







MemFire Cloud 中现在提供了一个新的 PostgreSQL 扩展:pgvector,一个开源向量相似性搜索。
过去一年,人工智能功能的飞速发展激发了许多新的现实世界应用。一个特定的挑战是能够大规模存储和查询嵌入。在这篇文章中,我们将解释什么是嵌入,为什么我们可能想要使用它们,以及如何使用 PostgreSQL 存储和查询它们pgvector。
🆕 MemFire Cloud 现已发布使用 Postgres 和 pgvector 开发 AI 应用程序的开源工具包。在AI 和 Vectors 文档中了解更多信息。
什么是嵌入?
嵌入可以捕获文本、图像、视频或其他类型信息的“相关性”。这种相关性最常用于:
- 搜索: 搜索词与正文有多相似?
- 建议: 两种产品有多相似?
- 分类: 我们如何对文本主体进行分类?
- 聚类: 我们如何识别趋势?
让我们探索一个文本嵌入的示例。假设我们有三个短语:
- “猫追老鼠”
- “小猫捕食啮齿动物”
- “我喜欢火腿三明治”
你的任务是将具有相似含义的短语归为一组。如果你是人类,这应该是显而易见的。短语 1 和 2 几乎相同,而短语 3 的含义则完全不同。
虽然短语 1 和 2 相似,但它们没有共同的词汇(除了“the”)。但它们的含义几乎相同。我们如何才能教会计算机它们是相同的?
人类
人类使用词语和符号来交流语言。但孤立的词语大多毫无意义——我们需要从共同的知识和经验中汲取知识才能理解它们。只有当你知道 Google 是一个搜索引擎并且人们一直将其用作动词时,“你应该用 Google 来搜索”这句话才有意义。
同样,我们需要训练一个神经网络模型来理解人类语言。一个有效的模型应该在数百万个不同的例子中进行训练,以理解每个单词、短语、句子或段落在不同语境中的含义。
那么这与嵌入有何关系?
嵌入如何工作?
