









高维统计需要对随机变量进行估计和误差分析,其使用的工具和方法与传统统计有所差异。
统计学研究的内容涉及:
- 怎么估计
a. 抽样出样本
b. 参数估计:eg无偏估计 θ ^ → θ \hat\theta\rightarrow\theta θ^→θ
c. 模型分析
d. 优化问题求解:梯度下降 - 估计的合理性
a. 误差估计: ∣ ∣ θ ^ − θ ∣ ∣ ||\hat\theta-\theta|| ∣∣θ^−θ∣∣
我们都知道用样本均值估计总体均值,样本协方差矩阵估计总体协方差矩阵,但是为什么能这样估计?估计的误差怎么衡量?这就是模型分析和误差估计要做的事情。
这篇note对后续所需要的随机变量估计涉及的不等式进行讨论,例如常用随机变量(sub-gaussian\sub-exponential)的不等式、推导不等式的所用工具和方法。
PartA–Basic tail and concentration bounds
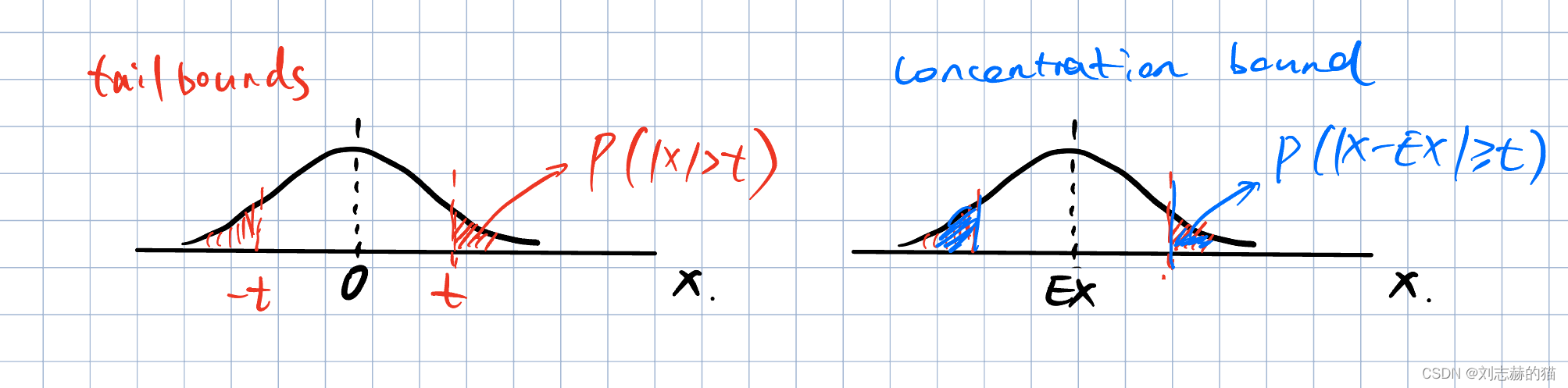
什么是tail bounds,concentration bounds?
随机变量
x
x
x的值用概率大小来度量,实际应用往往需要估计随机变量处在某个区间的概率,tail bounds是估计
P
(
∣
x
∣
>
t
)
P(|x|>t)
P(∣x∣>t),concentration bounds是估计
P
(
∣
x
−
μ
∣
≥
t
)
P(|x-\mu|\geq t)
P(∣x−μ∣≥t)
A1. 常用的tail bounds
(1)markov不等式
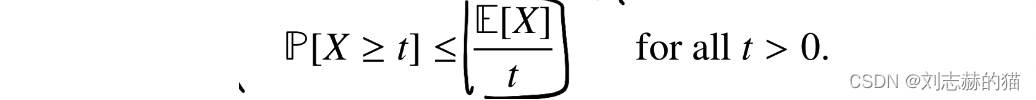
(2)chebyshev不等式
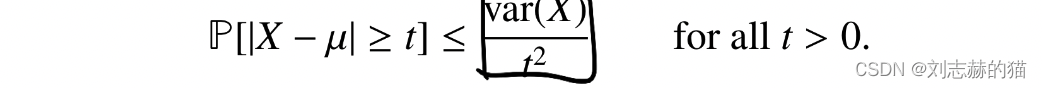
(3)markov不等式的推广
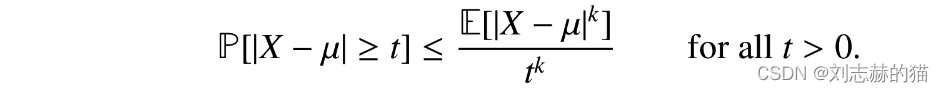
(4)chernoff bound
从moment generating function角度,设
ϕ
(
λ
)
=
E
[
e
λ
(
X
−
μ
)
]
\phi (\lambda)=\mathbb{E}[e^{\lambda (X-\mu)}]
ϕ(λ)=E[eλ(X−μ)]
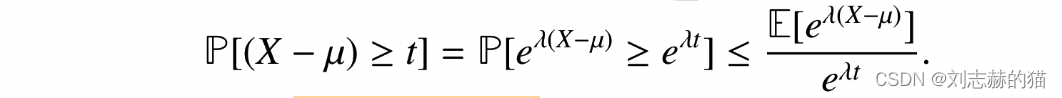
两边取对数,即得到chernoff bound:
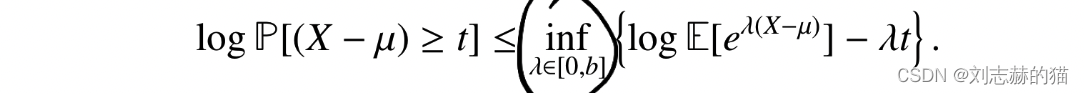
example1-(gaussian tail bound)

