






1.蛮力冒泡排序
冒泡排序与选择排序是用蛮力法解决排序问题的最直观的例子。
冒泡排序法(Bubble Sort)是由观察水中冒泡现象而来。如果将待排序的元素值看作是质量,那么,质量小的元素应向水面上浮(即向左边移动)。
冒泡排序的基本思想是:两两比较相邻记录,如果反序则交换,直到没有反序的记录为止。
#include<iostream>
#include<iomanip>
using namespace std;
//数组输出
void Display(int* data, int n)
{
for (int i = 0; i < n; i++)
cout << setw(3) << data[i];
cout << endl;
}
void Bubble(int* data, int n)
{
for (int i = 1; i < n; i++)//做第i=1,2,...,n-1趟排序
{
for (int j = n - 1; j > i - 1; j--)
{
//i=1时
//4 5 3 6 2 1
// j-1 j
//...
//j-1 j
//由上述过程可以得出循环介绍的条件是j>i-1
if (data[j] < data[j - 1])
{//交换
int temp = data[j];
data[j] = data[j - 1];
data[j - 1] = temp;
}
}
//显示第i趟排序后的数组
cout << "第" << setw(2) << i << "趟排序 "; Display(data, n);
}
}
//主函数
int main()
{ int data[6]={4,5,3,6,2,1};//待排序数组
cout<<"待排序数组 ";Display(data,6);
Bubble(data,6);//调用冒泡排序函数
return 0;
}
运行结果如下图1.1。
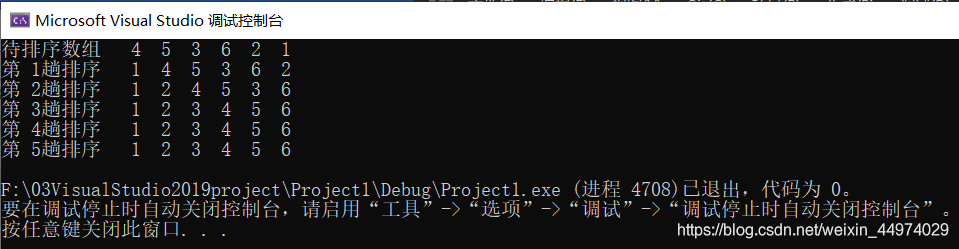 对6个元素做冒泡排序,在最坏情况下,需要做5趟排序。由上图发现,该数组其实只需做3趟排序即可,后面的两趟排序是多余的。为了克服这一缺陷,只需在冒泡函数中,增加一个标识变量和一个判断语句,就可弥补此缺陷,使臻完善。
对6个元素做冒泡排序,在最坏情况下,需要做5趟排序。由上图发现,该数组其实只需做3趟排序即可,后面的两趟排序是多余的。为了克服这一缺陷,只需在冒泡函数中,增加一个标识变量和一个判断语句,就可弥补此缺陷,使臻完善。
//冒泡排序
void Bubble(int* data, int n)
{
int flag;
for (int i = 1; i < n; i++)//做第i=1,2,...,n-1趟排序
{
flag = 1;//先假设数组为正序
for (int j = n - 1; j > i - 1; j--)
{
if (data[j] < data[j - 1])
{
flag = 0;//数组中仍有逆序
int temp = data[j];
data[j] = data[j - 1];
data[j - 1] = temp;
}
}
if (flag == 1)//如果做完第i趟排序发现数组确为正序
break;//退出,不必输出结果,也不再参与后续排序
else
{ //显示第i趟排序后的数组
cout << "第" << setw(2) << i << "趟排序 "; Display(data, n);
}
}
}
用改进后的冒泡函数去置换上述程序中的冒泡函数,程序运行结果如下图1.2。
 对冒泡排序法的性能分析:
对冒泡排序法的性能分析:
