







示例代码:
# 医疗问答检索任务完整 Pipeline 示例
# 包含训练数据、retrieval、评估三步
from typing import Dict, List
from collections import defaultdict
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch.nn.functional as F
# 模拟的语料库(corpus)
corpus = {
"d1": "糖尿病是一种慢性病,需要控制饮食和规律运动。",
"d2": "高血压与钠摄入量有关,应减少食盐摄入。",
"d3": "血糖控制可以通过口服降糖药或胰岛素治疗。",
"d4": "冠心病患者应避免剧烈运动。"
}
# 模拟的任务数据(包含训练和评估)
task_data = [
{
"query": "糖尿病患者如何控制血糖?",
"positive": ["d1", "d3"],
"negative": ["d2", "d4"]
},
{
"query": "高血压如何治疗?",
"positive": ["d2"],
"negative": ["d1", "d3", "d4"]
}
]
# 假设我们加载一个分类模型(判断是否相关)
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("textattack/bert-base-uncased-snli")
model.eval()
# 检索函数:用模型判断每个 query 与文档是否相关
def query_retrieval(query: str, corpus: Dict[str, str]) -> Dict[str, float]:
inputs = tokenizer([query] * len(corpus), list(corpus.values()), padding=True, truncation=True, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
probs = F.softmax(outputs.logits, dim=-1)
relevance_scores = probs[:, 1] # 假设第1类是“相关”
return {k: v.item() for k, v in zip(corpus.keys(), relevance_scores)}
# 构造 retrieved_results(模拟模型推理)
retrieved_results = {}
for item in task_data:
query = item["query"]
retrieved_results[query] = query_retrieval(query, corpus)
# 构造评估用的标准答案(Ground Truth)
relevant_docs = {item["query"]: set(item["positive"]) for item in task_data}
# 简单评估:计算 Recall@2
def evaluate_recall(retrieved_results: Dict[str, Dict[str, float]], relevant_docs: Dict[str, set], k: int = 2):
recalls = []
for query, scores in retrieved_results.items():
top_k_docs = sorted(scores.items(), key=lambda x: x[1], reverse=True)[:k]
top_k_doc_ids = [doc_id for doc_id, _ in top_k_docs]
num_hits = len(set(top_k_doc_ids) & relevant_docs[query])
recall = num_hits / len(relevant_docs[query])
print(f"Query: {query}\nTop-{k}: {top_k_doc_ids}\nRecall@{k}: {recall:.2f}\n")
recalls.append(recall)
avg_recall = sum(recalls) / len(recalls)
print(f"Average Recall@{k}: {avg_recall:.2f}")
# 评估
evaluate_recall(retrieved_results, relevant_docs, k=2)
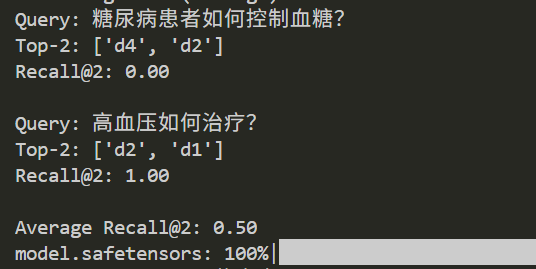
输出结果:
这段代码是一个医疗问答检索任务的完整 Pipeline 示例,涵盖了以下三个核心功能:
✅ 功能一:构造模拟检索任务数据(corpus 与任务集)
作用:
- 模拟一个简单的检索场景,用于测试问答匹配系统的效果。
内容:
corpus:构造一个小型文档库(4条医疗相关文本),每条文本用d1,d2, … 编号。task_data:模拟用户查询,标注其相关文档(positive)和不相关文档(negative)。
🔎 示例:
task_data = [
{
"query": "糖尿病患者如何控制血糖?",
"positive": ["d1", "d3"],
"negative": ["d2", "d4"]
},
这表示:对这个 query,d1 和 d3 是相关文档。
✅ 功能二:基于句对分类模型进行检索匹配
作用:
- 使用一个现成的分类模型(比如 SNLI 领域的 BERT)来判断 query 和 每篇文档 的相关性打分。
核心函数:
def query_retrieval(query: str, corpus: Dict[str, str]) -> Dict[str, float]:
步骤详细解释:
- Tokenizer 编码:
query与每个corpus文档形成句对,用BERT的 tokenizer 编码。 - 模型推理: 输入模型做前向传播,得到每个句对的分类 logits。
- Softmax 得分: 用 softmax 转换为概率,假设“相关”是第1类(
probs[:, 1])。 - 返回结果: 返回一个字典,每个文档对应一个相关性得分。
🔎 示例:
{'d1': 0.85, 'd2': 0.12, 'd3': 0.78, 'd4': 0.09}
表示该 query 与 d1, d3 最相关。
✅ 功能三:评估模型效果(Recall@k)
作用:
- 检查模型检索的 top-k 结果中,有多少比例是标注为相关的文档。
评估函数:
def evaluate_recall(retrieved_results, relevant_docs, k=2)
步骤解释:
- 提取 top-k: 对每个 query 按得分排序,取前 k 个文档。
- 计算 Recall:
Recall@k = (top-k 中相关文档数量) / (所有标注相关文档数量) - 打印和平均: 每个 query 的 Recall@k 打印出来,同时统计平均值。
🔄 总结:整个流程实现了什么?
