






目录
- 链接
- 附加:
- 关联知识
- 杂项
- vue2
- 为什么需要虚拟DOM
- 组件化的理解
- 折中办法
- 响应式数据的理解?
- vue中如何检测数组变化的?
- vue中如何实现响应式和进行依赖收集的?(面试-待定)
- computed和watch
- ref和reactive
- watch和watcheffect的区别?
- 如何将template转换成render函数?
- new vue()过程中发生了什么?(vue2)
- Vue.observable过程中发生了什么?(vue2)
- v-if和v-for那个优先级更高?
- 生命周期?
- vue中diff算法原理
- key的作用和原理
- Vue.use是干什么的?
- Vuex的响应式处理。
- Vue.extend 方法的作用?
- v-once的使用场景有哪些?
- vue中的mixin使用场景和原理
- vue中的slot如何实现的?
- 双向绑定原理
- vue中的.sync修饰符的作用
- 异步组件的作用和原理
- vue 如何优化首页的加载速度?vue 首页白屏是什么问题引起的?如何解决呢?
- webpack 打包 vue 速度太慢怎么办?
- 谈谈你对spa的理解?
- VDOM如何生成的?
- nextTick的理解?
- keep-alive的用法和原理
- 自定义指令的应用场景
- vue中的性能优化
- 40.单页应用首屏加载速度慢的怎么解决?
- 42、Vue 项目中有封装过 axios 吗?主要是封装哪方面的?
- 43、vue 要做权限管理该怎么做?如果控制到按钮级别的权限怎么做?
- 44、Vue-Router 有几种钩子函数,具体是什么及执行流程是怎样的
- 45、Vue-Router 几种模式的区别?
- 46.vue 项目本地开发完成后部署到服务器后报 404 是什么原因
- vuex
- 52.Vue3 中 CompositionAPI 的优势是?
- 53.Vue3 有了解过吗?能说说跟 Vue2 的区别吗?
- 54.Vue 项目中的错误如何处理的?
- 55.Vue3 中模板编译优化
- 56.你知道那些Vue3新特性
- 数据通信
- 路由
- vue-router导航守卫
- 双向绑定和 vuex 是否冲突
- vue3前置知识
- 5、(Vue核心虚拟Dom和 diff 算法)
- 6、(认识Ref全家桶)
- 7、认识Reactive全家桶
- 8、 toRef,toRefs,toRaw & 源码解析
- 11、watchEffect
- vue3
- 说说你使用 Vue 框架踩过最大的坑是什么?怎么解决的?
- ------------------------------分割线-----------------------------------
- 介绍模块化发展历程
- React
- 1、vue3新增变化
- 链接:
- vue3变化:(待定)
- 面试官:Vue3.0 所采用的 Composition Api 与 Vue2.x 使用的 Options Api 有什么不同?
- 面试官:Vue3.0的设计目标是什么?做了哪些优化
- 面试官:Vue3.0性能提升主要是通过哪几方面体现的?
- 面试官:说说Vue 3.0中Treeshaking特性?举例说明一下?
- ================ 分割线 ====================
- 介绍模块化发展历程
- webpack
- 常见面试题
- 以下面试题参考
- Webpack 的热更新原理
- Webpack怎么优化开发环境?(粗略)
- 如何⽤webpack来优化前端性能,优化打包结果?
- Babel原理
- webpack5新特性
- vite
- 杂项
- Babel之babel-polyfill、babel-runtime、transform-runtime详解
- pinia
链接
一些参考链接vue相关面试题参考以下内容即可:
- ✅b站视频:2023年最新Vue面试题剖析原理级讲解
- ❌vue2、vue3面试题汇总
- ❌Vue2到Vue3变化了什么?
- ❌未看: 【已完结】Vue高频面试题全套
- ❌剖析vue内部运行机制
- ❌想知道Vue3与Vue2的区别?五千字教程助你快速上手Vue3!
- ❌vue技术揭秘
附加:

关联知识
vue2、vue3、vite、pina、ts等
杂项
- filter在vue3中抛弃了,通过函数方法处理;
vue2
为什么需要虚拟DOM
- 概念:1、
virtul DOM就是用js对象来描述真实DOM,是对真实DOM的抽象,由于直接操作DOM性能低但是js层的操作效率高,可以将DOM操作转化为对象操作,最终通过diff算法比对差异来进行更新DOM。2、虚拟DOM不依赖真实平台环境从而也可以实现跨平台。 - VDOM是如何生成的?
- 我们平时在组件编写模板- template
- 这个模板会被编译为渲染函数- render
- 在页面渲染的时候会
调用render函数,返回的对象就是虚拟dom - 会在后续的
patch过程中转化为真实的DOM。
- vdom如何做diff的?
- 第一次生成的oldnode,响应式数据发生变化之后,将会引起组件重新render,此时就会生成VDOM-newVnode
- 使用old和new做diff操作,将更改的部分应用到真实的DOM上,从而转化为最小量的dom操作,高效更新视图。
组件化的理解
- 组件化的好处:高内聚、可重用、可组合
- vue可以做到只对组件级别的渲染
vue中的每个组件都有一个渲染函数watcher(vue2)、effect(vue3)。数据是响应式的,数据变化后会执行watcher或者effect。组件要合理的划分,如果不拆分组件,那更新的时候整个页面都要重新更新。如果过分拆分组件会导致watcher、effect产生过多也会造成性能浪费。
折中办法

响应式数据的理解?
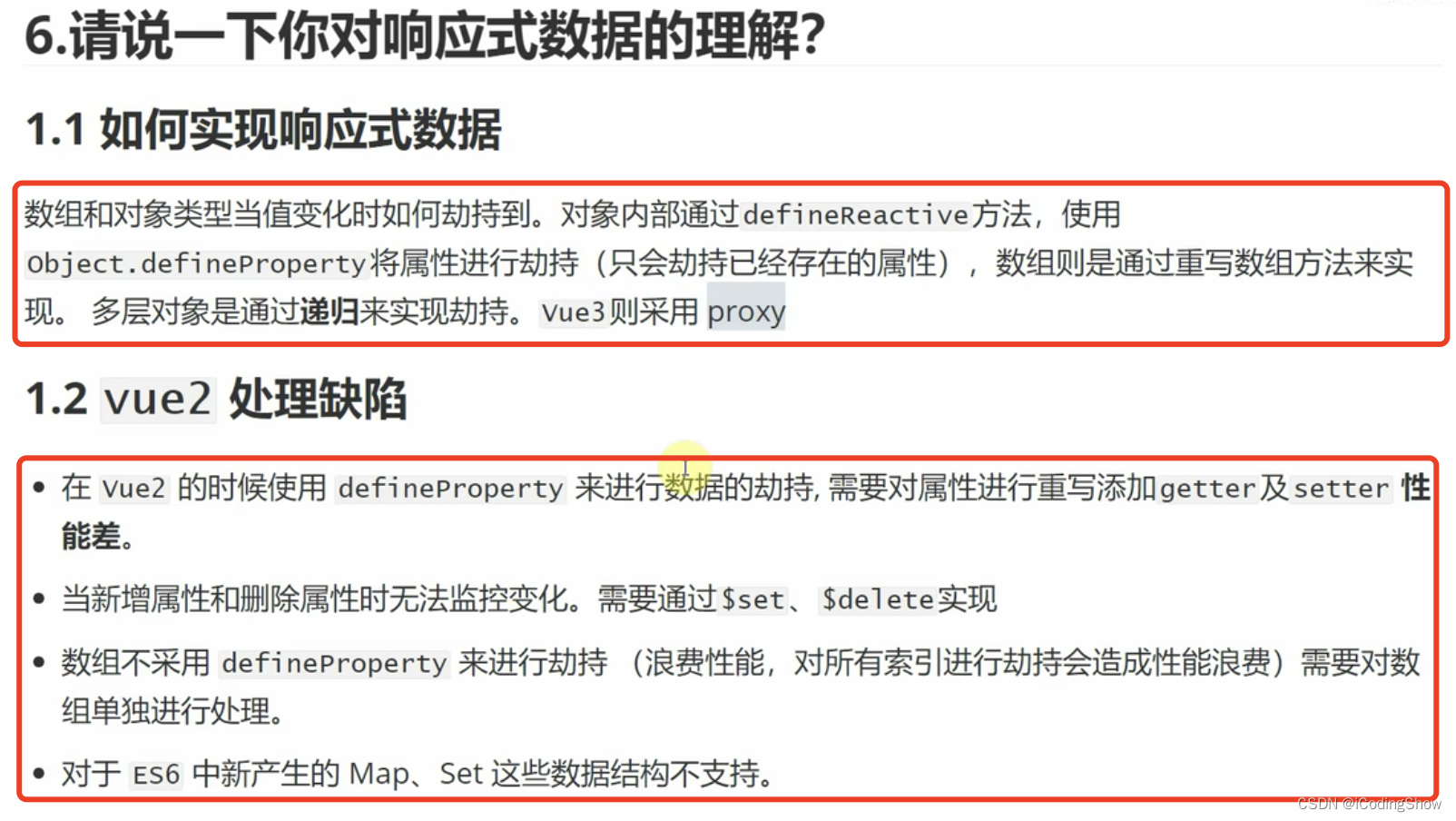
Object.defineProperty()重写属性,proxy是代理。
注意:
1、 数组
Object.defineProperty()是可以对数组实现监听操作的,但是vue并没有实现这个功能,因为数组长度不定而且数据可能会很多,如果对每一个数据都实现监听,性能代价太大。但是注意:数组中的元素是引用类型时是会被监听的(数组中如果是对象数据类型也会进行递归劫持)。vue对push,pop,splice等方法进行了hack,对于这些变异方法vue做了包裹,在原型上进行了拦截。
2、对象
Object.defineProperty()针对的是对象的某个属性,而且这个操作在vue的初始化阶段就完成了,所以新增的属性无法监听,通过set方法新增对象就相当于初始化阶段的数据响应式处理。
对象的替代方案:
// 新增
Vue.set(obj, newkey, newvalue)
vm.$set(obj, newkey, newvalue)
obj = Object.assign({}, obj, {newkey1: newvalue1, newkey2: newvalue2})
// 删除
Vue.delete(obj, key)
vm.$delete(obj, key)
delete 与 vm.$delete的区别?
