






MySQL调优
文章目录
Docker中安装MySQL
Docker安装
卸载旧版本
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
设置阿里云仓库
yum install -y yum-utils \
device-mapper-persistent-data \
lvm2
yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
安装 Docker Engine-Community
yum install docker-ce docker-ce-cli containerd.io
启动Docker
systemctl start docker
通过运行 hello-world 映像来验证是否正确安装了 Docker Engine-Community
docker run hello-world
MySQL安装
docker 中下载 mysql
docker pull mysql
启动 MySQL
📢密码组成:
数字+符号+字母
docker run --name mysql8 -p 3886:3886 -e MYSQL_ROOT_PASSWORD=980512@Nsd -d mysql
进入容器
docker exec -it mysql8 bash
登录mysql
mysql -uroot -p980512@Nsd
添加远程登录用户
CREATE USER 'RhysNi'@'%' IDENTIFIED WITH mysql_native_password BY '980512@Nsd';
GRANT ALL PRIVILEGES ON *.* TO 'RhysNi'@'%';
exit
安装vim, 因为下面我们要在docker中编辑mysql配置文件
apt-get update
apt-get install vim
exit
查看容器ID
docker ps -a

重启容器,ID换成兄弟们自己查询出来的ID即可
docker restart 39b6bfefda87
修改配置文件端口号
docker exec -it mysql8 bash
vi /etc/mysql/my.cnf

port=3886
改好
Esc输入:wq保存并退出编辑
重启进入
exit
docker restart 39b6bfefda87
docker exec -it mysql8 bash
mysql -uroot -p980512@Nsd
查看端口号

show global variables like 'port';
远程连接工具安装-DBeaver
DBeaver是一款免费的多平台数据库工具,适用于开发人员、数据库管理员、分析师和所有需要使用数据库的人。 支持所有流行的数据库:MySQL、PostgreSQL、SQLite、Oracle、DB2、SQL Server、Sybase、MS Access、Teradata、Firebird、Apache Hive、Phoenix、Presto 等。👇🏻
点击下图跳转下载👇🏻

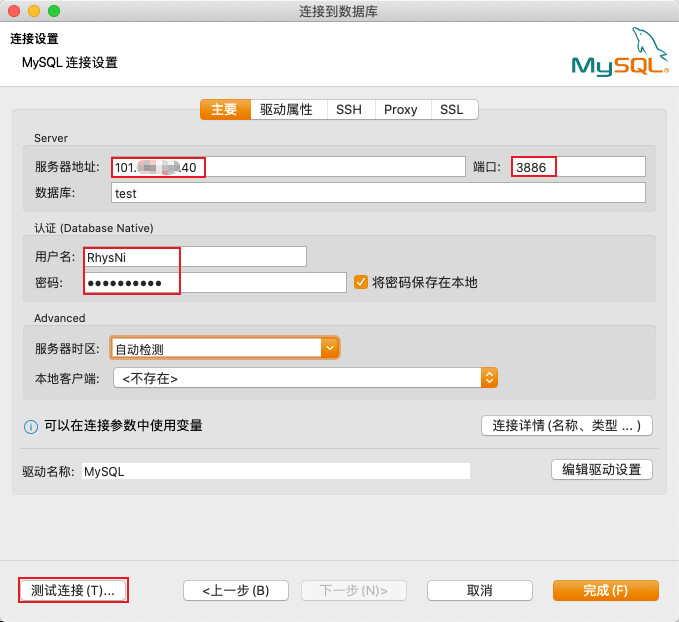
安装好后打开工具连接MySQL

填入认证信息
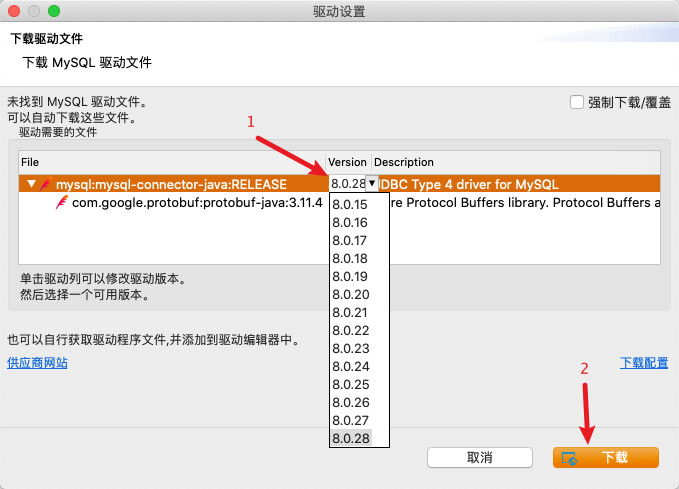
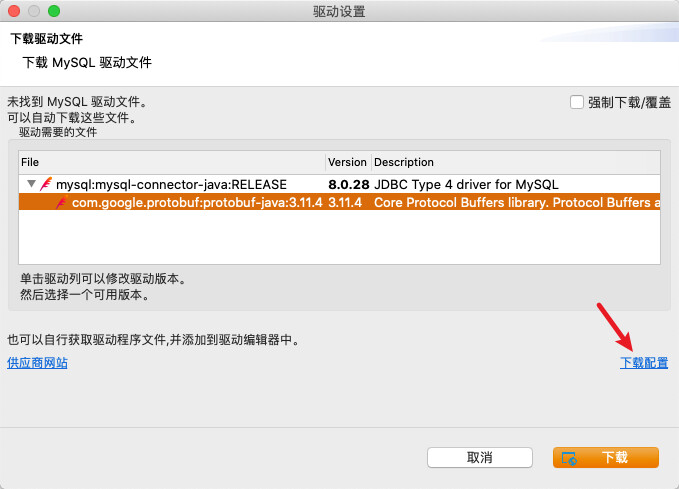
下载MySQL
对应版本的连接驱动,如果以上方法下载超时👉🏻跳转手动下载
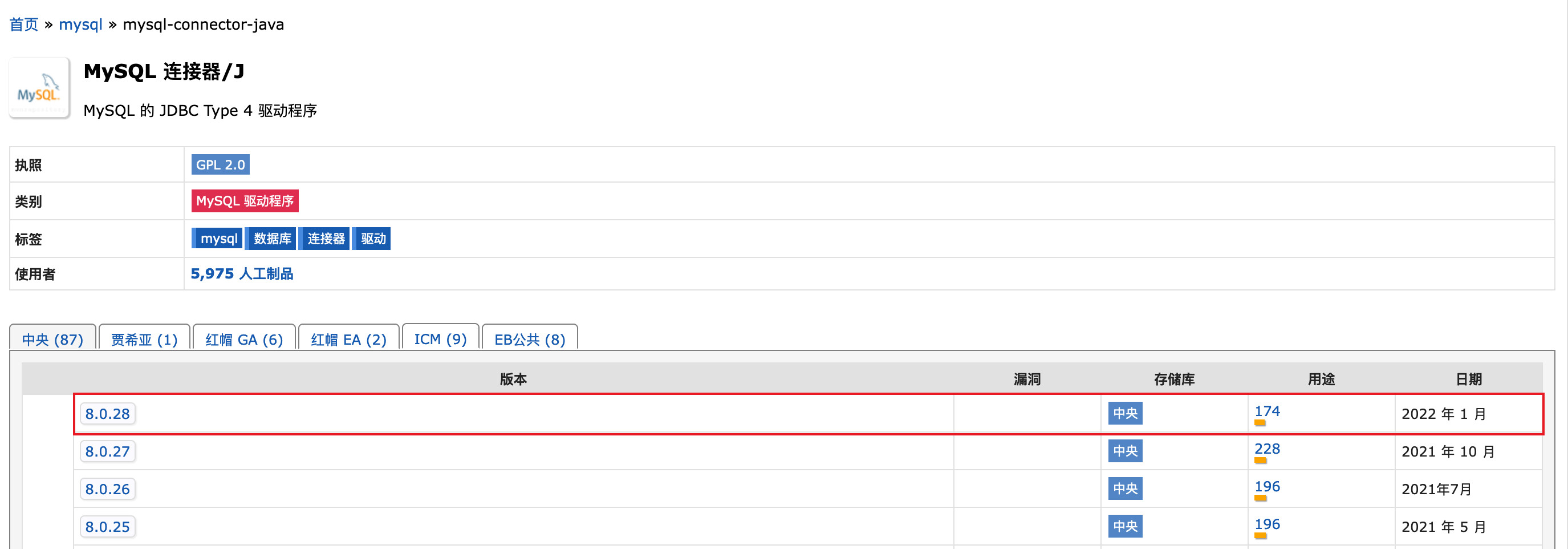
手动下载
咱们到
Maven仓库中手动下载相关jar包
选择对应版本点击
版本号进入详情页
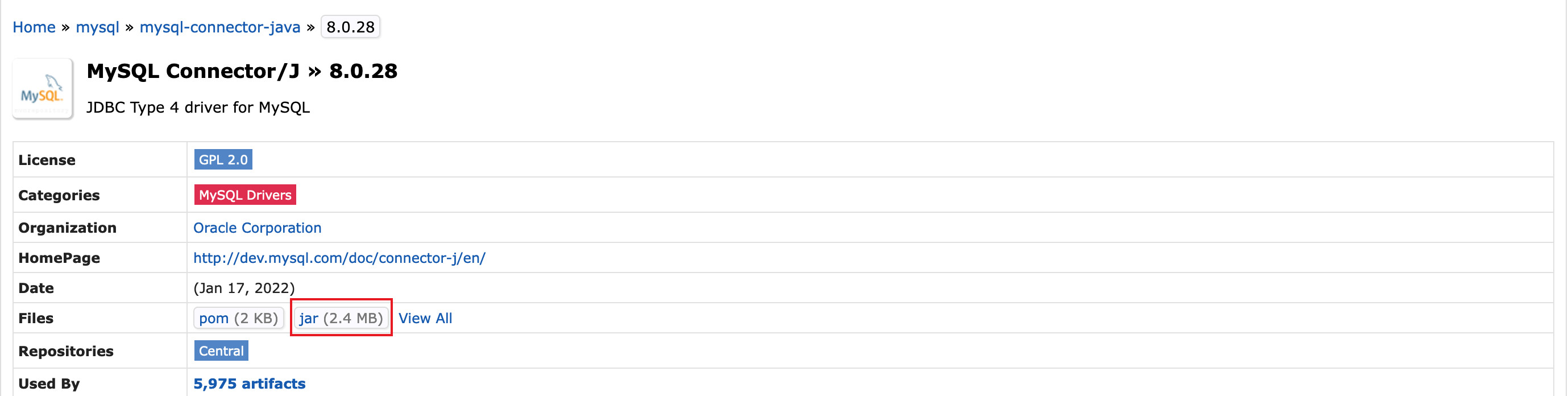
点击
Files -> jar下载jar包
下载完成后还需要下载一个
mysql-connector的依赖protobuf-java,当前依赖页面直接往下拉有一个编译依赖区域,点击protobuf-java版本号进入详情页

如果没有直接可以下载的
jar,需要点击View All

下载对应jar包即可
点击
下载配置查看本地驱动目录
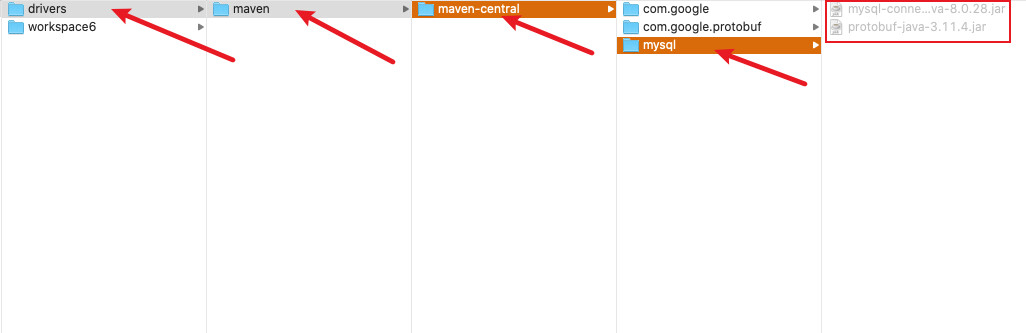
到
drivers下面对应目录把刚刚下载失败的依赖全部删掉,然后把我们刚刚下载的两个jar包放进去📢:
Mac本的兄弟🚪可以用Command+Shift+G开启目录跳转框输入对应地址直接跳转到mysql目录
以上操作全部完成后再回DBeavers连接窗口点击
测试连接即可成功连接了
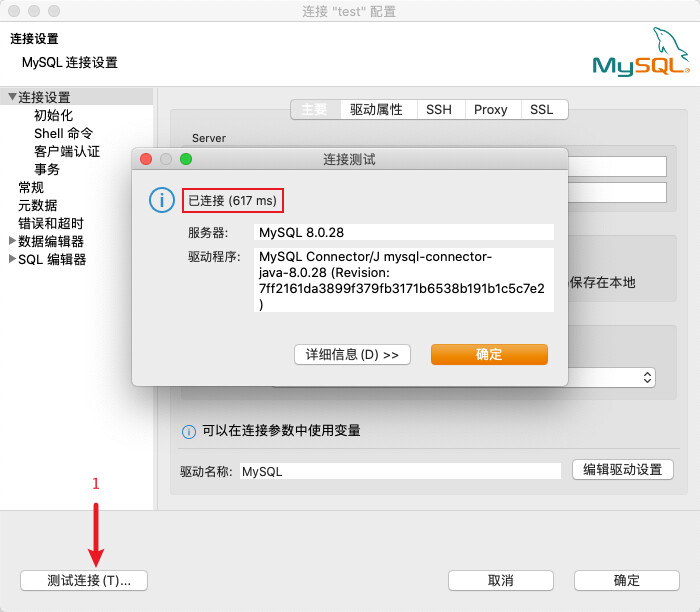
验证是否正常连接并操作数据库

性能监控
查询分析工具
由于MySQL将执行时间精确到了小数点后两位,所以很多语句执行完查看执行时间都是
0.00 sec,这并不代表该语句没有耗时,只是后面的看不到了,那怎么才能看到呢?
临时设置
profiling为1
set profiling=1;
执行需要分析的语句
select * from t;
查看详细耗时
show profiles;
详细步骤结果如下

查看最近一条SQL语句执行信息
show profile;
如果执行了多条SQL语句后想看其他语句的执行信息该怎么看?
show profile for query <Query_ID>;
SHOW PROFILE 语句
SHOW PROFILE [type [, type] ... ]
[FOR QUERY n]
[LIMIT row_count [OFFSET offset]]
*
type*可以指定值[可以写多个,用逗号隔开],显示特定的附加信息类型👇🏻:
| 指令 | 释义 |
|---|---|
ALL | 显示所有信息 |
BLOCK IO | 显示块输入的计数 和输出操作 |
CONTEXT SWITCHES | 显示计数自愿和非自愿上下文切换 |
CPU | 显示用户和系统 CPU 使用率次 |
IPC | 显示已发送消息的计数和已收到 |
MEMORY | 目前未实施 |
PAGE FAULTS | 显示主要的计数和次要页面错误 |
SOURCE | 显示函数的名称来自源代码,连同名称和行号发生函数的文件 |
SWAPS | 显示交换计数 |
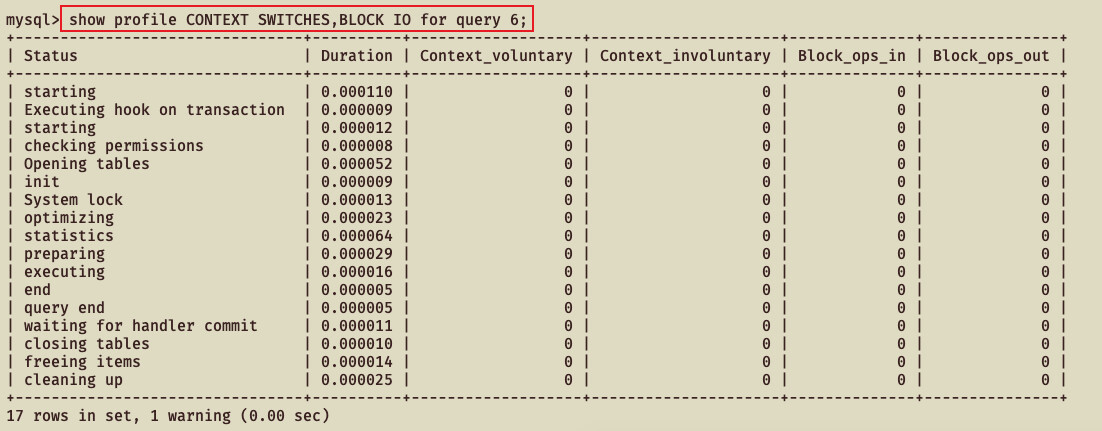
show profile CONTEXT SWITCHES,BLOCK IO for query 6;
Performance Schema
MySQL Performance Schema即MySQL性能模式
查看是否开启性能模式
show databases;

