






作为数据分析师,经常要在APP发版之后分析实验效果,为产品和运营团队提供数据支撑。为了尽量让新入行的数据分析师对AB实验有更深刻的了解,我先详述一个案例,再来写理论部分,让大家在看理论的时候能够带入例子,避免枯燥且更易懂。
一、举例
背景:产品同学想知道,在求职者刷求职软件时,职位列表如果增加一些店铺图片展示,是否能吸引求职者主动查看和主动聊天?
上线前:开发团队按产品团队设计的原型,在新版本上开发功能,使用新版的用户将会按照设定好的分组方式(按user_id尾号分,或者按哈希值随机分),抽样并分为A、B组。
上线后:上线3、4天左右,使用新版本的用户量达到了一定量级且基本稳定后,观察AB两组用户的核心行为指标,取一周或者两周的数据,观察均值,如果均值差异不明显,进行T检验,如果差异显著,认为实验有正向效果,建议推广至全量,如果无效果或者效果负向,建议实验下线。
二、定义
AB实验的基本思想是控制变量,尽量保证除了实验本身改进的功能点以外,其他变量保持一致。具体要看:
①人群是否同质。
②时间是否一致。
进一步衍生出,以下几种方法检验实验分流是否均匀:
①AA实验。
A/A:在AB实验上线前,先将实验组和对照组在没上实验策略的情况下空跑一段时间。
A/B/A:将对照组再拆分成两个组,从整体看,将产生2个对照组,1个实验组,比较两个对照组。
②与实验上线前对比。
如果实验是按尾号划分,可对比两组尾号在实验上线前是否在核心指标存在明显差异;也可以比较两组尾号在实验上线后、同为旧版本的用户是否在核心指标存在差异。
三、结果
在保证了其他变量同质的基础上,得到的实验结论需要进一步检验是否可靠,
①实验观测周期。
实验上线初期(3-4天内),使用新版本的用户逐渐增多,需要等数据差不多收敛后,再取1-2周的数据进行观察。
有一点需要注意:有时我们确实观测到了实验效果很好(有的指标会在一开始上线时有较好的反应),但是在一定长的时间后又会渐渐降低(新奇效应),甚至不如原始版本。
②实验最小样本量。
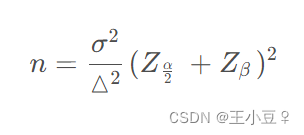
n是每组所需样本量,因为AB实验至少2组,所以实验所需样本量为2n;
α和β分别称为第一类错误概率和第二类错误概率,一般分别取0.05和0.2;
Z为正态分布的分位数函数;
Δ为两组数值的差异,如点击率1%到1.5%,那么Δ就是0.5%;
σ为标准差,是数值波动性的衡量,σ越大表示数值波动越厉害。③两组指标是否显著。
在日常工作中,如果能明显看出实验组的指标表现和对照组不同,可以不用显著性检验,直接判定实验起效,并由产品决定是否可以推广至全量。如肉眼判断不了两组差异,需使用假设检验(一般是用t检验)。
原假设:实验组和对照组的指标表现无差异。如果能拒绝原假设(p值足够小),则证明实验的功能改动确实造成了影响。
四、其他
1、互斥实验与正交实验
实验1和实验2的人群完全不同,则为互斥实验,如果把实验1和实验组2打乱,重新组合成实验组3和实验组4,那么实验组3和4为互斥实验,但和实验组1、2为正交实验。
2、什么情况下不能使用随机分流实验
①样本量太少。比如一天只有几百个活跃用户,实验的样本量不足以观测效果;再比如可能影响安全性的,无法进行大样本量的实验。
②实验组和对照组互相影响。如果发现实验组和对照组,除了实验本身应该改变的因素外,还影响到了其他因素,那么无法进行随机实验。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