1、删除对象结果一样:两者相同,都会把键名(属性/字段)和键值删除。
2、删除数组不同
delete,只是将要删除的变为undefined或者empty,不改变数组的键值名以及数组长度;
vm.$delete是直接将值完全删除掉,会改变数组的键值名以及数组长度;
Vue.set() 和 this.$set() 的区别?
import { set } from '../observer/index'
...
Vue.set = set
...
import { set } from '../observer/index'
...
Vue.prototype.$set = set
...
可以发现Vue.set()和this.$set()这两个 api 的实现原理基本一样,都是使用了set函数。
区别: Vue.set( ) 是将set函数绑定在 Vue 构造函数上,this.$set() 是将set函数绑定在 Vue原型上。
vm.$set 的实现原理
- 如果目标是数组,直接使用数组的
splice方法触发响应式; - 如果目标是对象,会先判断
属性是否存在、对象是否是响应式,如果存在,直接进行赋值;如果不存在,则是通过调用defineReactive方法进行响应式处理(defineReactive方法就是Vue在初始化对象时,给对象属性采用Object.defineProperty动态添加getter和setter的功能所调用的方法)
vue中如何检测数组变化的?
数组考虑性能原因没有使用defineProperty对数组的每一项进行拦截,而是选择重写数组(push等)方法;数组中如果是对象数据类型也会进行递归劫持;- 数组的缺点:数组的·
索引和长度变化·时无法监控到的。
替代方案:
// 修改值
vm.$set(arr, index, newvalue)
arr.splice(index, 1, newvalue)
// 修改数组长度
arr.splice(newLen)
因为:调用数组的pop、push、shift、unshift、splice、sort、reverse等方法时是可以监听到数组的变化的
vue3中使用proxy方法进行代理。
vue中如何实现响应式和进行依赖收集的?(面试-待定)
通过 Object.defineProperty 设置 setter 与 getter 函数,用来实现「响应式」以及「依赖收集」。
vue2依赖收集
- 每个属性都拥有自己的dep属性,存放他
所依赖的watcher,当属性变化后会通知自己对应的watcher去更新; - 默认在
初始化时调用render函数,此时会触发属性依赖收集dep.depend; - 当属性发生修改时会触发watcher更新dep.notify()
vue3依赖收集
- vue3中会通过
Map结构将属性和effect映射起来; - 默认在
初始化时调用render函数,此时会触发属性依赖收集track; - 当属性发生修改时会触发effect更新
trigger;
computed和watch
vue2中有三种watcher(渲染watcher、计算属性watcher、用户watcher)
vue3中有三种effect(渲染effect、计算属性effect、用户effect)
备注:计算属性watcher对应computed,用户watcher对应watch
- computed
计算属性仅当用户取值时才会执行对应的方法computed具备缓存的,依赖的值不发生变化,对其取值时计算属性方法不会重新执行- 不支持异步
- 原理:每一个计算属性内部维护一个dirty属性,当取值的时候,执行用户的方法,拿到值缓存起来并且将dirty标记为false,再次取值时,dirty标记为false直接返回缓存的值;当依赖变化时,dirty设为true,会触发更新,页面重新渲染,重新获取计算属性的值。
- watch
ref和reactive
- reactive用于处理对象类型的数据响应式。底层采用的是 new proxy()
- ref通常用于处理基本类型的响应式,ref主要解决原始值的响应式问题。底层采用的是OBject.defineProperty()实现的。(
new proxy只能对对象处理基本数据类型,基本数据类型不行) - ref的底层使用Object.defineProperty()对基本数据进行包装,把一个基本类型变成一个对象类型。
watch和watcheffect的区别?
watch 和 watchEffect 的主要功能是相同的,都能响应式地执行回调函数。它们的区别是追踪响应式依赖的方式不同:
- watch 只追踪明确定义的数据源,
不会追踪在回调中访问到的东西;默认情况下,只有在数据源发生改变时才会触发回调;watch 可以访问侦听数据的新值和旧值。 - watchEffect
会初始化执行一次,在副作用发生期间追踪依赖,自动分析出侦听数据源;watchEffect 无法访问侦听数据的新值和旧值。
简单一句话,watch 功能更加强大,而 watchEffect 在某些场景下更加简洁。
如何将template转换成render函数?
为什么转换的原因:我们在编写的时候不会直接编写虚拟DOM,我们可以直接使用模板编写,然后转换成render函数,我们调用render函数就可以生成对应的VDOM。
将template模板转化成ast语法树(逐词分析,词法分析、语法分析);对静态语法做静态标记。(这个过程为后续更新渲染可以直接跳过静态节点做优化)- 重新生成代码,将ast编译成
render字符串(增加with, new function),然后生成render函数。
vue3
vue3的模板转化,做了更多优化操作。vue2仅仅是标记了静态节点而已。
new vue()过程中发生了什么?(vue2)
Vue.observable过程中发生了什么?(vue2)
在非父子组件通信时,可以使用eventBus或者状态管理工具,但是功能不复杂的时候我们可以考虑使用vue.observable。(vue3不再使用)
v-if和v-for那个优先级更高?
- vue2中,先解析v-for在解析v-if
- vue3中,v-if的优先级高于v-for,原理是在外层添加一个template标签;
- 尽量同时避免使用,如果必须,使用计算属性转换一下。
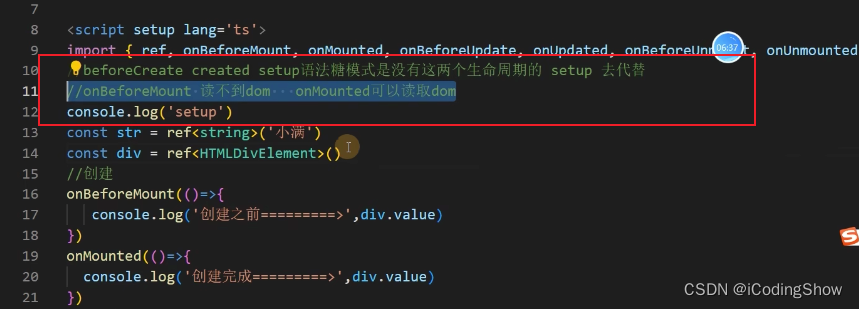
生命周期?
