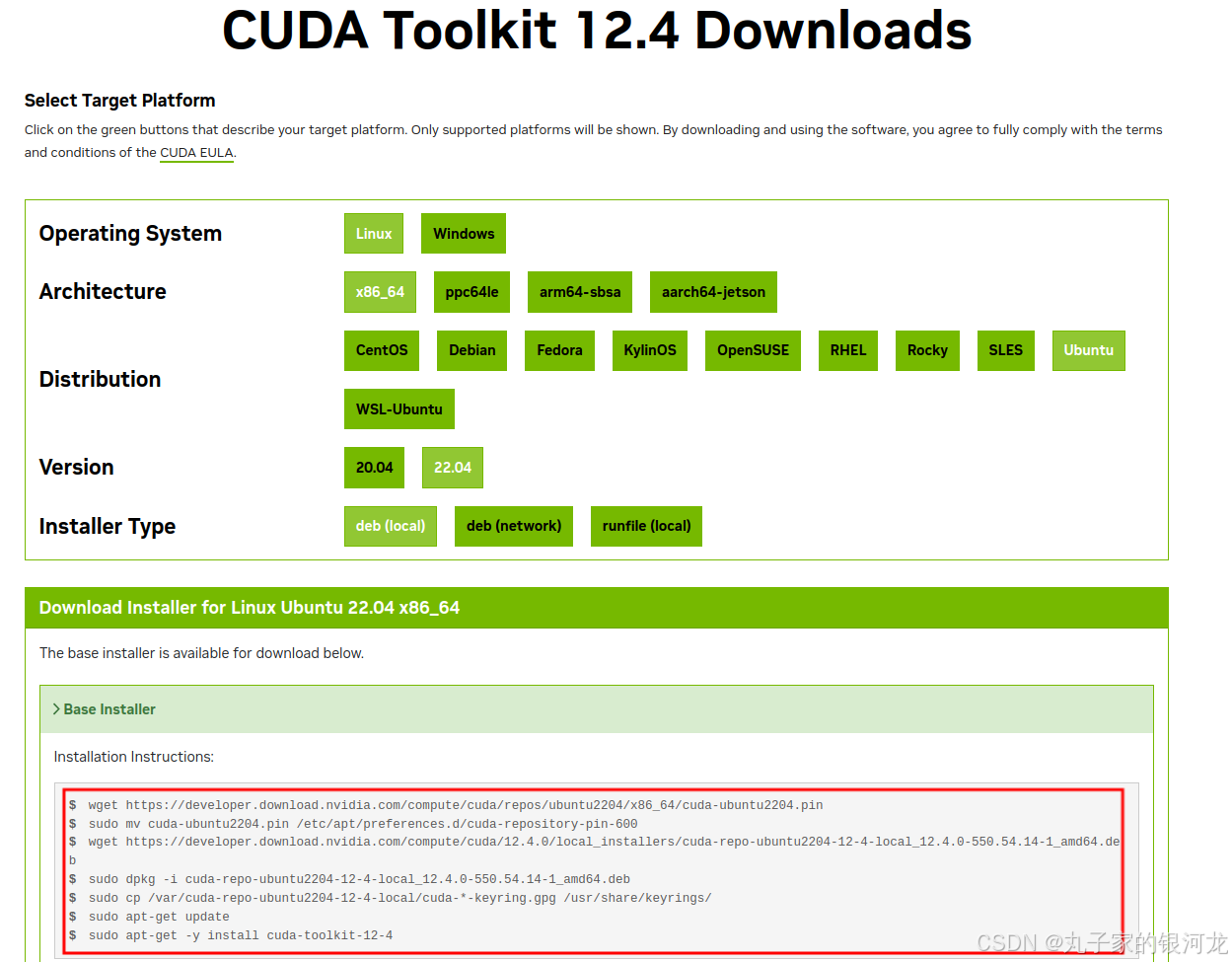
安装CUDA Toolkit
https://developer.nvidia.com/cuda-toolkit-archive
NVIDIA官网上,找到和自己torch匹配的版本
#查看torch版本
torch.version.cuda
我的是12.4,我就找到12.4安装
编译安装llama-cpp-python
普通安装
一般来说这么装就行了
export PATH=$PATH:/usr/local/cuda-12.4/bin/ # 换成你安装nvidia-cuda-toolkit的路径
CMAKE_ARGS="-DGGML_CUDA=on" pip install llama-cpp-python --extra-index-url https://abetlen.github.io/llama-cpp-python/whl/cu124 --force-reinstall --no-cache-dir
有几个坑:
1、LLAMA_CUBLAS这个选项已经被废弃了,编译不了
2、要装对版本的cuda-toolkit,不然也编译不了
编译完就可以使用了
安装最新版
但如果是最新发布的模型,可能llama_cpp里还没有合入对应的架构信息,就需要下载代码编译安装
# github地址,下载source code
https://github.com/ggml-org/llama.cpp/releases
# 解压,cmake
mkdir build;cd build
export PATH=$PATH:/usr/local/cuda-12.4/bin/ # 换成你安装nvidia-cuda-toolkit的路径
cmake -DGGML_CUDA=on ..
