







参考书:MLAPP
机器学习中,从监督学习到非监督学习、从线性回归到聚类降维,最终都转化成求解一个优化问题。本文从数学角度记录机器学习中的优化问题,内容包括优化问题类型、求解算法、应用,这其实对应着:
- 定义问题—>模型
- 解决问题—>算法
- 应用
内容概要
1.目标函数的类型
机器学习常用最小化损失函数的思想求解参数,其优化问题对应:
min θ ∈ Θ L ( θ ) \min_{\theta\in\Theta}L(\theta) θ∈ΘminL(θ)
不同的 L L L和变量空间 Θ \Theta Θ确定了不同的优化模型,而模型的特征和性质决定了解的存在性、判断最优解和求解的方法。
- 无约束优化VS有约束优化
假设 Θ \Theta Θ是整个 R D \mathbb{R}^D RD,那么相当于可以在整个D维空间上搜索解,无需考虑范围限制,这时对应的是无约束优化。
假设 Θ ⊂ R D \Theta\subset\mathbb{R}^D Θ⊂RD,那么需要考虑目标变量的搜索范围,这时对应的是约束优化。

上图可知,有无约束对于解的存在性和求解方法非常重要。
-
凸优化VS非凸优化
假设目标函数 L L L是凸函数,并且参数空间 Θ \Theta Θ是凸集,那么模型就是凸优化模型,否则即为非凸模型。
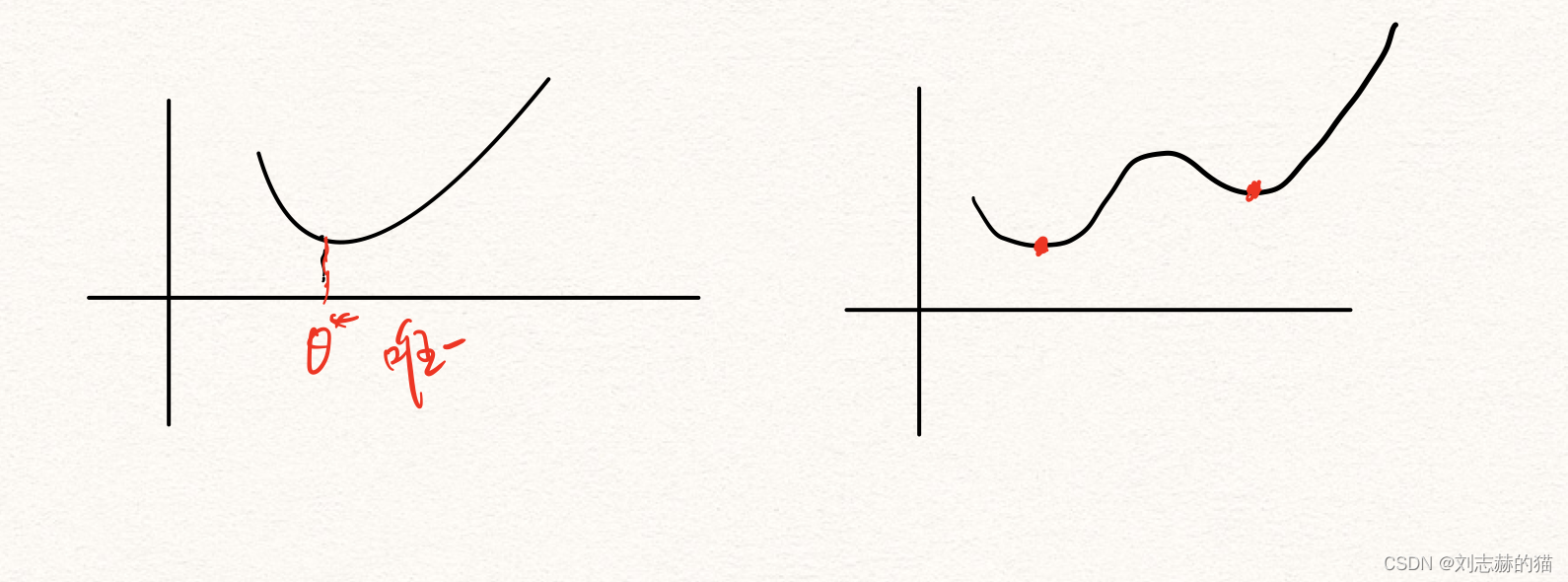