抽象出具有这样upper deviation不等式的随机变量,即sub-gaussian随机变量
A2. sub-gaussian和sub-exponential的tail bounds
sub-gaussian
(1)sub-gaussian定义
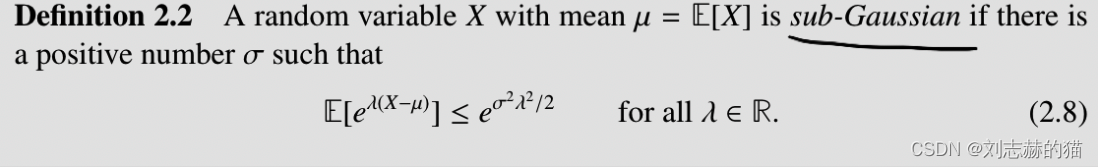
(2)concentration inequality
sub-gaussian随机变量
X
X
X是满足upper deviation不等式的,那么
−
X
-X
−X是满足lower deviation不等式的,合起来就是concentration不等式:
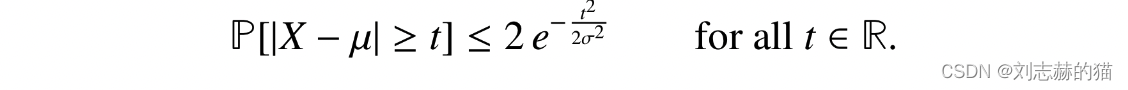
(3)一些sub-gaussian的例子
example1–Rademacher variables
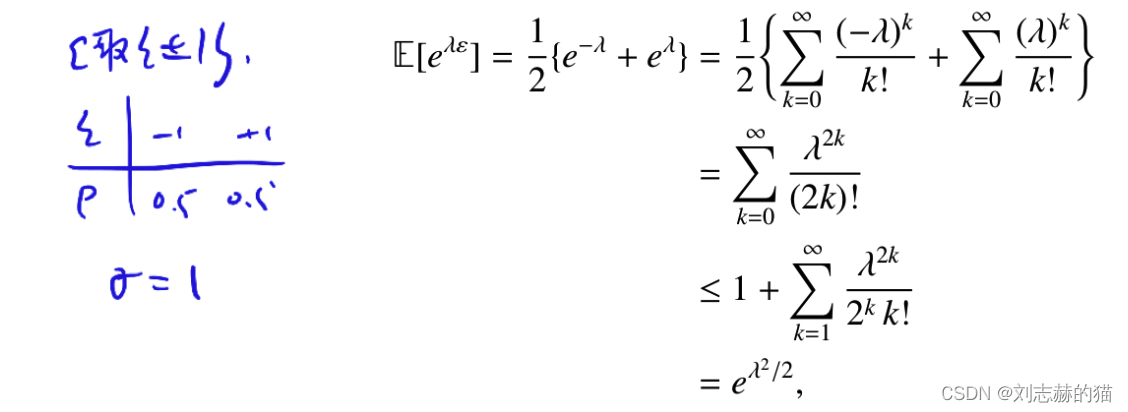
example2–Bounded random variables
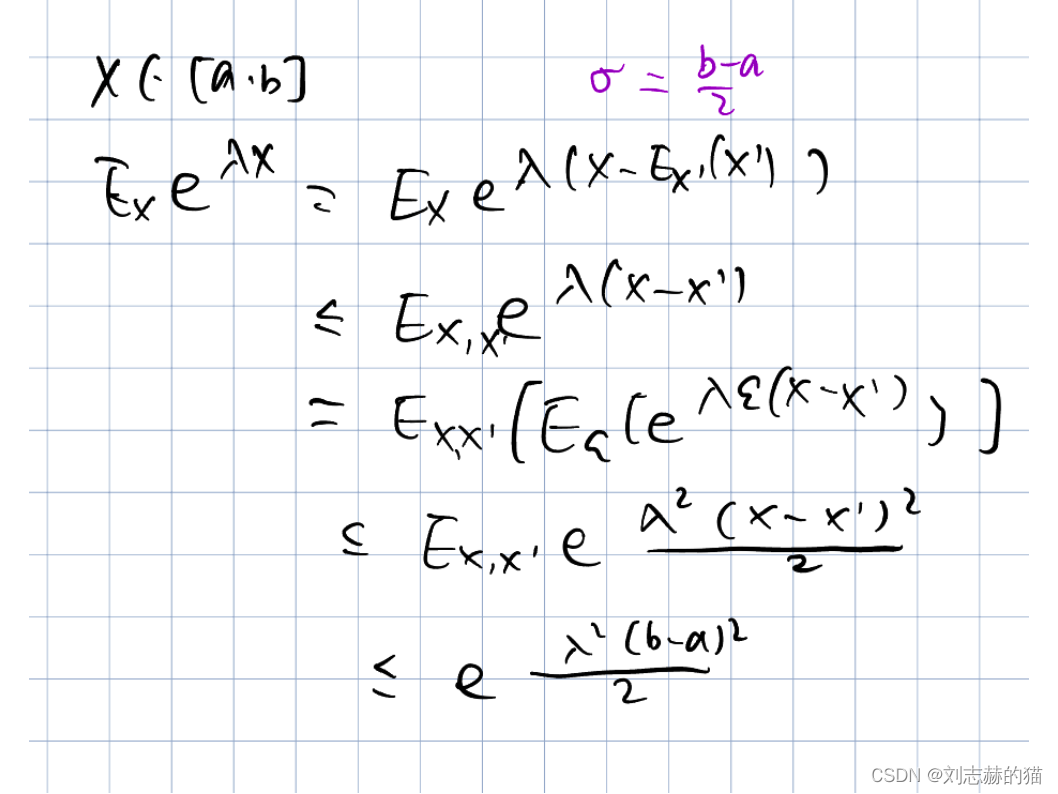
(4)sub-gaussian的和----hoeffding bound
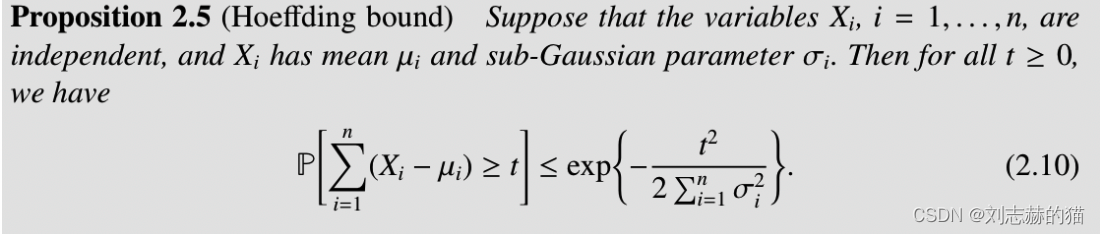
(5)sub-gaussian的等价定义方式
- MGF
- 任意sub-gaussian都能用高斯随机变量衡量
- 控制moments