# 中间报了个错: Could NOT find CURL (missing: CURL_LIBRARY CURL_INCLUDE_DIR)
# 需要安装libcurl4-openssl-dev
apt install libcurl4-openssl-dev
# 编译
....
# 未完待续
示例代码
from llama_cpp import Llama
import time
import json
## global variable
llm = None
default_sys_prompt = "你是一位AI助手"
system_prompt = {
"role": "system",
"content":{default_sys_prompt}
}
user_role = "user"
AI_role = "assistant"
## global settings
model_path = "/data/deepseek/DeepSeek-R1-Distill-Llama-70B-GGUF/DeepSeek-R1-Distill-Llama-70B-Q6_K/DeepSeek-R1-Distill-Llama-70B-Q6_K-00001-of-00002.gguf"
# model_path = "/data/deepseek/DeepSeek-R1-Distill-Llama-70B-GGUF/DeepSeek-R1-Distill-Llama-70B-Q4_K_M.gguf"
# model_path = "/data/deepseek/DeepSeek-R1-Distill-Llama-70B-GGUF/DeepSeek-R1-Distill-Llama-70B-IQ4_XS.gguf"
# model_path = "/data/deepseek/DeepSeek-R1-Distill-Qwen-32B-GGUF/DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf"
# model_path = "/data/deepseek/DeepSeek-R1-Distill-Qwen-14B-GGUF/DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf"
# model_path = "/data/deepseek/DeepSeek-R1-Distill-Llama-8B-GGUF/DeepSeek-R1-Distill-Llama-8B-Q4_K_M.gguf"
context_length = 5120 # 最大上下文长度
max_tokens = 512 # AI一次最多生成的tokens
gpu_layers = 28 # 没GPU就填0
threads = 8 # 贴近逻辑核数
## functions
def help_prompt():
print("系统提示词,提示AI的身份,例如:你是一位诗人")
print(f"默认提示词:{default_sys_prompt}")
def load_model():
global llm
# 开始计时
start_time = time.time()
llm = Llama(model_path=model_path,
n_ctx=context_length, # 上下文长度
n_threads=threads, # 使用的线程数,根据你的 CPU 核心数进行调整
n_gpu_layers=gpu_layers) # 如果你的 GPU 支持,可以设置大于 0 的值来使用 GPU 加速
# 结束计时
end_time = time.time()
# 计算耗时
elapsed_time = end_time - start_time
# 打印耗时
print(f"加载模型耗时耗时: {elapsed_time:.2f} 秒")
def set_system_prompt():
print("需要设置系统提示词吗 (y/n/help) ", end="")
str = input()
if str == 'y':
system_prompt["content"] = input("请输入提示词: ")
elif str == "help":
help_prompt()
set_system_prompt()
def deal_response(context, full_response):
global llm
# 开始计时
start_time = time.time()
# 生成模型的回复,使用流式生成
print("AI:", end="")
response_parts = []
for output in llm(context, max_tokens=max_tokens, temperature=0.6, top_p=0.95, stream=True):
token_text = output['choices'][0]['text']
response_parts.append(token_text)
if not full_response:
print(token_text, end='', flush=True)
# 结束计时
end_time = time.time()
# 计算耗时
elapsed_time = end_time - start_time
# 解码模型的回复
response = ''.join(response_parts)
think_end = response.find("</think>")
expect_response = response[think_end + 9:] #<think>的部分显示但不加入对话记录
print(f"expect_resp:{expect_response}")
# 打印耗时
print(f"本轮对话耗时: {elapsed_time:.2f} 秒")
return expect_response
def chat():
# local settings
history = []
full_response = False
extra_prompt = "<think>\n"
while True:
user_input = input("user:")
if user_input.lower() == "exit":
print("对话结束")
break
# 构建用户输入的 JSON 对象字符串并添加到历史记录
user_msg = {
"role": "f{user_role}",
"content": user_input
}
user_msg_str = json.dumps(user_msg, ensure_ascii=False)
history.append(user_msg_str)
# 构建 messages 列表
messages = [system_prompt]
for item in history:
msg = json.loads(item)
messages.append(msg)
# 手动构建上下文(增加<think>触发强制思考
context = "\n".join([f"{msg['role']}:{msg['content']}\n" for msg in messages]) + f"{AI_role}:<think>\n"
# 调用处理回复的函数
expect_response = deal_response(context, full_response)
# 构建 AI 回复的 JSON 对象字符串并添加到历史记录
ai_msg = {
"role": f"{AI_role}",
"content": expect_response
}
ai_msg_str = json.dumps(ai_msg, ensure_ascii=False)
history.append(ai_msg_str)
# 控制对话历史长度,避免过长
# 通过history + token < content_length判断,暂未实现
if __name__ == "__main__":
# 加载模型
load_model()
# 设置系统提示词
set_system_prompt()
# 开始会话
chat()

















 3183
3183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









