TiDB架构体系章节
1.TiDB的目的
1.更细粒度的的弹性扩容
2.高并发读写
3.数据不丢不错
4.多副本一致性和高可用
5.支持分布式事务
2.b-tree和LSM-tree
b-tree
1.两次写入 预写,写
2.读友好,写不友好(因为是平衡树)
3.无法集群,只能靠主节点
LSM-tree
1.用空间置换写入延迟,用顺序写替换随机写入
1.解决写的问题,先写10M,之后在合并到100M
2.RocksDB引擎(支持批量写入,无所快照读)
3.复制协议(raft协议)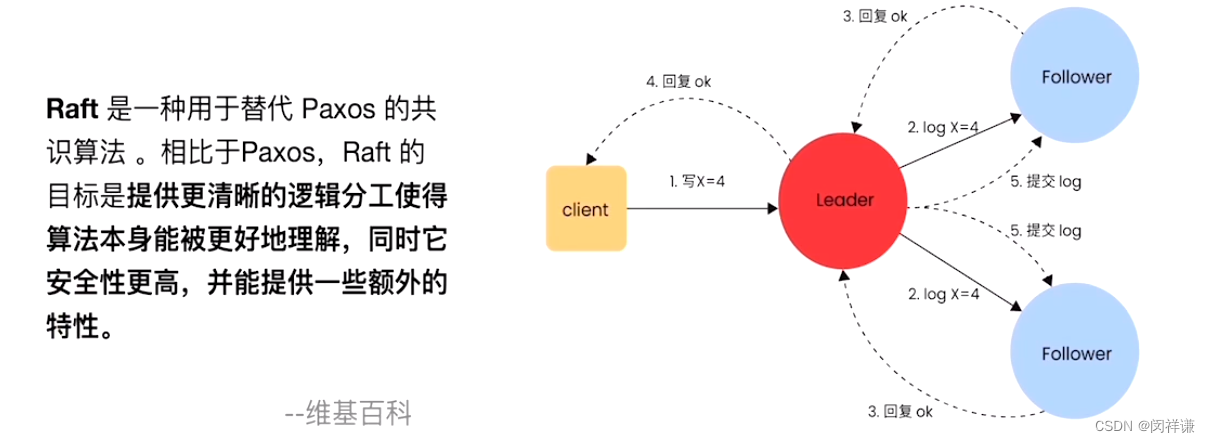
4.扩展分片
静态分表
提前规划,拓展性差
动态分表
hash range list 三种方式,Tikv用的是range
优点:
1.更有效的扫描数据
2.更好的合并分裂(LSM-tree配合)
3.弹性优先
缺点:
1.热点分片(最新分片最热)
5.Region
1.想等大小的k-v字段
2.通过key找region再找分片
3.灵活调度(96M默认自增分片,20M合并分片)
6.事务(MVCC)
1.在key后面加版本号 eg:key——version -->value
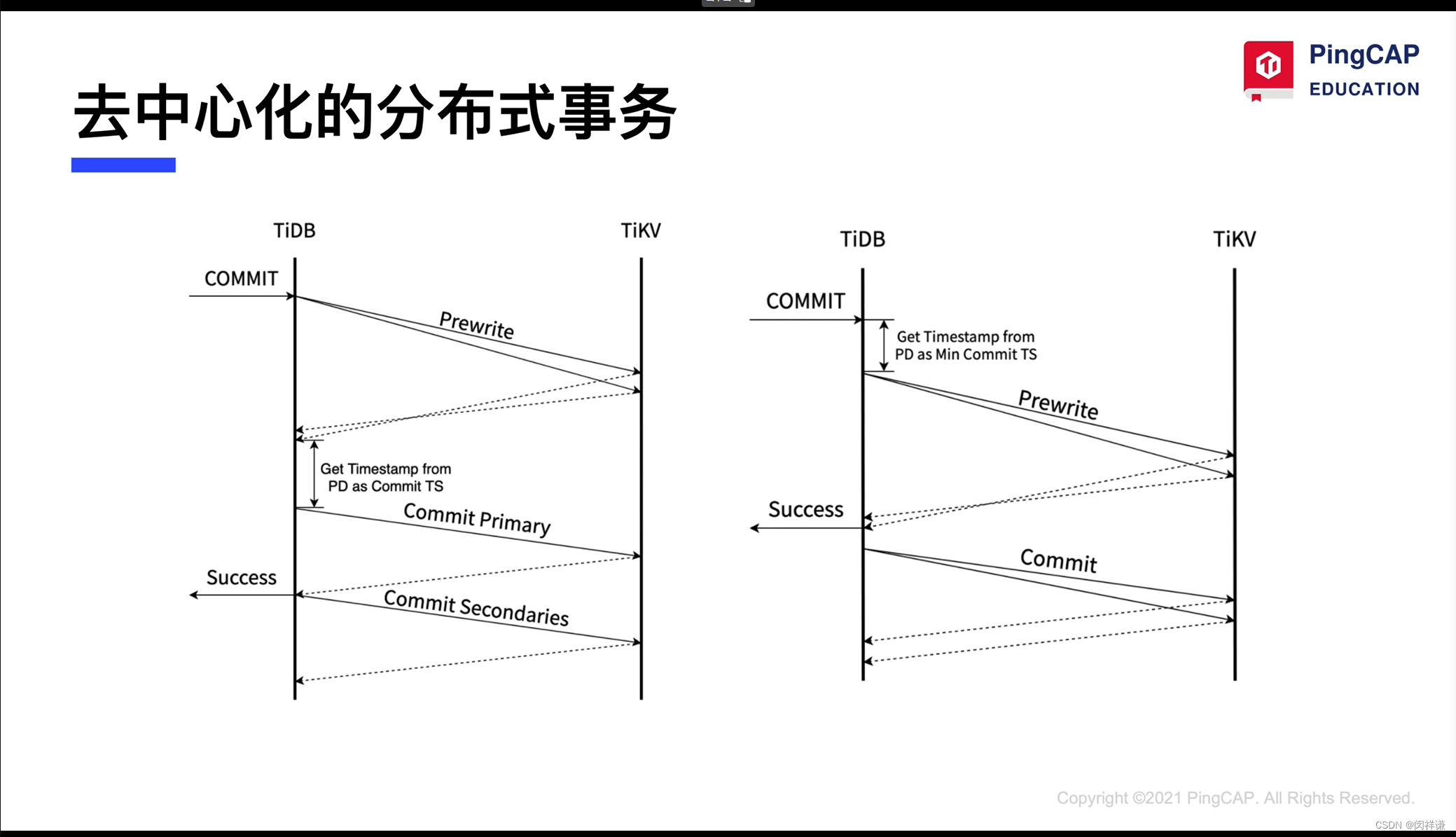
2.去中心化两阶段提交
a.每个Tikv单独存放锁的信息
b.GooglePercolator 事务模型
c.Tikv支持完整事务 kvAPI
d.默认乐观锁事务模型(3.0以上版本支持悲观锁)
e.默认隔离级别 Snapshot Lsocation
7.协作处理器
每个tikv都有,向下查找(更好使用LSM-tree)
8.在KV上实现逻辑
1.index实现:Index --> PrivateKey -->列信息
2.SQL:参考mysql
3.AST:文本-->结构化数据
4.Logical Plan :将sql改写优化
5.Optimized Logical Plan :生成执行计划(最重要的一步)
6.select:查找
9.分布式SQL引擎优化计算
会将sql下推到下面各自执行
10.关键算计分布式化
分批并行的 执行join查询,所以更快
11.online DDL算法
1.表只有一个
2,schema新增列,新数据会变更,旧数据不变更,等到查询使用的时候才变更
3.分状态来多节点的完成DDL
12.内部结构
1.mysql
2.tidb
3.执行器
13.前台功能
1.管理链接和账号权限
2.mysql协议转码解码
3.独立sql执行
4.库表信息
14. 后台功能
1.垃圾回收
2.执行DDL