- setup 这个函数是在
beforeCreate和created之前运行的,所以你可以用它来代替这两个钩子函数。 - vue3的钩子函数基本是在vue2的基础上加上一个
on,但也有两个钩子函数发生了变化:BeforeDestroy变成了onBeforeUnmount,destroy变成了onUnmount。
vue中diff算法原理
vue基于虚拟DOM做更新。diff的核心就是比较两个虚拟节点的差异。vue的diff算法是平级比较,不考虑跨级比较的情况。内部采用深度递归的方式 + 双指针的方式进行比较。
diff比较的过程:
- 1、先比较是否是相同节点, 通过
key、tag来进行比较是否是相同节点 - 2、相同节点比较属性,并复用老节点(将老的虚拟dom复用给新的虚拟节点dom)
- 3、比较儿子节点,考虑老节点和新节点儿子的情况
- 老的没儿子,新的有,直接插入新的儿子
- 老的有儿子,新的没有,直接删除页面节点
- 老的儿子是文本,洗的呢儿子是文本,直接更新文本节点即可
老的儿子是一个列表,新的儿子也是一个列表,updateChildren方法
- 4、两个列表的比较的采用双指针比较:优化比较:头头、尾尾、头尾、尾头
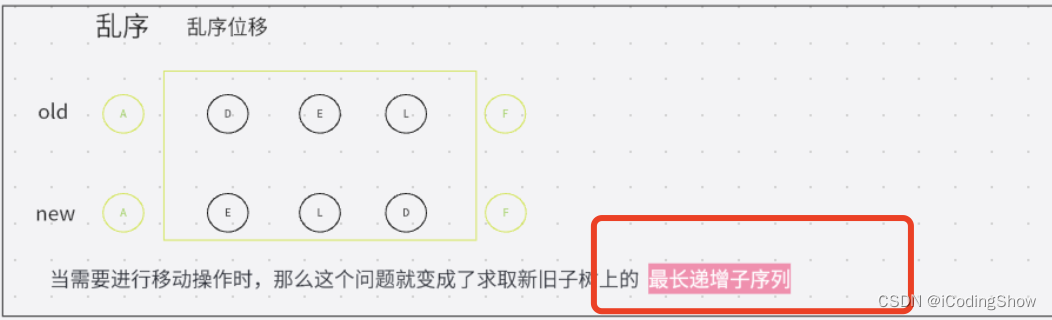
- 5、乱序的方案,最终方式:比对查找进行复用
vue3中采用
最长递增子序列来实现diff算法。
同级比较的时候采用首尾指针法
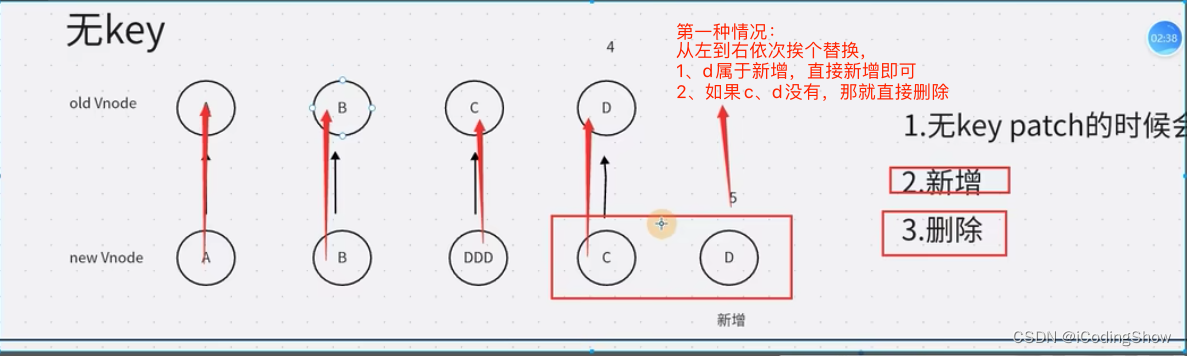
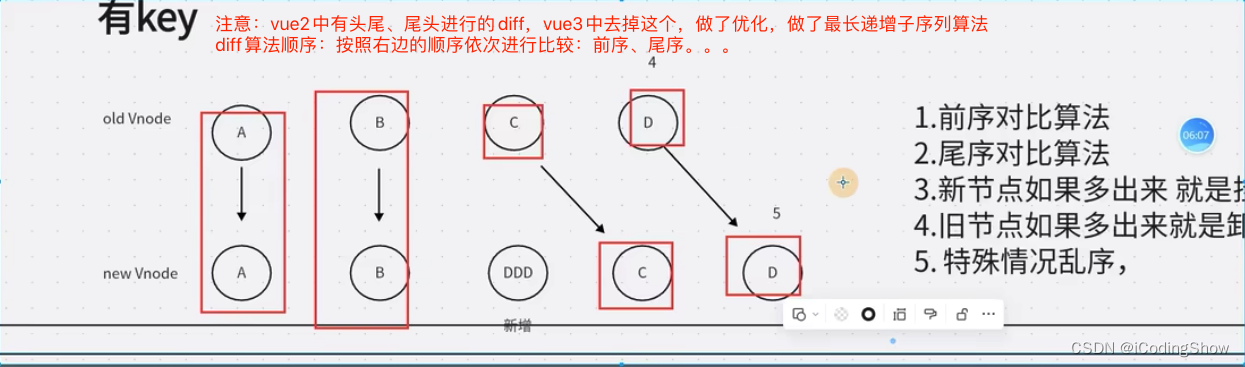
key的作用和原理
Vue.use是干什么的?
安装vue插件,如果插件是一个对象,必须提供install方法;如果插件是一个函数,它会被作为install方法,install方法调用时,会将vue作为参数传入,这样插件中就不在需要依赖vue了。
1、为什么在引入Vue-Router、Vuex、ElementUI的时候需要Vue.use()?而引入axios的时候,不需要Vue.use()?
本质就是:Vue-Router、Vuex、ElementUI三者都具有install方法,并且插件的运行依赖于install方法里的一些操作,才能正常运行,而axios没有install方法也能正常运行。
2、Vue.use方法主要做了如下的事:
- 检查插件是否安装,如果安装了就不再安装
- 如果没有没有安装,那么调用插件的install方法,并传入Vue实例
Vuex的响应式处理。
vuex通过Vue.use(Vuex)绑定vue实例上的,然后调用了install方法,通过applyMinxin(vue)在任意组件内执行this.$store就就可以访问到store对象。
如此,实现把store挂载到组件里面。vuex的state是响应式的,借助的就是vue的data。
Vue.extend 方法的作用?
vue中的构造器函数,可以创建一个子类,参数是一个包含组件选项的对象。
作用:
- 所有的组件创建的时候都会调用vue.extendf方法进行创建
- 有了这个方法我们可以用于手动挂载组件。(正常情况下,我们创建的组件都会挂载在根实例上,也就是app。创建组件的时候默认调用extend方法)
- 后端存储的字符串模板可以通过vue.extendf方法将其进行渲染,但是需要引入编译。
v-once的使用场景有哪些?
v-once是vue中的内置指令,只渲染元素和组件一次,之后的重新渲染会被视为静态内容而跳过,直接只用缓存。
vue中的mixin使用场景和原理
优点
- 提高代码复用性
- 无需传递状态
- 维护方便,只需要修改一个地方即可
缺点
- 命名冲突
- 滥用的话后期很难维护
- 不好追溯源,排查问题稍显麻烦
- 不能轻易的重复代码
vue中的slot如何实现的?
slot插槽设计来源于web components,利用slot进行占位,在使用组件时,组件标签内部会分发到对应的slot中。默认插槽、具名插槽,插槽就是方便用户定制化组件
作用:
弹框、表格
原理:
默认插槽:
具名插槽:
作用域插槽:
普通插槽就是替换,父组件渲染完之后,替换子组件的slot占位符;作用域插槽会把我们的父组件渲染成一个函数,子组件会调用这个函数,并且把数据传递给他,我们会拿到函数的返回值来替换slot占位符。
双向绑定原理
vue中双向绑定考的是指令v-model,可以绑定一个动态值到视图上,同时修改视图能改变数据对应的值(能修改的视图就是表单组件),经常会听到一句话:v-model是value + input的语法糖。
- 表单元素的v-model:内部会根据标签的不同解析出不同的语法
- 例如:文本框会被解析成value + input事件
- 例如:复选框会被解析成 checked + change事件
- 组件中的v-model:组件上的v-model默认会利用
名为value的prop和名为input的事件。对于组件而言,v-model就是value + input的语法糖。可用于组件中的数据的双向绑定。
备注:组件中如果有多个数据想做数据绑定,vue2不支持使用多个v-model的。vue3中可以通过一下方式进行绑定:<my v-model:a="a" v-model:b="b" />
vue中的.sync修饰符的作用
在有些情况下,我们可能需要对一个prop进行双向绑定,这时可以使用.sync来实现。v-model默认只能双向绑定一个属性,这里就可以通过.sync修饰符绑定多个属性。vue3已经废除这个。
异步组件的作用和原理
推荐的做法是将异步组件和webpack的code-splitting功能一起配合使用。
vue 如何优化首页的加载速度?vue 首页白屏是什么问题引起的?如何解决呢?
