







1、环境配置
参考:https://blog.csdn.net/liuxianfei0810/article/details/108863896
2、材料
1)模板
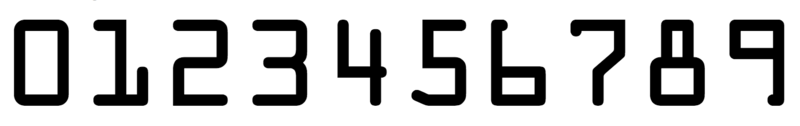
2)被检测图片

3、思路
1)模板
(1)目的:得到该数字在模板上对应的模板
(2)模板本身是BGR图像,画出轮廓需要二值图,先用BGR转化为二值图,使用threshold(阈值)来来转换成二值图像
(3)用findContours找轮廓,findContours方法的参数的格式必须是:二值图像深度复制的副本、mode轮廓检测模式一般选择RETR_EXTERNAL,而method表示轮廓逼近方法:一般选择CHAIN_APPROX_SIMPLE(只保留各个轮廓的部分顶点或者转折点,足够用来描绘出轮廓!)
(4)使用drawContours画出轮廓排序的思想是:通过boundingRect方法获取到包含了每个轮廓的矩形的左上坐标,因为模板图像本身是按照从小到大的顺序排列,因此,通过比较个轮廓矩形的左上坐标的横坐标即可得到个轮廓的排序的列表refCnts。
(5)通过定义一个digits字典来通过对refCnts列表的for循环来将数字0123456789与refCnts中的边框在ref图像中的像素点区域
2)被识别图像处理
(1)转化为灰度图
(2)初始化卷积核
(9, 3)是指的矩阵的宽w和高h, 9是因为想让横向的信息多保留
KectKernel为:
[[1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1]]
形状(3, 9)
(3)礼帽,突出更明亮的区域(以突出细节区域),得到的是噪音图像
(4)目的是四个数字构成的一个个块提取出来
先闭操作,阈值, 再次闭操作为了使得分组的图像中的空洞位置同样被白色填充,这样做的好处提升外轮廓定位的准确率
(5)按照常规步骤画图轮廓,遍历根据轮廓的宽高比以及宽高来选出数字块的图,根据X坐标的大小排序。
对每个数字块进行预处理,找出每个数字块里的数字的轮廓,排序,改变图片数字的大小跟模板数字的大小一样大,进行模板匹配,得分。在图片上画出识别的数字以及框框。
4、函数解释
3.1 argparse与vars
使用argparse模块创建一个ArgumentParser解析对象,可以理解成一个容器,将包含将命令行解析为Python数据类型所需的所有信息。
parse_args()是将之前add_argument()定义的参数进行赋值,并返回相关的namespace。
实例化 : aparse=argparse.ArgumentParser()
添加参数 :aparse.add_argument(‘a’,help=‘test’)
解析参数:a=aparse.parse_args()
参考:https://blog.csdn.net/chengmo123/article/details/103609449
parser = argparse.ArgumentParser()
# # 括号少了会报错AttributeError: 'str' object has no attribute 'prefix_chars'
parser.add_argument("-i", "--image", required=True, help="path to input image")
# -i可以理解为标签,--image既可以是标签又是属性
parser.add_argument("-t", "--template", required=True, help="path to template OCR-A image")
args = vars(parser.parse_args()) # print(args["image"])
# args为字典{'image': 'images/credit_card_01.png', 'template': 'images/ocr_a_reference.png'}
args = parser.parse_args() # print(args.image)
# Namespace(image='images/credit_card_01.png', template='images/ocr_a_reference.png')
# -t 和 --train两种情况,在bat文件和pycharm配置种注意区分前面的两个--还是一个-
pycharm下可以通过argparse模块完成参数设置,即生成全局变量
3.2 zip与zip*
zip() 函数用于将可迭代的对象(直观理解就是能用for循环进行迭代的对象就是可迭代对象。比如:字符串,列表,元祖,字典,集合等等,都是可迭代对象。)作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。(个人理解,将两组元素,分别各成元元组组合成一个列表)
zip 方法在 Python 2 和 Python 3 中的不同:在 Python 3.x 中为了减少内存,zip()
返回的是一个对象。如需展示列表,需手动 list() 转换。
a = [(1, 2), (2, 3), (3, 4)]
# 类似这些都是可以迭代的元祖,字符串等等。a = ((1, 2), (2, 3), (3, 4)), a="abc"
b = [(5, 6), (7, 8), (9, 9)]
print(zip(a, b)) # <zip object at 0x000001B5EB0CA0C8>
ret = list(zip(a, b))
# 输出 :[((1, 2), (5, 6)), ((2, 3), (7, 8)), ((3, 4), (9, 9))]
ret1 = list(zip(*ret))
# 或者写成这样:ret1 = list(zip(*(zip(z,b)))
# 输出: [((1, 2), (2, 3), (3, 4)), ((5, 6), (7, 8), (9, 9))]
3.3 sorted
#基础用法
#传进去一个可迭代的数据,返回一个新的列表,按照从小到大排序,注意,是新的列表!
a = [1, 4, 6, 8, 9, 3, 5]
b = "aghdb"
sorted(a) # print(a)不变,返回sorted(g)变; [1, 3, 4, 5, 6, 8, 9]
sorted(b) # 返回['a', 'b', 'd', 'g', 'h']
sorted(a, reverse=True) # 逆序排序; [9, 8, 6, 5, 4, 3, 1]
高级用法
列表里面的每一个元素都为二维元组,key参数传入了一个lambda函数表达式,其x就代表列表里的每一个元素,然后分别利用索引返回元素内的第一个和第二个元素,这就代表了sorted()函数根据哪一个元素进行排列。reverse参数起逆排的作用,默认为False,从小到大顺序。
c = [("a", 1), ("e", 2), ("c", 4)]
print(sorted(c, key=lambda x: x[0]))
print(sorted(c, key=lambda x: x[1]))
print(sorted(c, key=lam 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2778
2778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