n 个元素用冒泡排序法来排序,最好情况(已有序)下只需做一趟排序,做 n-1次元素比较,因此最好情况下的时间复杂度为O(n) ,无须移动元素;最坏情况下需做n-1 趟排序,第 i趟的元素比较n-i 次,移动元素 3(n-i)次,总的比较次数为1/2n(n-1)、移动次数为3/2n(n-1),因此,在最坏情况下的时间复杂度为 O(n*n)。
该算法执行时间与元素的初始排列有关,冒泡排序经过一趟排序后,能确定一个元素的最终位置。由图1.2可以看出,当待排序序列基本有序时,可以减少排序趟数。这表明,冒泡排序“偏爱”基本有序的序列。由于冒泡排序中的元素交换是相邻元素的交换,因此,冒泡排序是稳定的排序方法。冒泡排序仅需一个额外的存储空间用来存放变量temp。
2.蛮力选择排序
选择排序法(Select Sort)是在待排序序列data[0]—data[n-1]中,找出最小值元素,将它与data[0]交换,然后再待排序子序列data[1]—data[n-1]中,再找出最小值元素,再将它与data[1]交换,如此做下去,经过n-1趟排序后,使得待排序序列成为有序序列。
#include<iostream>
#include<iomanip>
using namespace std;
//输出数组
void Display(int* data, int n)
{
for (int i = 0; i < n; i++)
cout << setw(3) << data[i];
cout << endl;
}
//选择排序
void Select(int* data, int n)
{
int min, pos, flag;
for (int i = 1; i < n; i++)//做第i=1,2,...,n-1趟排序
{ //用顺序搜索法找出data[i-1]至data[n-1]的最小值
min = data[i - 1];
pos = i - 1;
flag = 1;//先假设data[i-1]为最小值
for (int j = i; j < n; j++)
{
if (min > data[j])
{
min = data[j];
pos = j;
flag = 0;//data[i-1]并非最小值,flag置0
}
}
if (flag == 0)//如果最小值被改变
{ //做交换
int temp = data[i - 1];
data[i - 1] = data[pos];
data[pos] = temp;
}
//显示第i趟排序后的数组
cout << "第" << setw(2) << i << "趟排序 "; Display(data, n);
}
}
//主函数
int main()
{
int data[6] = { 4,5,3,6,2,1 };//待排序数组
cout << "待排序数据 "; Display(data, 6);
Select(data, 6);//调用选择排序函数
return 0;
}
运行结果如下图2.1
 对选择排序法的性能分析:
对选择排序法的性能分析:
对任意初始数据,该算法都必须执行n-1趟。第i趟执行n-i次比较,这样总的比较次数为1/2n(n-1)。 因此,选择排序的最好、最坏和平均情况的时间复杂度都为***O(nn) ,而且它还需交换元素n-1次和移动元素3(n-1)次。
该排序算法经过一趟排序后,能确定一个元素的最终位置。由于元素间的交换不一定是相邻元素的交换,因此它是不稳定的。选择排序仅需一个额外的存储空间用来存放变量temp。由于该排序法在最好、最坏和平均情况下的时间复杂度都一样,它适合对那些“杂乱无序”数据进行排序。
3.减治插入排序
插入排序数据减治法的减一技术。