首页白屏的原因:
单页面应用的 html 是靠 js 生成,因为首屏需要加载很大的js文件(app.js vendor.js),所以当网速差的时候会产生一定程度的白屏
解决办法:
- 优化 webpack 减少模块打包体积,code-split 按需加载
- SSR服务端渲染,在服务端事先拼装好首页所需的 html
- 首页加 loading 或 骨架屏 (仅仅是优化体验)
- CDN资源还是很重要的,最好分开,也能减少一些不必要的资源损耗
- 利用webpack的code-split结合vue-router做懒加载
- 图片方面,像淘宝,会优先使用webp,如果不支持再用jpg,以及,小图采用base64编码,雪碧图等
- 代码压缩
webpack 打包 vue 速度太慢怎么办?
“打包慢”,是一个综合的因素,和vue关系不大。
- 确保下webpack,npm, node 及主要库版本要新,比如:4.x比3.x提升很多。
loader范围缩小到src项目文件!一些不必要的loader能关就关了吧- eslint代码校验其实是一个很费时间的一个步奏。
- 可以把eslint的范围缩小到src,且只检查*.js 和 *.vue
- 生产环境不开启lint,使用pre-commit或者husky在提交前校验
- 使用 alias 可以更快地找到对应文件。
- 如果在 require 模块时不写后缀名,默认 webpack 会尝试.js,.json 等后缀名匹配,配置
extensions,可以让 webpack 少做一点后缀匹配。 使用插件直接拷贝静态文件- cache-loader来进行缓存持久化
- 不同的devtool配置也会影响性能,最好配置为
‘eval’,或者‘cheap-module-eval-source-map’ - happypack多进程进行
如果上面优化后,时间还是不满意的话,就尝试下5,6吧。 - 动态链接库(DllPlugin),楼上已说。有点类似配置的externals。
补充一下:
缺点:将不能按需加载,会将配置的第三方库全部打包进去。
推荐:可以将使用率较高的包采用dll方案。 - HardSourceWebpackPlugin会将模块编译后进行缓存,第一次之后速度会明显提升。
谈谈你对spa的理解?
- 一个主页面和页面组件
- 局部刷新
- 速度快、用户体验好
- 维护成本:相对容易
- 首次渲染速度较慢(第一次返回空的html,需要再次请求首屏数据)白屏时间长。
怎么监听vuex数据的变化
- watch选项方式,可以以字符串形式监听
$store.state.xx(在vue文件中监听vuex的数据变化) - 调用store的watch实例方法,
store.watch,(在非vue文件中监听vuex数据的变更) - 在
Vue中监听Vuex数据的变化可以通过Vuex提供的subscribe方法来实现
揭秘vuex是如何给每个组件挂载$store的
vue中如何监听vuex中的数据变化
vue 监听vuex数据变化
VDOM如何生成的?
- 在vue中我们常常为组件编写模板:
template - 这个模板会变编译为渲染函数:render
- 在接下来的挂载过程中会调用render函数,返回的对象就是虚拟DOM
- 会在后续的patch过程中进一步转化为真实的DOM
nextTick的理解?
- vue中
视图更新是异步的,使用nextTick方法可以保证用户定义的逻辑在更新之后执行; - 可用于
获取更新后的DOM,多次调用nextTick会被合并。
document.getElementById('a').innerHTML
原理:
- 维护一个队列,按照顺序依次执行;nextTick的回调函数中有一个flush,先执行这个函数
总结:
keep-alive的用法和原理
概念:
keep-alive是vue中的内置组件,能在组件切换过程中将状态保留在内存中,防止重复渲染DOM。
使用场景:
- 动态组件
- 路由页面的渲染
属性和生命周期:
设置了 keep-alive 缓存的组件,会多出两个生命周期钩子(activated与deactivated);
属性:include、exclude、max
原理:
- 定义一个
this.cache, 是一个对象,用来存储需要缓存的组件。 - 如果
name不在inlcude中或者存在于exlude中则表示不缓存,直接返回vnode; - 获取组件的
key值,拿到key值后去this.cache对象中去寻找是否有该值,如果有则表示该组件有缓存,即命中缓存;直接从缓存中拿vnode的组件实例,此时重新调整该组件key的顺序,将其从原来的地方删掉并重新放在this.keys中最后一个。 - 如果没有命中缓存,则将其设置进缓存,则以该组件的
key为键,组件vnode为值,将其存入this.cache中,并且把key存入this.keys中; - 此时再判断
this.keys中缓存组件的数量是否超过了设置的最大缓存数量值this.max,如果超过了,则把第一个缓存组件删掉;
keep-alive数据更新问题:
- 每次组件渲染的时候,都会执行
beforeRouteEnter,重新获取数据; - 在keep-alive缓存的组件被激活的时候,都会执行
actived钩子,获取数据;
自定义指令的应用场景
- 图片懒加载v-lazy
- 防抖 v-debounce
- 按钮权限 v-has
这一节可以好好学学

mergeOptions && mixin && extend的关系
vue中的性能优化
- 数据层级不易过深,合理设置响应式数据
- 通过object.freeze方法冻结属性
- 使用数据时缓存值的结果,不频繁取值(for循环执行)
- 合理设置key属性
- v-show和v-if的选取
- 控制组件粒度-vue采用组件级更新
- 采用异步组件 => 借助webpack分包的能力
- 使用keep-alive缓存组件
- 分页、虚拟滚动、时间分片(将渲染分为不同时间进行处理)等策略。。。
40.单页应用首屏加载速度慢的怎么解决?

42、Vue 项目中有封装过 axios 吗?主要是封装哪方面的?
- 设置请求超时时间
-
- 根据项目环境设置请求路径
- 设置请求拦截,自动添加token
- 设置响应拦截,对响应的状态码或者数据进行格式化
- 增添请求队列,实现loading
43、vue 要做权限管理该怎么做?如果控制到按钮级别的权限怎么做?
44、Vue-Router 有几种钩子函数,具体是什么及执行流程是怎样的
45、Vue-Router 几种模式的区别?
3 种路由模式的说明如下:
hash: 使用 URL hash 值来作路由,支持所有浏览器,原理:hash + 通过监听hashChange事件,兼容性好,不够美观,hash服务端无法获取,不利于seo优化;history: 依赖 HTML5 History API 和服务器配置,原理:History API + 监听popState事件,美观,刷新会出现404;- abstract : 支持所有 JavaScript 运行环境,如 Node.js 服务器端。如果
发现没有浏览器的 API,路由会自动强制进入这个模式.
46.vue 项目本地开发完成后部署到服务器后报 404 是什么原因
history模式
vuex
你对 vuex 的个人理解
- Vuex中的store只有一份
如何监听 vuex 中数据的变化
- 1、通过watch监控vuex中状态变化;(待定)
- 2、通过store.subscribe监控状态变化;
页面刷新后 vuex 的数据丢失怎么解决?
- 每次获取数据前检测vuex数据是否存在,不存在则发请求重新拉取数据,存储到vuex中;
- 采用vuex持久化插件,将数据储存到localstorage;
mutation 和 action 的区别
有使用过 vuex 的 module 吗?在什么情况下会使用?
- 当应用变得复杂时,vuex允许将store分割成module,每个模块拥有自己的state、mutation、action、getter,甚至是嵌套子模块;
52.Vue3 中 CompositionAPI 的优势是?

- vue3中变成函数,不存在this的问题
- 构建工具自动tree-shaking
- 提取逻辑,是因为vue封装的函数,需要的直接引入过来
53.Vue3 有了解过吗?能说说跟 Vue2 的区别吗?

54.Vue 项目中的错误如何处理的?

55.Vue3 中模板编译优化
56.你知道那些Vue3新特性
数据通信
路由

vue-router导航守卫
双向绑定和 vuex 是否冲突
VueX规定了单向数据流,VueX的State放到v-model双向绑定报错,本来就是代码问题。和冲突么关系。而且VueX的双向绑定就是利用了new Vue实现的。为了单项数据流设置了Flag作为标记。不应该是VueX和双向绑定的冲突。是coder的问题。
Vue3必会——组合API ~三分钟带你了解组合API的魅力
vue3前置知识
vue3 + ts + vite + pinna + eletron
相关链接:Vue3 + vite + Ts + pinia + 实战 + 源码 +electron
5、(Vue核心虚拟Dom和 diff 算法)
6、(认识Ref全家桶)
ref的原理
7、认识Reactive全家桶
8、 toRef,toRefs,toRaw & 源码解析
toRef 只能修改响应式对象的值,非响应式视图无变化;
当结构reactive的时候,一定加上toRefs,可以让解构出来的内容带上响应式;
11、watchEffect
vue3
说说你使用 Vue 框架踩过最大的坑是什么?怎么解决的?
