







第一天
(1)从torchvision中加载resnet18模型结构,并载入预训练好的模型权重 ‘resnet18-5c106cde.pth’ (在物料包的weights文件夹中)。
import torch
#从torchvision库中加载模型结构
import torchvision.models as models
model = models.resnet18()
#读取预训练好的模型权重
pretrained_state_dict=torch.load('./weights/resnet18-5c106cde.pth')
#将读取的权重载入model
model.load_state_dict(pretrained_state_dict, strict=True)
(2)将(1)中加载好权重的resnet18模型,保存成onnx文件。
resnet18.onnx文件大小为45648KB

(3)以torch.rand([1,3,224,224]).type(torch.float32)作为输入,求resnet18的模型计算量和参数量。
Model: 1.82 GFLOPs and 11.69M parameters
(4)以torch.rand([1,3,448,448]).type(torch.float32)作为输入,求resnet18的模型计算量和参数量。
Model: 7.27 GFLOPs and 11.69M parameters
源码
import torch
'''
(1) 从torchvision中加载resnet18模型结构,并载入预训练好的模型权重 'resnet18-5c106cde.pth'
'''
#从torchvision库中加载模型结构
import torchvision.models as models
model = models.resnet18()
#读取预训练好的模型权重
pretrained_state_dict=torch.load('./weights/resnet18-5c106cde.pth')
#将读取的权重载入model
model.load_state_dict(pretrained_state_dict, strict=True)
'''
(2) 将(1)中加载好权重的resnet18模型,保存成onnx文件。
'''
#模型放置CPU
model.to(torch.device('cpu'))
#模型变为推理状态
model.eval()
#构建一个项目推理时需要的输入大小的单精度Tensor,并且放置模型所在的设备(CPU或CUDA)
inputs=torch.ones([1,3,224,224]).type(torch.float32).to(torch.device('cpu'))
#生成onnx
torch.onnx.export(model, inputs, './weights/resnet18.onnx', verbose=False)
'''
(3) 以torch.rand([1,3,224,224]).type(torch.float32)作为输入,求resnet18的模型计算量和参数量。
(4) 以torch.rand([1,3,448,448]).type(torch.float32)作为输入,求resnet18的模型计算量和参数量。
'''
#从torchvision库中加载模型结构
import torchvision.models as models
model = models.resnet18()
#构建一个适合模型输入大小的单精度Tensor
inputs=torch.ones([1,3,224,224]).type(torch.float32)
inputs2=torch.ones([1,3,448,448]).type(torch.float32)
#统计计算量和参数量
from thop import profile
flops, params = profile(model=model, inputs=(inputs,))
flops2, params2 = profile(model=model, inputs=(inputs2,))
print('Model: {:.2f} GFLOPs and {:.2f}M parameters'.format(flops/1e9, params/1e6))
print('Model2: {:.2f} GFLOPs and {:.2f}M parameters'.format(flops2/1e9, params2/1e6))
第二天
(1)把模型改为 resnet18,加载相应的模型权重(Lesson2 的物料包中有),跑一下 0.jpg和 1.jpg,看一下输出结果。官方 torchvision 训练 mobilenet 和训练 resnet 的方式是一样的,所以数据预处理和数据后处理部分完全相同。
('umbrella', 0.2279825508594513)
('peacock', 0.9976727366447449)
(2)自己找 2 张其他图,用 resnet18 做下推理。