比sub-gaussian条件宽松的随机变量–sub-exponential
(1)sub-exponential的定义
和sub-gaussian不同的是,sub-exponential只要求在某区间上满足不等式
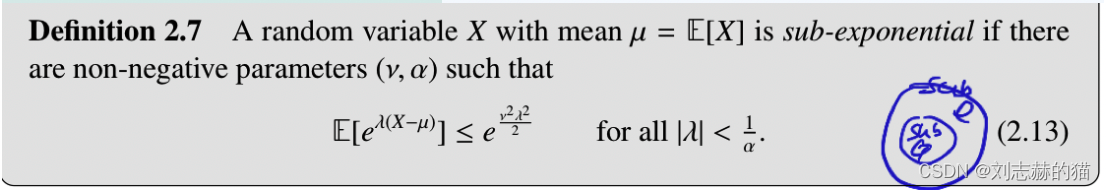
(2)tail bound和concentration bound(bernstein不等式)

根据sub-exponential的定义,将估计MGF推广到估计
(
X
−
μ
)
k
(X-\mu)^k
(X−μ)k,就是bernstein条件:
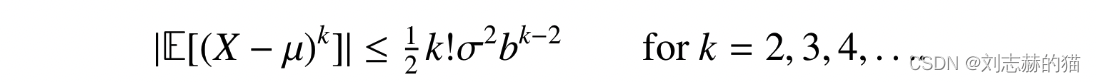
利用bernstein条件可以获得比hoeffding bound更紧的界:
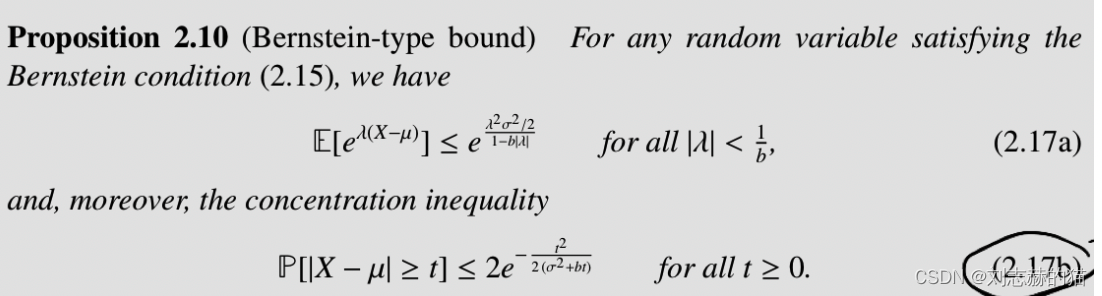
(3)sub-exponential的和
X
k
X_k
Xk是sub-exponential的,参数
(
γ
k
,
α
k
)
(\gamma_k,\alpha_k)
(γk,αk),那么
∑
k
=
1
n
(
X
k
−
μ
k
)
\sum_{k=1}^n(X_k-\mu_k)
∑k=1n(Xk−μk)也是sub-exponential的,参数为
(
γ
∗
,
α
∗
)
(\gamma_*,\alpha_*)
(γ∗,α∗),其中
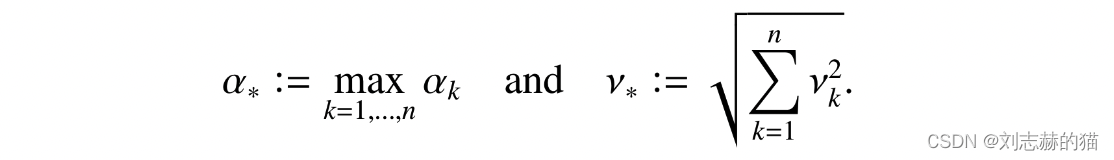
tail bounds:
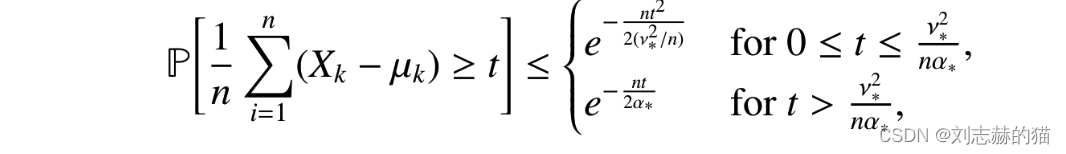
(4)sub-exponential的等价定义方式

(5)单边的bernstein不等式

从 ∑ i = 1 n ( X i − μ i ) \sum_{i=1}^n (X_i-\mu_i) ∑i=1n(Xi−μi)推广到 f ( X ) f(X) f(X)的bounds
goal:设 f : R n → R f:\mathbb{R}^n \rightarrow \mathbb{R} f:Rn→R,获得 f ( X ) − E [ f ( X ) ] f(X)-\mathbb{E}[f(X)] f(X)−E[f(X)]的界