vue在用v-if v-else渲染两个相同的按钮,一个绑定了事件,另外一个没有绑定事件。当渲染状态切换的时候,会导致未绑定事件的按钮也绑定上了事件。原因是有的vue版本在没给条件渲染的元素加上key标识时候会默认复用元素提升渲染能力,导致事件被错误的绑定上另一个按钮。解决方案:更换高版本vue,加上key标识两个按钮。
------------------------------分割线-----------------------------------
介绍模块化发展历程
React
react hooks
hooks是针对在使用react时存在以下问题而产生的:
组件之间复用状态逻辑很难,在hooks之前,实现组件复用,一般采用高阶组件;- 复杂的class组件,使用class组件,需要理解 JavaScript 中
this的工作方式,不能忘记绑定事件处理器等操作,代码复杂且冗余。
react hooks之后:
- Hooks 出现之后,我们将
复用逻辑提取到组件顶层,而不是强行提升到父组件中。 避免上面陈述的class组件带来的那些问题;
vue和react虚拟DOM的区别
1、vue3新增变化
diff算法变化
vue3的diff算法没有vue2的头尾、尾头之间的diff,对diff算法进行了优化,最长递归子序列。
ref VS reactive
- ref 支持所有的类型,reactive 支持引用类型,array object Map Set
- ref取值、赋值,都需要加.value,reactive是不需要.value
- reactive不能直接给数组赋值,因为proxy实现的,不能直接赋值,否则破坏响应式对象的
- 解决方案:数组,可以使用push + 解构,第二种方式:添加一个对象,把数组作为一个属性去解决
声明周期
链接:
vue3变化:(待定)
1、组合式API、setup 语法糖
优点:
-
逻辑复用:组合式 API 提供了更灵活的逻辑复用方式。
-
模块化组织:组合式 API 将组件逻辑拆分为可组合的函数,而不再依赖于生命周期钩子函数。这种模块化组织方式使得代码更具可读性和可维护性,同时提供了更好的代码组织结构,使开发者能够更容易地理解和管理组件。
-
更自由的 JavaScript 编程:组合式 API 使用普通的 JavaScript 函数来定义组件的逻辑,不再受限于特定的 Vue 实例上下文。这使得开发者能够更自由地使用传统的 JavaScript 工具和模式,例如条件语句、循环和函数调用,从而提高了开发的灵活性和可维护性。
-
代码组织和可维护性:通过组合式 API,可以更好地组织和封装组件的逻辑。逻辑相关的代码可以放在同一个函数中,使得代码结构更清晰,易于维护和理解。这种方式也有助于减少代码冗余,提高代码复用性和可测试性。
-
- Vue2中对逻辑复用都是放在mxins里,而组合式API解决了mixins的所有缺陷(命名冲突:组合式API里可以把引进来的进行重命名as)

- Vue2中对逻辑复用都是放在mxins里,而组合式API解决了mixins的所有缺陷(命名冲突:组合式API里可以把引进来的进行重命名as)
缺点
- 学习曲线:相对于响应式 API,组合式 API 的学习曲线可能会更陡峭一些。
- 破坏组件的封装性:组合式 API 提倡将逻辑聚合在一起,这意味着在多个组合函数之间共享逻辑时,逻辑可能会变得分散。
- 灵活性带来的挑战:组合式 API 提供了更大的灵活性,这可能导致代码结构不一致,使得代码更难以理解和维护。
2、ref和reactive

ref会对基本数据进行包装,把一个基本类型变成一个对象类型。
3、生命周期(移除了beforeCreate和created)
4、watch和computed原理(computed 是怎么收集依赖的?)待定
5、重写了虚拟Dom实现
6、双向绑定底层原理的调整
patch过程(待定)
面试官:Vue3.0 所采用的 Composition Api 与 Vue2.x 使用的 Options Api 有什么不同?
vue2中的mixin缺点:命名冲突、数据来源不清晰
- 在
逻辑组织和逻辑复用方面,Composition API是优于Options API(vue3向下兼容,可以使用两种) - 因为Composition API几乎是函数,
会有更好的类型推断。 - Composition API对
tree-shaking友好,代码也更容易压缩 - Composition API中见不到
this的使用,减少了this指向不明的情况 - 如果是小型组件,可以继续使用Options API,也是十分友好的
面试官:Vue3.0的设计目标是什么?做了哪些优化
vue2的问题:代码可读性随着组件变大而变差、每一种代码复用的方式都存在缺点、ts支持度较差
- 更小:Vue3移除一些不常用的 API,引入tree-shaking
- 更快,编译方面,见下面
优化方案:
- 源码。1、vue3整个源码是通过 monorepo的方式维护的;一些 package是可以独立于 Vue 使用的,
可以单独依赖这个响应式库而不用去依赖整个 Vue;2、Vue3是基于typeScript编写的,提供了更好的类型检查,能支持复杂的类型推导 - 性能。
体积优化、编译优化、数据劫持优化
面试官:Vue3.0性能提升主要是通过哪几方面体现的?
- 一、编译阶段
diff算法优化;vue3在diff算法中相比vue2增加了静态标记,其作用是为了会发生变化的地方添加一个flag标记,下次发生变化的时候直接找该地方进行比较;静态提升;Vue3中对不参与更新的元素,会做静态提升,只会被创建一次,在渲染时直接复用;事件监听缓存。默认情况下绑定事件行为会被视为动态绑定,所以每次都会去追踪它的变化。SSR优化;当静态内容大到一定量级时候,会用createStaticVNode方法在客户端去生成一个static node,这些静态node,会被直接innerHtml,就不需要创建对象,然后根据对象渲染;
- 二、源码体积
- 相比Vue2,Vue3整体体积变小了,除了移出一些不常用的API,再重要的是
Tree shanking
- 相比Vue2,Vue3整体体积变小了,除了移出一些不常用的API,再重要的是
- 三、响应式系统
vue2中采用 defineProperty来劫持整个对象,然后进行深度遍历所有属性,给每个属性添加getter和setter,实现响应式;vue3采用proxy重写了响应式系统,因为proxy可以对整个对象进行监听,所以不需要深度遍历
面试官:说说Vue 3.0中Treeshaking特性?举例说明一下?
在Vue2中,无论我们使用什么功能,它们最终都会出现在生产代码中。主要原因是Vue实例在项目中是单例的,捆绑程序无法检测到该对象的哪些属性在代码中被使用到;
而Vue3源码引入tree shaking特性,将全局 API 进行分块。如果您不使用其某些功能,它们将不会包含在您的基础包中
import { nextTick, observable } from 'vue'
nextTick(() => {})
如何做的
Tree shaking是基于ES6模板语法(import与exports),主要是借助ES6模块的静态编译思想,在编译时就能确定模块的依赖关系,以及输入和输出的变量
Tree shaking无非就是做了两件事:
编译阶段利用ES6 Module判断哪些模块已经加载判断那些模块和变量未被使用或者引用,进而删除对应代码
================ 分割线 ====================
介绍模块化发展历程
webpack
0、webpack核心工作原理(打包流程是怎么样)
Webpack的基本功能有哪些:代码转换、文件优化、代码分割、模块合并、自动刷新、代码校验。
有五大核心概念:入口(entry)、输出(output)、解析器(loader)、插件(plugin)、模式(mode)。
流程:
Webpack会读取项目根目录下的Webpack配置文件,解析其中的配置项,并根据配置项构建打包流程。
在前端项目中,会存在js、css、png、scss、html等文件,webpack首先会确定一个打包的入口,然后顺着我们入口文件的代码,根据代码中出现的import语句来解析推断出所依赖的资源模块,然后去解析每一个模块对应的依赖,最后生成了项目中用到文件的一个依赖关系的依赖树。确定这个依赖树之后,webpack会递归这个依赖树,找到每个节点对应的资源文件,然后在根据我们配置文件的rule属性找到这个模块的加载器去加载这个模块,(Webpack会在打包流程中执行一系列插件,插件可以用于完成各种任务,例如生成HTML文件、压缩代码等等。),最后会把加载的结果放到bundle.js中,从而实现整个项目的打包。
1、说说webpack中常见的Loader?解决了什么问题?
