







前言
线性模型也是机器学习中最为基础的模型,很多复杂模型均可认为由线性模型衍生而得。
一、线性模型
1.1 基本形式
给定由 d个属性描述的示例 x = (X1;X2;…;Xd), 其中Xi是X在第i个属性上的取值,线性模型 (linear model)试图学得一个通过属性的线性组合来进行 预测的函数,即
f(x) = ω1X1 + ω2X2 十 …+ωdXd + b
一般用向量形式写成
f(x) = ωTx+b
举一个西瓜书的例子
若在想买一个好瓜,他的判定标准用线性模型表示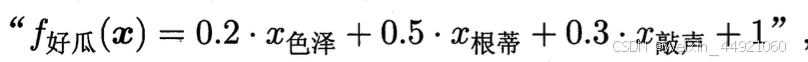 则意味着可 通过综合考虑色泽、根蒂和敲声来判断瓜好不好,其中根蒂最要紧,而敲声比 色泽更重要.
则意味着可 通过综合考虑色泽、根蒂和敲声来判断瓜好不好,其中根蒂最要紧,而敲声比 色泽更重要.
二、单变量线性回归(Linear Regression with One Variable)
在学之前我们先学一个定义-什么是回归?
以下解答来自百度百科
回归分析是研究某一变量(因变量)与另一个或多个变量(解释变量、自变量)之间的依存关系,用解释变量的已知值或固定值来估计或预测因变量的总体平均值
1.1 定义
单变量线性回归又称为一元线性回归,是分析只有一个自变量(自变量x和因变量y)线性相关关系的方法。
以下图房产价格举例子
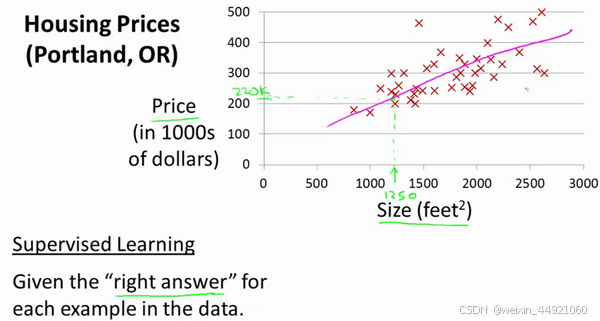
我们要使用一个数据集,数据集包含俄勒冈州波特兰市的住房价格。在这里,我要根据不同房屋尺寸所售出的价格,画出我的数据集。比方说,如果你朋友的房子是1250平方尺大小,你要告诉他们这房子能卖多少钱。那么,你可以做的一件事就是构建一个模型,也许是条直线,可以用** y = ax + b** 来表示,从这个数据模型上来看,也许你可以告诉你的朋友,他能以大约220000(美元)左右的价格卖掉这个房子。
三、损失函数
3.1 定义
在上面预测房价的例子中,我们定义了一个线性函数,我们需要选择合适的参数a和b用来减少模型预测值和实际值之间的差距,在房价问题这个例子中便是直线的斜率和在y轴上的截距。
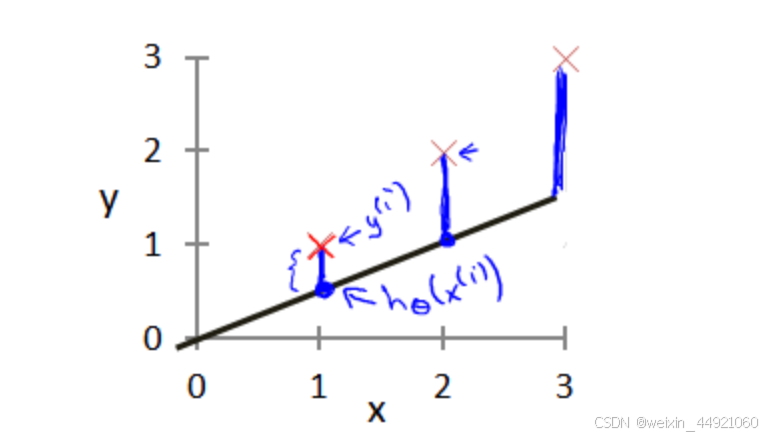
模型所预测的值与训练集中实际值之间的差距(图中蓝线表示)就是建模误差(modeling error)。为了让建模误差最小,我们需要引入一个新的名词–代价函数
代价函数是用于衡量模型预测值与实际值之间的差异,从而评估模型的性能。通过最小化代价函数,我们可以找到最优的模型参数,使模型在训练数据上的表现尽可能好。
3.2 常见的代价函数
以下是一些常见的代价函数以及它所适用的场景






3.3 均方误差

解释一下上图,我们有一个一元线性函数,他的参数是θ0和θ1,他的代价函数是J(θ0,θ1),我们的目标就是获取最小化的均方误差
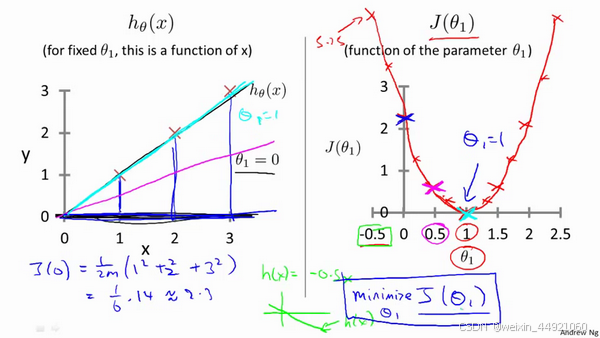
其中θ0是一个常数,θ1是一个变量,求取最佳的θ0,使θ0=0,此时函数f只跟θ1相关即f(x)=θ1x,J函数会简化为J(θ1),也只跟θ1相关。
在左图中,当θ1=1的时候,如浅蓝线所画,此时J(θ1) = (0² + 0² + 0²)/ 2M = 0。
在右图,列出了当横轴θ1取不同的数值时,纵轴J(θ1)对应的值,由此可见当θ1=0的时候,J(θ1)最小为0.
在这里我们获得了,当θ0=0,θ1=1的时候,能获取最小均方误差


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