(1)martingale
定义一个递增的
σ
−
\sigma-
σ−域
{
F
k
}
k
=
1
∞
\{\mathcal{F}_k\}_{k=1}^{\infty}
{Fk}k=1∞(也叫filtration),设
{
Y
k
}
k
=
1
∞
\{Y_k\}_{k=1}^{\infty}
{Yk}k=1∞在
F
k
\mathcal{F}_k
Fk上可测,则

D
k
=
Y
k
−
Y
k
−
1
D_k=Y_k-Y_{k-1}
Dk=Yk−Yk−1为martingale序列
(2)一些例子

(3)martingale序列
D
k
D_k
Dk的Concentration bounds

(4)利普希茨函数的bounds

PartB–Concentration of measure
得到tail bounds和concentration bounds的方法:
B1.entropy methods
(1)
ϕ
−
\phi-
ϕ−entropy
设
X
∼
P
X\sim\mathbb{P}
X∼P,凸函数
ϕ
:
R
→
R
\phi:\mathbb{R}\rightarrow \mathbb{R}
ϕ:R→R,定义一个衡量随机变量可变性(扰动)的度量:
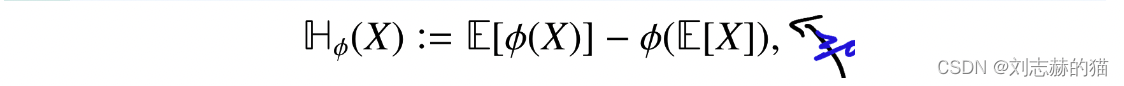
例子:
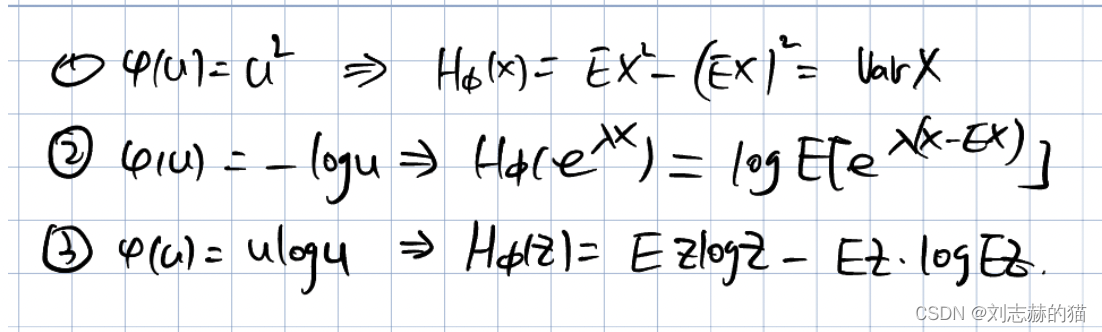
设MGF为
φ
X
(
λ
)
=
E
[
e
λ
X
]
\varphi_X(\lambda)=\mathbb{E}[e^{\lambda X}]
φX(λ)=E[eλX],则entropy和MGF的关系:
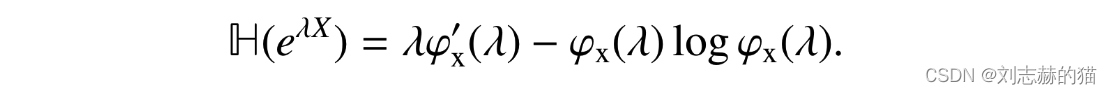
(2)entropy与tail bounds
entropy是衡量随机变量可变性(扰动)的度量,那么限制entropy就等于给随机变量找bounds:
- sub-gaussian