在webpack内部中,webpack只支持对js 和json文件打包,像css、sass、png等这些类型的文件的时候,webpack则无能为力,这时候就需要配置对应的loader进行文件内容的解析;
常见的loader(加载器)如下:
webpack中的大致可以分为三类:编译转换类、文件操作类、代码检查类;
- style-loader:
将css添加到style标签里,存在于head标签中; - css-loader :编译转换类,
目的就是将css文件转化为js模块。允许将css文件通过require的方式引入,并返回css代码(注意:css-loader只是负责将.css文件进行一个解析,而并不会将解析后的css插入到页面中,需要用到style-loader) - less-loader、sass-loader: 处理less、sass
- ts-loader: 将TypeScript转换成JavaScript
- postcss-loader: 用postcss来处理CSS, 处理CSS3属性前缀
file-loader:文件操作类,文件资源加载器, 分发文件到output目录并返回相对路径,过程:webpack遇到图片文件,根据配置文件中的的配置,匹配到对应的文件加载器,先将文件拷贝到输出目录,然后在导出输出目录的路径作为当前模块的返回值进行返回;url-loader: 和file-loader类似,区别是用户可以设置一个阈值,大于阈值会交给 file-loader 处理,小于阈值时返回文件 base64 形式编码 (处理图片和字体)。适合场景:项目中的小文件、小图片使用url-loader,减少请求次数。此外,大文件单独提取存放,提高加载速度;- babel-loader :
用babel来转换ES6文件到ES5;babel是基于插件机制去实现的,它仅仅就是个平台,它的核心机制不会转化代码,具体转化代码是通过插件来实现。@babel/preset-env是一个插件的集合,这是转化的核心,其实也不是preset-env转化的,具体的是@babel/plugin-transform-module-commonjs实现的,此外,在创建.babelrc文件存放"presets": ["@babel/preset-env"]; - html-minify-loader: 压缩HTML
- image-loader:加载并且压缩图⽚⽂件
eslint-loader:运行ESLint检查的loader;
重点:开发一个loader
loader本质是一个函数,接受源代码作为参数,返回处理后的结果。举个最简单的例子:开发一个markdownloader,希望导出的是转化后的html文件。
const marked = require('marked'); // markdown解析的模块
module.exports = source => {
// return 'console.log("hello~")'; // 返回的是一个JavaScript代码
const html = marked(source); // 解析
return `module.exports = ${JSON.stringify(html)}`;
// 第二种方式
}
webpack加载资源的过程有点像工作管道,在这个过程中使用多个loader,但是经过管道处理的结果一定是一段JavaScript代码。
通过以上:我们知道loader内部工作原理就是负责资源文件从输入到输出的转换,是一种管道的概念,将此次处理的结果交给下一个loader,完成一个功能。
使用:在rules中进行配置,当检测到markdown文件时,执行上面的loader。
2、说说Loader和Plugin的区别?编写Loader,Plugin的思路?
loader专注于资源模块的加载,从而实现整个项目的打包;Loader 本质就是一个函数,在该函数中对接收到的内容进行转换,返回转换后的结果。因为 Webpack 只认识 JavaScript,所以 Loader 就成了翻译官,对其他类型的资源进行转译的预处理工作。
插件是解决项目除了资源加载以外的其他自动化的工作!基于事件流框架 Tapable
说说webpack中常见的Plugin?解决了什么问题?
plugin赋予其各种灵活的功能,例如打包优化、资源管理、环境变量注入等,它们会运行在 webpack 的不同阶段(钩子 / 生命周期),贯穿了webpack整个编译周期;
常见的Plugin如下:
clean-webpack-plugin,打包之前先清理dist目录下的文件,如果不清理,则之前打包的会一直存在;html-webpack-plugin,自动引入打包结果bundle.js的html文件;copy-webpack-plugin,复制文件或目录到执行区域,如我们将一些文件放到public的目录下,那么这个目录会被复制到dist文件夹中;mini-css-extract-plugin,提取CSS到一个单独的文件中DefinePlugin,允许在编译时创建配置的全局对象,定义全局常量,可以在代码中直接使用;webpack-bundle-analyzer: 可视化 Webpack 输出文件的体积
webpack开发一个插件
webpack的插件机制通过钩子机制实现:它类似于事件,webpack在工作过程中有很多的环节,为了插件的扩展,webpack几乎在每一个环节都埋下了一个的钩子,这样我们在开发插件的时候,通过在不同的节点上挂载不同的任务,就可以轻松的扩展webpack的能力。
注意📢:webpack要求我们的插件必须是一个函数或者是已给包含apply方法的对象。
// 开发一个插件,清除webpack打包生成的bundle文件的不必要的注释;
// 首先明确这个任务的执行时机,依据开发的插件可以在明确生成bundle文件内容之后实施响应的任务
// 在webpack文档中找到一个emit钩子,发现emit这个钩子是在webpack即将往输出目录输出文件的时候执行;
// 定义
class myPlugin {
// compiler是webpack的核心对象,包含webpack此次构建的所有信息,也是通过这个对象构造钩子函数
apply(compiler) {
// console.log('myPlugin 启动,这个方法会在webpack启动时自动调用');
// tap传递两个参数,插件名称,挂载在钩子的函数
compiler.hooks.emit.tap('myPlugin', compilation => {
// compilation => 可以理解为此次打包的上下文,此次打包的所有结果都会放到这个对象中
for(const name in compilation.assets) {
// console.log(name)
// 只对打包的js结尾的文件处理
if(name.endsWith('.js')) {
// 1、先获取文件内容
const contents = compilation.asserts[name].source();
// 2、接下来用正则替换文件中的注释:找到注释/**/替换''
// 3、替换完的结果替换原来文件中的内容
}
}
})
}
}
// 执行, 在plugin配置中
new myPlugin()
附加:Webpack常见的事件
emit,在Webpack生成输出文件之前触发,可以用于修改输出文件或生成一些附加文件。done: 在Webpack完成构建时触发,可以用于生成构建报告或通知开发者构建结果。compilation: 在Webpack编译代码期间触发,可以用于监听编译过程或处理编译错误。
其他:
Webpack的事件机制是基于Tapable实现的,它的工作流程就是将各个插件串联起来,而实现这一切的核心就是Tapable。Tapable是Webpack事件机制的核心类,它封装了事件的订阅和发布机制。在Webpack中,Compiler对象和Compilation对象都是Tapable类的实例对象。
Tapable的源码解读:记住重点,核心就是call和tap两个方法。
webpack它工作流程能将各个插件plugin串联起来的原因,而实现这一切的核心就是Tapable。流程:
- 在初始化webpack的配置过程中,会循环我们配置的以及webpack默认的所有插件也就是
plugin。 - 这个过程,会把
plugin中所有tap事件收集到每个生命周期的hook中。 (可以看到每次调用tap,就是收集当前hook实例所有订阅的事件到taps数组。) - 最后根据每个hook执行
call方法的顺序(也就是生命周期)。就可以把所有plugin执行了。
Webpack插件机制之Tapable-源码解析
3、实际开发体验
1、watch工作模式(略)
监听文件变化,自动重新打包。 npm webpack --watch
2、自动刷新浏览器(略)
browerSync
3、Dev Server
wepack推出的一个工具,集成了【自动编译】和【自动刷新浏览器】等功能。
devServer: {
}
webpack Dev Server支持配置代理,用于本地代理跨域。
4、Source Map
运行代码和源代码完全不同,源代码地图,提供一个运行代码和源代码之间的映射,帮助开发者调试和定位错误。
webpack配置source map
配置开发过程中的辅助工具,就是与source map相关的一些配置
devtool: 'source-map',
找到bundle打包的文件,发现在文件最后一行显示,通过注释的形式引入了source-map文件
//# sourceMappingURL=app.927d40ffb38db55716fd.js.map
webpack eval模式的source map
eval会执行字符串函数
5、自动刷新的问题 && HMR(模块热替换)
问题核心:自动刷新导致的页面状态丢失。
目的:页面不刷新的前提下,模块也可以及时更新。
HMR是webpack中最强大的功能之一。
开启HMR
devServer: {
hot: true
}
plugins: [
new webpack.HotModuleReplacementPlugin()
]
webpack中的HMR并不是开箱即用。
Q1:为什么样式文件的热更新开箱即用?