凸优化是一类性质非常好的模型,理论十分完善。由于凸优化的局部最优就是全局最优,所以求解凸优化时只需要找到局部最优解即可。
而非凸优化不仅不能保证局部解就是全局解,还存在一类非常特殊的鞍点,使得梯度下降陷入局部解无法继续下降。 -
光滑优化VS非光滑优化
假设目标函数 L L L满足一定的光滑条件,比如拉普拉斯光滑条件 ∣ L ( x ) − L ( y ) ∣ ≤ a ∣ x − y ∣ |L(x)-L(y)|\leq a|x-y| ∣L(x)−L(y)∣≤a∣x−y∣就称为一阶光滑。
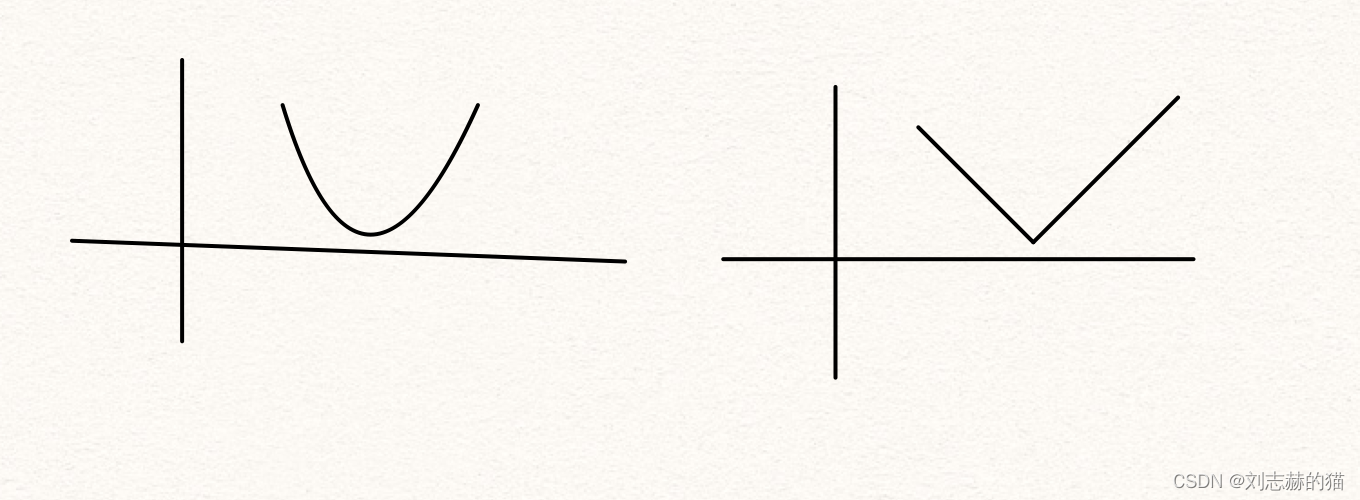
优化问题常用梯度下降,对于非光滑的目标函数,无法求得梯度,因此需要用到别的方法求解,比如下一节提到的次梯度下降等。
2.求解算法
2.1 一阶方法
一阶方法是指在求解过程中用到了目标函数的一阶梯度(次梯度)信息。
梯度下降
迭代格式:
θ t + 1 = θ t + η t d t \theta_{t+1}=\theta_t+\eta_td_t θt+1=θt+ηtdt
- 下降方向:使得目标函数减少的 d t d_t dt,即 L ( θ t + 1 ) < L ( θ t ) L(\theta_{t+1})<L(\theta_t) L(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