翻车了
('kite', 0.3684402108192444) # bald-eagle.jpg
('quill', 0.013711282052099705) # hen.jpg
(3)以 ResNet18 为例,用 time 模块和 for 循环,对”./images/0.jpg”连续推理 100次,统计时间开销,比如:
# 有 CUDA 的,改下代码:self.device=torch.device('cuda')。用上述相同方法测试时间开销。
model_classify=ModelPipline()
import time
image=cv2.imread("./images/0.jpg")
t_all=0
for i in range(100):
t_start=time.time()
result=model_classify.predict(image)
t_end=time.time()
t_all+=t_end-t_start
print(t_all)
测试结果
('kite', 0.3684402108192444)
4.733127117156982
源码
import torch
import torchvision.models as models
import numpy as np
import cv2
import time
class ModelPipline(object):
def __init__(self):
# 进入模型的图片大小:为数据预处理和后处理做准备
self.inputs_size = (224, 224)
# CPU or CUDA:为数据预处理和模型加载做准备
self.device = torch.device('cuda')
# 载入模型结构和模型权重
self.model = self.get_model()
# 载入标签,为数据后处理做准备
label_names = open('./labels/imagenet_label.txt', 'r').readlines()
self.label_names = [line.strip('\n') for line in label_names]
def predict(self, image):
# 数据预处理
inputs = self.preprocess(image)
# 数据进网络
outputs = self.model(inputs)
# 数据后处理
results = self.postprocess(outputs)
return results
def get_model(self):
# 上一节课的内容
model = models.resnet18()
pretrained_state_dict = torch.load('./weights/resnet18-5c106cde.pth',
map_location=lambda storage, loc: storage)
model.load_state_dict(pretrained_state_dict, strict=True)
model.to(self.device)
model.eval()
return model
def preprocess(self, image):
# opencv默认读入是BGR,需要转为RGB,和训练时保持一致
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# resize成模型输入的大小,和训练时保持一致 image = cv2.resize(image, dsize=self.inputs_size)
# 归一化和标准化,和训练时保持一致
inputs = image / 255
inputs = (inputs - np.array([0.485, 0.456, 0.406])) / np.array([0.229, 0.224, 0.225])
##以下是图像任务的通用处理
# (H,W,C) ——> (C,H,W)
inputs = inputs.transpose(2, 0, 1)
# (C,H,W) ——> (1,C,H,W)
inputs = inputs[np.newaxis, :, :, :]
# NumpyArray ——> Tensor
inputs = torch.from_numpy(inputs)
# dtype float32
inputs = inputs.type(torch.float32)
# 与self.model放在相同硬件上
inputs = inputs.to(self.device)
return inputs
def postprocess(self, outputs):
# 取softmax得到每个类别的置信度
outputs = torch.softmax(outputs, dim=1)
# 取最高置信度的类别和分数
score, label_id = torch.max(outputs, dim=1)
# Tensor ——> float
score, label_id = score.item(), label_id.item()
# 查找标签名称
label_name = self.label_names[label_id]
return label_name, score
if __name__ == '__main__':
model_classify = ModelPipline()
t_all = 0
image = cv2.imread('./images/bald-eagle.jpg')
for i in range(100):
t_start = time.time()
result = model_classify.predict(image)
t_end = time.time()
t_all += (t_end - t_start)
print(result)
print(t_all)
# image = cv2.imread('./images/hen.jpg')
# result = model_classify.predict(image)
# print(result)
第三天
(1)对 “./images/car.jpg” 做语义分割,提取出里面的车辆,模仿上课时,对“可视化推理结果”和“BGRA 四通道图”进行保存。


(2)自己找 2 张其他图,对图中某个类别进行分割,并保存“BGRA 四通道图”。




(3)用 time 模块和 for 循环,对”./images/car.jpg”连续推理 100 次,统计时间开销。有 CUDA 的同学,改下代码:self.device=torch.device(‘cuda’),统计时间开销。
CPU连续推理时间:226.58551049232483 S
第四天
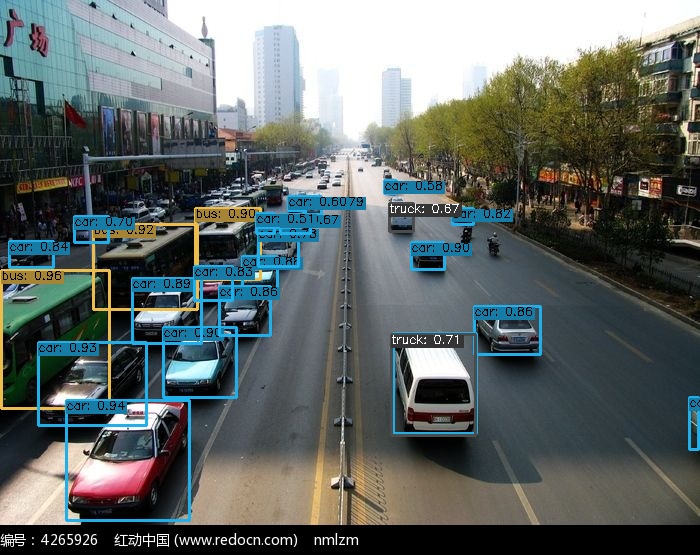
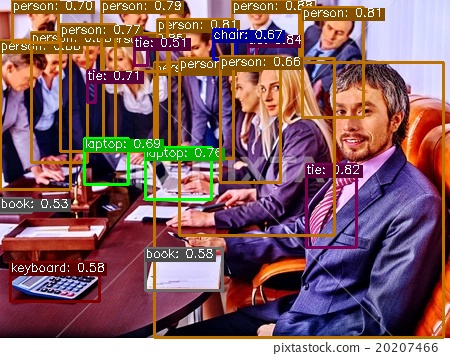
(1)自己找 2 张其他图,用 Yolox_s 进行目标检测,并注明输入尺寸和两个阈值。
第一张car.jpg(750x555)
第二张people.jpg(450x356)
阈值设置如下:
self.conf_threshold=0.5
self.nms_threshold=0.45
(2)Yolox_s:用 time 模块和 for 循环,对”./images/1.jpg”连续推理 100 次,统计时间开销。有 CUDA 的同学,改下代码:self.device=torch.device(‘cuda’),统计时间开销。
使用cuda(MX450):6.146997451782227
(3)有 CUDA 的同学,分别用 Yolox_tiny、Yolox_s、Yolox_m、Yolox_l、Yolox_x 对”./images/1.jpg”连续推理 100 次,统计时间开销。
使用cuda(MX450)
Yolox_tiny:
Yolox_s:6.146997451782227
Yolox_m:
Yolox_l:
Yolox_x:















 2497
2497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