选择
performance_schema表
use performance_schema;
查看
performance_schema的属性
SHOW VARIABLES LIKE 'performance_schema';

性能模式特征
表分类
performance_schema库下的表可以按照监视不同的纬度分组语句事件记录表,这些表记录了语句事件信息,当前语句事件表events_statements_current、历史语句事件表events_statements_history和长语句历史事件表events_statements_history_long、以及聚合后的摘要表summary,其中,summary表还可以根据帐号(account),主机(host),程序(program),线程(thread),用户(user)和全局(global)再进行细分)
show tables like '%statement%';
等待事件记录表,与语句事件类型的相关记录表类似:
show tables like '%wait%';
阶段事件记录表,记录语句执行的阶段事件的表
show tables like '%stage%';
事务事件记录表,记录事务相关的事件的表
show tables like '%transaction%';
监控文件系统层调用的表
show tables like '%file%';
监视内存使用的表
show tables like '%memory%';
动态对performance_schema进行配置的配置表
show tables like '%setup%';
配置与使用
数据库刚刚初始化并启动时,并非所有instruments和consumers都启用了,所以默认不会收集所有的事件,可能你需要检测的事件并没有打开,需要进行设置,可以使用如下两个语句打开对应的instruments和consumers
打开等待事件的采集器配置项开关,需要修改setup_instruments配置表中对应的采集器配置项
UPDATE setup_instruments SET ENABLED = 'YES', TIMED = 'YES'where name like 'wait%';
打开等待事件的保存表配置开关,修改setup_consumers配置表中对应的配置项
UPDATE setup_consumers SET ENABLED = 'YES'where name like '%wait%';
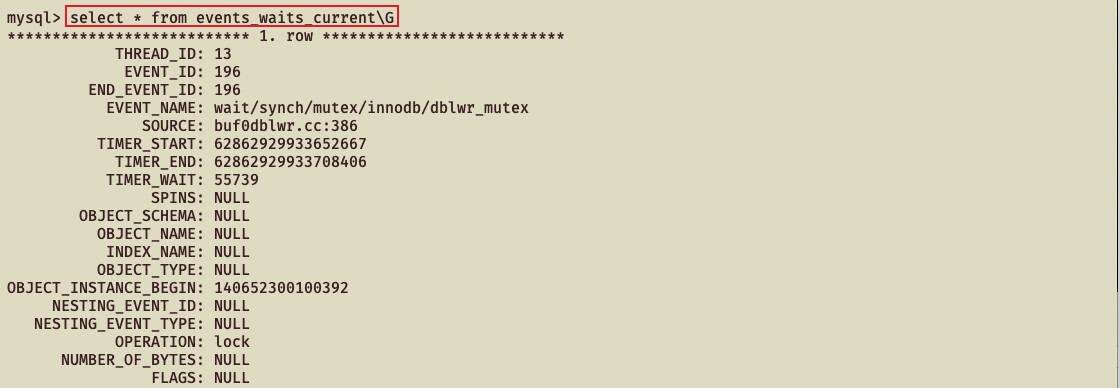
当配置完成之后可以查看当前server正在做什么,可以通过查询events_waits_current表来得知,该表中每个线程只包含一行数据,用于显示每个线程的最新监视事件
字段参数释义👇🏻:
参数 释义 THREAD_ID 事件来自哪个线程,事件编号是多少 EVENT_ID 事件ID EVENT_NAME 表示检测到的具体的内容 SOURCE 表示这个检测代码在哪个源文件中以及行号 TIMER_START 表示该事件的开始时间 TIMER_END 表示该事件的结束时间 TIMER_WAIT 表示该事件总的花费时间
数据库连接监控
查看当前连接信息
show processlist;

表释义
| 列名 | 释义 |
|---|---|
| Id | 连接标识符 |
| User | 发出语句的 MySQL 用户 |
| Host | 发出语句的客户端的主机名 |
| db | 线程的默认数据库,如果没有选择则为NULL |
| Command | 线程代表执行的命令类型客户,如果会话空闲则为 Sleep |
| Time | 线程处于当前状态的时间状态(以秒为单位) |
| State | 指示线程当前状态 |
| Info | 线程正在执行的语句,如果没执行任何语句则为 NULL。 |
Schema与数据类型优化
数据类型优化
-
数据类型最小化
尽量使用可以正确存储数据的最小数据类型,更小的数据类型通常更快,因为它们占用更少的磁盘、内存和CPU缓存,并且处理时需要的CPU周期更少,但是要确保没有低估需要存储的值的范围,如果无法确认哪个数据类型,就选择你认为不会超过范围的最小类型
-
数据类型简单化
简单数据类型的操作通常需要更少的CPU周期:
1、整型比字符操作代价更低,因为字符集和校对规则是字符比较比整型比较更复杂,
2、使用mysql自建类型而不是字符串来存储日期和时间
3、用整型存储IP地址 -
避免使用Null
如果查询中包含可为NULL的列,对mysql来说很难优化,因为可为null的列使得索引、索引统计和值比较都更加复杂,坦白来说,通常情况下null的列改为not null带来的性能提升比较小,所有没有必要将所有的表的schema进行修改,但是应该尽量避免设计成可为null的列
类型选择
整型
尽量使用满足需求的最小数据类型
| 类型 | 存储空间(字节)/(位) |
|---|---|
| TINYINT | 1 / 8 |
| SMALLINT | 2 / 16 |
| MEDIUMINT | 3 / 24 |
| INT | 4 / 32 |
| BIGINT | 8 / 64 |
字符/字符串
varchar
-
根据实际内容长度保存数据
-
使用最小的符合需求的长度
-
varchar(n) n小于等于255使用额外一个字节保存长度,n>255使用额外两个字节保存长度
-
varchar(5)与varchar(255)保存同样的内容,硬盘存储空间相同,但内存空间占用不同,是指定的大小
-
varchar在
mysql5.6之前变更长度,从255以下变更到255以上时会导致锁表
-
-
应用场景
-
存储长度波动较大的数据,如:文章,有的会很短有的会很长
-
字符串很少用于更新的场景,每次更新后都会重算并使用额外存储空间保存长度
-
适合保存多字节字符,如:汉字,特殊字符等
-
char
-
固定长度的字符串
-
最大长度:255
-
会自动删除末尾的空格
-
检索效率、写效率 会比varchar高,以空间换时间
-
-
应用场景
- 存储长度波动不大的数据,如:md5摘要
- 存储短字符串、经常更新的字符串
blob & text
mysql把每个 BLOB 和 TEXT 值当作一个独立的对象处理。
两者都是为了存储很大数据而设计的字符串类型,分别采用二进制和字符方式存储。
时间类型
datetime
- 占8字节存储空间
- 与时区无关,数据库底层时区配置,对datetime无效
- 可保存到毫秒
- 可保存时间范围大
- 不要使用字符串存储日期类型,占用空间大,损失日期类型函数的便捷性
timestamp
- 占4个字节存储空间
- 时间范围:1970-01-01到2038-01-19
- 采用整形存储,精确到秒
- 依赖数据库设置的时区
- 自动更新timestamp列的值
date
- 占用3字节存储空间
- 可以利用日期时间函数进行日期之间的计算
- 用于保存1000-01-01到9999-12-31之间的日期
枚举类型
有时可以使用枚举类
代替常用的字符串类型,mysql存储枚举类型会非常紧凑,会根据列表值的数据压缩到1-2字节中,mysql在内部会将每个值在列表中的位置保存为整数,并且在表的 xxx.frm文件中保存“数字-字符串”映射关系的查找表
验证
创建枚举表
create table enum_test(e enum('fish','apple','dog') not null);
插入映射数据
insert into enum_test(e) values('fish'),('dog'),('apple');
查询枚举表所有映射
select * from enum_test;
+-------+
| e |
+-------+
| fish |
| dog |
| apple |
+-------+
3 rows in set (0.00 sec)
查询枚举表枚举数为
1的枚举字符串映射值
select * from enum_test where e = 1;
+------+
| e |
+------+
| fish |
+------+
1 row in set (0.00 sec)
查询枚举表枚举字符串值为
apple的映射
select * from enum_test where e = 'apple';
+-------+
| e |
+-------+
| apple |
+-------+
1 row in set (0.00 sec)
特殊类型
我们常用
varchar(15)来存储ip地址,然而,它的本质是32位无符号整数不是字符串,可以使用INET_ATON()和INET_NTOA函数在这两种表示方法之间转换
验证
select inet_aton('127.0.0.1');
+------------------------+
| inet_aton('127.0.0.1') |
+------------------------+
| 2130706433 |
+------------------------+
1 row in set (0.00 sec)
select inet_ntoa(2130706433);
+-----------------------+
| inet_ntoa(2130706433) |
+-----------------------+
| 127.0.0.1 |
+-----------------------+
1 row in set (0.00 sec)
范式和反范式
要想很好的做到严格意义上的范式或者反范式,一般需要混合使用
范式
优点
- 范式化的更新通常比反范式要快
- 当数据较好的范式化后,很少或者没有重复的数据
- 范式化的数据比较小,可以放在内存中,操作比较快
缺点
- 需要进行关联
反范式
优点
- 所有的数据都在同一张表中,可以避免关联
- 可以设计有效的索引
缺点
- 表格内的冗余较多,删除数据时候会造成表有些有用的信息丢失
案例
范式设计
表设计
用户表
CREATE TABLE `user` (
`user_id` int NOT NULL AUTO_INCREMENT COMMENT '用户ID',
`name` varchar(64) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '姓名',
`phone` varchar(16) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '电话',
`address` varchar(256) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '地址',
`zip_code` varchar(16) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '邮编',
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户表';
订单表
CREATE TABLE `order` (
`order_id` int NOT NULL AUTO_INCREMENT COMMENT '订单ID',
`user_id` int NOT NULL COMMENT '用户ID',
`place_order_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '下单时间',
`payment_type` char(1) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '支付类型',
`status` char(1) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`),
KEY `order_FK` (`user_id`),
CONSTRAINT `order_FK` FOREIGN KEY (`user_id`) REFERENCES `user` (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='订单表';
商品表
CREATE TABLE `goods` (
`goods_id` int NOT NULL AUTO_INCREMENT COMMENT '商品ID',
`name` varchar(100) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '名称',
`description` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '描述',
`expiration_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '过期时间',
PRIMARY KEY (`goods_id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='商品表';
订单商品表
CREATE TABLE `order_list` (
`order_id` int NOT NULL COMMENT '订单ID',
`goods_Id` int NOT NULL COMMENT '商品ID',
`number` varchar(100) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '商品数量',
`price` double DEFAULT NULL COMMENT '商品价格',
KEY `order_list_FK` (`order_id`),
KEY `order_list_FK_1` (`goods_Id`),
CONSTRAINT `order_list_FK` FOREIGN KEY (`order_id`) REFERENCES `order` (`order_id`),
CONSTRAINT `order_list_FK_1` FOREIGN KEY (`goods_Id`) REFERENCES `goods` (`goods_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='订单商品表';
数据插入
INSERT INTO `order` (user_id,place_order_time,payment_type,status) VALUES (1,'2022-05-24 06:56:35','1','1');
INSERT INTO `user` (name,phone,address,zip_code) VALUES ('RhysNi','18888888888','上海浦东新区','000000');
INSERT INTO goods (name,description,expiration_time) VALUES ('MacPro','电脑','2022-06-06 00:00:00');
INSERT INTO order_list (order_id,goods_Id,`number`,price) VALUES (2,1,'2',14899.23);
查询语句
select
u.name ,
u.phone ,
u.address ,
o.order_id ,
SUM(ol.price * ol.`number`) as order_price
from
`order` o
JOIN `user` u ON
o.user_id = u.user_id
JOIN order_list ol ON
ol.order_id = o.order_id
GROUP BY
u.user_id ,
u.phone ,
u.address ,
o.order_id;
反范式设计
表设计
订单表设计修改
ALTER TABLE `order` ADD order_price DOUBLE NULL;
ALTER TABLE `order` ADD user_name varchar(64) NULL COMMENT '是用户名';
ALTER TABLE `order` ADD phone varchar(16) NULL COMMENT '电话';
ALTER TABLE `order` ADD address varchar(256) NULL COMMENT '地址';
数据更新
数据更新
UPDATE `order` SET order_price=14231.23,user_name='RhysNi',phone='1888888888',address='上海浦东新区';
查询语句
select
o.user_name ,
o.phone ,
o.address ,
o.order_id ,
o.order_price
from
`order` o;
主键
代理主键
与业务无关的,无意义的数字序列
- 例如主键生成器
- 与业务无耦合,易于维护
- 大多数表甚至全部表都使用通用的键策略能够减少编码量,减少系统的成本
自然主键
事物属性中的自然唯一标识
- 身份证
字符集
- 纯拉丁字符能表示的内容,没必要选择 latin1 之外的其他字符编码,因为这会节省大量的存储空间。
- 如果不需要存放多种语言,就没必要非得使用UTF8或者其他UNICODE字符类型,这回造成大量的存储空间浪费。
- MySQL的数据类型可以精确到字段,所以当我们需要大型数据库中存放多字节数据的时候,可以通过对不同表不同字段使用不同的数据类型来较大程度减小数据存储量,进而降低 IO 操作次数并提高缓存命中率。
存储引擎
| InnoDB | MyISAM | |
|---|---|---|
| 索引类型 | 聚簇索引 | 非聚簇索引 |
| 支持事务 | 是 | 否 |
| 支持表锁 | 是 | 是 |
| 支持行锁 | 是 | 否 |
| 支持外键 | 是 | 否 |
| 支持全文索引 | 5.6后支持 | 是 |
| 适合场景 | 大量Insert、Delete、Update | 大量Select |
数据冗余
- 被频繁引用且只能通过 Join 2张(或者更多)大表的方式才能得到的独立小字段,这样的场景可以适当地存在数据冗余
- 由于每次Join仅仅只是为了取得某个小字段的值,Join到的记录又大,会造成大量不必要的 IO,完全可以通过空间换取时间的方式来优化。不过,冗余的同时需要确保数据的一致性不会遭到破坏,确保更新的同时冗余字段也被更新
表拆分
当我们的表中存在类似于 TEXT 或者是很大的 VARCHAR类型的大字段的时候,如果我们大部分访问这张表的时候都不需要这个字段,我们就该义无反顾的将其拆分到另外的独立表中,以减少常用数据所占用的存储空间。这样做的一个明显好处就是每个数据块中可以存储的数据条数可以大大增加,既减少物理 IO 次数,也能大大提高内存中的缓存命中率。
执行计划
咱们为了知道优化SQL语句的执行,需要查看SQL语句的具体执行过程,以加快SQL语句的执行效率。
可以使用explain+SQL语句来模拟优化器执行SQL查询语句,从而知道mysql是如何处理sql语句的。
explain select * from `order`;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | order | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
计划输出字段释义
| 列名 | 释义 |
|---|---|
id | SELECT标识符 |
select_type | SELECT类型 |
table | 输出行所属表名 |
partitions | 匹配的分区 |
type | 联接类型 |
possible_keys | 可供选择的索引 |
key | 实际选择的索引 |
key_len | 所选密钥的长度 |
ref | 与索引比较的列 |
rows | 预计要检查的行数 |
filtered | 按表条件过滤的行百分比 |
Extra | 附加信息 |
字段场景分析-----后补案例
-
id
select 查询的序列号,包含一组数字,标识查询中执行子查询或者操作表的顺序
id相同:从上到下顺序执行id不同:子查询id序号会递增,id值越大优先级越高,越先执行。id同时存在相同的和不同的序列号:相同的可以认为是一组,从上往下顺序执行,在所有组中,id越大越先执行。
-
select_type
主要用来分辨查询的类型,是普通查询还是联合查询还是子查询
类型值 释义 SIMPLE简单的SELECT(不使用UNION或子查询) PRIMARY外层的选择 UNION一个UNION中的第二个或以后的SELECT语句 DEPENDENT UNION一个UNION中的第二个或更高的SELECT语句,依赖于外部查询 UNION RESULTUNION的结果 SUBQUERY子查询中的第一个SELECT DEPENDENT SUBQUERY第一个SELECT子查询,依赖于外部查询 DERIVED派生表 DEPENDENT DERIVED依赖于另一个表的派生表 MATERIALIZED物化子查询 UNCACHEABLE SUBQUERY一个子查询,其结果不能缓存,必须为外部查询的每一行重新计算 UNCACHEABLE UNION在UNION中属于非缓存子查询的第二个或更晚的选择(参见unacheable subquery) -
table
对应行正在访问哪一个表,表名或者别名,可能是临时表或者union合并结果集
- 如果是具体的表名,则表明从实际的物理表中获取数据,当然也可以是表的别名
- 表名是derivedN的形式,表示使用了id为N的查询产生的衍生表
- 当有union result的时候,表名是union n1,n2等的形式,n1,n2表示参与union的id
-
type
type显示的是访问类型,访问类型表示我是以何种方式去访问我们的数据,最容易想的是全表扫描,直接暴力的遍历一张表去寻找需要的数据,效率非常低下,访问的类型有很多,效率从最好到最坏依次是
system>const>eq_ref>ref>fulltext>ref_or_null>index_merge>unique_subquery>index_subquery>range>index>ALL一般情况下,得保证查询至少达到range级别,最好能达到ref
-
possible_keys
显示可能应用在这张表中的索引,一个或多个,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用
-
key
实际使用的索引,如果为null,则没有使用索引,查询中若使用了覆盖索引,则该索引和查询的select字段重叠
-
key_len
表示索引中使用的字节数,可以通过key_len计算查询中使用的索引长度,在不损失精度的情况下长度越短越好
-
ref
显示索引的哪一列被使用了,如果可能的话,是一个常数
-
rows
根据表的统计信息及索引使用情况,大致估算出找出所需记录需要读取的行数,此参数很重要,直接反应的sql找了多少数据,在完成目的的情况下越少越好
-
extra
包含额外的信息
索引优化
索引的基本知识
索引优点
- 减少服务器扫描的数据量
- 帮助服务器避免排序和临时表
- 将随机IO变成顺序IO
索引用处
- 快速查找匹配Where子句的行
- 从考虑中消除行。如果要在多个索引之间进行选择,MySQL通常使用找到行数最少的那个索引(选择性最高的索引)。
- 当有表连接的时候,从其他表检索行数据
- 查找特定索引列的min或max值
- 如果排序或分组时在可用索引的最左前缀上完成的,则对表进行排序和分组
- 在某些情况下,可以优化查询以检索值而无需查询数据行
索引分类
- 主键索引
- 唯一索引
- 普通索引
- 全文索引
- 组合索引
索引数据结构
哈希表
B+树
回表