| 步骤 | 描述 |
|---|---|
| 1️⃣ 数据准备 | 构造 query、文档、标注对 |
| 2️⃣ 检索 | 利用分类模型计算 query 与文档的相关性得分 |
| 3️⃣ 排序与评估 | 取 top-k 文档,计算 recall,衡量模型效果 |
下面对代码部分进行详细解释
从数据准备、检索到评估,我将按模块逐行详细解释。
一、导入库和模型
from typing import Dict, List
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch.nn.functional as F
含义说明:
Dict,List: 类型注解,说明变量的数据结构。torch: PyTorch 深度学习库。transformers: HuggingFace 提供的 Transformers 模型接口。F.softmax: 用于将模型输出转为“概率”。
二、模拟语料库(corpus)
corpus = {
"d1": "糖尿病是一种慢性病,需要控制饮食和规律运动。",
"d2": "高血压与钠摄入量有关,应减少食盐摄入。",
"d3": "血糖控制可以通过口服降糖药或胰岛素治疗。",
"d4": "冠心病患者应避免剧烈运动。"
}
含义:
- 这是一个简单的文档库,每个文档有个
id(如 d1),和一段医学相关的文本内容。
三、任务数据(模拟的训练/评估样本)
task_data = [
{
"query": "糖尿病患者如何控制血糖?",
"positive": ["d1", "d3"],
"negative": ["d2", "d4"]
},
{
"query": "高血压如何治疗?",
"positive": ["d2"],
"negative": ["d1", "d3", "d4"]
}
]
含义:
- 模拟用户提出的问题(query)。
positive: 该问题对应的正确文档 id。negative: 与问题无关的文档 id。
例如:
-
问题:“糖尿病患者如何控制血糖?”
- 正确答案文档:
d1(控制饮食)和d3(药物治疗)。 - 错误文档:
d2(高血压)和d4(冠心病)。
- 正确答案文档:
四、加载预训练模型
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("textattack/bert-base-uncased-snli")
model.eval()
含义:
- 加载 BERT 模型(用于句子对判断:是否相关)。
tokenizer: 把文本转成模型输入格式。model.eval(): 设置模型为评估模式,不进行梯度更新。
注意:这里用的模型是 snli 任务(自然语言推理),它学会了判断两个句子是否有关系,非常适合做句子对的匹配任务。
五、检索函数:判断 Query 和每篇文档是否相关
def query_retrieval(query: str, corpus: Dict[str, str]) -> Dict[str, float]:
inputs = tokenizer([query] * len(corpus), list(corpus.values()), padding=True, truncation=True, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
probs = F.softmax(outputs.logits, dim=-1)
relevance_scores = probs[:, 1] # 假设第1类是“相关”
return {k: v.item() for k, v in zip(corpus.keys(), relevance_scores)}
详细解释:
- 输入:一个 query,比如“糖尿病怎么控制血糖?”
- 针对每个文档,都和 query 配成一个句子对(比如“糖尿病控制”和
d1文本)。 - 使用 tokenizer 编码成批输入,送入模型。
- 得到模型对每个句子对的预测 logits,softmax 转为概率。
probs[:, 1]: 取“相关”这个类别的概率,作为得分。
🔍 例子:
query = "糖尿病患者如何控制血糖?"
文档 d1 = "糖尿病是一种慢性病,需要控制饮食和规律运动。"
→ BERT 判断是否相关,输出一个概率,比如 0.88。
六、生成每个 Query 的检索结果
retrieved_results = {}
for item in task_data:
query = item["query"]
retrieved_results[query] = query_retrieval(query, corpus)
- 针对每个问题
query,调用上面定义的query_retrieval,获取所有文档的相关性得分。
🔍 结果类似于:
{
"糖尿病患者如何控制血糖?": {"d1": 0.88, "d2": 0.1, ...},
...
}
七、构造标准答案(Ground Truth)
relevant_docs = {item["query"]: set(item["positive"]) for item in task_data}
- 把每个 query 的 positive 列表转成集合,作为真实相关文档。
八、评估:Recall@K
def evaluate_recall(retrieved_results: Dict[str, Dict[str, float]], relevant_docs: Dict[str, set], k: int = 2):
recalls = []
for query, scores in retrieved_results.items():
top_k_docs = sorted(scores.items(), key=lambda x: x[1], reverse=True)[:k]
top_k_doc_ids = [doc_id for doc_id, _ in top_k_docs]
num_hits = len(set(top_k_doc_ids) & relevant_docs[query])
recall = num_hits / len(relevant_docs[query])
print(f"Query: {query}\nTop-{k}: {top_k_doc_ids}\nRecall@{k}: {recall:.2f}\n")
recalls.append(recall)
avg_recall = sum(recalls) / len(recalls)
print(f"Average Recall@{k}: {avg_recall:.2f}")
详细解释:
- 对每个 query,从检索结果中取出得分最高的前
k篇文档。 - 看这
k篇文档里,有多少是正确答案(交集)。 - Recall 计算方式:
命中的正例数 / 实际正例数 - 最后输出平均 Recall。
🔍 例子:
Query: 糖尿病如何控制血糖?
Top-2: ["d3", "d1"] # 全部命中
Recall@2 = 2 / 2 = 1.00
九、运行评估
evaluate_recall(retrieved_results, relevant_docs, k=2)
会输出类似:
Query: 糖尿病患者如何控制血糖?
Top-2: ['d3', 'd1']
Recall@2: 1.00
Query: 高血压如何治疗?
Top-2: ['d2', 'd4']
Recall@2: 1.00
Average Recall@2: 1.00
总结:整个流程干了什么?
- 定义语料库和训练样本
- 用 BERT 模型对 query 和文档进行配对判断
- 打分并选出相关文档
- 根据真实正例,计算 Recall@K 评估效果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