- sub-exponential
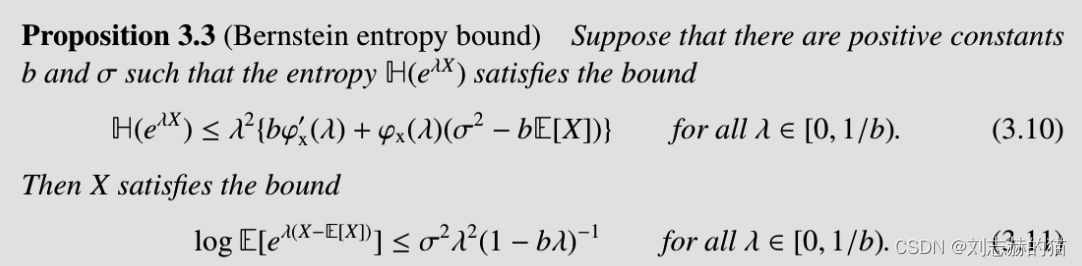
B2. 几何方法
(1)concentration function

Q1:concentration function怎么得到concentration bound?
Q2:当
ϵ
\epsilon
ϵ变大,concentration function会如何变化,它趋向于0的速度如何?
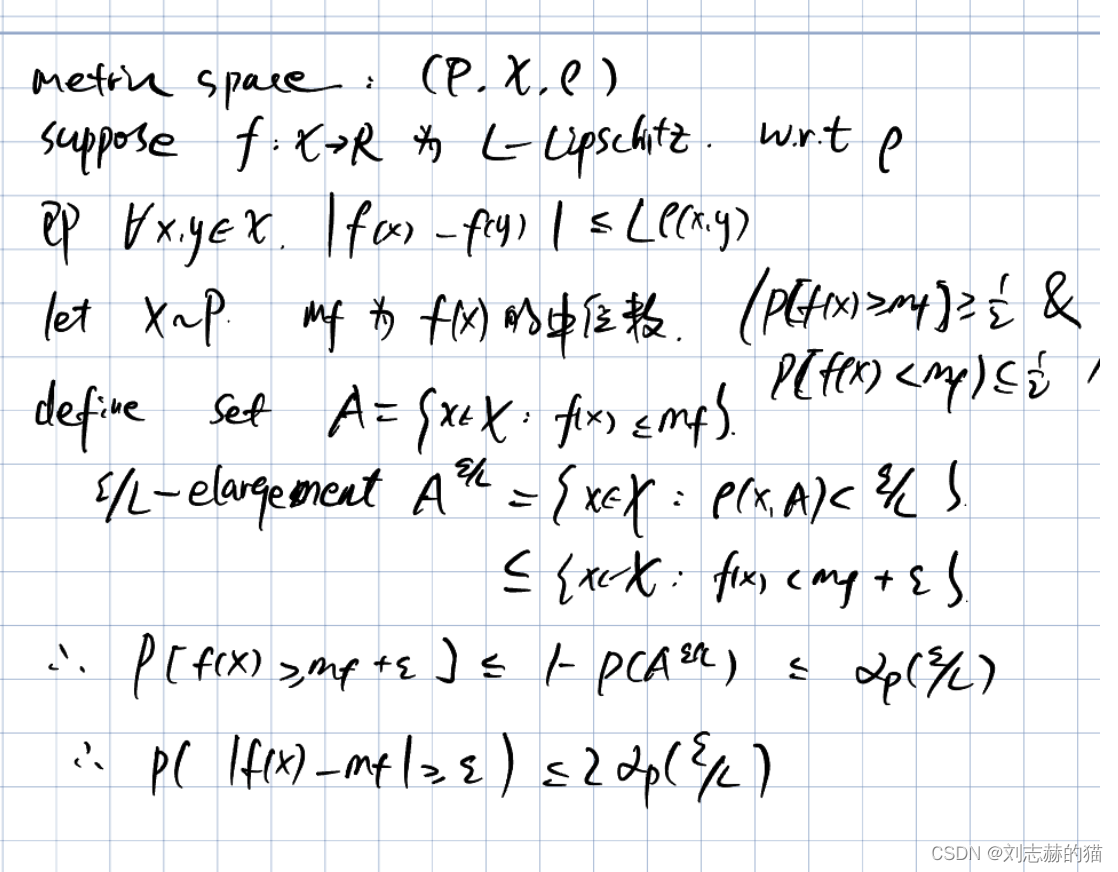