B+Tree在数据新增过程中是通过分裂合并的形式,经过一系列分裂合并后,原来存在于某指针地址的数据已经被分裂合并到其他地址中,使用原有指针去查找数据是无用的,所以采用回表查找的方式,在辅助索引中叶子结点数据区存放关联的主键id
覆盖索引
创建一个索引,该索引包含查询中用到的所有字段,称为“覆盖索引”。
使用覆盖索引,MySQL 只需要通过索引就可以查找和返回查询所需要的数据,而不必在使用索引处理数据之后再进行回表操作。
覆盖索引可以一次性完成查询工作,有效减少IO,提高查询效率。
最左匹配
建立索引 name+age索引
select id where name=? and age=?;如果
where条件后紧跟的条件字段跟索引最左边字段不匹配则不走索引select id where age=?; #针对这种情况要想让两条语句都走索引应该再单独建立一个`占用内存较小的字段为索引`(age)
索引下推
- 减少回表查询次数,提高查询效率
- 将部分上层(服务层)负责的事情,交给了下层(引擎层)去处理。
- 只能用于
range、ref、eq_ref、ref_or_null访问方法;- 只能用于
InnoDB和MyISAM存储引擎及其分区表;- 对存储引擎来说,索引下推只适用于二级索引(也叫辅助索引);
索引匹配方式
测试数据库准备
下载测试数据库
wget https://downloads.mysql.com/docs/sakila-db.zip
安装zip操作命令
yum install -y unzip zip
解压sakila-db.zip
unzip sakila-db.zip
将文件夹拷贝到docker容器的根目录
docker cp sakila-db/ 39b6bfefda87:/
进入docker容器
docker exec -it mysql8 bash
连接mysql
mysql -uroot -p980512@Nsd
依次导入sql脚本
source /sakila-db/sakila-schema.sql
source /sakila-db/sakila-data.sql
查看是否存在sakila数据库
show databases;

选取
sakila作为测试数据库
use sakila;
查看
sakila中的表
show tables;

创建自定义
staffs表
create table staffs(
id int primary key auto_increment,
name varchar(24) not null default '' comment '姓名',
age int not null default 0 comment '年龄',
pos varchar(20) not null default '' comment '职位',
add_time timestamp not null default current_timestamp comment '入职时间'
) charset utf8 comment '员工记录表';
#创建idx_nap索引
alter table staffs add index idx_nap(name, age, pos);
查看索引列表
show index from staffs;

