






推荐语:
在自然语言处理(NLP)领域,大型语言模型(LLMs)的进步已经彻底改变了我们对文本理解和生成的能力。然而,在知识密集型任务中,传统的检索增强生成(RAG)系统面临着诸多挑战,如上下文完整性受损、过度依赖语义相似性以及检索精度不足等问题。
本文提出的CausalRAG框架通过引入因果图,为RAG系统带来了新的视角。CausalRAG不仅保留了上下文的连续性,还通过追踪因果关系提高了检索的精确性和响应的可解释性。实验结果表明,CausalRAG在多个指标上优于传统的RAG和基于图的RAG方法,显著提升了知识密集型任务的性能。
如果你对如何利用因果推理来增强AI系统的检索和生成能力感兴趣,这篇文章将为你提供宝贵的见解和方法。快来一探究竟吧!
核心速览
研究背景
- 研究问题:这篇文章要解决的问题是传统检索增强生成(RAG)系统在处理知识密集型任务时面临的局限性,包括上下文完整性中断、过度依赖语义相似性进行检索以及选择真正相关文档的准确性不足。
- 研究难点:该问题的研究难点包括:如何在不破坏上下文完整性的情况下进行文本分块,如何从语义相似性转向因果相关性以提高检索精度,以及如何提高选择真正相关文档的准确性。
- 相关工作:该问题的研究相关工作有:优化RAG系统的检索流程和交互、改进外部知识的结构化以提升检索效率、将因果图与RAG结合以提高知识检索和推理能力。
研究方法
这篇论文提出了CausalRAG框架,用于解决RAG系统在处理知识密集型任务时的局限性。具体来说,
-
索引:首先,系统接收用户上传的文档和查询,并将这些输入索引到向量数据库中。对于上传的文档,采用基于LLM的文本图构建方法将其转换为结构化图,然后存储节点和边。
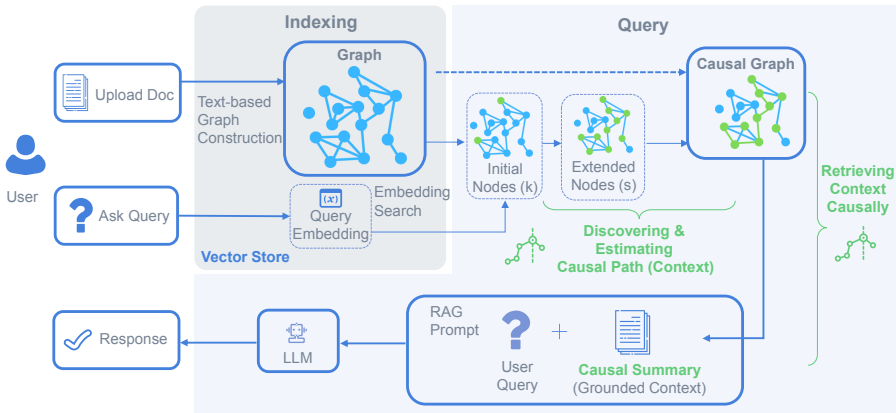
-
发现和估计因果路径:在查询时,首先根据嵌入距离匹配用户查询到图中的节点,选择距离最近的k个节点。然后沿着图的边扩展搜索,步长为s,以拓宽检索到的上下文。最后,利用LLM识别和估计这些节点和边中的因果路径,构建一个精细化的因果图。
-
因果上下文检索:在构建因果图后,总结检索到的信息并生成一个因果摘要。这个摘要不仅高度相关,而且在用户查询中具有因果基础,确保生成的响应逻辑一致且事实准确。然后将因果摘要与用户查询结合,构建一个结构化的最终输入,使RAG能够专注于通过因果关系进行推理。
实验设计
为了评估CausalRAG的有效性,进行了以下实验设计:
- 参数和数据集:设置CausalRAG的默认参数为k=3,s=3,并使用相同的k值进行GraphRAG的社区检索和常规RAG的文档检索。评估四种RAG变体:常规RAG、GraphRAG(局部和全局搜索)和提出的CausalRAG。使用GPT-4o-mini作为所有模型的基LLM。数据集来自OpenAlex公共学术数据集,涵盖多个领域的研究论文。
- 评估指标:使用Ragas框架评估模型在三个关键指标上的表现:答案准确性、上下文召回率和上下文精确率。准确性衡量生成响应与参考信息的事实一致性,召回率衡量检索到的正确参考信息的比例,精确率衡量检索到的正确响应的比例。
结果与分析
-
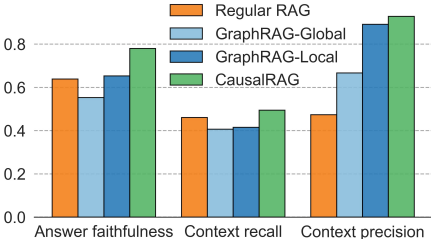
答案准确性:常规RAG在答案准确性上表现相对较强,但仍不如CausalRAG。GraphRAG(局部和全局搜索)在答案准确性上略优于常规RAG,但仍不如CausalRAG。
-
上下文召回率:常规RAG在上下文召回率上表现较高,因为它采用了广泛的检索方法。GraphRAG(局部和全局搜索)由于社区总结过程牺牲了一些上下文多样性,召回率略有下降。CausalRAG在召回率和精确率之间取得了平衡,召回率仍高于常规RAG。
-
上下文精确率:常规RAG在上下文精确率上表现较低,通常检索到语义相似但上下文无关的内容。GraphRAG(局部和全局搜索)显著提高了这一指标,但仍不如CausalRAG。CausalRAG通过因果图过滤检索到的信息,保持了高精确率。
总体结论
这篇论文提出了CausalRAG框架,通过将因果图集成到RAG中,解决了现有RAG系统在处理知识密集型任务时的局限性。实验结果表明,CausalRAG在答案准确性、上下文召回率和上下文精确率上均优于常规RAG和GraphRAG。此外,CausalRAG还提高了LLM的可解释性,增强了答案的接地性,并减少了生成响应中的幻觉。未来的工作包括在特定领域任务上对CausalRAG进行基准测试。
