






本文将用Tensorflow框架训练Mnist数据集,搭建卷积神经网络CNN,损失将以动态折线图方式展示。
卷积如何工作?
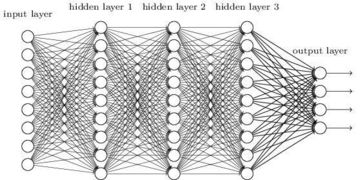
首先大家看一下下面的全连接神经网络,从这张图我们知道,全连接神经网络中,每一层的每个神经元输出的特征都被下一层每一个神经元接收,公式表达为 f(wx+b),f为激活函数,w是权重,截取自标准正态分布,b为偏置,上一层的输出作为下一层的输入,即便某一个神经元的输出并没有特征,或者是干扰信息,也会被下一层所接受,那么这就产生了两个问题,第一:计算量太大;第二:获取特征不准确,精度低,对于多特征的提取效果差。
分析了全连接的工作原理,我们知道全连接特征提取效果不好,那么卷积是如何工作的呢?下图黄色部分可以看作是一个3×3的卷积核,在工作的时候,对应位置相乘,就把3×3的区域卷成了一个1×1的区域,称为特征图。卷积核里面的值为权重w,w初始是随机的,训练的过程中不断更新w的值,直到损失变得很小。

由此可见,卷积神经网络特征提取的准确度更高,效果更好,计算量也减小了,训练速度加快。
卷积神经网络中其他技术
池化
池化的作用就是把特征图减小,降低计算量,池化分为最大池化和平均池化,一般最大池化用的多。