匹配方式详解
全值匹配
全值匹配指的是和索引中的所有列进行匹配
mysql> explain select * from staffs where name = 'July' and age = '23' and pos = 'dev';
# possible_keys列用到idx_nap索引
# ref 由于查询语句中给的是具体值,所以认为用到了3个索引列并且当成常量值来处理,因此rows中只需匹配1行数据,效率最高。
# type级别为ref,级别较高
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
| 1 | SIMPLE | staffs | NULL | ref | idx_nap | idx_nap | 140 | const,const,const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
匹配最左前缀
只匹配前面的几列
mysql> explain select * from staffs where name = 'July' and age = '23';
# ref中索引列数量由查询语句中命中的索引个数决定 因为用到了 name 和 age 两个索引列所以 ref中匹配到了两个索引列
# key_len 索引列所占用的长度
+----+-------------+--------+------------+------+---------------+---------+---------+-------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+---------+---------+-------------+------+----------+-------+
| 1 | SIMPLE | staffs | NULL | ref | idx_nap | idx_nap | 78 | const,const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+---------------+---------+---------+-------------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
#因为只用到了 name 索引列所以 ref中只匹配到了一个索引列
mysql> explain select * from staffs where name = 'July';
+----+-------------+--------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | staffs | NULL | ref | idx_nap | idx_nap | 74 | const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)
匹配列前缀
可以匹配某一列的值的开头部分
mysql> explain select * from staffs where name like 'J%';
# type达到最低要求`range`级别
# Extra:Using index condition 代表用到了索引条件
+----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | staffs | NULL | range | idx_nap | idx_nap | 74 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.01 sec)
# %在前不走索引,所以possible_keys列为NULL
# type为ALL 全表扫描
mysql> explain select * from staffs where name like '%y';
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | staffs | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
匹配范围值
可以查找某一个范围的数据
mysql> explain select * from staffs where name > 'Mary';
#type 为range 代表范围查询
#Extra 中表示用到了部分索引条件
+----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | staffs | NULL | range | idx_nap | idx_nap | 74 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
精确匹配某一列并范围匹配另外一列
可以查询第一列的全部和第二列的部分
mysql> explain select * from staffs where name = 'July' and age > 25;
+----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | staffs | NULL | range | idx_nap | idx_nap | 78 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
#由于索引匹配从左到右有次序匹配的原因,所以跳过age匹配pos是不走pos索引的,这边匹配了name索引,所以 type为ref而ref只有1个const列
mysql> explain select * from staffs where name = 'July' and pos > 25;
+----+-------------+--------+------------+------+---------------+---------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+---------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | staffs | NULL | ref | idx_nap | idx_nap | 74 | const | 1 | 100.00 | Using index condition |
+----+-------------+--------+------------+------+---------------+---------+---------+-------+------+----------+-----------------------+
1 row in set, 2 warnings (0.00 sec)
#此时执行的sql语句是不在乎索引顺序的,因为在执行时会将语句优化,只要索引列都存在会自动调整索引顺序。
mysql> explain select * from staffs where name = 'July' and pos = 'dev' and age = 25;
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
| 1 | SIMPLE | staffs | NULL | ref | idx_nap | idx_nap | 140 | const,const,const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
只访问索引的查询
查询的时候只需要访问索引,不需要访问数据行,本质上就是覆盖索引
mysql> explain select name,age,pos from staffs where name = 'July' and age = 25 and pos = 'dev';
# Extra:Using index代表用到了覆盖索引,不用再执行回表操作
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------------+
| 1 | SIMPLE | staffs | NULL | ref | idx_nap | idx_nap | 140 | const,const,const | 1 | 100.00 | Using index |
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
Hash索引
基于哈希表的实现,只有精确匹配索引所有列的查询才有效
在mysql中,只有memory的存储引擎显式支持哈希索引
哈希索引自身只需存储对应的hash值,所以索引的结构十分紧凑,查找速度非常快
哈希索引的限制
1、哈希索引只包含哈希值和行指针,而不存储字段值,索引不能使用索引中的值来避免读取行
2、哈希索引数据并不是按照索引值顺序存储的,所以无法进行排序
3、哈希索引不支持部分列匹配查找,哈希索引是使用索引列的全部内容来计算哈希值
4、哈希索引支持等值比较查询,但不支持范围查询
5、访问哈希索引的数据非常快,除非有很多哈希冲突,当出现哈希冲突的时候,存储引擎必须遍历链表中的所有行指针,逐行进行比较,直到找到所有符合条件的行
6、哈希冲突比较多的话,维护的代价也会很高
哈希索引使用场景
当需要存储大量的URL,并且根据URL进行搜索查找,如果使用B+树,存储的内容就会很大:
select id from url where url=""也可以利用将url使用
CRC32做哈希,可以使用以下查询方式:
select id fom url where url="" and url_crc=CRC32("")此查询性能较高原因是使用体积很小的索引来完成查找
组合索引
当包含多个列作为索引,需要注意的是正确的顺序依赖于该索引的查询,同时需要考虑如何更好的满足排序和分组的需要
使用方法解析
现有组合索引 index(a,b,c)
| 语句 | 是否走索引 |
|---|---|
| where a = 3 | 是,只用了a |
| where a = 3 and b=5 | 是,使用了a,b |
| where a = 3 and b=5 and c=4 | 是,使用了a,b,c |
| where a = 3 or where c=4 | 否 |
| where a = 3 and c=4 | 是,只用了a |
| where a = 3 and b>10 and c=7 | 是,使用了a,b |
| where a = 3 and b like ‘%RhysNi%’ and c=7 | 是,只用了a |
聚簇索引&非聚簇索引
不是单独的索引类型,而是一种数据存储方式,
聚簇索引
指的是数据行跟相邻的键值紧凑的存储在一起
优点
1、可以把相关数据保存在一起
2、数据访问更快,因为索引和数据保存在同一个树中
3、使用覆盖索引扫描的查询可以直接使用页节点中的主键值
缺点
1、聚簇数据最大限度地提高了IO密集型应用的性能,如果数据全部在内存,那么聚簇索引就没有什么优势
2、插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式
3、更新聚簇索引列的代价很高,因为会强制将每个被更新的行移动到新的位置
4、基于聚簇索引的表在插入新行,或者主键被更新导致需要移动行的时候,可能面临页分裂的问题
5、聚簇索引可能导致全表扫描变慢,尤其是行比较稀疏,或者由于页分裂导致数据存储不连续的时候
非聚簇索引
数据文件跟索引文件分开存放
覆盖索引
如果一个索引包含所有需要查询的字段的值,我们称之为覆盖索引,不是所有类型的索引都可以称为覆盖索引,覆盖索引必须要存储索引列的值,不同的存储实现覆盖索引的方式不同,不是所有的引擎都支持覆盖索引,
memory不支持覆盖索引
优点
1、索引条目通常远小于数据行大小,如果只需要读取索引,那么mysql就会极大的较少数据访问量
2、因为索引是按照列值顺序存储的,所以对于IO密集型的范围查询会比随机从磁盘读取每一行数据的IO要少的多
3、一些存储引擎如MYISAM在内存中只缓存索引,数据则依赖于操作系统来缓存,因此要访问数据需要一次系统调用,这可能会导致严重的性能问题
4、由于INNODB的聚簇索引,覆盖索引对INNODB表特别有用
场景分析1
符合覆盖索引条件场景
mysql> explain select name,age,pos from staffs where name = 'July' and age = 25 and pos = 'dev';
#此时由于查询的字段都是索引列,所以符合覆盖索引条件,Extra为 Using index
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------------+
| 1 | SIMPLE | staffs | NULL | ref | idx_nap | idx_nap | 140 | const,const,const | 1 | 100.00 | Using index |
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
不满足覆盖索引条件
mysql> explain select name,age,pos,add_time from staffs where name = 'July' and age = 25 and pos = 'dev';
#此时查询字段中新增查询字段`add_time` ,由于不是索引列,所以导致覆盖索引条件不满足。Extra为NULL
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
| 1 | SIMPLE | staffs | NULL | ref | idx_nap | idx_nap | 140 | const,const,const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
场景分析2
当发起一个被索引覆盖的查询时,在explain的extra列可以看到using index的信息,此时就使用了覆盖索引
mysql> explain select store_id,film_id from inventory\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: inventory
partitions: NULL
type: index
possible_keys: NULL
key: idx_store_id_film_id
key_len: 3
ref: NULL
rows: 1
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
在大多数存储引擎中,覆盖索引只能覆盖那些只访问索引中
部分列的查询。不过,可以进一步的进行优化,可以使用innodb的二级索引来覆盖查询。例如:actor使用innodb存储引擎,并在
last_name字段有二级索引,虽然该索引的列不包括主键actor_id,但也能够用于对actor_id做覆盖查询
mysql> explain select actor_id,last_name from actor where last_name='HOPPER'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: actor
partitions: NULL
type: ref
possible_keys: idx_actor_last_name
key: idx_actor_last_name
key_len: 182
ref: const
rows: 1
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
MySQL优化细节
-
当使用索引列进行查询的时候尽量不要使用表达式,把计算放到业务层而不是数据库层
#分别执行两条语句查看结果 mysql> select actor_id from actor where actor_id=4; Empty set (0.00 sec) mysql> select actor_id from actor where actor_id+1=5; Empty set (0.00 sec) #分别查看两条语句的执行计划, #从下图可以看出看包含运算的语句虽然执行结果都是相同的,但实际的执行计划是不同的 mysql> explain select actor_id from actor where actor_id=4; mysql> explain select actor_id from actor where actor_id+1=5;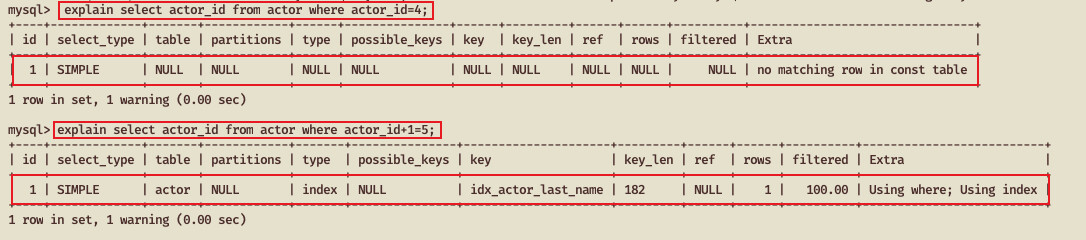
-
尽量使用主键查询,而不是其他索引,因此主键查询不会触发回表查询
前缀索引
有时候需要索引很长的字符串,这会让索引变的大且慢,通常情况下可以使用某个列开始的部分字符串,这样大大的节约索引空间,从而提高索引效率,但这会降低索引的选择性,索引的选择性是指不重复的索引值和数据表记录总数的比值,范围从[0,1]之间。索引的选择性越高则查询效率越高,因为选择性更高的索引可以让mysql在查找的时候过滤掉更多的行。
一般情况下某个列前缀的选择性也是足够高的,足以满足查询的性能,但是对应BLOB,TEXT,VARCHAR类型的列,必须要使用前缀索引,因为mysql不允许索引这些列的完整长度,使用该方法的诀窍在于要选择足够长的前缀以保证较高的选择性,同时又不能太长。
优点
前缀索引是一种能使索引更小更快的有效方法
缺点
mysql无法使用前缀索引做order by 和 group by
场景分析
创建数据表
create table citydemo(city varchar(50) not null);
insert into citydemo(city) select city from city;
重复执行5次下面的sql语句
insert into citydemo(city) select city from citydemo;
查看citydemo表记录数
mysql> select count(*) from citydemo;
+----------+
| count(*) |
+----------+
| 19200 |
+----------+
更新城市表的名称
mysql> update citydemo set city=(select city from city order by rand() limit 1);
#共19200行记录 一条语句需要修改19169行记录
Query OK, 19169 rows affected (10.89 sec)
Rows matched: 19200 Changed: 19169 Warnings: 0
查找最常见的城市列表,发现每个值都出现四五十次
mysql> select count(*) as cnt,city from citydemo group by city order by cnt desc limit 10;
+-----+--------------+
| cnt | city |
+-----+--------------+
| 50 | Loja |
| 49 | Stara Zagora |
| 46 | Baiyin |
| 45 | London |
| 45 | Tongliao |
| 45 | Juiz de Fora |
| 44 | Lilongwe |
| 44 | Crdoba |
| 44 | Botshabelo |
| 44 | Baha Blanca |
+-----+--------------+
10 rows in set (0.02 sec)
前缀长度计算
查找最频繁出现的城市前缀,先从3个前缀字母开始,发现比原来出现的次数更多,可以分别截取多个字符查看城市出现的次数
mysql> select count(*) as cnt,left(city,3) as pref from citydemo group by pref order by cnt desc limit 10;
+-----+------+
| cnt | pref |
+-----+------+
| 471 | San |
| 202 | Cha |
| 165 | Sal |
| 159 | Tan |
| 153 | al- |
| 148 | Sou |
| 139 | Val |
| 138 | Kam |
| 134 | Shi |
| 120 | Man |
+-----+------+
10 rows in set (0.02 sec)
mysql> select count(*) as cnt,left(city,5) as pref from citydemo group by pref order by cnt desc limit 10;
+-----+-------+
| cnt | pref |
+-----+-------+
| 119 | South |
| 104 | Santa |
| 77 | Chang |
| 76 | Xiang |
| 75 | Shimo |
| 69 | San F |
| 66 | Toulo |
| 60 | al-Qa |
| 59 | Saint |
| 59 | Valle |
+-----+-------+
10 rows in set (0.02 sec)
mysql> select count(*) as cnt,left(city,7) as pref from citydemo group by pref order by cnt desc limit 10;
+-----+---------+
| cnt | pref |
+-----+---------+
| 69 | San Fel |
| 59 | Valle d |
| 51 | Santiag |
| 50 | Loja |
| 49 | Stara Z |
| 46 | Baiyin |
| 45 | London |
| 45 | Tonglia |
| 45 | Juiz de |
| 44 | Lilongw |
+-----+---------+
10 rows in set (0.02 sec)
mysql> select count(*) as cnt,left(city,8) as pref from citydemo group by pref order by cnt desc limit 10;
+-----+----------+
| cnt | pref |
+-----+----------+
| 69 | San Feli |
| 59 | Valle de |
| 51 | Santiago |
| 50 | Loja |
| 49 | Stara Za |
| 46 | Baiyin |
| 45 | London |
| 45 | Tongliao |
| 45 | Juiz de |
| 44 | Lilongwe |
+-----+----------+
10 rows in set (0.02 sec)
#发现截取前7个和截取前8个结果相同,因此计算得出当截取前7个作为前缀的选择性接近于完整列的选择性
还可以通过另外一种方式来计算完整列的选择性
mysql> select count(distinct left(city,3))/count(*) as sel3,
-> count(distinct left(city,4))/count(*) as sel4,
-> count(distinct left(city,5))/count(*) as sel5,
-> count(distinct left(city,6))/count(*) as sel6,
-> count(distinct left(city,7))/count(*) as sel7,
-> count(distinct left(city,8))/count(*) as sel8
-> from citydemo;
#可以看到当前缀长度到达7之后,再增加前缀长度,选择性提升的幅度已经很小了
+--------+--------+--------+--------+--------+--------+
| sel3 | sel4 | sel5 | sel6 | sel7 | sel8 |
+--------+--------+--------+--------+--------+--------+
| 0.0239 | 0.0293 | 0.0305 | 0.0309 | 0.0310 | 0.0310 |
+--------+--------+--------+--------+--------+--------+
1 row in set (0.07 sec)
计算完成之后可以创建前缀索引
alter table citydemo add key(city(7));
查看citydemo索引列信息
mysql> show index from citydemo;
#可以看到Sub_part = 7 说明前缀长度为7
#Cardinality(基数)(该值为近似值):某一个单列中唯一的那个值有多少个
#计数值越小代表重复数据越多,在关联查询的时候,所需要检索的数据行越少
#HyperLogLog算法就是用来计算基数值的
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| citydemo | 1 | city | 1 | city | A | 596 | 7 | NULL | | BTREE | | | YES | NULL |
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
1 row in set (0.01 sec)
索引扫描
mysql有两种方式可以生成有序的结果:通过排序操作或者按索引顺序扫描,如果explain出来的type列的值为index,则说明mysql使用了索引扫描来做排序
扫描索引本身是很快的,因为只需要从一条索引记录移动到紧接着的下一条记录。但如果索引不能覆盖查询所需的全部列,那么就不得不每扫描一条索引记录就得回表查询一次对应的行,这基本都是随机IO,因此按索引顺序读取数据的速度通常要比顺序地全表扫描慢
只有当索引的列顺序和order by子句的顺序完全一致,并且所有列的排序方式都一样时,mysql才能够使用索引来对结果进行排序,如果查询需要关联多张表,则只有当orderby子句引用的字段全部为第一张表时,才能使用索引做排序。order by子句和查找型查询的限制是一样的,需要满足索引的最左前缀的要求,否则,mysql都需要执行顺序操作,而无法利用索引排序
场景分析一
文件排序
mysql> explain select * from actor order by first_name;
#Extra = Using filesort 代表使用了文件排序
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| 1 | SIMPLE | actor | NULL | ALL | NULL | NULL | NULL | NULL | 200 | 100.00 | Using filesort |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
1 row in set, 1 warning (0.00 sec)
索引排序
mysql> explain select * from actor order by actor_id;
#type为index级别 因此判定该语句用了索引扫描的方式进行排序
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+
| 1 | SIMPLE | actor | NULL | index | NULL | PRIMARY | 2 | NULL | 200 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
场景分析二
sakila数据库中rental表在rental_date,inventory_id,customer_id上有rental_date的索引
使用rental_date索引为下面的查询做排序
mysql> explain select rental_id,staff_id from rental where rental_date='2005-05-25' order by inventory_id,customer_id\G
#MySQL8.0版本
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: rental
partitions: NULL
type: ref
possible_keys: rental_date
key: rental_date
key_len: 5
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
#MySQL5.7版本
#order by子句不满足索引的最左前缀的要求,也可以用于查询排序,这是因为所以第一列被指定为一个常数
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: rental
partitions: NULL
type: ref
possible_keys: rental_date
key: rental_date
key_len: 5
ref: const
rows: 1
filtered: 100.00
Extra: Using index condition
1 row in set, 1 warning (0.00 sec)
当查询条件为索引的第一列提供了常量条件,而使用第二列进行排序,将两个列组合在一起,就形成了索引的最左前缀
mysql> explain select rental_id,staff_id from rental where rental_date='2005-05-25' order by inventory_id asc\G
#MySQL8.0版本降序索引(新特性)
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: rental
partitions: NULL
type: ref
possible_keys: rental_date
key: rental_date
key_len: 5
ref: const
rows: 1
filtered: 100.00
Extra: Backward index scan
1 row in set, 1 warning (0.00 sec)
#MySQL5.7版本
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: rental
partitions: NULL
type: ref
possible_keys: rental_date
key: rental_date
key_len: 5
ref: const
rows: 1
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
下面的查询不会利用索引排序
mysql> explain select rental_id,staff_id from rental where rental_date>'2005-05-25' order by rental_date,inventory_id\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: rental
partitions: NULL
type: ALL
possible_keys: rental_date
key: NULL
key_len: NULL
ref: NULL
rows: 16008
filtered: 50.00
Extra: Using where; Using filesort
1 row in set, 1 warning (0.00 sec)
该查询使用了两中不同的排序方向,但是索引列都是正序排序的
mysql> explain select rental_id,staff_id from rental where rental_date>'2005-05-25' order by inventory_id desc,customer_id asc\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: rental
partitions: NULL
type: ALL
possible_keys: rental_date
key: NULL
key_len: NULL
ref: NULL
rows: 16008
filtered: 50.00
Extra: Using where; Using filesort
1 row in set, 1 warning (0.00 sec)
该查询中引用了一个不在索引中的列
staff_id不是索引列
mysql> explain select rental_id,staff_id from rental where rental_date>'2005-05-25' order by inventory_id,staff_id\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: rental
partitions: NULL
type: ALL
possible_keys: rental_date
key: NULL
key_len: NULL
ref: NULL
rows: 16008
filtered: 50.00
Extra: Using where; Using filesort
1 row in set, 1 warning (0.00 sec)
union all,in,or都能够使用索引,但是推荐使用in
#分别执行 union all,in,or的查询语句
mysql> explain select * from actor where actor_id = 1 union all select * from actor where actor_id = 2;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | PRIMARY | actor | NULL | const | PRIMARY | PRIMARY | 2 | const | 1 | 100.00 | NULL |
| 2 | UNION | actor | NULL | const | PRIMARY | PRIMARY | 2 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
2 rows in set, 1 warning (0.00 sec)
mysql> explain select * from actor where actor_id in (1,2);
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | actor | NULL | range | PRIMARY | PRIMARY | 2 | NULL | 2 | 100.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from actor where actor_id = 1 or actor_id =2;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | actor | NULL | range | PRIMARY | PRIMARY | 2 | NULL | 2 | 100.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
#临时设置`profiling`为`1` 准备对比执行时间
mysql> set profiling=1;
Query OK, 0 rows affected, 1 warning (0.00 sec)
#分别执行三条不同的查询语句
mysql> select * from actor where actor_id = 1 union all select * from actor where actor_id = 2;
+----------+------------+-----------+---------------------+
| actor_id | first_name | last_name | last_update |
+----------+------------+-----------+---------------------+