插入排序法(Insert Sort)是将序列中第一个元素作为一个有序序列,然后将剩下的 个元素按大小依次插入该有序序列,每插入一个元素后依然保持该序列有序。
#include<iostream>
#include<iomanip>
using namespace std;
//输出数组
void Display(int* data, int n)
{
for (int i = 0; i < n; i++)
cout << setw(3) << data[i];
cout << endl;
}
//插入排序
void Insert(int* data, int n)
{
for (int i = 1; i < n; i++)//做第i=1,2,...,n-1趟排序
{
int temp = data[i];// temp暂存待插元素
int j = i - 1;//确定待插元素的前驱位置
while (j >= 0 && temp < data[j])//当待插元素值小于它的前驱值时
{
data[j + 1] = data[j];//前驱元素后移
j--;//前驱位置前移
}
data[j + 1] = temp;//找到temp的插入位置,使它归位
//显示第i趟排序后的数组
cout << "第" << setw(2) << i << "趟排序 "; Display(data, n);
}
}
//主函数
int main()
{
int data[6] = { 4,5,3,6,2,1 };//待排序数组
cout << "待排序数组 "; Display(data, 6);
Insert(data, 6);//调用插入排序函数
return 0;
}
运行结果如下图3.1
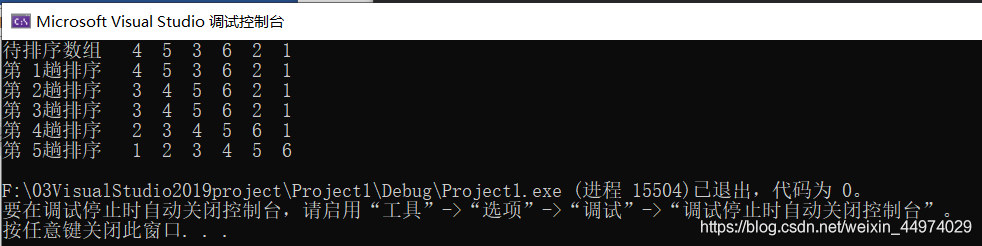 对插入排序法的性能分析:
对插入排序法的性能分析:
插入排序法必须进行n-1趟。最好情况(初始序列为升序的)下,执行n-1趟排序,每趟比较1次,总的比较次数为 n-1,因此最好情况下的时间复杂度为O(n) 。
最坏情况(初始序列为降序的)下,第i趟排序,比较次数为 i次,移动元素次数2i次,需要的比较次数和移动元素次数分别为1/2n(n-1),n*(n-1),因此最坏情况下的时间复杂度为 O(n*n)。
在第i趟排序中,是将元素data[i]与i个有序元素data[0],…,data[i-1]调整成有序的,仅在data[i]<data[j](0≤j≤i-1)时,才会依序移动元素,故它是稳定的。且只需一个额外的存储空间用来存放变量temp。由于该排序法在最好、最坏情况下的时间复杂度相差甚大,因此它适宜对基本有序的数据进行排序。
除了冒泡、选择和插入这三种基本排序法外,还有一些排序效率更高的排序法。
4.减治堆排序
堆排序法是选择排序法的一种改进,它可以减少选择排序法中的比较次数,进而提高排序效率。堆排序法利用最大堆(或最小堆)来完成排序。
#include<iostream>
#include<iomanip>
using namespace std;
//输出函数
void Display(int *data,int n)
{ for(int i=0;i<n;i++)
cout<<setw(2)<<data[i];
cout<<endl;
}
//下滑法调最大堆
void SiftDown(int *data,int n)
{ //将data[0]-data[n-1]调成最大堆
int i,j,temp,parent;
for(parent=(n-2)/2;parent>=0;parent--)
{ i=parent;
