







训练模型
训练模型就是搜寻使成本函数(在训练集上)最小化的参数组合。
有助于快速定位到合适的模型、正确的训练算法,以及一套适当的超参数。

一、线性回归(LinearRegression)
线性模型就是对输入特征加权求和,再加上一个偏置项的常数,以此进行预测。
线性回归模型预测:

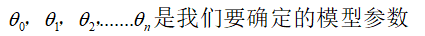
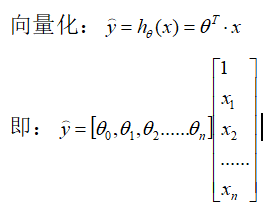
衡量一个回归模型性能指标:均方根误差(RMSE),但求均方误差(MSE)更方便

我们生成一些线性数据来测试这个公式
import numpy as np
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
X表示100个数据的1个特征属性
以点的形式来表示100个数据:
生成的线性函数是y=4+3x
from matplotlib import pyplot as plt
plt.xlabel("X")
plt.ylabel("y")
plt.scatter(X, y, marker = 'o', color = 'green', s = 40)
plt.show()

现在,我们使用标准方程来计算θ。使用Numpy的线性代数模块(np.linalg)中的inv()函数来对矩阵求逆,并用dot()方法计算矩阵内积:
X_b = np.c_[np.ones((100, 1)), X]
theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y)
theta_best
得到
array([[3.86709543],
[3.16372488]])
现在可以用θ做预测了
X_new = np.array([[0],[2]])
X_new_b = np.c_[np.ones((2,1)), X_new]
y_predict = X_new_b.dot(theta_best)
y_predict
这是预测X=0和X=2的值
得到
array([[ 3.86709543],
[10.19454519]])

绘制模型的预测结果
plt.plot(X_new, y_predict, "r-")
plt.plot(X, y, "b.")
plt.axis([0, 2, 0, 15])
plt.show()

Scikit-Learn的等效代码
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X, y)
lin_reg.intercept_, lin_reg.coef_
注意:Scikit-Learn将偏置项(intercept_)和特征权重(coef_)分离开了。
得到
(array([3.86709543]), array([[3.16372488]]))
结果与上面得到的结果一致。
二、梯度下降
适合于特征数或者训练实例数量大到内存无法满足要求的场景
梯度下降的中心思想就是迭代地调整参数从而使成本函数最小化
梯度下降的做
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