| 1 | PENELOPE | GUINESS | 2006-02-15 04:34:33 |
| 2 | NICK | WAHLBERG | 2006-02-15 04:34:33 |
+----------+------------+-----------+---------------------+
2 rows in set (0.00 sec)
mysql> select * from actor where actor_id in (1,2);
+----------+------------+-----------+---------------------+
| actor_id | first_name | last_name | last_update |
+----------+------------+-----------+---------------------+
| 1 | PENELOPE | GUINESS | 2006-02-15 04:34:33 |
| 2 | NICK | WAHLBERG | 2006-02-15 04:34:33 |
+----------+------------+-----------+---------------------+
2 rows in set (0.00 sec)
mysql> select * from actor where actor_id = 1 or actor_id =2;
+----------+------------+-----------+---------------------+
| actor_id | first_name | last_name | last_update |
+----------+------------+-----------+---------------------+
| 1 | PENELOPE | GUINESS | 2006-02-15 04:34:33 |
| 2 | NICK | WAHLBERG | 2006-02-15 04:34:33 |
+----------+------------+-----------+---------------------+
2 rows in set (0.00 sec)
#查看各语句执行耗时,发现in是三种查询中耗时最少的,因此推荐使用in来查询
mysql> show profiles;
+----------+------------+-----------------------------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+-----------------------------------------------------------------------------------------+
| 1 | 0.00057000 | select * from actor where actor_id = 1 union all select * from actor where actor_id = 2 |
| 2 | 0.00046200 | select * from actor where actor_id in (1,2) |
| 3 | 0.00046275 | select * from actor where actor_id = 1 or actor_id =2 |
+----------+------------+-----------------------------------------------------------------------------------------+
3 rows in set, 1 warning (0.00 sec)
范围列
- 范围列可以用到索引
- 范围条件是:<、>
- 范围列可以用到索引,但是范围列后面的列无法用到索引,索引最多用于一个范围列
强制类型转换
-
强制类型转换会全表扫描
创建表和索引
create table user(id int,name varchar(10),phone varchar(11)); alter table user add index idx_1(phone); #查看索引是否创建成功 mysql> show index from user; +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | user | 1 | idx_1 | 1 | phone | A | 0 | NULL | NULL | YES | BTREE | | | YES | NULL | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ 1 row in set (0.00 sec)触发索引
mysql> explain select * from user where phone='13800001234'; +----+-------------+-------+------------+------+---------------+-------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-------+---------+-------+------+----------+-------+ | 1 | SIMPLE | user | NULL | ref | idx_1 | idx_1 | 47 | const | 1 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+-------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec)不触发索引
mysql> explain select * from user where phone=13800001234; #因为我们phone字段为字符串类型 这边作为条件时传入的常量值为int类型,触发了强制类型转换导致全表扫描,type为ALL类型 +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | user | NULL | ALL | idx_1 | NULL | NULL | NULL | 1 | 100.00 | Using where | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1 row in set, 3 warnings (0.00 sec)
更新频繁
-
更新十分频繁,数据区分度不高的字段上不宜建立索引
- 更新会变更B+树,更新频繁的字段建议索引会大大降低数据库性能
- 类似于性别这类区分不大的属性,建立索引是没有意义的,不能有效的过滤数据,
- 一般区分度在80%以上的时候就可以建立索引,区分度可以使用
count(distinct(列名))/count(*)来计算
-
创建索引的列,不允许为null,可能会得到不符合预期的结果
Join原理
mysql的关联查询很重要,但其实关联查询执行的策略比较简单:mysql对任何关联都执行嵌套循环关联操作,即mysql先在一张表中循环取出单条数据,然后再嵌套到下一个表中寻找匹配的行,依次下去,直到找到所有表中匹配的行为止。然后根据各个表匹配的行,返回查询中需要的各个列。mysql会尝试再最后一个关联表中找到所有匹配的行,如果最后一个关联表无法找到更多的行之后,mysql返回到上一层次关联表,看是否能够找到更多的匹配记录,以此类推迭代执行。整体的思路如此,但是要注意实际的执行过程中有多个变种形式:
- 当需要进行表连接的时候,最好不要超过三张表,因为需要join的字段,数据类型必须一致
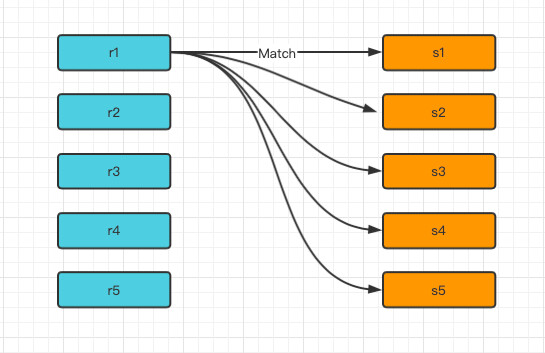
Simple Nested-Loop Join (简单的嵌套循环连接)
r为驱动表,s为匹配表,从r分支中逐条取记录去匹配s表的所有列,然后再合并数据,需要对s表进行r表的行数次访问(访问量 = s表列数 * r表行数),对数据库开销较大
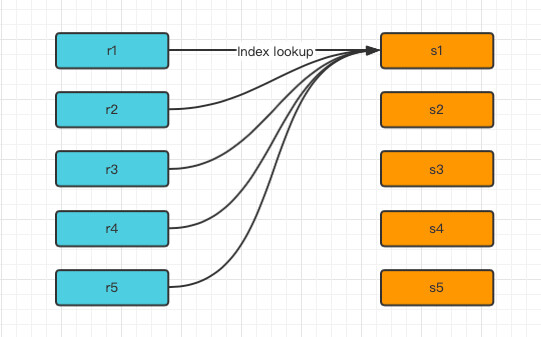
Index Nested-Loop Join(索引嵌套循环连接)
- 要求非驱动表(s 表)上有索引,可以通过索引来减少比较,加速查询
- 在查询时,驱动表(r表)会根据关联字段的索引进行查找,当在索引上找到符合的值,再回表进行查询,也就是只有当匹配到索引以后才会进行回表查询。
- 如果非驱动表(s表)关联键是主键的话,性能会非常高,如果不是主键,要进行多次回表查询,先关联索引,然后根据二级索引的主键ID进行回表操作,性能上比索引是主键要慢
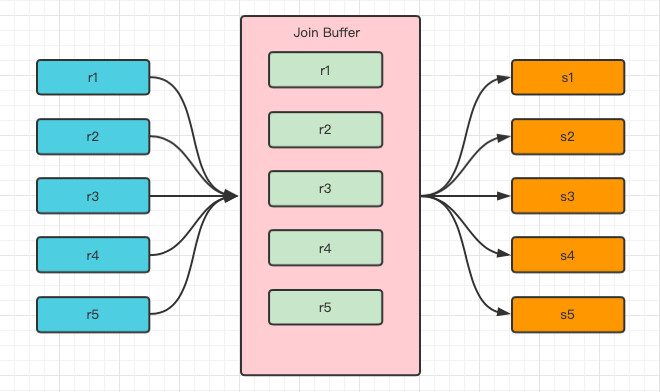
Block Nested-Loop Join (缓存块嵌套循环连接)
- 如果join列有索引则会走索引嵌套循环连接方式,没有索引就会采用缓存块循环嵌套连接,这种连接在驱动表和匹配表之间有一层
Join Bufffer缓冲区,将驱动表的所有join相关的列都先缓存到Join Buffer中,然后批量与匹配表进行匹配,将简单的嵌套循环连接中的多次比较合并成一次,降低了匹配表(s表)的访问频率。- 默认情况下
join_buffer_size=256k,在查找的时候MySQL会将所有的需要的列缓存到Join Buffer中,包括Select的列,而不是只缓存关联列。有可能出现缓存不下的情况,可调整join_buffer_size的值,根据实际情况决定- 在一个有N个Join关联的SQL中会在执行的时候分配N-1个Join Buffer
- join_buffer_size的最大值在MySQL 5.1.22版本前是4G-1,而之后的版本才能在64位操作系统下申请大于4G的Join Buffer空间。
- 使用Block Nested-Loop Join算法需要开启优化器管理配置的optimizer_switch的设置block_nested_loop为on,
默认为开启。
mysql> show variables like '%join_buffer%';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| join_buffer_size | 262144 |
+------------------+--------+
1 row in set (0.01 sec)
mysql> show variables where Variable_name = 'join_buffer_size';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| join_buffer_size | 262144 |
+------------------+--------+
mysql> show variables like '%optimizer_switch%';
+---------------+------+
| Variable_name | Value|
+---------------+------+
|optimizer_switch|index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,`block_nested_loop=on`,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,use_invisible_indexes=off,skip_scan=on,hash_join=on,subquery_to_derived=off,prefer_ordering_index=on,hypergraph_optimizer=off,derived_condition_pushdown=on |
+------------------+---+
1 row in set (0.01 sec)
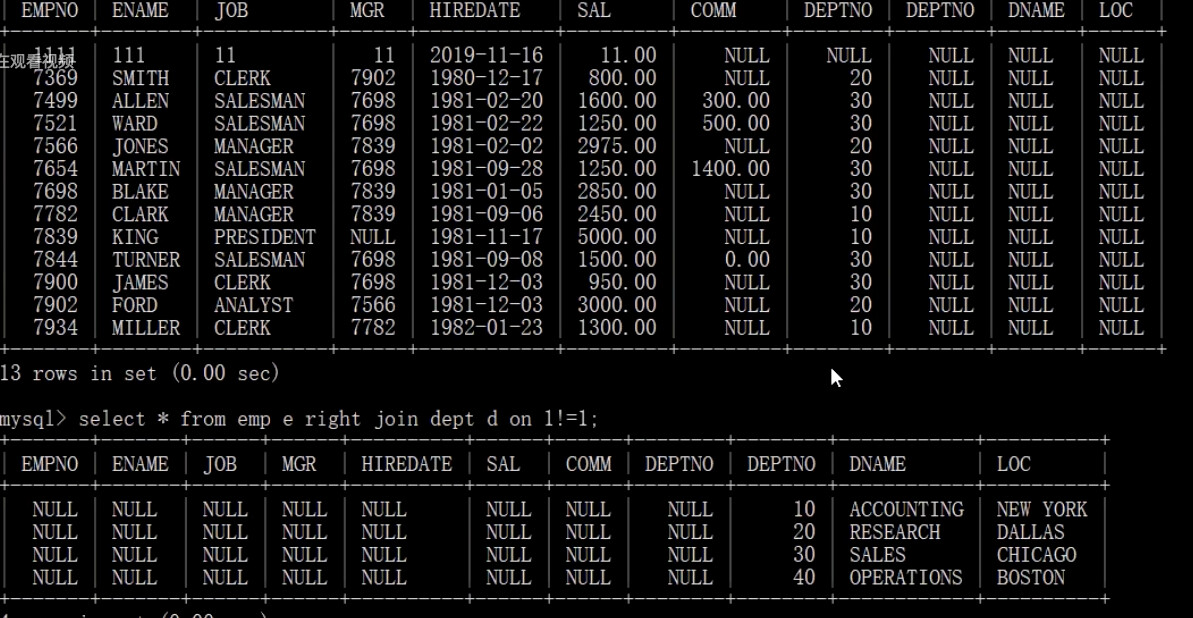
案例分析1
select * from xxx a join xxx b on a.id = b.id and a.id = 10;
select * from xxx a join xxx b on a.id = b.id where a.id = 10;
#结论
#当使用内连接的时候,两种方式结果相同
#当使用左连接时,and会在连接前过滤A表或B表中哪些记录符合连接条件,同时会兼顾是左连接还是右连接,如果是左连接的话,假设左边表的某条记录不符合连接条件,那么他不进行连接,但是仍然留在结果集中(此时右边部分的连接结果为NULL)
#on条件实在生成临时表时使用的条件,他不管on的条件是否为真,都会返回左边表中的记录
#当使用右连接时,右表结果全部显示,左边内容全部为NULL
案例分析2
查看不同的顺序执行方式对查询性能的影响
mysql> explain select film.film_id,film.title,film.release_year,actor.actor_id,actor.first_name,actor.last_name from film inner join film_actor using(film_id) inner join actor using(actor_id);
#共扫描了228行数据
+----+-------------+------------+------------+--------+------------------------+---------+---------+---------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+------------------------+---------+---------+---------------------------+------+----------+-------------+
| 1 | SIMPLE | actor | NULL | ALL | PRIMARY | NULL | NULL | NULL | 200 | 100.00 | NULL |
| 1 | SIMPLE | film_actor | NULL | ref | PRIMARY,idx_fk_film_id | PRIMARY | 2 | sakila.actor.actor_id | 27 | 100.00 | Using index |
| 1 | SIMPLE | film | NULL | eq_ref | PRIMARY | PRIMARY | 2 | sakila.film_actor.film_id | 1 | 100.00 | NULL |
+----+-------------+------------+------------+--------+------------------------+---------+---------+---------------------------+------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
查看执行的成本
mysql> show status like 'last_query_cost';
#最后一个查询所耗费的成本是2529
+-----------------+-------------+
| Variable_name | Value |
+-----------------+-------------+
| Last_query_cost | 2529.432367 |
+-----------------+-------------+
1 row in set (0.00 sec)
强制按照自定义的顺序执行
mysql> explain select straight_join film.film_id,film.title,film.release_year,actor.actor_id,actor.first_name,actor.last_name from film inner join film_actor using(film_id) inner join actor using(actor_id);
#共扫描了1006行数据
+----+-------------+------------+------------+--------+------------------------+----------------+---------+----------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+------------------------+----------------+---------+----------------------------+------+----------+-------------+
| 1 | SIMPLE | film | NULL | ALL | PRIMARY | NULL | NULL | NULL | 1000 | 100.00 | NULL |
| 1 | SIMPLE | film_actor | NULL | ref | PRIMARY,idx_fk_film_id | idx_fk_film_id | 2 | sakila.film.film_id | 5 | 100.00 | Using index |
| 1 | SIMPLE | actor | NULL | eq_ref | PRIMARY | PRIMARY | 2 | sakila.film_actor.actor_id | 1 | 100.00 | NULL |
+----+-------------+------------+------------+--------+------------------------+----------------+---------+----------------------------+------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
查看执行的成本
mysql> show status like 'last_query_cost';
#最后一个查询所耗费的成本是2819
+-----------------+-------------+
| Variable_name | Value |
+-----------------+-------------+
| Last_query_cost | 2819.114608 |
+-----------------+-------------+
1 row in set (0.00 sec)
limit
能使用limit的时候尽量使用limit
使用limit时,查询到结果截止,不会继续往下查找,能提升查询效率
-
单表索引建议控制在5个以内
-
单索引字段数不允许超过5个(组合索引)
-
创建索引的时候应该避免以下错误概念
- 索引越多越好
- 过早优化,在不了解系统的情况下进行优化
索引监控
查询索引读取信息
show status like 'Handler_read%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| Handler_read_first | 11 |
| Handler_read_key | 144 |
| Handler_read_last | 0 |
| Handler_read_next | 129 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 4 |
| Handler_read_rnd_next | 17317 |
+-----------------------+-------+
7 rows in set (0.00 sec)
参数释义
| 参数 | 释义 |
|---|---|
| Handler_read_first | 读取索引第一个条目的次数 |
| Handler_read_key | 通过index获取数据的次数 |
| Handler_read_last | 读取索引最后一个条目的次数 |
| Handler_read_next | 通过索引读取下一条数据的次数 |
| Handler_read_prev | 通过索引读取上一条数据的次数 |
| Handler_read_rnd | 从固定位置读取数据的次数 |
| Handler_read_rnd_next | 从数据节点读取下一条数据的次数 |
索引优化案例
创建订单表与数据
SET FOREIGN_KEY_CHECKS=0;
DROP TABLE IF EXISTS `itdragon_order_list`;
CREATE TABLE `itdragon_order_list` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '主键id,默认自增长',
`transaction_id` varchar(150) DEFAULT NULL COMMENT '交易号',
`gross` double DEFAULT NULL COMMENT '毛收入(RMB)',
`net` double DEFAULT NULL COMMENT '净收入(RMB)',
`stock_id` int(11) DEFAULT NULL COMMENT '发货仓库',
`order_status` int(11) DEFAULT NULL COMMENT '订单状态',
`descript` varchar(255) DEFAULT NULL COMMENT '客服备注',
`finance_descript` varchar(255) DEFAULT NULL COMMENT '财务备注',
`create_type` varchar(100) DEFAULT NULL COMMENT '创建类型',
`order_level` int(11) DEFAULT NULL COMMENT '订单级别',
`input_user` varchar(20) DEFAULT NULL COMMENT '录入人',
`input_date` varchar(20) DEFAULT NULL COMMENT '录入时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10003 DEFAULT CHARSET=utf8;
INSERT INTO itdragon_order_list VALUES ('10000', '81X97310V32236260E', '6.6', '6.13', '1', '10', 'ok', 'ok', 'auto', '1', 'itdragon', '2017-08-28 17:01:49');
INSERT INTO itdragon_order_list VALUES ('10001', '61525478BB371361Q', '18.88', '18.79', '1', '10', 'ok', 'ok', 'auto', '1', 'itdragon', '2017-08-18 17:01:50');
INSERT INTO itdragon_order_list VALUES ('10002', '5RT64180WE555861V', '20.18', '20.17', '1', '10', 'ok', 'ok', 'auto', '1', 'itdragon', '2017-09-08 17:01:49');
优化案例一 - 索引类型优化
mysql> select * from itdragon_order_list where transaction_id = "81X97310V32236260E";
+-------+--------------------+-------+------+----------+--------------+----------+------------------+-------------+-------------+------------+---------------------+
| id | transaction_id | gross | net | stock_id | order_status | descript | finance_descript | create_type | order_level | input_user | input_date |
+-------+--------------------+-------+------+----------+--------------+----------+------------------+-------------+-------------+------------+---------------------+
| 10000 | 81X97310V32236260E | 6.6 | 6.13 | 1 | 10 | ok | ok | auto | 1 | itdragon | 2017-08-28 17:01:49 |
+-------+--------------------+-------+------+----------+--------------+----------+------------------+-------------+-------------+------------+---------------------+
1 row in set (0.00 sec)
#通过查看执行计划发现type=all,需要进行全表扫描
mysql> explain select * from itdragon_order_list where transaction_id = "81X97310V32236260E";
+----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | itdragon_order_list | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where |
+----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
优化一
为transaction_id创建唯一索引
mysql> create unique index idx_order_transaID on itdragon_order_list (transaction_id);
Query OK, 0 rows affected (0.10 sec)
Records: 0 Duplicates: 0 Warnings: 0
验证
mysql> explain select * from itdragon_order_list where transaction_id = "81X97310V32236260E";
#当创建索引之后,唯一索引对应的type是const,通过索引一次就可以找到结果,const的性能要高于All
+----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | itdragon_order_list | NULL | const | idx_order_transaID | idx_order_transaID | 453 | const | 1 | 100.00 | NULL |
+----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
优化二
使用覆盖索引
mysql> explain select transaction_id from itdragon_order_list where transaction_id = "81X97310V32236260E";
#查询的结果变成 transaction_id,当extra出现using index,表示使用了覆盖索引
+----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | itdragon_order_list | NULL | const | idx_order_transaID | idx_order_transaID | 453 | const | 1 | 100.00 | Using index |
+----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
优化案例二 - 索引排序优化
创建联合索引
mysql> create index idx_order_levelDate on itdragon_order_list (order_level,input_date);
Query OK, 0 rows affected (0.10 sec)
Records: 0 Duplicates: 0 Warnings: 0
执行语句查看计划
mysql> explain select * from itdragon_order_list order by order_level,input_date;
#创建索引之后发现跟没有创建索引一样,都是全表扫描,都是文件排序
+----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+----------------+
| 1 | SIMPLE | itdragon_order_list | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | Using filesort |
+----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+----------------+
1 row in set, 1 warning (0.00 sec)
使用force index强制指定索引
mysql> explain select * from itdragon_order_list force index(idx_order_levelDate) order by order_level,input_date;
+----+-------------+---------------------+------------+-------+---------------+---------------------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------------+------------+-------+---------------+---------------------+---------+------+------+----------+-------+
| 1 | SIMPLE | itdragon_order_list | NULL | index | NULL | idx_order_levelDate | 68 | NULL | 3 | 100.00 | NULL |
+----+-------------+---------------------+------------+-------+---------------+---------------------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
给订单排序意义不大,给订单级别添加索引意义也不大,因此可以先确定order_level的值,然后再给input_date排序
mysql> explain select * from itdragon_order_list where order_level=3 order by input_date;
+----+-------------+---------------------+------------+------+---------------------+---------------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------------+------------+------+---------------------+---------------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | itdragon_order_list | NULL | ref | idx_order_levelDate | idx_order_levelDate | 5 | const | 1 | 100.00 | NULL |
+----+-------------+---------------------+------------+------+---------------------+---------------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
查询优化
查询慢的原因
- 网络
- CPU - 时间片切换
- IO
- 上下文切换
- 系统调用
- 生成统计信息
- 锁等待时间
优化数据访问
-
查询性能低下的主要原因是访问的数据太多,某些查询不可避免的需要筛选大量的数据,我们可以通过减少访问数据量的方式进行优化
- 确认应用程序是否在检索大量超过需要的数据
- 确认mysql服务器层是否在分析大量超过需要的数据行
-
是否向数据库请求了不需要的数据
-
查询不需要的记录
-
我们常常会误以为mysql会只返回需要的数据,实际上mysql却是先返回全部结果再进行计算,在日常的开发习惯中,经常是先用select语句查询大量的结果,然后获取前面的N行后关闭结果集。
-
优化方式
在查询后面添加limit
-
-
多表关联时返回全部列
select * from actor inner join film_actor using(actor_id) inner join film using(film_id) where film.title='Academy Dinosaur';
select actor.* from actor inner join film_actor using(actor_id) inner join film using(film_id) where film.title='Academy Dinosaur';
-
总是取出全部列 (禁止使用select *)
-
重复查询相同的数据
如果需要不断的重复执行相同的查询,且每次返回完全相同的数据,
因此,基于这样的应用场景,可以将这部分数据缓存起来,这样的话能够提高查询效率
-
执行过程优化
查询缓存 (MySQL 8.0以后被去除)
在解析一个查询语句之前,如果查询缓存是打开的,那 么mysql会优先检查这个查询是否命中查询缓存中的数据,
如果查询恰好命中了查询缓存,那么会在返回结果之前会检查用户权限,
如果权限没有问题,那么mysql会跳过所有的阶段,就直接从缓存中拿到结果并返回给客户端
查询优化处理
mysql通过关键字将SQL语句进行解析,并生成一颗解析树
mysql解析器将使用mysql语法规则验证和解析查询,例如验证使用了错误的关键字或者顺序是否正确等等,
预处理器会进一步检查解析树是否合法,例如表名和列名是否存在,是否有歧义,还会验证权限等等
语法解析器和预处理
查询优化器
执行查询语句
mysql> select count(*) from film_actor;
+----------+
| count(*) |
+----------+
| 5462 |
+----------+
1 row in set (0.04 sec)
#last_que ry_cost : 最后一个查询所耗费的成本是多少
mysql> show status like 'last_query_cost';
+-----------------+------------+
| Variable_name | Value |
+-----------------+------------+
| Last_query_cost | 549.199000 |
+-----------------+------------+
1 row in set (0.00 sec)
这条查询语句大概需要做549个数据页才能找到对应的数据,这是经过一系列的统计信息计算来的,包括如下数据:
每个表或者索引的页面个数
索引的基数
索引和数据行的长度
索引的分布情况
-
在很多情况下mysql会选择错误的执行计划,原因如下:
- 统计信息不准确
- InnoDB因为其mvcc的架构,并不能维护一个数据表的行数的精确统计信息
- 执行计划的成本估算不等同于实际执行的成本