嵌入将离散信息(单词和符号)压缩为分布式连续值数据(向量)。如果我们把之前的短语拿出来并绘制在图表上,它可能看起来像这样:
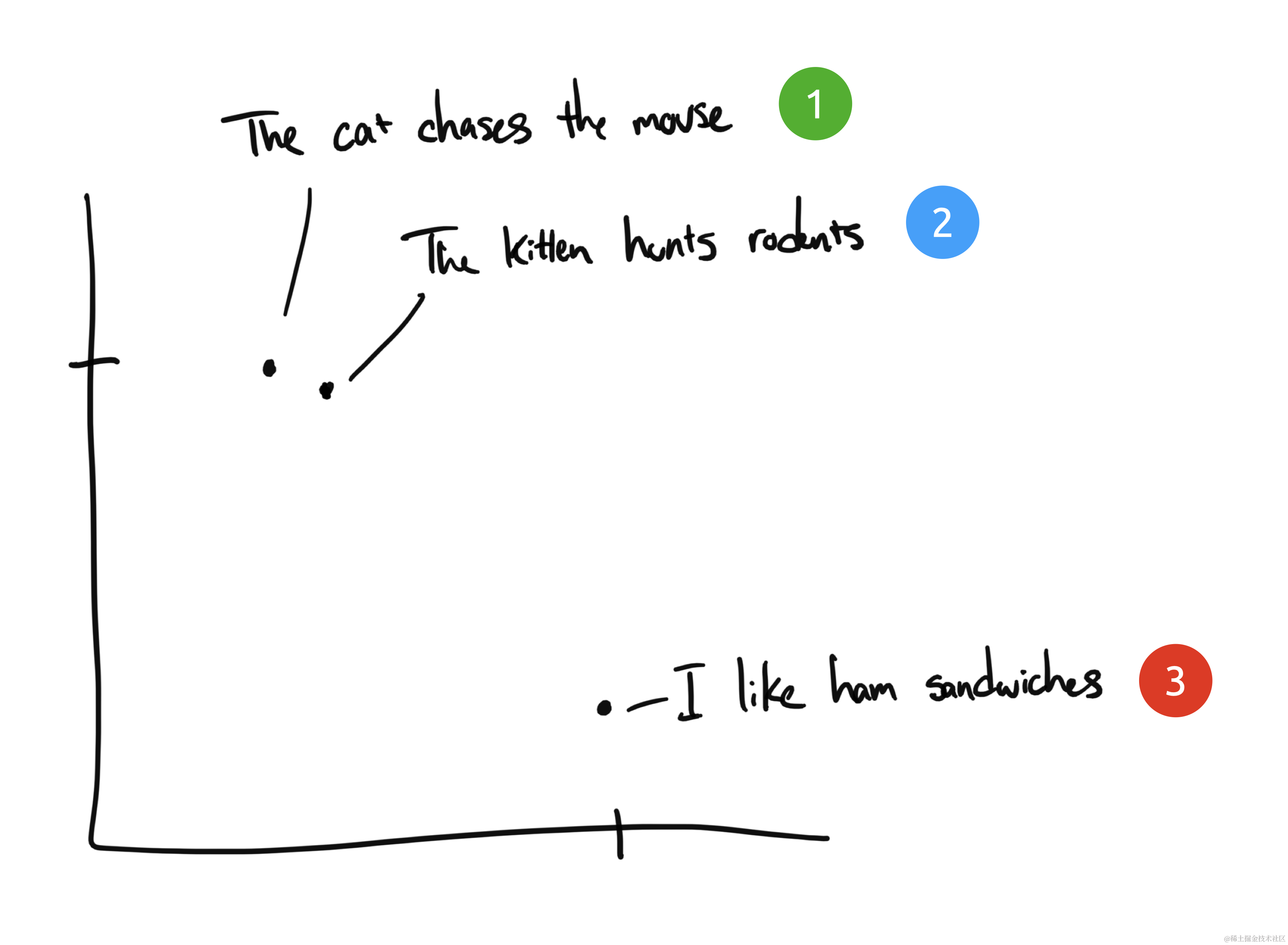
短语 1 和 2 将被绘制得彼此靠近,因为它们的含义相似。我们预计短语 3 会位于较远的地方,因为它与短语 3 无关。如果我们有第四个短语“Sally 吃瑞士奶酪”,它可能位于短语 3(奶酪可以放在三明治上)和短语 1(老鼠喜欢瑞士奶酪)之间的某个地方。
在这个例子中,我们只有 2 个维度:X 轴和 Y 轴。实际上,我们需要更多维度才能有效捕捉人类语言的复杂性。
OpenAI
OpenAI 提供了一个API,可以使用其语言模型为文本字符串生成嵌入。您可以向其输入任何文本信息(博客文章、文档、公司的知识库),它将输出一个浮点数向量,表示该文本的“含义”。
与我们上面的二维示例相比,他们的最新嵌入模型text-embedding-ada-002将输出 1536 维。
为什么这很有用?一旦我们在多个文本上生成了嵌入,使用余弦距离等向量数学运算来计算它们的相似度就很简单了。一个完美的用例是搜索。您的流程可能看起来像这样:
- 预处理知识库并为每个页面生成嵌入
- 存储你的嵌入以供稍后引用(更多信息请见此处)
- 构建一个提示用户输入的搜索页面
- 获取用户的输入,生成一次性嵌入,然后对预处理的嵌入执行相似性搜索。
- 向用户返回最相似的页面
实践中的嵌入
在小规模上,您可以将嵌入存储在 CSV 文件中,将其加载到 Python 中,然后使用类似库numPy来计算它们之间的相似度,例如使用余弦距离或点积。OpenAI 有一个食谱示例可以做到这一点。不幸的是,这可能无法很好地扩展:
- 如果我需要存储和搜索大量文档和嵌入(超过内存可以容纳的数量)怎么办?
- 如果我想动态创建/更新/删除嵌入怎么办?
- 如果我不使用 Python 怎么办?
