







一.基础介绍
1.知识蒸馏简介
知识蒸馏是一种模型压缩方法,是一种基于“教师-学生网络思想”的训练方法。该方法使用复杂的教师网络诱导简单的学生网络训练,将已训练好的模型中包含的“知识”,蒸馏提取到另一个模型去,以实现知识迁移。
2.背景及应用
大模型参数多,需要消耗大量计算资源。由于内存显存算力等限制,采用大模型做推理,速度慢,成本高,不方便部署到服务端,因此模型压缩成为了一个重要的问题。知识蒸馏就是模型压缩方法的一种。
由知识蒸馏产生的轻量级学生网络可以轻松部署在视觉识别,语音识别和自然语言处理(NLP)等应用程序中。此外,还可以用于对抗攻击,数据增强,数据隐私和安全性,压缩数据集等方面.
3.基本原理
Hinton在《Distilling the Knowledge in a Neural Network》一文中首次提出蒸馏算法:

其核心思想是先训练一个复杂网络模型,然后使用这个复杂网络的输出和数据的真实标签去训练一个更小的网络。
二.阅读笔记
该论文是一篇将知识蒸馏用于异常检测的论文,论文链接:
https://arxiv.org/abs/2011.11108v1
1.摘要
无监督学习存在的两个挑战:
1.样本量小,通过传统技术无法学习到丰富的generalizable representation(可归纳/泛化的表示)。
2.虽然训练时只有正常样本可用,但学习到的特征应能区分正常和异常样本。
论文解决办法:
使用两个网络,源网络(在ImageNet上预训练)和克隆网络。将源网络的各个层的特征“蒸馏”到更简单的克隆网络中。利用它们中间激活值的差异来检测和定位异常。与仅使用最后一层激活值相比,在蒸馏中考虑多个中间特征,能更好地利用专家知识并且能取得更明显的差异。
2.引言
阐述了该论文的主要贡献:
1.能够更全面地将预训练专家网络的知识转移到克隆人网络。发现将知识提炼进更紧凑的网络有助于区分正常与异常的特征。
2.与其他工作比,计算成本低且训练过程稳定。
3.通过计算输入差异损失的梯度,可以实时精确地对异常定位。
4.进行了大量不同的实验,在许多数据集上超越了以前的SOTA模型。
3.方法

(1)训练过程:
看完代码后发现,论文是先将VGG16 ImageNet的预训练权重加载到源网络(VGG16)中,再把训练图片(正常图片)输入两个网络中。将源网络与克隆网络3,6,9,12层的输出,分别作为真实标签和预测标签,算出损失值,最后进行反向传播,迭代运算。
(2)测试过程
测试图片分别输入源网络和克隆网络中,和训练过程一样,算出损失值,再设通过置阈值方法,将正常图片和异常图片区分出来。
(3)损失函数:
值损失函数:
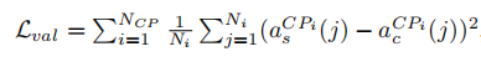
其中CPi为网络中的第i个关键层,acCPi为S的i层激活值(激活函数的值),asCPi为C的i层激活值,Ni为CPi层中神经元数量,Ncp为被使用的关键层总数。
方向损失函数:
因为,在激活函数使用ReLu的网络中,具有相同欧几里得距离的两个激活向量,在激活后续神经元时可能具有相反的行为。
例如:
假设来自两个不同克隆网络的激活向量
a1=(0,0 ,1, 0,0,…,0)
a2=(0,1+
2
\sqrt 2
2,0,0,…,0)
设a0=(0,1,0,…,0),显然a1,a2与a0的欧式距离相同。
设W=(0,1,…,0,0)为网络下一层神经元的权重向量,则:
Wta1=0≤0
Wta2=
2
\sqrt 2
2+1
Wta0=1>0
这种情况下,a2与a0相应的ReLU神经元将激活,但是a1的未激活。为了解决这个问题,论文使用方向损失Ldir增加向量之间的方向相似性。
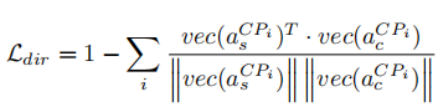
其中Vec(x)为向量化函数,能将具有任意维度的矩阵x转换为一维向量。这促使C的激活向量在欧几里德距离方面接近S的激活向量,而且激活向量在同一方向上。其中a1的Ldir为1,a2的Ldir为0。
总损失函数:
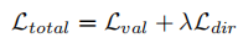
λ的作用是为了使两个组成项的尺度相同,为此,论文在未训练的网络上找到每一项的初始误差量,针对这一误差量来设置λ。
(4)如何检测与定位?
检测:测试图片分别送进S和C,由于S只向C传授了关于正常图像的知识,异常图片的输入会存在潜在差异,通过设置Ltotal阈值检测异常。
定位:利用Ltotal的梯度找到导致Ltotal增加的异常区域。
首先我们需要获取梯度属性图:
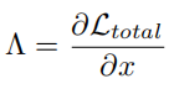
为了减少这些图的噪声,引入了高斯模糊并使用了形态滤波器: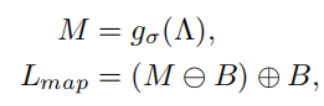
其中g表示标准差为σ的高斯滤波器。下面式子的两个符号分别表示腐蚀与膨胀。
这些操作可以消除小的零星噪声,结构元素B是一个简单的二值映射,通常为椭圆形或圆盘形。
参考资料:
[1] https://blog.csdn.net/andyjkt/article/details/108501693
[2] https://blog.csdn.net/nature553863/article/details/80568658
[3] https://blog.csdn.net/u012347027/article/details/111415197
[4] https://blog.csdn.net/minushuang/article/details/50435689
[5] https://blog.csdn.net/armsnow/article/details/79431052
[6] Salehi, M. , et al. “Multiresolution Knowledge Distillation for Anomaly Detection.” (2020).
[7] Hinton G , Vinyals O , Dean J . Distilling the Knowledge in a Neural Network[J]. Computer Science, 2015, 14(7):38-39.















 2179
2179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