因为样式是loader处理的,在style-loader中自动处理了样式的热更新。
Q2:我的项目手动处理js文件,照样可以热更新。
框架中提供了HMR方案。
6、生产环境优化
不同环境下的配置
- 配置文件根据环境不同导出不同配置
- 一个环境对应一个配置文件
webpack-merge合并公共配置和私有配置。
DefinePlugin
为代码注入全局成员。往我们代码中注入一个process.env.NODE_ENV的常量,很多第三方的模块根据这个常量判断是否做一些操作。
plugins: [
// 接受一个对象,对象里面的键值会注入到我们的代码当中
new webpack.DefinePlugin({
'process.env': env
API_BASE_URL: '"http://baidu.com"' // 传入一个字符串
// API_BASE_URL: JSON.stringify('http://baidu.com') // 使用这种方式
}),
]
在我们代码中执行
console.log(API_BASE_URL);
在bundle.js中显示替换之后的值:console.log(http://baidu.com),不带引号
tree Shaking
tree shaking不是指某个配置选型,它是一组功能搭配使用后的优化效果。在生产模式自动开启。
原理:Tree-shaking依赖于ES6的模块机制,因为ES6模块是静态的,编译时就能确定模块的依赖关系。对于非ES6模块的代码或者动态引入的代码,无法被消除掉。
由于 tree shaking 只支持 esmodule ,如果你打包出来的是 commonjs,此时 tree-shaking 就失效了。不过当前大家都用的是 vue,react 等框架,他们都是用 babel-loader 编译,以下配置就能够保证他一定是 esmodule。
// optimization集中配置webpack优化的功能
optimization: {
usedExports: true, // 表示只导出外部使用的成员
minimize: true // 移除
}
usedExports相当于【负责标记‘枯树叶’】,minimize负责【摇掉】他们。
合并模块函数 concatenateModules, 又被成为Scope Hoisting,作用域提升,合并代码模块,尽可能的将所有模块合并输出到一个函数中,既提升了运行效率,又减小了代码的体积。
optimization: {
usedExports: true,
minimize: true,
concatenateModules: true
}
Code Splitting(代码分割)
背景:
- 项目复杂的话,导致bundle体积过大
- 并不是每个模块在启动时都是必要的
所以把打包结果分离到不同的bundle上,``按需加载`,太大也不行,太小也不行,物极必反
至于如何拆分,方式因人而异,因项目而异。我个人的拆分原则是:
业务代码和第三方库分离打包,实现代码分割;- 业务代码中的
公共业务模块提取打包到一个模块; - 第三方库最好也不要全部打包到一个文件中,因为第三方库加起来通常会很大,我会
把一些特别大的库分别独立打包,剩下的加起来如果还很大,就把它按照一定大小切割成若干模块。
两种代码分割的方式
多入口打包动态导入
多入口打包的问题
多入口打包,往往会有公共的模块,这里我们需要提取公共模块 split chunks。
optimization: {
splitChunks: {
chunks: 'all' // 表示会把所有的公共模块都提取到单独的模块当中
}
}
动态导入(dynamic imports)
webpack使用动态导入的模式来实现模块的按需加载。动态导入的模块会被自动分包。
MiniCssExtractPlugin
将css从打包结果中提取出来,从而实现css的按需加载。
plugins: [
new MiniCssExtractPlugin()
]
style-loader的目的是将样式通过style标签注入,此时需要MiniCssExtractPlugin.loader替换style-loader,将css文件单独提取成一个文件,使用link来引入。
注意📢:如果css太小,不建议提取,大于150KB建议提取。
OptimizeCssAssetsWebpackPlugin 压缩输出的CSS文件
webpack仅支持对js的压缩,其他文件的压缩需要使用插件。
可以使用 optimize-css-assets-webpack-plugin压缩CSS代码。放到minimizer中,在生产模式下就会自动压缩。
optimization: {
minimizer: [
// 指定了minimizer说明要自定义压缩器,所以要把JS的压缩器指明,否则无法压缩
// 如果没有new TerseWebpackPlugin(),则webpack默认为要用自定义压缩器,覆盖内部的压缩器
new TerseWebpackPlugin(),
new OptimizeCssAssetWebpackPlugin()
]
}
7、输出文件名 hash
生产模式下,文件名使用Hash
文件级别的hash,:8是指定hash长度 (推荐)
output: {
filename: '[name]-[contenthash:8].bundle.js'
},
常见面试题
说说webpack proxy工作原理?为什么能解决跨域?
webpack proxy,即webpack提供的代理服务,基本行为就是接收客户端发送的请求后转发给其他服务器,其目的是为了便于开发者在开发模式下解决跨域问题(浏览器安全策略限制),想要实现代理首先需要一个中间服务器,webpack中提供服务器的工具为webpack-dev-server;
工作原理: proxy工作原理实质上是利用http-proxy-middleware 这个http代理中间件,实现请求转发给其他服务器;
如何提高webpack的构建速度?
从基础到实战 手摸手带你掌握新版Webpack4.0详解 一起读文档
以下面试题参考
Webpack 的热更新原理
Webpack 的热更新又称热替换(Hot Module Replacement),缩写为 HMR。 这个机制可以做到不用刷新浏览器而将新变更的模块替换掉旧的模块。
- 通过
webpack-dev-server创建两个服务器- 使用
express框架启动本地server,负责直接提供静态资源的服务(打包后的资源直接被浏览器请求和解析); - 本地
server启动之后,再去启动websocket服务,通过websocket,可以建立本地服务和浏览器的双向通信;
- 使用
- 在启动本地服务前又做了不少事:在
entry入口默默增加了 2 个文件,那就意味会一同打包到bundle文件中去,也就是线上运行时。webpack-dev-server/client/index.js,一个是获取websocket客户端代码;webpack/hot/dev-server.js,这个文件主要是用于检查更新逻辑的;
- 当监听到一次
webpack编译结束,就会调用_sendStats方法通过websocket给浏览器发送通知,ok和hash事件,这样浏览器就可以拿到最新的hash值了,做检查更新逻辑。 - 当监听到一次
webpack编译结束,_sendStats方法就通过websoket给浏览器发送通知,检查下是否需要热更新。被打包进bundle.js中webpack-dev-server/client/index.js文件,运行在浏览器中,socket方法建立了websocket和服务端的连接,并注册了 2 个监听事件。hash事件,更新最新一次打包后的hash值。ok事件,进行热更新检查。
- 打包进的另一个文件
webpack/hot/dev-server.js,运行在浏览器中。核心逻辑:这里webpack监听到了webpackHotUpdate事件,并获取最新了最新的hash值,然后终于进行检查更新了。- 检查更新调用的是
module.hot.check方法。module.hot.check又是哪里冒出来了的!答案是HotModuleReplacementPlugin搞得鬼。HotModuleReplacementPlugin原来也是默默的塞了很多代码到bundle.js中呀。这和第 2 步骤很是相似哦!为什么,因为检查更新是在浏览器中操作呀。这些代码必须在运行时的环境。
- 检查更新调用的是
- 通过上一步,我们就可以知道
moudle.hot.check方法是如何来的啦。那都做了什么?之后的源码都是HotModuleReplacementPlugin塞入到bundle.js中的哦- 利用上一次保存的hash值,调用hotDownloadManifest发送
xxx/hash.hot-update.json的ajax请求; - 请求结果获取热更新模块,以及下次热更新的Hash 标识,并进入热更新准备阶段。
- 调用hotDownloadUpdateChunk发送
xxx/hash.hot-update.js请求,通过JSONP方式。
- 利用上一次保存的hash值,调用hotDownloadManifest发送
- 热更新的核心逻辑就在
hotApply方法了- 删除过期的模块,就是需要替换的模块
- 将新的模块添加到
modules中 - 通过
__webpack_require__执行相关模块的代码
细节点:
- 为什么代码的改动保存会自动编译,重新打包?这一系列的重新检测编译就归功于
compiler.watch这个方法了。监听本地文件的变化主要是通过文件的生成时间是否有变化,这里就不细讲了。 - 执行setFs方法,这个方法主要目的就是
将编译后的文件打包到内存。这就是为什么在开发的过程中,你会发现dist目录没有打包后的代码,因为都在内存中。原因就在于访问内存中的代码比访问文件系统中的文件更快,而且也减少了代码写入文件的开销,这一切都归功于memory-fs。 - 因为这里要解释下为什么使用
JSONP获取最新代码?主要是因为JSONP获取的代码可以直接执行。为什么要直接执行?我们来回忆下/hash.hot-update.js的代码格式是怎么样的。可以发现,新编译后的代码是在一个webpackHotUpdate函数体内部的。也就是要立即执行webpackHotUpdate这个方法。
Webpack怎么优化开发环境?(粗略)
- 配置合适的SourceMap策略;
- 使用缓存
- 使用 DllPlugin:DllPlugin 是 Webpack 的一个插件,它可以将一些不经常变动的第三方库预先打包好,然后在开发过程中直接使用。
- 多线程并行打包
如何⽤webpack来优化前端性能,优化打包结果?