使用PostgreSQL
输入pgvector,这是 PostgreSQL 的一个扩展,它允许您在数据库中存储和查询向量嵌入。让我们尝试一下。
首先,我们将启用VectorDatabase扩展。在 MemFire Cloud 中,可以通过→从 Web 门户完成此操作Extensions。您也可以通过运行以下命令在 SQL 中执行此操作:
create extension vector;
接下来让我们创建一个表来存储我们的文档及其嵌入:
create table documents (
id bigserial primary key,
content text,
embedding vector(1536)
);
pgvector引入了一个名为 的新数据类型vector。在上面的代码中,我们创建了一个embedding以vector数据类型命名的列。向量的大小定义了向量包含的维度数。OpenAI 的text-embedding-ada-002模型输出 1536 个维度,因此我们将使用它作为向量大小。
我们还创建了一个text名为的列,content用于存储生成此嵌入的原始文档文本。根据您的用例,您可能只在此处存储对文档的引用(URL 或外键)。
我们很快就需要对这些嵌入执行相似性搜索。让我们创建一个函数来执行此操作:
create or replace function match_documents (
query_embedding vector(1536),
match_threshold float,
match_count int
)
returns table (
id bigint,
content text,
similarity float
)
language sql stable
as $$
select
documents.id,
documents.content,
1 - (documents.embedding <=> query_embedding) as similarity
from documents
where documents.embedding <=> query_embedding < 1 - match_threshold
order by documents.embedding <=> query_embedding
limit match_count;
$$;
pgvector引入了3个可用于计算相似度的新运算符:
| 操作员 | 描述 |
|---|---|
<-> | 欧几里德距离 |
<#> | 负内积 |
<=> | 余弦距离 |
OpenAI 建议在其嵌入上使用余弦相似度,因此我们将在这里使用它。
现在我们可以调用match_documents(),传入我们的嵌入、相似度阈值和匹配计数,然后我们将获得所有匹配文档的列表。由于这一切都由 Postgres 管理,因此我们的应用程序代码变得非常简单。
索引
一旦您的表开始随着嵌入而增长,您可能希望添加索引以加快查询速度。向量索引在对结果进行排序时尤为重要,因为向量不是按相似性分组的,因此通过顺序扫描找到最接近的向量是一项资源密集型操作。
每个距离运算符都需要不同类型的索引。我们希望按余弦距离排序,因此我们需要vector_cosine_ops索引。列表的良好起始数量是 4 * sqrt(table_rows):
create index on documents using ivfflat (embedding vector_cosine_ops)
with
(lists = 100);
您可以在此处pgvector阅读有关GitHub 页面上索引的更多信息。
生成嵌入
让我们使用 JavaScript 生成嵌入并将它们存储在 Postgres 中:
create or replace function match_documents (
query_embedding vector(1536),
match_threshold float,
match_count int
)
returns table (
id bigint,
content text,
similarity float
)
language sql stable
as $$
select
documents.id,
documents.content,
1 - (documents.embedding <=> query_embedding) as similarity
from documents
where documents.embedding <=> query_embedding < 1 - match_threshold
order by documents.embedding <=> query_embedding
limit match_count;
$$;
构建一个简单的搜索功能
最后,让我们创建一个边缘函数来执行相似性搜索:
import { serve } from 'https://deno.land/std@0.170.0/http/server.ts'
import 'https://deno.land/x/xhr@0.2.1/mod.ts'
import { createClient } from 'https://esm.sh/@supabase/supabase-js@2.5.0'
import { Configuration, OpenAIApi } from 'https://esm.sh/openai@3.1.0'
import { supabaseClient } from './lib/supabase'
export const corsHeaders = {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Headers': 'authorization, x-client-info, apikey, content-type',
}
serve(async (req) => {
// Handle CORS
if (req.method === 'OPTIONS') {
return new Response('ok', { headers: corsHeaders })
}
// Search query is passed in request payload
const { query } = await req.json()
// OpenAI recommends replacing newlines with spaces for best results
const input = query.replace(/\n/g, ' ')
const configuration = new Configuration({ apiKey: '<YOUR_OPENAI_API_KEY>' })
const openai = new OpenAIApi(configuration)
// Generate a one-time embedding for the query itself
const embeddingResponse = await openai.createEmbedding({