temp=data[i];//temp取双亲结点值
j=2*i+1;//让j指向i的左孩子位置
while(j<n)
{ if(j+1<n) //如果右孩子位置j+1未超界
j=data[j]<data[j+1]?j+1:j;//让j指向左右孩子中最大者的位置
if(temp>data[j])//如果双亲结点值大
break;//不做交换
else//如果双亲结点值小
{ data[i]=data[j];//做交换
i=j;//改变双亲结点位置
j=2*i+1;//再让j指向i的左孩子位置
}
}
data[i]=temp;//使temp归位
}
}
//堆排序
void HeapSort(int *data,int n)
{ int i,temp;
for(i=1;i<n;i++)//做第i=1,...,n-1趟排序
{ //用下滑法将data[0]-data[n-i]将调成最大堆
SiftDown(data,n-i+1);
//头尾结点交换
temp=data[n-i];
data[n-i]=data[0];
data[0]=temp;
//输出第i趟排序结果
cout<<"第"<<setw(2)<<i<<"趟排序 ";
Display(data,n);
}
}
//主函数
int main()
{ int data[7]={5,2,6,1,7,3,4};//待排序数组
cout<<"待排序数据 ";Display(data,7);
HeapSort(data,7);//调用堆排序函数
return 0;
}
运行结果如下图4.1
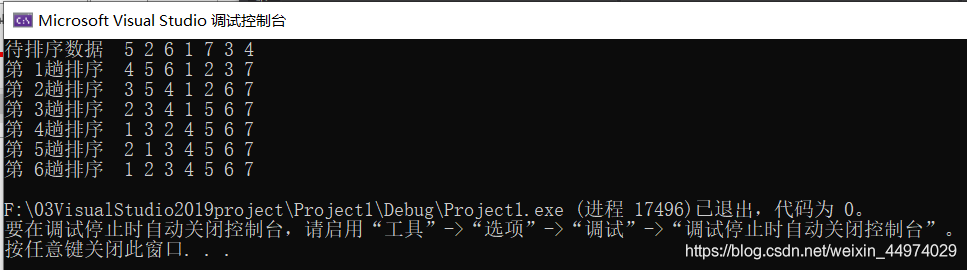 对堆排序法的性能分析:
对堆排序法的性能分析:
在所有情况下,堆排序法的时间复杂度为 O(n*log2n),堆排序是不稳定的,只需要一个额外的存储空间。
5.分治快排
分治法(divide and conquer method)是著名算法设计技术之一。用计算机求解问题时所需的时间一般都与问题规模有关。问题规模越小,求解问题所需的时间也越少,从而也较容易处理。
分治法将一个难以直接解决的大问题划分成一些规模较小的子问题,分别求解各个子问题,再合并子问题得到原问题的解。
快速排序算法的思想就是分治法。快速排序法是目前公认的最佳排序法,它是采用递归方式进行排序的。
快排算法首先对排序序列进行划分,划分的基准元素应该遵循平衡子问题的原则,使划分后的两个子序列的长度尽可能相等,这是决定快排算法时间性能的关键。基准的选择可以由很多种,例如可以随机选出一个记录作为基准元素。
#include<iostream>
#include<iomanip>
using namespace std;
//输出函数
void Display(int* data, int n)
{
for (int i = 0; i < n; i++)
cout << setw(3) << data[i];
cout << endl;
}
//快速排序算法
void QuickSort(int a[], int left, int right)
{
if (left > right)
return;
int static cnt = 0;//快速排序趟数统计变量
int k = a[left];//k存放基准元素
int i = left;
int j = right;
while (i != j)
{
while (a[j] >= k && i < j)//从左往右找比k小的元素位置
j--;
while (a[i] <= k && i < j)//从右往左找比k大的元素位置
i++;
//交换两个元素在数组中的位置