优化打包结果的核心目标就是让打出来的包体积更小,让打包的最终结果在浏览器运⾏快速⾼效。
打包体积分析:一般脚手架里直接运行命令行就能生成打包体积图,然后可以根据包体积能定向优化。缩小打包作用域:exclude/include (确定 loader 规则范围)等压缩代码:CSS、JS代码压缩,删除多余的代码、注释。模块懒加载:可以使用Webpack的动态导入功能,使用模块懒加载之后,大js文件会分成多个小js文件,网页加载时会按需加载。利⽤CDN加速: 在构建过程中,将引⽤的静态资源路径修改为CDN上对应的路径。开启Tree Shaking: 将代码中永远不会⾛到的⽚段删除掉。- Code Splitting: 将代码按路由维度或者组件分块(chunk),这样做到按需加载,同时可以充分利⽤浏览器缓存
提取公共代码: SplitChunks抽取公共模块,可以浏览器⻓期缓存这些⽆需频繁变动的公共代码。分离第三方库:将第三方库从应用程序代码中分离出来,单独打包,这样可以提高缓存效率并减小应用程序代码的大小。
Babel原理
- 解析:将代码转换成 AST
- 转换:访问 AST 的节点进行变换操作生产新的 AST(Taro就是利用 babel 完成的小程序语法转换)
- 生成:以新的 AST 为基础生成代码
webpack5新特性
1、模块联邦
实现微前端的一种方式,模块联邦是webpack5引入的特性,能轻易实现在两个使用 webpack 构建的项目之间共享代码,甚至组合不同的应用为一个应用。
模块联邦是实现多个项目之间共享代码的机制。举个例子,假设我们有一个微前端应用,其中包含了一个商品管理应用和一个订单管理应用,这两个应用都需要使用到同一个UI组件库。
为了避免重复的代码,我们可以将UI组件库拆分成一个独立的子应用作为模块提供方,然后通过模块联邦的方式在商品管理应用和订单管理应用中动态加载该组件库。
2、压缩代码
webpack4 上需要下载安装 terser-webpack-plugin 插件;webpack5内部本身就自带 js 压缩功能,他内置了 terser-webpack-plugin 插件,我们不用再下载安装。而且在 mode=“production” 的时候会自动开启 js 压缩功能。
3、webpack 缓存
webpack5 内部内置了 cache 缓存机制,使用持久化缓存。直接配置即可。
4、对loader的优化
asset/resource 替换 file-loader(发送单独文件)
asset/inline 替换url-loader(导出 url)
5、Tree Shaking优化
Webpack5进一步改进了Tree Shaking算法,可以更准确地判断哪些代码是无用的,从而更好地优化构建输出的文件大小。webpack5的 mode=“production” 自动开启 tree-shaking。
6、更快的构建速度
Webpack5在构建速度方面进行了大量优化,尤其是在开发模式下,构建速度有了明显提升。
vite
1、为什么说 vite 比 webpack 要快
启动方面,webpack启动的时候会将所有的文件进行编译打包,vite启动的时候不需要打包,当浏览器启动模块的时候,再对模块内容进行编译,按需编译,根据esModules会自动向依赖的module发送请求,按需动态编译;热更新方面,Vite是按需加载,webpack是全部加载。当改动了一个模块后,vite 仅需让浏览器重新请求该模块即可,不像 webpack 那样需要把该模块的相关依赖模块全部编译一次,效率更高;底层原理方面,vite 是基于了esbuild预构建的,更快(esbuild 使用 Go 编写,并且比以 JavaScript 编写的打包器(webpack)预构建依赖快 10-100 倍,js的操作一般是毫秒级,go的操作是纳秒级)
在浏览器支持 ES 模块之前,JavaScript 并没有提供原生机制让开发者以模块化的方式进行开发。这也正是我们对 “打包” 这个概念熟悉的原因:使用工具抓取、处理并
将我们的源码模块串联成可以在浏览器中运行的文件。诸如 webpack、Rollup 和 Parcel 等工具应运而生。
Vite 旨在利用生态系统中的新进展解决上述问题:
浏览器开始原生支持 ES 模块,且越来越多 JavaScript 工具使用编译型语言编写。
2、vite 对比 webpack ,优缺点在哪?
优点:
- 更快的热更新
- 更快的冷启动
缺点:
webpack支持的更广。Vite 是基于ES Module,所以代码中不可以使用CommonJs;开发环境下懒加载变慢:由于unbundle 机制,动态加载的文件,需要做 resolve 、 load 、 transform 、 parse 操作,并且还有大量的 http 请求,导致懒加载性能也受到影响。开发环境下首屏加载变慢:由于 unbundle 机制, Vite 首屏期间需要额外做其它工作。不过首屏性能差只发生在 dev server 启动以后第一次加载页面时发生。之后再 reload 页面时,首屏性能会好很多。原因是 dev server 会将之前已经完成转换的内容缓存起来
3、Vite是否支持 commonjs 写法?
纯业务代码,一般建议采用ESM写法。
如果引入的三方组件或者三方库采用了CJS写法,vite 在预构建的时候就会将CJS模块转化为ESM模块。
如果非要在业务代码中采用CJS模块,那么我们可以提供一个 vite 插件,定义 load hook,在 hook 内部识别是 CJS 模块还是 ESM 模块。如果是 CJS 模块,利用 esbuild 的 transfrom 功能,将 CJS 模块转化为 ESM 模块。
4、线上打包
- 当需要打包到生产环境时,
vite使用传统的rollup进行打包,因此,vite的主要优势在开发阶段。另外,由于vite利用的是ES Module,因此在代码中不可以使用CommonJS。 esbuild用在开发环境,解析依赖,编译不同格式文件成可执行esm的js,rollup用于生产环境,也需要解析编译,但是产物是兼容性更好的原生js;
5、线上打包,Vite为什么不用Webpack?Rollup和webpack的区别
Rollup使用新的ESM,而Webpack用的是旧的CommonJS。Rollup支持相对路径,webpack需要使用path模块。Rollup使用起来更简洁,并且Rollup打出更小体积的文件,所以Rollup更适合Vite。
6、Vite生产环境用了Rollup,那能在生产环境中直接使用 esm 吗?
生产环境使用rollup打包可能会造成开发环境与生产环境的不一致。因为打包方式不一样,生产的打包方式是rollup 打包,开发打包是直接把转化后的 es module 的JavaScript,扔给浏览器,让浏览器根据依赖关系,自己去加载依赖。
- 如果你的项目不需要兼容
IE11等低版本的浏览器,自然是可以使用的。 - 但是更通用的方案可能还是提前构建好
bundle.js与es module两个版本的代码,根据浏览器的实际兼容性去动态选择导入哪个模块。
杂项
resolve.alias配置通过别名来将原导⼊路径映射成⼀个新的导⼊路径。resolve.extensions在导⼊语句没带⽂件后缀时,webpack会⾃动带上后缀后,去尝试查找⽂件是否存在。
参考链接:
前端面试:Webpack高频面试题「2023」
「吐血整理」再来一打Webpack面试题
17项关于webpack的性能优化
webpack优化之玩转代码分割和公共代码提取
浅谈 webpack 性能优化(内附巨详细 webpack 学习笔记)
Babel之babel-polyfill、babel-runtime、transform-runtime详解
如果我们没有配置一些规则,Babel 默认只转换新的 JavaScript 句法(syntax),而不转换新的 API,比如 Iterator、Generator、Set、Maps、Proxy、Reflect、Symbol、Promise 等全局对象,以及一些定义在全局对象上的方法(比如 Object.assign )都不会转码。
-
当运行环境中并没有实现的一些方法,babel-polyfill 会给其做兼容。 但是这样做也有一个缺点,就是会污染全局变量,而且项目打包以后体积会增大很多,因为把整个依赖包也搭了进去。所以并不推荐在一些方法类库中去使用。 -
为了不污染全局对象和内置的对象原型,但是又想体验使用新鲜语法的快感。就可以配合使用babel-runtime和babel-plugin-transform-runtime。 比如当前运行环境不支持promise,可以通过引入babel-runtime/core-js/promise来获取promise, 或者通过babel-plugin-transform-runtime自动重写你的promise。
-
babel-runtime
不能转码实例方法,比如这样的代码:'hello'.includes('h');,这只能通过 babel-polyfill 来转码,因为 babel-polyfill 是直接在原型链上增加方法。 -
babel-runtime和 babel-plugin-transform-runtime的区别是,相当一
前者是手动挡而后者是自动挡,每当要转译一个api时都要手动加上require(‘babel-runtime’) -
随着历史进程的发展,新一代的
babel-prenset-env很强大,了解一下?
对babel-transform-runtime,babel-polyfill的一些理解
babel-polyfill VS babel-runtime
pinia
- 更贴合 Vue 3 的 Composition API 风格,学习成本更低
- 不需要区分 Mutation 和 Action,统一使用 Actions 操作状态
- 支持 TypeScript,可以充分利用 TS 的静态类型系统
- 模块化管理 States,每个模块是一个 Store
- 直观的 Devtools,可以看到每个 State 的变化
Pinia 的核心原理是什么?
Pinia 的核心原理是将应用的状态分解为多个独立的 store,并通过 provide / inject 机制来将它们注入到 Vue 组件中。每个 store 由一个名为 defineStore 的工厂函数创建,它接收一个名为 id 的参数,用于标识该 store,以及一个名为 state 的对象,用于定义该 store 的状态。在组件中,我们可以使用 $store 访问这些 store,并通过 computed 属性来监听它们的变化。














 3070
3070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