- 有时候某个执行计划虽然需要读取更多的页面,但是他的成本却更小,因为如果这些页面都是顺序读或者这些页面都已经在内存中的话,那么它的访问成本将很小,mysql层面并不知道哪些页面在内存中,哪些在磁盘,所以查询之际执行过程中到底需要多少次IO是无法得知的
- mysql的最优可能跟你想的不一样
- mysql的优化是基于成本模型的优化,但是有可能不是最快的优化
- mysql不考虑其他并发执行的查询
- mysql不会考虑不受其控制的操作成本
- 执行存储过程或者用户自定义函数的成本
- 统计信息不准确
优化器的优化策略
mysql对查询的静态优化只需要一次,但对动态优化在每次执行时都需要重新评估
静态优化
直接对解析树进行分析,并完成优化
动态优化
动态优化与查询的上下文有关,也可能跟取值、索引对应的行数有关
优化器的优化类型
-
重新定义关联表的顺序
数据表的关联并不总是按照在查询中指定的顺序进行,决定关联顺序时优化器是很重要的功能
-
将外连接转化成内连接,内连接的效率要高于外连接
-
使用等价变换规则,mysql可以使用一些等价变化来简化并规划表达式
-
优化count(),min(),max()
索引和列是否可以为空通常可以帮助mysql优化这类表达式:例如,要找到某一列的最小值,只需要查询索引的最左端的记录即可,不需要全文扫描比较
-
预估并转化为常数表达式,当mysql检测到一个表达式可以转化为常数的时候,就会一直把该表达式作为常数进行处理
explain select film.film_id,film_actor.actor_id from film inner join film_actor using(film_id) where film.film_id = 1; +----+-------------+------------+------------+-------+----------------+----------------+---------+-------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+------------+------------+-------+----------------+----------------+---------+-------+------+----------+-------------+ | 1 | SIMPLE | film | NULL | const | PRIMARY | PRIMARY | 2 | const | 1 | 100.00 | Using index | | 1 | SIMPLE | film_actor | NULL | ref | idx_fk_film_id | idx_fk_film_id | 2 | const | 10 | 100.00 | Using index | +----+-------------+------------+------------+-------+----------------+----------------+---------+-------+------+----------+-------------+ 2 rows in set, 1 warning (0.00 sec) -
索引覆盖扫描,当索引中的列包含所有查询中需要使用的列的时候,可以使用覆盖索引
-
子查询优化
mysql在某些情况下可以将子查询转换一种效率更高的形式,从而减少多个查询多次对数据进行访问,例如将经常查询的数据放入到缓存中
-
等值传播
如果两个列的值通过等式关联,那么mysql能够把其中一个列的where条件传递到另一个上
mysql> explain select film.film_id from film inner join film_actor using(film_id) where film.film_id > 500; +----+-------------+------------+------------+-------+----------------+----------------+---------+---------------------+------+----------+--------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+------------+------------+-------+----------------+----------------+---------+---------------------+------+----------+--------------------------+ | 1 | SIMPLE | film | NULL | range | PRIMARY | PRIMARY | 2 | NULL | 500 | 100.00 | Using where; Using index | | 1 | SIMPLE | film_actor | NULL | ref | idx_fk_film_id | idx_fk_film_id | 2 | sakila.film.film_id | 5 | 100.00 | Using index | +----+-------------+------------+------------+-------+----------------+----------------+---------+---------------------+------+----------+--------------------------+ 2 rows in set, 1 warning (0.00 sec)这里使用film_id字段进行等值关联,film_id这个列不仅适用于film表而且适用于film_actor表
explain select film.film_id from film inner join film_actor using(film_id) where film.film_id > 500 and film_actor.film_id > 500; +----+-------------+------------+------------+-------+----------------+----------------+---------+---------------------+------+----------+--------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+------------+------------+-------+----------------+----------------+---------+---------------------+------+----------+--------------------------+ | 1 | SIMPLE | film | NULL | range | PRIMARY | PRIMARY | 2 | NULL | 500 | 100.00 | Using where; Using index | | 1 | SIMPLE | film_actor | NULL | ref | idx_fk_film_id | idx_fk_film_id | 2 | sakila.film.film_id | 5 | 100.00 | Using index | +----+-------------+------------+------------+-------+----------------+----------------+---------+---------------------+------+----------+--------------------------+ 2 rows in set, 1 warning (0.00 sec)
关联查询
排序优化
排序是一个成本很高的操作,所以从性能的角度出发,应该尽可能避免排序或者尽可能避免对大量数据进行排序。推荐利用索引进行排序.
但是当不能使用索引的时候,mysql就需要自己进行排序,如果数据量小则再内存中进行,如果数据量大就需要使用磁盘mysql中称之为filesort。
如果需要排序的数据量小于排序缓冲区(show variables like '%sort_buffer_size%';),mysql使用内存进行快速排序操作
如果内存不够排序,那么mysql就会先将树分块,对每个独立的块使用快速排序进行排序,并将各个块的排序结果存放再磁盘上,然后将各个排好序的块进行合并,最后返回排序结果
排序的算法
当需要排序的列的总大小超过max_length_for_sort_data定义的字节,mysql会选择双次排序,反之使用单次排序,当然,用户可以设置此参数的值来选择排序的方式
mysql> show variables like '%max_length_for_sort_data%'; #mysql8默认4096字节 #5默认1024字节 +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | max_length_for_sort_data | 4096 | +--------------------------+-------+ 1 row in set (0.00 sec)
-
两次传输排序
-
第一次数据读取是将需要排序的字段读取出来,然后进行排序,
-
第二次是将排好序的结果按照需要去读取数据行。
这种方式效率比较低,因为第二次读取数据的时候已经排好序,需要去读取所有记录而此时更多的是
随机IO,读取数据成本会比较高两次传输的优势,在排序的时候存储尽可能少的数据,让排序缓冲区可以尽可能多的容纳行数来进行排序操作
-
-
单次传输排序
- 先读取查询所需要的所有列,然后再根据给定列进行排序,最后直接返回排序结果,此方式只需要一次顺序IO读取所有的数据,而无须任何的随机IO,问题在于查询的列特别多的时候,会占用大量的存储空间,无法存储大量的数据
优化特定类型的查询
优化count()查询
count()是特殊的函数,有两种不同的作用,一种是某个列值的数量,也可以统计行数
- count(*) 、count(1) 、 count(rental_id) 开销和结果都相同
#count(*)统计行数结果以及开销
mysql> select count(*) from rental;
+----------+
| count(*) |
+----------+
| 16044 |
+----------+
1 row in set (0.04 sec)
mysql> show status like 'last_query_cost';
+-----------------+-------------+
| Variable_name | Value |
+-----------------+-------------+
| Last_query_cost | 1625.049000 |
+-----------------+-------------+
1 row in set (0.01 sec)
#count(1)统计行数结果以及开销
mysql> select count(1) from rental;
+----------+
| count(1) |
+----------+
| 16044 |
+----------+
1 row in set (0.03 sec)
mysql> show status like 'last_query_cost';
+-----------------+-------------+
| Variable_name | Value |
+-----------------+-------------+
| Last_query_cost | 1625.049000 |
+-----------------+-------------+
1 row in set (0.01 sec)
#count(rental_id)统计行数结果以及开销
mysql> select count(rental_id) from rental;
+------------------+
| count(rental_id) |
+------------------+
| 16044 |
+------------------+
1 row in set (0.02 sec)
mysql> show status like 'last_query_cost';
+-----------------+-------------+
| Variable_name | Value |
+-----------------+-------------+
| Last_query_cost | 1625.049000 |
+-----------------+-------------+
1 row in set (0.00 sec)
统计列值的数量
#统计列值的数量及开销
#因为`return_date`列存在NULL值,所以自动忽略NULL值列
mysql> select count(return_date) from rental;
+--------------------+
| count(return_date) |
+--------------------+
| 15861 |
+--------------------+
1 row in set (0.00 sec)
mysql> show status like 'last_query_cost';
+-----------------+-------------+
| Variable_name | Value |
+-----------------+-------------+
| Last_query_cost | 1625.049000 |
+-----------------+-------------+
1 row in set (0.00 sec)
-
总有人认为MyISAM的count函数比较快,这是有前提条件的,只有没有任何where条件的count(*)才是比较快的
-
使用近似值
在某些应用场景中,不需要完全精确的值,可以参考使用近似值来代替
比如可以使用explain来获取近似的值,其实在很多OLAP的应用中,需要计算某一个列值的基数,有一个计算近似值的算法叫hyperloglog。
-
更复杂的优化
一般情况下,count()需要扫描大量的行才能获取精确的数据,其实很难优化,在实际操作的时候可以考虑使用索引覆盖扫描,或者增加汇总表,或者增加外部缓存系统。
优化关联查询
-
确保on或者using子句中的列上有索引,在创建索引的时候就要考虑到关联的顺序
当表A和表B使用列C关联的时候,如果优化器的关联顺序是B、A,那么就不需要再B表的对应列上建上索引,没有用到的索引只会带来额外的负担,一般情况下来说,只需要在关联顺序中的第二个表的相应列上创建索引
-
确保任何的groupby和order by中的表达式只涉及到一个表中的列,这样mysql才有可能使用索引来优化这个过程
优化子查询
子查询的优化最重要的优化建议是尽可能使用关联查询代替,也并不是所有的子查询都必须要用关联查询代替,看具体语句执行情况
优化limit分页
在很多应用场景中我们需要将数据进行分页,一般会使用limit加上偏移量的方法实现,同时加上合适的orderby 的子句
如果这种方式有索引的帮助,效率通常不错,否则的化需要进行大量的文件排序操作还有一种情况,当偏移量非常大的时候,前面的大部分数据都会被抛弃,这样的代价太高。
要优化这种查询的话,要么是在页面中限制分页的数量,要么优化大偏移量的性能
优化此类查询的最简单的办法就是尽可能地使用覆盖索引,而不是查询所有的列
mysql> select film_id,description from film order by title limit 50,5;
+---------+---------------------------------------------------------------------------------------------------------------------------------+
| film_id | description |
+---------+---------------------------------------------------------------------------------------------------------------------------------+
| 51 | A Insightful Panorama of a Forensic Psychologist And a Mad Cow who must Build a Mad Scientist in The First Manned Space Station |
| 52 | A Thrilling Documentary of a Composer And a Monkey who must Find a Feminist in California |
| 53 | A Epic Drama of a Madman And a Cat who must Face a A Shark in An Abandoned Amusement Park |
| 54 | A Awe-Inspiring Drama of a Car And a Pastry Chef who must Chase a Crocodile in The First Manned Space Station |
| 55 | A Awe-Inspiring Story of a Feminist And a Cat who must Conquer a Dog in A Monastery |
+---------+---------------------------------------------------------------------------------------------------------------------------------+
5 rows in set (0.00 sec)
mysql> select film.film_id,film.description from film inner join (select film_id from film order by title limit 50,5) as lim using(film_id);
+---------+---------------------------------------------------------------------------------------------------------------------------------+
| film_id | description |
+---------+---------------------------------------------------------------------------------------------------------------------------------+
| 51 | A Insightful Panorama of a Forensic Psychologist And a Mad Cow who must Build a Mad Scientist in The First Manned Space Station |
| 52 | A Thrilling Documentary of a Composer And a Monkey who must Find a Feminist in California |
| 53 | A Epic Drama of a Madman And a Cat who must Face a A Shark in An Abandoned Amusement Park |
| 54 | A Awe-Inspiring Drama of a Car And a Pastry Chef who must Chase a Crocodile in The First Manned Space Station |
| 55 | A Awe-Inspiring Story of a Feminist And a Cat who must Conquer a Dog in A Monastery |
+---------+---------------------------------------------------------------------------------------------------------------------------------+
5 rows in set (0.00 sec)
#以上两条语句查询结果相同,耗时相差也不大,我们需要查看两天语句执行计划判断谁效率更高
#用普通分页偏移量方式查询出来实际扫描了约1000行数据
mysql> explain select film_id,description from film order by title limit 50,5;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| 1 | SIMPLE | film | NULL | ALL | NULL | NULL | NULL | NULL | 1000 | 100.00 | Using filesort |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
1 row in set, 1 warning (0.00 sec)
#通过join方式查询实际扫描了共约111行数据,因此通过此方法查询的效率更高
mysql> explain select film.film_id,film.description from film inner join (select film_id from film order by title limit 50,5) as lim using(film_id);
+----+-------------+------------+------------+--------+---------------+-----------+---------+-------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+---------------+-----------+---------+-------------+------+----------+-------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 55 | 100.00 | NULL |
| 1 | PRIMARY | film | NULL | eq_ref | PRIMARY | PRIMARY | 2 | lim.film_id | 1 | 100.00 | NULL |
| 2 | DERIVED | film | NULL | index | NULL | idx_title | 514 | NULL | 55 | 100.00 | Using index |
+----+-------------+------------+------------+--------+---------------+-----------+---------+-------------+------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
优化union查询
mysql总是通过创建并填充临时表的方式来执行union查询,因此很多优化策略在union查询中都没法很好的使用。
经常需要手工的将where、limit、order by等子句下推到各个子查询中,以便优化器可以充分利用这些条件进行优化
除非确实需要服务器消除重复的行,否则一定要使用union all,因此没有all关键字,mysql会在查询的时候给临时表加上distinct的关键字,这个操作的代价很高
用户自定义变量
用户自定义变量是一个容易被遗忘的mysql特性,但是如果能够用好,在某些场景下可以写出非常高效的查询语句,在查询中混合使用过程化和关系话逻辑的时候,自定义变量会非常有用。
用户自定义变量是一个用来存储内容的临时容器,在连接mysql的整个过程中都存在(只在当前会话中有效)。
自定义变量的使用
基础赋值
mysql> set @one:=1;
Query OK, 0 rows affected (0.00 sec)
mysql> select @one;
+------+
| @one |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
查询赋值
mysql> set @min_actor :=(select min(actor_id) from actor);
Query OK, 0 rows affected (0.00 sec)
mysql> select @min_actor;
+------------+
| @min_actor |
+------------+
| 1 |
+------------+
1 row in set (0.00 sec)
计算赋值
mysql> set @last_week :=current_date-interval 1 week;
Query OK, 0 rows affected (0.00 sec)
mysql> select @last_week;
+------------+
| @last_week |
+------------+
| 2022-05-31 |
+------------+
1 row in set (0.00 sec)
自定义变量的限制
- 无法使用查询缓存
- 不能在使用常量或者标识符的地方使用自定义变量,例如表名、列名或者limit子句
- 用户自定义变量的生命周期是在一个连接中有效,所以不能用它们来做连接间的通信
- 不能显式地声明自定义变量地类型
- mysql优化器在某些场景下可能会将这些变量优化掉,这可能导致代码不按预想地方式运行
- 赋值符号:=的优先级非常低,所以在使用赋值表达式的时候应该明确的使用括号
- 使用未定义变量不会产生任何语法错误
使用案例
优化排名语句
在给一个变量赋值的同时使用这个变量
mysql> select actor_id,@rownum:=@rownum+1 as rownum from actor limit 10;
+----------+--------+
| actor_id | rownum |
+----------+--------+
| 58 | NULL |
| 92 | NULL |
| 182 | NULL |
| 118 | NULL |
| 145 | NULL |
| 194 | NULL |
| 76 | NULL |
| 112 | NULL |
| 67 | NULL |
| 190 | NULL |
+----------+--------+
10 rows in set, 1 warning (0.00 sec)
查询获取演过最多电影的前10名演员,然后根据出演电影次数做一个排名
mysql> select actor_id,count(*) as cnt from film_actor group by actor_id order by cnt desc limit 10;
+----------+-----+
| actor_id | cnt |
+----------+-----+
| 107 | 42 |
| 102 | 41 |
| 198 | 40 |
| 181 | 39 |
| 23 | 37 |
| 81 | 36 |
| 37 | 35 |
| 158 | 35 |
| 106 | 35 |
| 13 | 35 |
+----------+-----+
10 rows in set (0.00 sec)
避免重新查询刚刚更新的数据
当需要高效的更新一条记录的时间戳,同时希望查询当前记录中存放的时间戳是什么
创建表数据
create table t1 (id int,t_date datetime);
insert into t1 values(1,now());
更新并查询
mysql> update t1 set t_date=now() where id =1;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select t_date from t1 where id =1;
+---------------------+
| t_date |
+---------------------+
| 2022-06-07 15:46:27 |
+---------------------+
1 row in set (0.00 sec)
更新赋值并查询自定义变量
mysql> update t1 set t_date = now() where id = 1 and @now:=now();
#这边可能由于自定义变量不能指定类型所以mysql对字符值是否符合字段要求进行了严格的检查导致报错,实际没有影响
#把sql_mode中的strict_trans_tables去掉即可 (show variables like 'sql_mode';)。
ERROR 1292 (22007): Truncated incorrect DOUBLE value: '2022-06-07 15:55:20'
mysql> select @now;
+---------------------+
| @now |
+---------------------+
| 2022-06-07 15:55:20 |
+---------------------+
1 row in set (0.00 sec)
确定取值的顺序
在赋值和读取变量的时候可能是在查询的不同阶段
mysql> set @rownum:=0;
Query OK, 0 rows affected (0.01 sec)
#因为where和select在查询的不同阶段执行,所以看到查询到两条记录,这不符合预期
mysql> select actor_id,@rownum:=@rownum+1 as cnt from actor where @rownum<=1;
+----------+------+
| actor_id | cnt |
+----------+------+
| 58 | 1 |
| 92 | 2 |
+----------+------+
2 rows in set, 1 warning (0.00 sec)
当引入了order by之后,打印出了全部结果,这是因为order by引入了文件排序,而where条件是在文件排序操作之前取值的
mysql> set @rownum:=0;
Query OK, 0 rows affected (0.00 sec)
mysql> select actor_id,@rownum:=@rownum+1 as cnt from actor where @rownum<=1 order by first_name;
+----------+------+
| actor_id | cnt |
+----------+------+
| 132 | 1 |
| 71 | 2 |
...省略196条记录
| 82 | 199 |
| 11 | 200 |
+----------+------+
200 rows in set, 1 warning (0.00 sec)
解决这个问题的关键在于让变量的赋值和取值发生在执行查询的同一阶段
mysql> set @rownum:=0;
Query OK, 0 rows affected (0.00 sec)
mysql> select actor_id,@rownum as cnt from actor where (@rownum:=@rownum+1)<=1;
+----------+------+
| actor_id | cnt |
+----------+------+
| 58 | 1 |
+----------+------+
1 row in set, 1 warning (0.00 sec)
分区表
对于用户而言,分区表是一个独立的逻辑表,但是底层是由多个物理子表组成。分区表对于用户而言是一个完全封装底层实现的黑盒子,对用户而言是透明的,从文件系统中可以看到多个使用
#分隔命名的表文件。
mysql在创建表时使用partition by子句定义每个分区存放的数据,在执行查询的时候,优化器会根据分区定义过滤那些没有我们需要数据的分区,这样查询就无须扫描所有分区。
分区的主要目的是将数据安好一个较粗的力度分在不同的表中,这样可以将相关的数据存放在一起。
分区表的应用场景
- 表非常大以至于无法全部都放在内存中,或者只在表的最后部分有热点数据,其他均是历史数据
- 分区表的数据更容易维护
- 批量删除大量数据可以使用清除整个分区的方式
- 对一个独立分区进行优化、检查、修复等操作
- 分区表的数据可以分布在不同的物理设备上,从而高效地利用多个硬件设备
- 可以使用分区表来避免某些特殊的瓶颈
- innodb的单个索引的互斥访问
- ext3文件系统的inode锁竞争
- 可以备份和恢复独立的分区
分区表的限制
- 一个表最多只能有1024个分区,在5.7版本的时候可以支持8196个分区
- 在早期的mysql中,分区表达式必须是整数或者是返回整数的表达式,在mysql5.5中,某些场景可以直接使用列来进行分区
- 如果分区字段中有主键或者唯一索引的列,那么所有主键列和唯一索引列都必须包含进来
- 分区表无法使用外键约束
分区表的原理
分区表由多个相关的底层表实现,这个底层表也是由句柄对象标识,我们可以直接访问各个分区。存储引擎管理分区的各个底层表和管理普通表一样(所有的底层表都必须使用相同的存储引擎),分区表的索引只是在各个底层表上各自加上一个完全相同的索引。从存储引擎的角度来看,底层表和普通表没有任何不同,存储引擎也无须知道这是一个普通表还是一个分区表的一部分。
有些操作时支持过滤的,例如,当删除一条记录时,MySQL需要先找到这条记录,如果where条件恰好和分区表达式匹配,就可以将所有不包含这条记录的分区都过滤掉,这对update同样有效。
如果是insert操作,则本身就是只命中一个分区,其他分区都会被过滤掉。mysql先确定这条记录属于哪个分区,再将记录写入对应得分区表,无须对任何其他分区进行操作
虽然每个操作都会“先打开并锁住所有的底层表”,但这并不是说分区表在处理过程中是锁住全表的,如果存储引擎能够自己实现行级锁,例如innodb,则会在分区层释放对应表锁。
分区表的操作按照以下的操作逻辑进行:
select操作
当查询一个分区表的时候,分区层先打开并锁住所有的底层表,优化器先判断是否可以过滤部分分区,然后再调用对应的存储引擎接口访问各个分区的数据
insert操作
当写入一条记录的时候,分区层先打开并锁住所有的底层表,然后确定哪个分区接受这条记录,再将记录写入对应底层表
delete操作
当删除一条记录时,分区层先打开并锁住所有的底层表,然后确定数据对应的分区,最后对相应底层表进行删除操作
update操作
当更新一条记录时,分区层先打开并锁住所有的底层表,mysql先确定需要更新的记录在哪个分区,然后取出数据并更新,
再判断更新后的数据应该再哪个分区,最后对底层表进行写入操作,并对源数据所在的底层表进行删除操作
分区表的类型
范围分区
范围分区表的分区方式是:每个分区都包含行数据且分区的表达式在给定的范围内,分区的范围应该是连续的且不能重叠,可以使用
values less than运算符来定义。
创建普通的表
DROP TABLE employees;
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
);
查看表文件
ls /var/lib/mysql/sakila
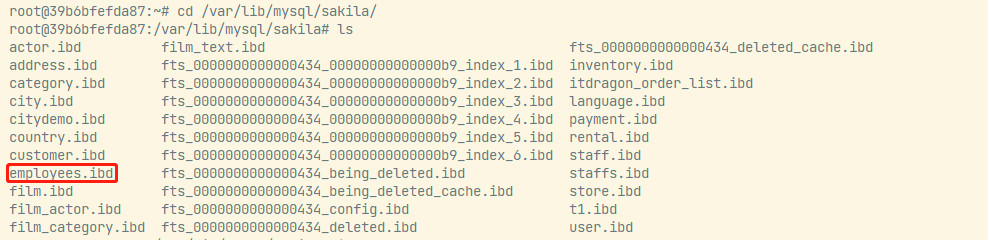
删除普通
DROP TABLE employees;
查看employees表文件是否存在
ls /var/lib/mysql/sakila
根据字段值范围分区方案
创建带分区的表
- 按照store_id来进行分区的,指定了4个分区
- store_id的值在1-5的在p0分区,6-10的在p1分区,11-15的在p3分区,16-20的在p4分区
- 但是如果插入超过20的值就会报错,因为mysql不知道将数据放在哪个分区
DROP TABLE employees;
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN (21)
);
查看employees分区表文件是否创建成功
ls /var/lib/mysql/sakila