if (i < j)//当i和j不相遇
{
int temp = a[i]; a[i] = a[j]; a[j] = temp;
}
}
a[left] = a[i]; a[i] = k;//与a[i]与基准元素k交换
//显示第i趟排序后的数组
cout << "第" << setw(2) << ++cnt << "趟排序 "; Display(a, 7);
QuickSort(a, left, i - 1);//继续处理左边的序列
QuickSort(a, i + 1, right);//继续处理右边的序列
}
//主函数
int main()
{
int data[7] = { 5,2,6,1,7,3,4 };//待排序数组
cout << "待排序数组 ";Display(data, 7);
QuickSort(data, 0, 6);
return 0;
}
运行结果如下图5.1
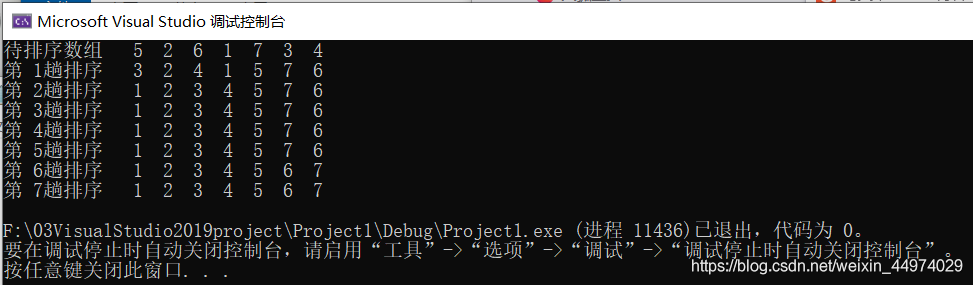 对快速排序法的性能分析:
对快速排序法的性能分析:
在最好和平均情况下,时间复杂度为O(n*log2n)。最坏情况下的时间复杂度为O(n*n) 。快速排序法是不稳定的排序法。空间复杂度在最坏情况下为 O(n),在最好情况下为O(log2n) 。
6.分治归并
二路归并排序是成功应用分治法的一个完美例子。
下面,介绍二路归并排序思想。
将待排序数组视为有序数组。
第1趟:从左至右按len=1分组,将它们合并为长度len=2的有序数组;
第2趟:从左至右按len=2分组,并将它们合并为长度len=4的有序数组;
第3趟:从左至右按len=4分组,并将它们合并为长度len=8的有序数组。
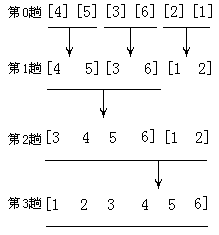
具体实现过程,如下图所示:
 其中,DividMerge(a,n,len)表示对含n个元素数组a按长度len进行分组。Merge(a,left,mid,right)表示对有序左段a[left,mid]与有序右段a[mid+1,right]进行合并
其中,DividMerge(a,n,len)表示对含n个元素数组a按长度len进行分组。Merge(a,left,mid,right)表示对有序左段a[left,mid]与有序右段a[mid+1,right]进行合并
#include<iostream>
#include<iomanip>
#include<cmath>
using namespace std;
#define N 6
//输出函数
void Display(int a[],int n)
{
int i,col=0;
for(i=0;i<n;i++)
{
cout<<setw(6)<<a[i];
col++;
if(col==20)
{
cout<<endl;
col=0;
}
}
cout<<endl;
}
//2段归并
void Merge(int a[],int left,int mid,int right)
{
//归并 有序左段a[left...mid]与有序右段a[mid+1...right]
int *A;//定义一个动态数组
A=new int[right-left+1];//为A分配内存
int i=left,j=mid+1,k=0;//k为A的首下标
while(i<=mid&&j<=right)
{
if(a[i]<a[j])
{
A[k]=a[i];//将有序左段元素存入A
i++;k++;
}
else
{
A[k]=a[j];//将有序右段元素存入A
j++;k++;
}
}
while(i<=mid)//将有序左段余下元素存入A
{
A[k]=a[i];