(2)从几何到concentration bounds
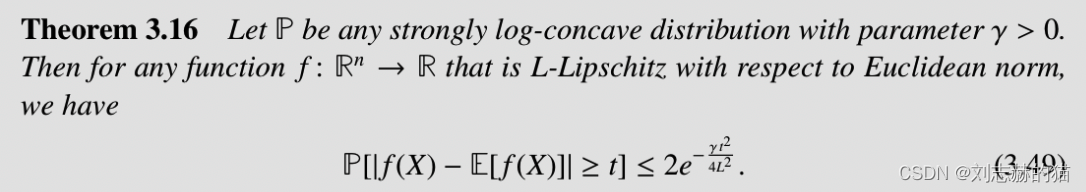
B3. transportation cost方法
(1)wasserstein distance
度量空间
(
X
,
ρ
)
(\mathcal{X},\rho)
(X,ρ)上的两个概率分布
Q
,
P
\mathbb{Q},\mathbb{P}
Q,P的距离:
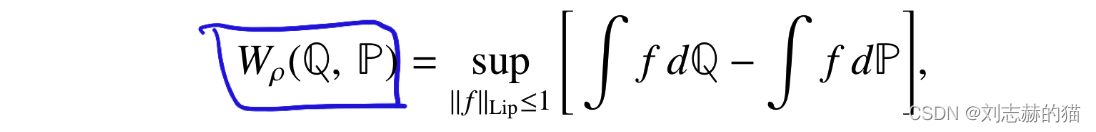
其中
∣
∣
f
∣
∣
L
i
p
||f||_{Lip}
∣∣f∣∣Lip是使得利普希茨条件成立的最小
L
L
L
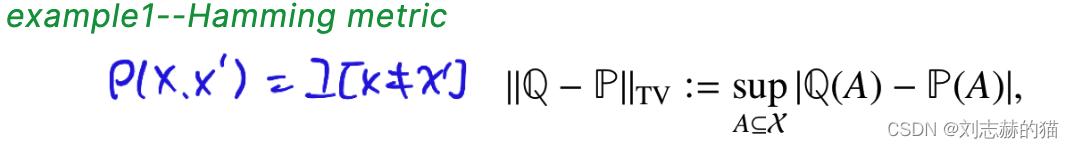
(2)wasserstein distance的对偶定义
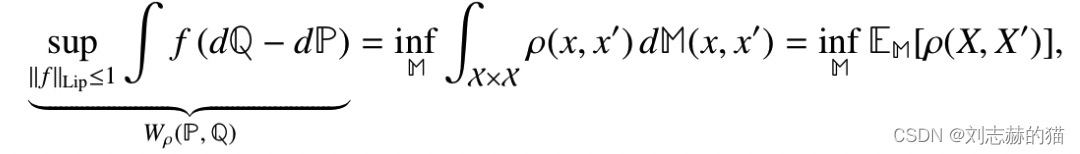
(3)KL散度

(4)Tensor for transportation cost

partC–大数定律
C1. 动机
累积分布函数
累计分布函数
F
(
t
)
=
P
(
X
≤
t
)
F(t)=\mathbb{P}(X\leq t)
F(t)=P(X≤t),
{
X
i
}
i
=
1
n
\{X_i\}_{i=1}^n
{Xi}i=1n是从
F
F
F中抽的独立样本,用经验累积分布函数
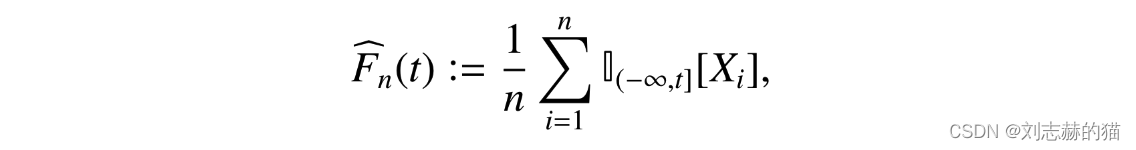
估计
F
F
F,由强大数定理可知
F
^
n
(
t
)
→
a.s
F
(
t
)
\hat{F}_n(t)\xrightarrow{\text{a.s}} F(t)
F^n(t)a.sF(t)(点点收敛);一致收敛是更为严格的收敛,对于用
γ
(
F
^
n
)
\gamma(\hat{F}_n)
γ(F^n)估计
γ
(
F
)
\gamma(F)
γ(F)提供理论支持