3.统计信息管理
4.sql执行器优化
15.HTAP
OLTP:高并发,低延迟
OLAP:吞吐量
tidb作为数据中台优点
1.海量存储,实时同步
2.支持标准的Sql,夺标联查快(就是第十一知识点)
3.透明多业务模块,支持分表聚合后可以任务维度查询
4.tidb最大下推机制。以及并行hash join 等算子决定tisb在表关联查询上的优势
16.Spark
只能提供低并发的重量查询
列存:对PLAP查询友好,维护麻烦
DeltaMertge 解决上述问题 https://cn.pingcap.com/blog/how-tidb-implements-columnar-storage-engine 参考
17.MPP(解决算力)
1.并行计算
2.将查询下推到每个节点
18 .三个分布式系统
1.分布式的kv存储系统
2.分布式sql计算系统
3.分布式的HTAP架构系统
优势:
1.自动分片技术是更细维度弹性的基础
a.全局有序kvmap
b.等长的分片
c.分片连续有序
d.seek成本固定
e.region是复制调度的最小单位
2.弹性分片让系统更加动态
a.自动merge(96m自增 20m合并)
3.Multi-Raft
a.Raft Multi-Raft
b. leader floewer listener
c. 强主模式 读写都在leader上
d.4.0版本以后开启folower read
4.基于Multi-Raft实现谢图的线性扩展
当新增物理节点,整个集群的写入量会线性增长
5.基于Multi-Raft实现阔IDC单表多节点写入
一张表可以统计多个节点写入
6.去中心化的分布式事务
7.local read and Geo-Partition
a.多地部署,低延时访问
b. 数据安全合规,数据不出国
c.支持异地多活容灾
d.冷热数据分离
8、更大的数据容量下的TP和AP融合
a.引入实时更新的列式存储(解决了资源隔离,提高了AP效率)
b.列式存储使用MPP,实现了Sql join的下推并行处理
c. 通过Raft-base提高了时效性
d. 融入大数据生态Tispark
9.数据服务的统一
19.典型场景
1.分库分表(先分表不行在分库)
分表.b-tree结构问题导致要分库分表
分库:写入全看主节点,从只复制
2.real-time HTAP
20 数据架构模型
1.稳定
2.效率
3.成本
4.安全
5.开源























 8461
8461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