i++;k++;
}
while(j<=right)//将有序右段余下元素存入A
{
A[k]=a[j];
j++;k++;
}
for(k=0,i=left;i<=right;k++,i++)//使a=A
a[i]=A[k];
}
//分组归并
void DividMerge(int a[],int n,int len)
{
int i;
for(i=0;i+2*len-1<n;i=i+2*len)//合并长度为len的两相邻数组
Merge(a,i,i+len-1,i+2*len-1);//相邻两数组归并
if(i+len-1<n)//余下的两个数组,后者长度小于len
Merge(a,i,i+len-1,n-1);//余下两数组归并
//显示本趟分组排序后的数组
cout<<"第"<<setw(2)<<log(len)/log(2)+1<<"趟排序 ";
Display(a,n);
}
//二路归并排序
void MergeSort(int a[],int n)
{
int len;//分组长度
for(len=1;len<n;len=2*len)
DividMerge(a,n,len);//分组
}
//主函数
void main()
{
int a[N]={4,5,3,6,2,1};
cout<<"待排序数组 ";Display(a,N);
MergeSort(a,N);//合并排序
}
运行结果如图6.1
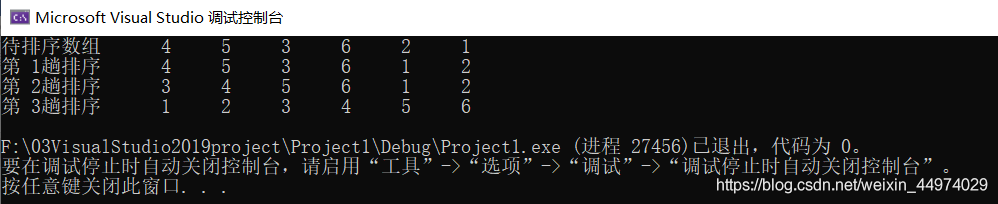 由算法可知,需要一个与待排序数组a[]等长的辅助数组A[],故空间复杂度为O(n)。
由算法可知,需要一个与待排序数组a[]等长的辅助数组A[],故空间复杂度为O(n)。
待排序数组含 个元素,将此 个元素看作叶子结点,若将两两归并生成的数组看作它们的父结点,则归并过程对应由叶向根生成一棵二叉树的过程。所以归并趟数约等于二叉树的高度减1,约为log2n,每趟归并大约需移动元素n次,故时间复杂度为O(n*log2n)。它不随待排序数组的初始状态的变化而变化,它是稳定的排序法。
快速排序也是基于分治法的排序算法。与二路归并排序不同的是,二路归并排序是按照元素在序列中的位置,对序列进行分组划分。而快速排序是按照元素的值,对序列进行分组划分。
7.桶排序
基数排序法又称桶排序(Bucket Sort),是利用对多关键字进行排序的思想,实现对单关键字进行排序的方法。
基数排序法可分最高位优先MSD(Most Significant Digit First)和最低位优先LSD(Least Significant Digit First)两种。MSD法是从最左边的位数开始比较,而LSD则是从最右边的位数开始比较。
下面,采用低位优先法,对数组data[12]={59,95,7,34,60,168,171,259,372,45,88,133}进行升序排序。
(1)根据初始数据次序,按数据的个位数字,放入相应编号的桶中。数据按个位数字进桶后的状态如下表所示。
 依个位数字排序后的数据次序如下:
依个位数字排序后的数据次序如下:
60 171 372 133 34 95 45 7 168 88 59 259
(2)再根据个位数字排序后的数据次序,按数据的十位数字,再放入相应编号的桶中。数据按十位数字进桶后的状态如下表所示。
 依十位数字排序后的数据次序如下:
依十位数字排序后的数据次序如下:
7 133 34 45 59 259 60 168 171 372 88 95
(3)再根据十位数字排序后的数据次序,按数据的百位数字,再放入相应编号的桶中。数据按百位数字进桶后的状态如下表所示。