论文评价
优点与创新
- 系统识别RAG检索过程的局限性:通过分析和实验研究,系统地识别了常规RAG及其图基扩展的固有限制,揭示了LLMs在RAG框架中生成看似相关但缺乏细节的浅层答案的主要原因。
- 提出CausalRAG框架:通过将因果性引入RAG,增强了检索和生成质量,有效解决了现有RAG系统的限制。
- 缓解幻觉问题并提高可解释性:该方法不仅提高了检索效果,还显著减少了生成响应中的幻觉,增强了AI系统的可解释性。
- 多领域数据集上的实验验证:在多个领域的公开研究论文数据集上进行了实验,验证了CausalRAG在不同上下文长度下的鲁棒性和有效性。
- 参数分析和案例研究:进行了参数分析和案例研究,进一步探讨了框架的贡献,并为RAG研究提供了有价值的见解。
不足与反思
- 构建因果图的计算成本:从非结构化文本中构建因果图依赖于基于LLM的提取,这在复杂或模糊的情况下可能会引入额外的成本。
- 大规模文档的计算开销:扩展和分析因果路径的计算成本随着文档变大而增加,在极端情况下(如大量令牌)可能会影响检索效率。
关键问题及回答
问题1:CausalRAG是如何在检索过程中保持上下文完整性的?
CausalRAG通过构建和跟踪因果关系来保持上下文完整性。具体步骤如下:
- 文本图构建:首先,系统接收用户上传的文档和查询,并将这些输入索引到向量数据库中。对于上传的文档,采用基于LLM的文本图构建方法将其转换为结构化图,然后存储节点和边。
- 因果路径扩展:在查询时,首先根据嵌入距离匹配用户查询到图中的节点,选择距离最近的k个节点。然后沿着图的边扩展搜索,步长为s,以拓宽检索到的上下文。这个步骤确保了检索到的信息在文本内的因果和关系连接得以保留。
- 因果图构建:最后,利用LLM识别和估计这些节点和边中的因果路径,构建一个精细化的因果图。这个因果图不仅保留了因果相关信息,还过滤掉了语义相似但因果无关的内容,从而保持了上下文的完整性。
问题2:在实验中,CausalRAG在不同长度的文本上表现如何?
CausalRAG在不同长度的文本上表现出色,展现了良好的可扩展性。具体结果如下:
- 短文本:在较短的文本上,常规RAG表现较好,甚至超过了GraphRAG。这是因为短文本通常包含的信息量较少,语义相似性检索就能满足需求。
- 长文本:随着文本长度的增加,尤其是超过一定阈值(如全文),GraphRAG的性能开始超越常规RAG,而CausalRAG则表现出更高的稳定性和精确率。这是因为长文本中包含了更多的信息和复杂的因果关系,常规RAG的广泛检索方法可能会引入大量不相关的信息,而GraphRAG和CausalRAG则能通过结构化图和因果路径分析更好地处理这些复杂关系。
- 复杂因果关系:CausalRAG通过调整参数s,能够捕捉长文本中隐藏的长距离因果关系,生成更为合理和准确的响应。这一点在处理复杂因果关系的任务时尤为突出,显示了CausalRAG的优势。
问题3:CausalRAG在答案准确性、上下文召回率和上下文精确率上分别表现如何?
- 答案准确性:CausalRAG在答案准确性上表现最佳。它通过因果图过滤检索到的信息,确保生成的响应不仅相关,而且得到了检索证据的支持,减少了幻觉现象。相比之下,常规RAG虽然能检索到一些相关上下文,但在答案的准确性和合理性上仍有不足。
- 上下文召回率:常规RAG在上下文召回率上表现较高,因为它采用了广泛的检索方法,倾向于最大化包含潜在相关内容的可能性。然而,GraphRAG由于其社区总结过程牺牲了一些上下文多样性,召回率略有下降。CausalRAG在召回率和精确率之间取得了平衡,召回率仍高于常规RAG,确保了检索到的信息既多样又相关。
- 上下文精确率:常规RAG在上下文精确率上表现较低,通常检索到语义相似但上下文无关的内容。GraphRAG通过结构化图提高了这一指标,但仍不如CausalRAG。CausalRAG通过因果图过滤检索到的信息,进一步提高了精确率,确保检索到的信息不仅相关,而且因果上合理。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