针对上述插入超过20的值就会报错的情况,可以使用less than maxvalue来避免
- maxvalue表示始终大于等于最大可能整数值的整数值
DROP TABLE employees;
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN MAXVALUE
);
根据员工的职务代码对表进行分区
DROP TABLE employees;
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (job_code) (
PARTITION p0 VALUES LESS THAN (100),
PARTITION p1 VALUES LESS THAN (1000),
PARTITION p2 VALUES LESS THAN (10000)
);
查看employees分区表文件是否创建成功
ls /var/lib/mysql/sakila

可以使用date类型进行分区:如虚妄根据每个员工离开公司的年份进行划分,如year(separated)
DROP TABLE employees;
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY RANGE ( YEAR(separated) ) (
PARTITION p0 VALUES LESS THAN (1991),
PARTITION p1 VALUES LESS THAN (1996),
PARTITION p2 VALUES LESS THAN (2001),
PARTITION p3 VALUES LESS THAN MAXVALUE
);
查看employees分区表文件是否创建成功
ls /var/lib/mysql/sakila

利用函数分区方案
可以使用函数根据range的值来对表进行分区,如timestampunix_timestamp()
- timestamp不允许使用任何其他涉及值的表达式
CREATE TABLE quarterly_report_status (
report_id INT NOT NULL,
report_status VARCHAR(20) NOT NULL,
report_updated TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
)
PARTITION BY RANGE ( UNIX_TIMESTAMP(report_updated) ) (
PARTITION p0 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-01-01 00:00:00') ),
PARTITION p1 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-04-01 00:00:00') ),
PARTITION p2 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-07-01 00:00:00') ),
PARTITION p3 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-10-01 00:00:00') ),
PARTITION p4 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-01-01 00:00:00') ),
PARTITION p5 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-04-01 00:00:00') ),
PARTITION p6 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-07-01 00:00:00') ),
PARTITION p7 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-10-01 00:00:00') ),
PARTITION p8 VALUES LESS THAN ( UNIX_TIMESTAMP('2010-01-01 00:00:00') ),
PARTITION p9 VALUES LESS THAN (MAXVALUE)
);
查看分区表文件是否创建成功
ls /var/lib/mysql/sakila

基于时间间隔的分区方案
在mysql5.7中,可以基于范围或事件间隔实现分区方案,有两种选择
基于范围的分区
对于分区表达式,可以使用操作函数基于date、time、或者datatime列来返回一个整数值
DROP TABLE members;
CREATE TABLE members (
firstname VARCHAR(25) NOT NULL,
lastname VARCHAR(25) NOT NULL,
username VARCHAR(16) NOT NULL,
email VARCHAR(35),
joined DATE NOT NULL
)
PARTITION BY RANGE( YEAR(joined) ) (
PARTITION p0 VALUES LESS THAN (1960),
PARTITION p1 VALUES LESS THAN (1970),
PARTITION p2 VALUES LESS THAN (1980),
PARTITION p3 VALUES LESS THAN (1990),
PARTITION p4 VALUES LESS THAN MAXVALUE
);
DROP TABLE quarterly_report_status;
CREATE TABLE quarterly_report_status (
report_id INT NOT NULL,
report_status VARCHAR(20) NOT NULL,
report_updated TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
)
PARTITION BY RANGE ( UNIX_TIMESTAMP(report_updated) ) (
PARTITION p0 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-01-01 00:00:00') ),
PARTITION p1 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-04-01 00:00:00') ),
PARTITION p2 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-07-01 00:00:00') ),
PARTITION p3 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-10-01 00:00:00') ),
PARTITION p4 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-01-01 00:00:00') ),
PARTITION p5 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-04-01 00:00:00') ),
PARTITION p6 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-07-01 00:00:00') ),
PARTITION p7 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-10-01 00:00:00') ),
PARTITION p8 VALUES LESS THAN ( UNIX_TIMESTAMP('2010-01-01 00:00:00') ),
PARTITION p9 VALUES LESS THAN (MAXVALUE)
);
查看分区表文件是否创建成功
ls /var/lib/mysql/sakila

基于范围列的分区
使用date或者datatime列作为分区列
DROP TABLE members;
CREATE TABLE members (
firstname VARCHAR(25) NOT NULL,
lastname VARCHAR(25) NOT NULL,
username VARCHAR(16) NOT NULL,
email VARCHAR(35),
joined DATE NOT NULL
)
PARTITION BY RANGE COLUMNS(joined) (
PARTITION p0 VALUES LESS THAN ('1960-01-01'),
PARTITION p1 VALUES LESS THAN ('1970-01-01'),
PARTITION p2 VALUES LESS THAN ('1980-01-01'),
PARTITION p3 VALUES LESS THAN ('1990-01-01'),
PARTITION p4 VALUES LESS THAN MAXVALUE
);
列表分区
类似于按range分区,区别在于list分区是基于列值匹配一个离散值集合中的某个值来进行选择
DROP TABLE employees;
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LIST(store_id) (
PARTITION pNorth VALUES IN (3,5,6,9,17),
PARTITION pEast VALUES IN (1,2,10,11,19,20),
PARTITION pWest VALUES IN (4,12,13,14,18),
PARTITION pCentral VALUES IN (7,8,15,16)
);
列分区
mysql从5.5开始支持column分区,可以认为i是range和list的升级版,在5.5之后,可以使用column分区替代range和list,但是column分区只接受普通列不接受表达式
DROP TABLE `list_c`;
CREATE TABLE `list_c` (
`c1` int(11) DEFAULT NULL,
`c2` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
PARTITION BY RANGE COLUMNS(c1)
(PARTITION p0 VALUES LESS THAN (5) ENGINE = InnoDB,
PARTITION p1 VALUES LESS THAN (10) ENGINE = InnoDB);
DROP TABLE `list_c`;
CREATE TABLE `list_c` (
`c1` int(11) DEFAULT NULL,
`c2` int(11) DEFAULT NULL,
`c3` char(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
/*!50500 PARTITION BY RANGE COLUMNS(c1,c3)
(PARTITION p0 VALUES LESS THAN (5,'aaa') ENGINE = InnoDB,
PARTITION p1 VALUES LESS THAN (10,'bbb') ENGINE = InnoDB); */
DROP TABLE `list_c`;
CREATE TABLE `list_c` (
`c1` int(11) DEFAULT NULL,
`c2` int(11) DEFAULT NULL,
`c3` char(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
/*!50500 PARTITION BY LIST COLUMNS(c3)
(PARTITION p0 VALUES IN ('aaa') ENGINE = InnoDB,
PARTITION p1 VALUES IN ('bbb') ENGINE = InnoDB); */
查看分区表文件是否创建成功
ls /var/lib/mysql/sakila

hash分区
基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含myql中有效的、产生非负整数值的任何表达式
DROP TABLE employees;
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY HASH(store_id)
PARTITIONS 4;
DROP TABLE employees;
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LINEAR HASH(YEAR(hired))
PARTITIONS 4;
key分区
类似于hash分区,区别在于key分区只支持一列或多列,且mysql服务器提供其自身的哈希函数,必须有一列或多列包含整数值
CREATE TABLE tk (
col1 INT NOT NULL,
col2 CHAR(5),
col3 DATE
)
PARTITION BY LINEAR KEY (col1)
PARTITIONS 3;
查看分区表文件是否创建成功
ls /var/lib/mysql/sakila