γ
(
F
^
n
)
\gamma(\hat{F}_n)
γ(F^n)估计
γ
(
F
)
\gamma(F)
γ(F)的例子:

一般函数
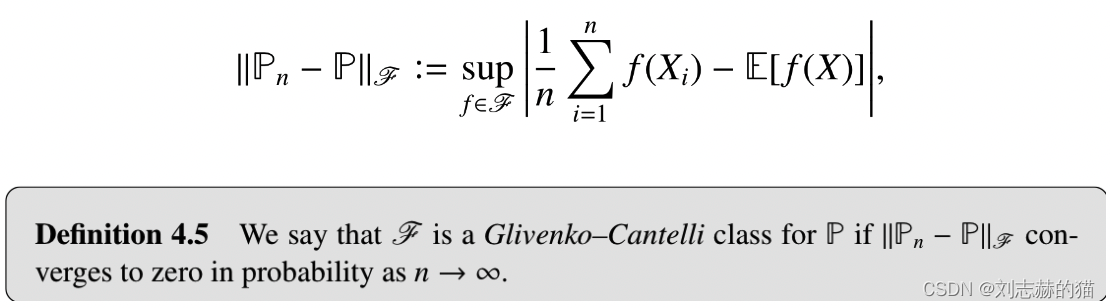
随机变量
∣
∣
P
n
−
P
∣
∣
F
||P_n-P||_{\mathscr{F}}
∣∣Pn−P∣∣F对于:
- empirical risk minimization
- decision-theoretic
十分关键
empirical risk
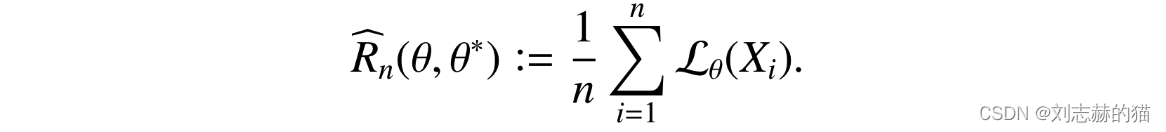
population risk
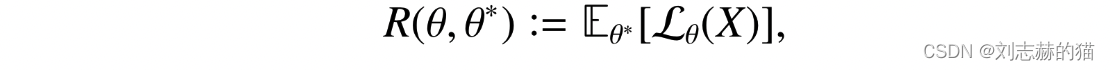
excess risk
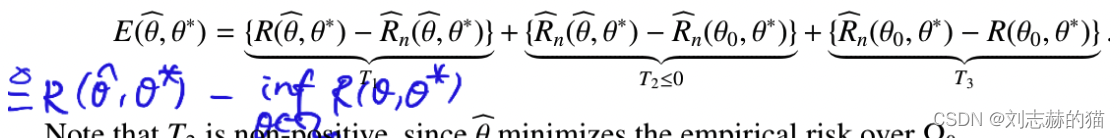
C2. Rademacher complexity
(1)定义empirical Rademacher complexity
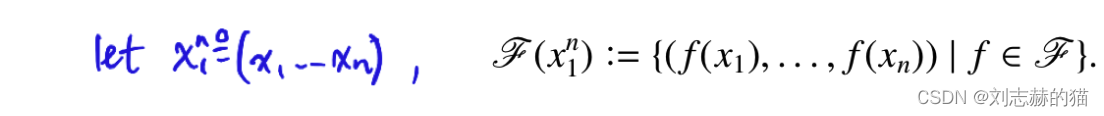
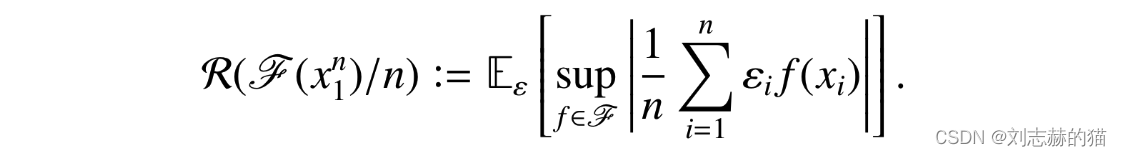
它衡量了
(
f
(
X
1
)
,
.
.
.
,
f
(
X
n
)
)
(f(X_1),...,f(X_n))
(f(X1),...,f(Xn))与噪声
(
ϵ
1
,
.
.
.
,
ϵ
n
)
(\epsilon_1,...,\epsilon_n)
(ϵ1,...,ϵn)的最大相关程度
对任意的有界函数集合 F \mathscr{F} F, R n ( F ) = o ( 1 ) \mathcal{R}_n(\mathscr{F})=o(1) Rn(F)=o(1)即为Glivenko–Cantelli property