model: 'text-embedding-ada-002',
input,
})
const [{ embedding }] = embeddingResponse.data.data
// In production we should handle possible errors
const { data: documents } = await supabaseClient.rpc('match_documents', {
query_embedding: embedding,
match_threshold: 0.78, // Choose an appropriate threshold for your data
match_count: 10, // Choose the number of matches
})
return new Response(JSON.stringify(documents), {
headers: { ...corsHeaders, 'Content-Type': 'application/json' },
})
})
构建更智能的搜索功能
ChatGPT 不仅仅返回现有文档。它能够将各种信息整合成一个统一的答案。为此,我们需要为 GPT 提供一些相关文档,以及一个可用于制定此答案的提示。
text-davinci-003 OpenAI补全模型的最大挑战之一是 4000 个 token 的限制。你必须将你的提示和最终的补全都放在 4000 个 token 之内。如果你想提示 GPT-3 回答有关你自己的自定义知识库的问题,而这些问题在单个提示中是无法解决的,那么这将非常具有挑战性。
嵌入可以通过将提示分为两个阶段的过程来帮助解决此问题:
- 查询嵌入数据库,查找与问题最相关的文档
- 将这些文档作为上下文注入,供 GPT-3 在其答案中引用
下面是另一个基于上述简单示例的边缘函数:
import { serve } from 'https://deno.land/std@0.170.0/http/server.ts'
import 'https://deno.land/x/xhr@0.2.1/mod.ts'
import { createClient } from 'https://esm.sh/@supabase/supabase-js@2.5.0'
import { Configuration, OpenAIApi } from 'https://esm.sh/openai@3.1.0'
import { supabaseClient } from './lib/supabase'
export const corsHeaders = {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Headers': 'authorization, x-client-info, apikey, content-type',
}
serve(async (req) => {
// Handle CORS
if (req.method === 'OPTIONS') {
return new Response('ok', { headers: corsHeaders })
}
// Search query is passed in request payload
const { query } = await req.json()
// OpenAI recommends replacing newlines with spaces for best results
const input = query.replace(/\n/g, ' ')
const configuration = new Configuration({ apiKey: '<YOUR_OPENAI_API_KEY>' })
const openai = new OpenAIApi(configuration)
// Generate a one-time embedding for the query itself
const embeddingResponse = await openai.createEmbedding({
model: 'text-embedding-ada-002',
input,
})
const [{ embedding }] = embeddingResponse.data.data
// In production we should handle possible errors
const { data: documents } = await supabaseClient.rpc('match_documents', {
query_embedding: embedding,
match_threshold: 0.78, // Choose an appropriate threshold for your data
match_count: 10, // Choose the number of matches
})
return new Response(JSON.stringify(documents), {
headers: { ...corsHeaders, 'Content-Type': 'application/json' },
})
})
流式传输结果
OpenAI API 响应需要更长时间,具体取决于“答案”的长度。ChatGPT 通过立即将响应流式传输给用户,提供了良好的用户体验。你可以在 Supabase 文档中看到类似的效果:
OpenAI API 支持使用服务器端事件完成流式传输。Supabase Edge Functions 在 Deno 中运行,它也支持服务器端事件。查看此提交以了解我们如何修改上述函数以构建流式传输接口。
包起来
在 Postgres 中存储嵌入打开了一个无限可能的世界。您可以将搜索功能与遥测功能相结合,添加用户提供的反馈(点赞/踩),并使您的搜索与您的产品更加融合。
pgvector 扩展现已在所有新的 MemFire Cloud 项目中可用。要使用它,请启动一个新的 Postgres 数据库:database.new
更多 pgvector 和 AI资源
- Supabase Clippy:Supabase Docs 的 ChatGPT
- Supabase 现已支持 Hugging Face
- 如何使用 Supabase Edge Runtime 从头构建 ChatGPT 插件
- Docs pgvector:嵌入和向量相似度
- 为 AI 工作负载选择计算附加组件
- pgvector v0.5.0:使用 HNSW 索引进行更快的语义搜索
原文来自:https://supabase.com/blog/openai-embeddings-postgres-vector















 2408
2408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