Tensorflow框架搭建卷积神经网络CNN训练Mnist数据集
理论讲完了,下面来实现一个基于Tensorflow的CNN网络,用来识别手写数字mnist数据集。
1.首先导入tensorflow和tensorflow中的mnist数据集,设置为one-hot的形式:
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets(".\MNIST_data",one_hot=True)
2.然后导入PIL库用来画图,展示标签和识别结果,并对比:
import matplotlib.pyplot as plt
import PIL.Image as pimg
import PIL.ImageDraw as pdraw
import PIL.ImageFont as pfont
font_path="msyh.ttf"
3.self.x是神经网络的输入,self.y是神经网络的输出,(这里为什么写成这样参考我上一篇博客https://blog.csdn.net/weixin_44928646/article/details/104519603)
self.w1和self.b1是神经网络的第一层,shape=[N,H,W,C],3×3的卷积核。
self.x=tf.placeholder(shape=[None,784],dtype=tf.float32)
self.y=tf.placeholder(shape=[None,10],dtype=tf.float32)
self.w1=tf.Variable(tf.truncated_normal(shape=[3,3,1,16],stddev=tf.sqrt(1/16),dtype=tf.float32))
self.b1=tf.Variable(tf.zeros(shape=[16],dtype=tf.float32))
4.定义前向通道,首先进行形状变换,把[N,V]=[N,784]->[N,H,W,C]=[-1,28,28,1],因为卷积输入格式为***[N,H,W,C]***,下面就是计算卷积了,每一层卷积完加一层池化。
def forward(self):
x=tf.reshape(self.x,shape=[-1,28,28,1])
y1=tf.nn.relu(tf.layers.batch_normalization(tf.nn.conv2d(x,self.w1,strides=[1,1,1,1],padding="SAME")+self.b1))#28*28*16
dr_y1=tf.nn.dropout(y1,keep_prob=self.dropout)
pool_y1=tf.nn.max_pool(dr_y1,[1,2,2,1],[1,2,2,1],padding="SAME")#14*14*16
y2 = tf.nn.relu(tf.layers.batch_normalization(tf.nn.conv2d(pool_y1, self.w2,strides=[1,1,1,1],padding="SAME") + self.b2))#14*14*128
dr_y2 = tf.nn.dropout(y2, keep_prob=self.dropout)
pool_y2 = tf.nn.max_pool(dr_y2,[1,2,2,1],[1,2,2,1],padding="SAME")#7*7*128
5.卷积完之后,最后加一层全连接,注意[N,H,W,C]->[N,V],然后用softmax激活后输出
y2=tf.reshape(pool_y2,shape=[-1,7*7*128])
self.y3 =tf.layers.batch_normalization(tf.matmul(y2, self.w3) + self.b3)
self.output=tf.nn.softmax(self.y3)
6.用交叉熵作损失
def loss(self):
self.error=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=self.y,logits=self.y3))
+param*tf.reduce_sum(self.w1**2)+param*tf.reduce_sum(self.w2**2)+param*tf.reduce_sum(self.w3**2)
7.Adam优化器优化损失,学习率0.001
def backward(self):
# self.optimizer=tf.train.GradientDescentOptimizer(0.001).minimize(self.error)
self.optimizer=tf.train.AdamOptimizer(0.001).minimize(self.error)
8.下面的就是主函数,训练次数50000次,每次取100张图片训练,每训练100次验证一次。
完整程序:
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets(".\MNIST_data",one_hot=True)
import matplotlib.pyplot as plt
import PIL.Image as pimg
import PIL.ImageDraw as pdraw
import PIL.ImageFont as pfont
font_path="msyh.ttf"
param=0.01
class Net:
def __init__(self):
self.x=tf.placeholder(shape=[None,784],dtype=tf.float32)
self.y=tf.placeholder(shape=[None,10],dtype=tf.float32)
self.w1=tf.Variable(tf.truncated_normal(shape=[3,3,1,16],stddev=tf.sqrt(1/16),dtype=tf.float32))
self.b1=tf.Variable(tf.zeros(shape=[16],dtype=tf.float32))
self.w2=tf.Variable(tf.truncated_normal(shape=[3,3,16,128],stddev=tf.sqrt(1/128),dtype=tf.float32))
self.b2=tf.Variable(tf.zeros(shape=[128],dtype=tf.float32))
self.w3=tf.Variable(tf.truncated_normal(shape=[7*7*128,10],stddev=tf.sqrt(1/10),dtype=tf.float32))
self.b3=tf.Variable(tf.zeros(shape=[10],dtype=tf.float32))
self.dropout=tf.placeholder(dtype=tf.float32)
def forward(self):
x=tf.reshape(self.x,shape=[-1,28,28,1])
y1=tf.nn.relu(tf.layers.batch_normalization(tf.nn.conv2d(x,self.w1,strides=[1,1,1,1],padding="SAME")+self.b1))#28*28*16
dr_y1=tf.nn.dropout(y1,keep_prob=self.dropout)
pool_y1=tf.nn.max_pool(dr_y1,[1,2,2,1],[1,2,2,1],padding="SAME")#14*14*16
y2 = tf.nn.relu(tf.layers.batch_normalization(tf.nn.conv2d(pool_y1, self.w2,strides=[1,1,1,1],padding="SAME") + self.b2))#14*14*128
dr_y2 = tf.nn.dropout(y2, keep_prob=self.dropout)
pool_y2 = tf.nn.max_pool(dr_y2,[1,2,2,1],[1,2,2,1],padding="SAME")#7*7*128
y2=tf.reshape(pool_y2,shape=[-1,7*7*128])
self.y3 =tf.layers.batch_normalization(tf.matmul(y2, self.w3) + self.b3)
self.output=tf.nn.softmax(self.y3)
def loss(self):
self.error=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=self.y,logits=self.y3))
+param*tf.reduce_sum(self.w1**2)+param*tf.reduce_sum(self.w2**2)+param*tf.reduce_sum(self.w3**2)
def backward(self):
# self.optimizer=tf.train.GradientDescentOptimizer(0.001).minimize(self.error)
self.optimizer=tf.train.AdamOptimizer(0.001).minimize(self.error)
def accuracy(self):
y=tf.equal(tf.argmax(self.output),tf.argmax(self.y))
self.acc=tf.reduce_mean(tf.cast(y,dtype=tf.float32))
if __name__ == '__main__':
net=Net()
net.forward()
net.loss()
net.backward()
net.accuracy()
init=tf.global_variables_initializer()
plt.ion()
a=[]
b=[]
c=[]
with tf.Session() as sess:
sess.run(init)
for i in range(50000):
xs,ys=mnist.train.next_batch(100)
error,_=sess.run([net.error,net.optimizer],feed_dict={net.x:xs,net.y:ys,net.dropout:0.5})
if i%100==0:
xss,yss=mnist.validation.next_batch(100)
_error,_output,acc=sess.run([net.error,net.output,net.acc],feed_dict={net.x:xss,net.y:yss,net.dropout:1})
label=np.argmax(yss[0])
out=np.argmax(_output[0])
print("acc", acc)
print("label:",label,"output:",out,"error:",_error)
a.append(i)
b.append(error)
c.append(_error)
plt.clf()
plt.subplot(1,2,1)
train,=plt.plot(a,b,color="red")
validation,=plt.plot(a,c,color="blue")
plt.legend([train,validation],["train","validation"])
plt.subplot(1,2,2)
font = pfont.truetype(font=font_path, size=10)
arr = np.reshape(xss[0], [28, 28]) * 255
img = pimg.fromarray(arr)
imagedraw = pdraw.ImageDraw(img)
imagedraw.text(xy=(1, 1), text=str(out), fill=255, font=font)
plt.imshow(img)
plt.pause(0.01)
plt.ioff()
9.训练结果以动态方式展现,下面是两张截图,开始训练和训练结束


train:训练损失
validation:验证损失
大数字:标签label
坐上小数字:训练输出
10.结论:用卷积神经网络CNN识别手写数字,速度是很快的,只需训练不到100次,就可以得到接近0的损失,准确率很高,速度很快。
11.训练的动态视频可以点击这个链接看:https://www.bilibili.com/video/av91959887/
转载或引用请注明来源!















 208
208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