求分布的误差可转换为求Rademacher complexity的上界
- 有限函数类:simple union bound methods
- 无线函数类:metric entropy、chaining arguments
method1—simple union bound methods
设 x 1 n = ( x 1 , . . . , x n ) x_1^n=(x_1,...,x_n) x1n=(x1,...,xn)为点集,集合 F ( x 1 n ) = { ( f ( x 1 ) , . . . , f ( x n ) ) ∣ f ∈ F } \mathscr{F}(x_1^n)=\{(f(x_1),...,f(x_n))|f\in\mathscr{F}\} F(x1n)={(f(x1),...,f(xn))∣f∈F}的“大小”提供了一种依靠样本的度量 F \mathscr{F} F的方式:
- F ( x 1 n ) \mathscr{F}(x_1^n) F(x1n)对所有样本都是有限的个数,那么大小就是cardinality
- 我们关系cardinality关于n成多项式增长的函数集

这类函数集的Rademacher complexity上界:

哪些函数满足polynomial discrimination
- Classical Glivenko–Cantelli
- Vapnik–Chervonenkis (VC) dimension

如果
ν
(
F
)
\nu(\mathscr{F})
ν(F)有限,则称
F
\mathscr{F}
F为VC类;任意有限VC类都满足 polynomial discrimination(degree最大为VC dim)

method2— Metric entropy
(1)覆盖数的定义
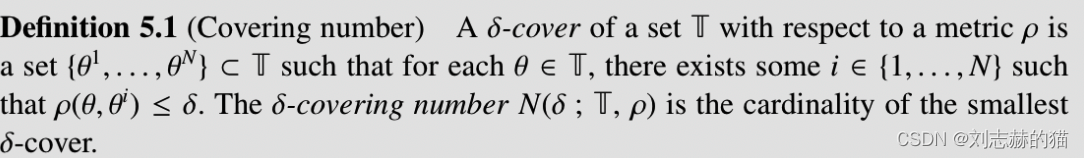
log
N
(
δ
;
T
,
ρ
)
\log N(\delta;\mathbb{T},\rho)
logN(δ;T,ρ)为metric entropy

以上用了不同的方法获得上下界,packing number可以把这两种方法统一
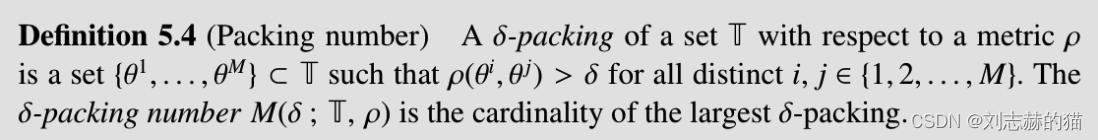
packing number和覆盖数的关系:
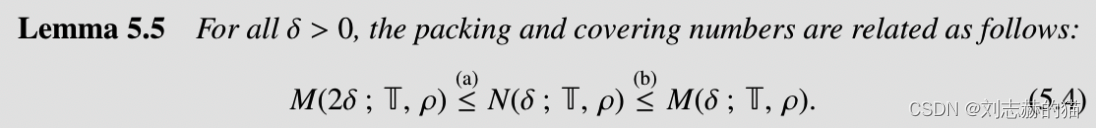
(2)使得metric entropy满足的几何性质

(3)随机过程
metric entropy描述的是确定的
随机过程的描述
{
X
θ
,
θ
∈
T
}
\{X_\theta,\theta\in\mathbb{T}\}
{Xθ,θ∈T}往往依赖指标集
T
\mathbb{T}
T的结构
考虑两个方向的问题:
- 给定 T \mathbb{T} T的结构,随机过程的表现如何
- 给定随机过程,指标集 T \mathbb{T} T会有什么性质
12相互作用的例子:Gaussian and Rademacher complexity

两者关系:
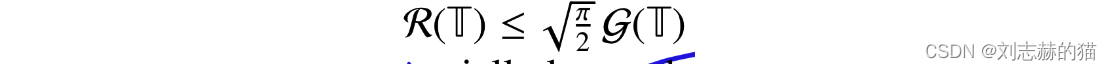
(4)更一般的:sub-Gaussian processes

upper bound

tighter bound

lower bound
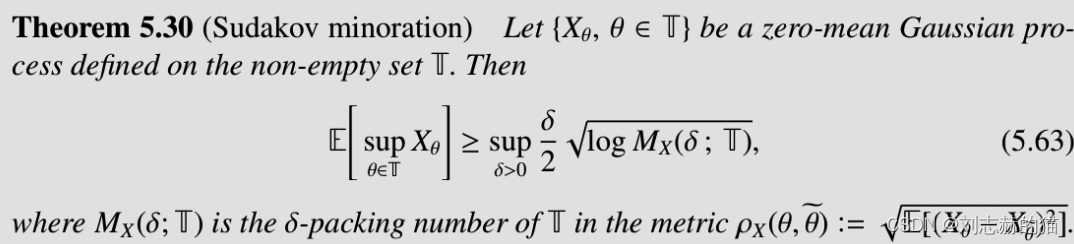















 1024
1024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