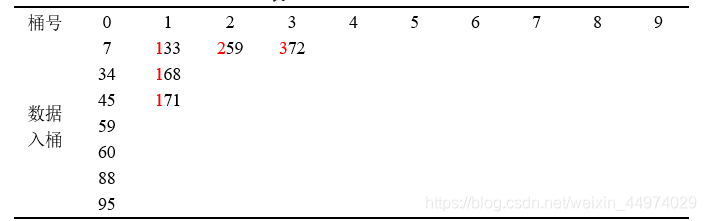
依百位数字排序后的数据次序如下:
7 34 45 59 60 88 95 133 168 171 259 375
上述对桶排序过程的描述,可提炼成以下程序中的桶排序函数BucketSort。
核心三步:一、获取个,十,百,并初始化桶。二、进桶。三、出桶,并输出桶状态和数组状态。
#include<iostream>
#include<iomanip>
using namespace std;
//输出函数
void Display(int *data,int n)
{ for(int i=0;i<n;i++)
cout<<setw(5)<<data[i];
cout<<endl;
}
//初始化桶
void Initial(int *bucket,int n)
{ for(int j=0;j<10;j++)
{ bucket[0*10+j]=j;//第0行为桶号(0-9)
for(int i=1;i<n+1;i++)
bucket[10*i+j]=0;//第1-n行置0,表示桶空
}
}
//桶排序
void BucketSort(int *data,int *bucket,int n)
{ int i,j,p,q;
for(p=1;p<=100;p=p*10)//基数p分别取1,10,100
{ Initial(bucket,n);//初始化桶
int row[10]={0};//row[]记录0-9号桶内装入数据个数
//data进桶
for(i=0;i<n;i++)
{ q=(data[i]/p)%10;//p=1,q取个数,p=10,q取十位,p=100,q取百位
row[q]++;//q号桶装入数据个数增1
bucket[10*row[q]+q]=data[i];//data[i]进入q号桶
}
//搜索桶中装入元素个数的最大值
int MaxRow=0;
for(j=0;j<10;j++)
{ if(row[j]>MaxRow)
MaxRow=row[j];
}
//按p位排序结果改写数组data
int k=0;//活动下标
for(j=0;j<10;j++)
for(i=1;i<=MaxRow;i++)
if(bucket[10*i+j]!=0)
data[k++]=bucket[10*i+j];
//输出桶状态
cout<<setw(3)<<p<<"位进桶状态"<<endl;
for(i=0;i<=MaxRow;i++)
{ for(j=0;j<10;j++)
cout<<setw(5)<<bucket[10*i+j];
cout<<endl;
}
//输出p位排序后的数组
cout<<setw(3)<<p<<"位排序 ";Display(data,n);
}
}
//主函数
int main()
{ int data[12]={59,95,7,34,60,168,171,259,372,45,88,133};
int *bucket=new int(13*10);//桶数组
cout<<" 初始数组 ";Display(data,12);
BucketSort(data,bucket,12);
return 0;
}
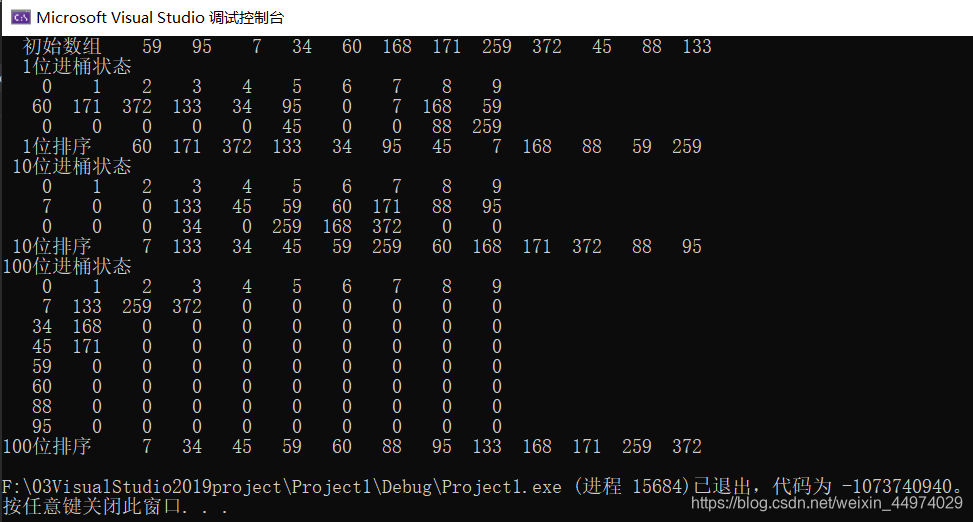
运行结果如图7.1
 对桶排序法的性能分析:
对桶排序法的性能分析:
在所有情况下,基数排序法的时间复杂度O(n)、空间复杂度均为O(n) ,它是稳定的,当n很大时,此排序法拥有极高的效率。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











