






《Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering》论文笔记
GitHub链接: https://github.com//peteanderson80/bottom-up-attention
本文提出一种自上而下与自下而上相结合的注意力模型方法,应用于视觉场景理解和视觉问答系统的相关问题。其中基于自下而上的关注模型(使用Faster R-CNN)用于提取图像中的兴趣区域,获取对象特征;而基于自上而下的注意力模型用于学习特征所对应的权重(使用LSTM),以此实现对视觉图像的深入理解。
自下而上的注意力模块
使用Faster R-CNN和ResNet-101-CNN结合,生成一组图像特征V用于ImageCaption或VQA.
取模型的最终输出,并使用IOU阈值对每个对象类执行非最大抑制。然后,选择类检测概率超过置信阈值的所有区域,并提取出区域的平均池化特征。
文中提及使用Faster R-CNN实现自下向上的关注模型,从图中可以看出相比之前不同之处在于,通过设定的阈值允许兴趣框的重叠,这样可以更有效的理解图像内容。文中对每一个感兴趣区域不仅使用对象检测器还使用属性分类器,这样可以获得对对象的(属性,对象)的二元描述。这样的描述更加贴合实际应用。

文本描述模型
Top-Down Attention LSTM:

上标1表示top-down attention LSTM,上标2表示language LSTM
Top-Down Attention LSTM
使用LSTM来确定image feature 的权重, 是soft attention机制。
top-down attention LSTM的输入分别由:
1、前一时刻language model的隐藏状态;
2、k个图像特征的平均池化特征 ;
3、之前生成的词的encoding:为t时刻输入单词的one-hot encoding,为embedding矩阵
三者concatenate得到
对于k个image feature 的注意力权重,是由top-down attention LSTM在每一个时刻利用自身隐藏层产生的:
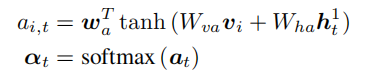
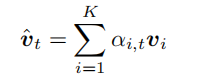
记忆了之前输入的单词、单词的平均池化特征、language LSTM的隐藏状态,Wva ∈ RH×V , Wha ∈ RH×M , wa ∈ RH都是要学习的参数
Language LSTM
Language LSTM的输入:包括:
1、注意力特征加权和;
2、当前时刻attention LSTM的隐藏状态concatenate而成
训练目标:
使用最小化交叉熵损失来进行训练:
其中是文本表述的真实标签。
在t时刻输出的任一单词的概率分布,其中为单词序列,整个句子的概率分布,为每个单词概率的连乘。
还用到了SCST(S. J. Rennie, E. Marcheret, Y. Mroueh, J. Ross, and V. Goel. Self-critical sequence training for image captioning. In CVPR, 2017. 1, 2, 3, 4, 6, 7)中的强化学习来对CIDEr分数进行优化:
梯度近似为:
其中是强化学习中sample得到的caption,是baseline.即如果这个sample的句子比baseline好,该梯度会提高它出现的概率,如果不好就抑制。
实验:
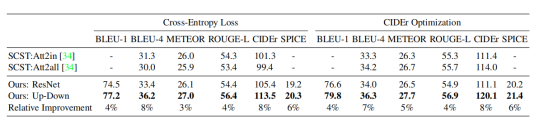
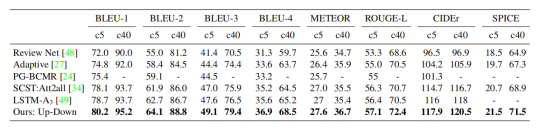
本文整理了https















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









