






研究背景:
训练深度神经网络的复杂性在于,每一层的 输入分布在训练期间随着前一层的参数变化而变化,这需要通过较低的学习率和仔细的参数初始化来减慢训练速度,并且使得训练具有饱和非线性的模型变得非常困难。我们将这种现象称为内部协变移偏移。
为了解决这种问题,设置了Batch Normalization 允许我们使用更高的学习率并且对初始化要求没有那么仔细,并且在某种情况下可以减少Dropout 层的使用。大大的提高网络训练的速度以及准确度。
深度学习极大的推动了视觉,语音和其他领域的技术水平,随机梯度下降已经被证明是训练深度网络的一种有效方式。如动量已被用于实现最先进的性能,SGD优化了网络的参数,使损失最小化。后续介绍(SGD,ADAM).
但是随机梯度下降的缺点也很明显,他需要不断的调整超参数。尤其是学习率和初始参数值
方法和性质
论文提到协方差,
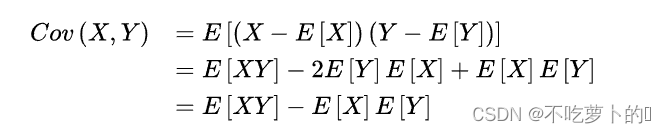

协方差可以反映两个变量的协同关系。变化方向是否一致,同向还是反向
X变化越大,Y变化也越大,那我们可以称,X,Y是同向变化的,这时协方差是正的
X变化越大,Y变化越小,那我们可以称,X,Y是反向变化的,这时协方差是负的,数值相差的越大两者的变化越大。
由于sigmoid函数在网络训练后期的梯度为0(我理解就是导数为0,对于参数更新会造成影响),这样会造成梯度消失的后果,如果我们能确保非线性的输入的分布随着网络的训练而保持稳定,那么优化器不太可能卡在饱和状态,训练就会加速。在训练过程中,我们把深度网络内部节点分布变化称为内部共变移位。因此提出批量归一化。通过固定层输入的均值和方差的nor-malization步骤来实现这一目标.
研究结果
亮点
1:BN大大加快了深度网络的训练,
2:可以用较大的学习率而不用考虑梯度爆炸和消失
3;可以一定程度上减少Dropout层的使用,而且还有正则化的作用,增加模型的范化能力
4:降低了模型对初始权重的依赖
5:即使不使用ReLu函数也可以解决激活函数饱和问题。(但其实深度学习使用RELU函数还是较多的。)
实现方式
首先进行标准化,我们使用均值为0,方差为1,对每一层的维度进行规范化处理,

但是简单的对每一层的输入归一化,可能会改变层可以表示的内容,为了解决这个问题,作者将标准化之后的数据进行线性变化。公式如下:
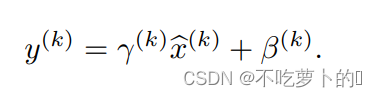
这个线性变化主要是将标准化之后的数据恢复一定的原始表达,y(相当于weight)和B(相当于bais)是和网络一起训练的,至于恢复多少完全由模型自己训练决定的
数据
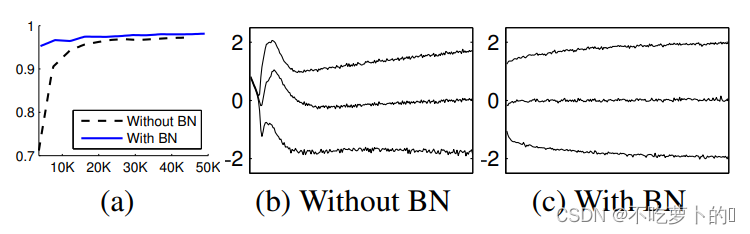
a图体现了有BN可以提高网络的准确率,b,c是对比BN使分布更加稳定,可以减少内部协变量的转移,梯度变平缓就可以加大学习率
结果
BN可以不要反复仔细的调参数,可以使用较大的学习率,可以减少Dropout层的使用,提高网络精度与训练速度。
研究展望
本文作者给我们指出了未来工作方向,未来的工作包括将我们的方法应用于递归神经网(Pascanu等人,2013),其中内部协变量偏移和消失或爆炸梯度可能特别严重,这将允许我们
更彻底地检验归一化的假设改进梯度传播。即归一化是否执行,通过网络将允许它更容易地推广到
新的数据分布,也许只需重新计算总体均值和方差(Alg. 2)。
想法和问题
用sigmoid函数替换RELU函数,并用BN进行批量归一化,对网络模型是否会有影响。















 8210
8210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