子分区
在分区的基础之上,再进行分区后存储
CREATE TABLE `t_partition_by_subpart`
(
`id` INT AUTO_INCREMENT,
`sName` VARCHAR(10) NOT NULL,
`sAge` INT(2) UNSIGNED ZEROFILL NOT NULL,
`sAddr` VARCHAR(20) DEFAULT NULL,
`sGrade` INT(2) NOT NULL,
`sStuId` INT(8) DEFAULT NULL,
`sSex` INT(1) UNSIGNED DEFAULT NULL,
PRIMARY KEY (`id`, `sGrade`)
) ENGINE = INNODB
PARTITION BY RANGE(id)
SUBPARTITION BY HASH(sGrade) SUBPARTITIONS 2
(
PARTITION p0 VALUES LESS THAN(5),
PARTITION p1 VALUES LESS THAN(10),
PARTITION p2 VALUES LESS THAN(15)
);
查看分区表文件是否创建成功
ls /var/lib/mysql/sakila
如何使用分区表
如果需要从非常大的表中查询出某一段时间的记录,而这张表中包含很多年的历史数据,数据是按照时间排序的,此时应该如何查询数据呢?
因为数据量巨大,肯定不能在每次查询的时候都扫描全表。考虑到索引在空间和维护上的消耗,也不希望使用索引,即使使用索引,会发现会产生大量的碎片,还会产生大量的随机IO,但是当数据量超大的时候,索引也就无法起作用了,此时可以考虑使用分区来进行解决
-
全量扫描数据,不要任何索引
使用简单的分区方式存放表,不要任何索引,根据分区规则大致定位需要的数据为止,通过使用where条件将需要的数据限制在少数分区中,这种策略适用于以正常的方式访问大量数据
-
索引数据,并分离热点
如果数据有明显的热点,而且除了这部分数据,其他数据很少被访问到,那么可以将这部分热点数据单独放在一个分区中,让这个分区的数据能够有机会都缓存在内存中,这样查询就可以只访问一个很小的分区表,能够使用索引,也能够有效的使用缓存
需要注意的问题
- null值会使分区过滤无效
- 分区列和索引列不匹配,会导致查询无法进行分区过滤
- 选择分区的成本可能很高
- 打开并锁住所有底层表的成本可能很高
- 维护分区的成本可能很高
服务器参数设置
通用设置
vim /etc/mysql/my.cnf
参数释义
| 参数 | 释义 |
|---|---|
| datadir = /var/lib/mysql | 数据文件存放的目录 |
| socket = /var/lib/mysql/mysql.sock | mysql.socket表示server和client在同一台服务器,并且使用localhost进行连接,就会使用socket进行连接 |
| pid-file = /var/lib/mysql/mysql.pid | 存储mysql的pid |
| port = 3306 | mysql服务的端口号 |
| default_storage_engine = InnoDB | mysql存储引擎 ,默认InnoDB |
| skip-grant-tables | 当忘记mysql的用户名密码的时候,可以在mysql配置文件中配置该参数,跳过权限表验证,不需要密码即可登录mysql |
字符设置
| 参数 | 释义 |
|---|---|
| character_set_client | 客户端数据的字符集 |
| character_set_connection | mysql处理客户端发来的信息时,会把这些数据转换成连接的字符集格式 |
| character_set_results | mysql发送给客户端的结果集所用的字符集 |
| character_set_database | 数据库默认的字符集 |
| character_set_server | mysql server的默认字符集 |
连接设置
| 参数 | 释义 |
|---|---|
| max_connections | mysql的最大连接数,如果数据库的并发连接请求比较大,应该调高该值 |
| max_user_connections | 限制每个用户的连接个数 |
| back_log | mysql能够暂存的连接数量,当mysql的线程在一个很短时间内得到非常多的连接请求时,就会起作用,如果mysql的连接数量达到max_connections时,新的请求会被存储在堆栈中,以等待某一个连接释放资源,如果等待连接的数量超过back_log,则不再接受连接资源 |
| wait_timeout | mysql在关闭一个非交互的连接之前需要等待的时长 |
| interactive_timeout | 关闭一个交互连接之前需要等待的秒数 |
mysql> show variables like '%max_connections%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| max_connections | 151 |
| mysqlx_max_connections | 100 |
+------------------------+-------+
2 rows in set (0.00 sec)
mysql> show variables like '%max_user_connections%';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| max_user_connections | 0 |
+----------------------+-------+
1 row in set (0.00 sec)
mysql> show variables like '%back_log%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| back_log | 151 |
+---------------+-------+
1 row in set (0.00 sec)
日志设置
| 参数 | 释义 |
|---|---|
| log_error | 指定错误日志文件名称,用于记录当mysqld启动和停止时,以及服务器在运行中发生任何严重错误时的相关信息 |
| log_bin | 指定二进制日志文件名称,用于记录对数据造成更改的所有查询语句 |
| binlog_do_db | 指定将更新记录到二进制日志的数据库,其他所有没有显式指定的数据库更新将忽略,不记录在日志中 |
| binlog_ignore_db | 指定不将更新记录到二进制日志的数据库 |
| sync_binlog | 指定多少次写日志后同步磁盘 |
| general_log | 是否开启查询日志记录 |
| general_log_file | 指定查询日志文件名,用于记录所有的查询语句 |
| slow_query_log | 是否开启慢查询日志记录 |
| slow_query_log_file | 指定慢查询日志文件名称,用于记录耗时比较长的查询语句 |
| long_query_time | 设置慢查询的时间,超过这个时间的查询语句才会记录日志 |
| log_slow_admin_statements | 是否将管理语句写入慢查询日志 |
缓存设置
| 参数 | 释义 |
|---|---|
| key_buffer_size | 索引缓存区的大小(只对myisam表起作用) |
| sort_buffer_size | 每个需要排序的线程分派该大小的缓冲区 |
| max_allowed_packet=32M | 限制server接受的数据包大小 |
| join_buffer_size=2M | 表示关联缓存的大小 |
| thread_cache_size | 服务器线程缓存,这个值表示可以重新利用保存再缓存中的线程数量,当断开连接时,那么客户端的线程将被放到缓存中以响应下一个客户而不是销毁,如果线程重新被请求,那么请求将从缓存中读取,如果缓存中是空的或者是新的请求,这个线程将被重新请求,那么这个线程将被重新创建,如果有很多新的线程,增加这个值即可Threads_cached:代表当前此时此刻线程缓存中有多少空闲线程Threads_connected:代表当前已建立连接的数量Threads_created:代表最近一次服务启动,已创建现成的数量,如果该值比较大,那么服务器会一直再创建线程Threads_running:代表当前激活的线程数 |
查询缓存设置
show variables like '%query_cache%';
| 参数 | 释义 |
|---|---|
| query_cache_size | 查询缓存的大小,8版本被删除show status like '%Qcache%'; 查看缓存的相关属性Qcache_free_blocks:缓存中相邻内存块的个数,如果值比较大,那么查询缓存中碎片比较多Qcache_free_memory:查询缓存中剩余的内存大小Qcache_hits:表示有多少此命中缓存Qcache_inserts:表示多少次未命中而插入Qcache_lowmen_prunes:多少条query因为内存不足而被移除cacheQcache_queries_in_cache:当前cache中缓存的query数量Qcache_total_blocks:当前cache中block的数量 |
| query_cache_limit | 超出此大小的查询将不被缓存 |
| query_cache_min_res_unit | 缓存块最小大小 |
| query_cache_type | 缓存类型,决定缓存什么样的查询 [0:表示禁用 ] [1:表示将缓存所有结果,除非sql语句中使用sql_no_cache禁用查询缓存 ] [2:表示只缓存select语句中通过sql_cache指定需要缓存的查询 ] |
存储引擎设置
| 参数 | 释义 |
|---|---|
| innodb_buffer_pool_size | 该参数指定大小的内存来缓冲数据和索引,最大可以设置为物理内存的80% |
| innodb_flush_log_at_trx_commit | 主要控制innodb将log buffer中的数据写入日志文件并flush磁盘的时间点,值分别为0,1,2 |
| innodb_thread_concurrency | 设置innodb线程的并发数,默认为0表示不受限制,如果要设置建议跟服务器的cpu核心数一致或者是cpu核心数的两倍 |
| innodb_log_buffer_size | 此参数确定日志文件所用的内存大小,以M为单位 |
| innodb_log_file_size | 此参数确定数据日志文件的大小,以M为单位 |
| innodb_log_files_in_group | 以循环方式将日志文件写到多个文件中 |
| read_buffer_size | mysql读入缓冲区大小,对表进行顺序扫描的请求将分配到一个读入缓冲区 |
| read_rnd_buffer_size | mysql随机读的缓冲区大小 |
| innodb_file_per_table | 此参数确定为每张表分配一个新的文件 mysql8版本默认开启 并且将frm文件并入ibd文件 |
MySQL锁
**锁是计算机协调多个进程或线程并发访问某一资源的机制。**在数据库中,除传统的 计算资源(如CPU、RAM、I/O等)的争用以外,数据也是一种供许多用户共享的资源。如何保证数据并发访问的一致性、有效性是所有数据库必须解决的一 个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。从这个角度来说,锁对数据库而言显得尤其重要,也更加复杂。
相对其他数据库而言,MySQL的锁机制比较简单,其最 显著的特点是不同的存储引擎支持不同的锁机制。比如,MyISAM和MEMORY存储引擎采用的是表级锁(table-level locking);InnoDB存储引擎既支持行级锁(row-level locking),也支持表级锁,但默认情况下是采用行级锁。
表级锁
开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
行级锁
开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
MyISAM表锁
MySQL的表级锁有两种模式:表共享读锁(Table Read Lock)和表独占写锁(Table Write Lock)。
建立测试数据库
create database locktest;
use locktest;
CREATE TABLE `mylock` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`NAME` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
INSERT INTO `mylock` (`id`, `NAME`) VALUES ('1', 'a');
INSERT INTO `mylock` (`id`, `NAME`) VALUES ('2', 'b');
INSERT INTO `mylock` (`id`, `NAME`) VALUES ('3', 'c');
INSERT INTO `mylock` (`id`, `NAME`) VALUES ('4', 'd');
MyISAM 写锁阻塞读案例
当一个线程获得对一个表的写锁之后,只有持有锁的线程可以对表进行更新操作。其他线程的读写操作都会等待,直到锁释放为止。
session1给表上write锁
lock table mylock write;
session1对表的查询,插入,更新操作都可以执行
select * from mylock;
insert into mylock values(5,'e');

session2 对表的查询会被阻塞
select * from mylock;

session1释放锁
unlock tables;
#提交write锁
commit;

session2能够立刻执行,并返回对应结果

MyISAM读阻塞写案例
一个session使用lock table给表加读锁,这个session可以锁定表中的记录,但更新和访问其他表都会提示错误,同时,另一个session可以查询表中的记录,但更新就会出现锁等待。
提前创建
person表待用
CREATE TABLE `person` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`NAME` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
session1给表上read锁
lock table mylock read;
session1、session2都可以查询该表记录
select * from mylock;


session1不能查询没有锁定的表
select * from person;

session2可以查询或者更新未锁定的表
select * from person;
insert into person values(1,'zhangsan');

session1插入或更新被锁的表会提示错误
insert into mylock values(6,'f');
update mylock set name='aa' where id = 1;

session2插入数据会等待获得锁
insert into mylock values(6,'f');

session1释放锁
unlock tables;
#提交read锁
commit;
session2获得锁,插入成功


注意点
MyISAM在执行查询语句之前,会自动给涉及的所有表加读锁,在执行更新操作前,会自动给涉及的表加写锁,这个过程并不需要用户干预,因此用户一般不需要使用命令来显式加锁,上例中的加锁时为了演示效果。
MyISAM的并发插入问题
MyISAM表的读和写是串行的,这是就总体而言的,在一定条件下,MyISAM也支持查询和插入操作的并发执行
session1给表上read local锁
lock table mylock read local;
session1不能对表进行更新或者插入操作
insert into mylock values(6,'f');
update mylock set name='aa' where id = 1;

session2可以查询该表的记录
select* from mylock;

session1不能查询没有锁定的表,也不能访问其他session插入的记录
select * from person;

session2可以进行插入操作,但是更新会阻塞
update mylock set name = 'aa' where id = 1;

session1释放锁资源
unlock tables;
commit;
session2获取锁,更新操作完成

-
可以通过检查table_locks_waited和table_locks_immediate状态变量来分析系统上的表锁定争夺
如果Table_locks_waited的值比较高,则说明存在着较严重的表级锁争用情况
mysql> show status like 'table%'; +----------------------------+-------+ | Variable_name | Value | +----------------------------+-------+ | Table_locks_immediate | 58 | | Table_locks_waited | 1 | | Table_open_cache_hits | 77 | | Table_open_cache_misses | 1 | | Table_open_cache_overflows | 0 | +----------------------------+-------+ 5 rows in set (0.00 sec)
InnoDB锁
事务及其ACID属性
事务是由一组SQL语句组成的逻辑处理单元,事务具有4属性,通常称为事务的ACID属性。
原子性(Actomicity):事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
一致性(Consistent):在事务开始和完成时,数据都必须保持一致状态。
隔离性(Isolation):数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。
持久性(Durable):事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
并发事务带来的问题
相对于串行处理来说,并发事务处理能大大增加数据库资源的利用率,提高数据库系统的事务吞吐量,从而可以支持更多用户的并发操作,但与此同时,会带来一下问题
脏读
一个事务正在对一条记录做修改,在这个事务并提交前,这条记录的数据就处于不一致状态;这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些“脏”的数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被形象地叫做“脏读”
不可重复读
一个事务在读取某些数据已经发生了改变、或某些记录已经被删除了!这种现象叫做“不可重复读”。
幻读
一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为“幻读” >
上述出现的问题都是数据库读一致性的问题,可以通过事务的隔离机制来进行保证。
数据库的事务隔离越严格,并发副作用就越小,但付出的代价也就越大,因为事务隔离本质上就是使事务在一定程度上串行化,需要根据具体的业务需求来决定使用哪种隔离级别
| 脏读 | 不可重复读 | 幻读 | |
|---|---|---|---|
| read uncommitted | √ | √ | √ |
| read committed | √ | √ | |
| repeatable read | √ | ||
| serializable |
-
可以通过检查InnoDB_row_lock状态变量来分析系统上的行锁的争夺情况
如果发现InnoDB_row_lock_waits和InnoDB_row_lock_time_avg的值比较高,则锁争用比较严重
mysql> show status like 'innodb_row_lock%'; +-------------------------------+-------+ | Variable_name | Value | +-------------------------------+-------+ | Innodb_row_lock_current_waits | 0 | | Innodb_row_lock_time | 0 | | Innodb_row_lock_time_avg | 0 | | Innodb_row_lock_time_max | 0 | | Innodb_row_lock_waits | 0 | +-------------------------------+-------+ 5 rows in set (0.00 sec)
InnoDB的行锁模式及加锁方法
mysql InnoDB引擎默认的修改数据语句:update,delete,insert都会自动给涉及到的数据加上排他锁,select语句默认不会加任何锁类型,如果加排他锁可以使用select …for update语句,加共享锁可以使用select … lock in share mode语句。所以加过排他锁的数据行在其他事务种是不能修改数据的,也不能通过for update和lock in share mode锁的方式查询数据,但可以直接通过select …from…查询数据,因为普通查询没有任何锁机制。
共享锁(s)
又称读锁。允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
排他锁(x)
又称写锁。允许获取排他锁的事务更新数据,阻止其他事务取得相同的数据集共享读锁和排他写锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。
InnoDB行锁实现方式
InnoDB行锁是通过给索引上的索引项加锁来实现的,这一点MySQL与Oracle不同,后者是通过在数据块中对相应数据行加锁来实现的。InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
1、在不通过索引条件查询的时候,innodb使用的是表锁而不是行锁
创建测试表
create table tab_no_index(id int,name varchar(10)) engine=innodb;
insert into tab_no_index values(1,'1'),(2,'2'),(3,'3'),(4,'4');
session1操作
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from tab_no_index where id = 1;
+------+------+
| id | name |
+------+------+
| 1 | 1 |
+------+------+
1 row in set (0.00 sec)
session2操作
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql>
mysql> select * from tab_no_index where id =2;
+------+------+
| id | name |
+------+------+
| 2 | 2 |
+------+------+
1 row in set (0.00 sec)
session1加行锁
mysql> select * from tab_no_index where id = 1 for update;
+------+------+
| id | name |
+------+------+
| 1 | 1 |
+------+------+
1 row in set (0.00 sec)
session2给其他行加排他锁
select * from tab_no_index where id = 2 for update;

由上可知session1只给一行加了排他锁,但是session2在请求其他行的排他锁的时候,会出现锁等待。原因是在没有索引的情况下,innodb只能使用表锁。
2、创建带索引的表进行条件查询,innodb使用的是行锁
#释放锁并提交事务
unlock tables;
commit;
create table tab_with_index(id int,name varchar(10)) engine=innodb;
alter table tab_with_index add index id(id);
insert into tab_with_index values(1,'1'),(2,'2'),(3,'3'),(4,'4');
session1 操作
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql>
mysql> select * from tab_with_index where id = 1;
+------+------+
| id | name |
+------+------+
| 1 | 1 |
+------+------+
1 row in set (0.00 sec)
session2操作
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from tab_no_index where id =2;
+------+------+
| id | name |
+------+------+
| 2 | 2 |
+------+------+
1 row in set (0.00 sec)
session1 加排他锁
mysql> select * from tab_with_index where id = 1 for update;
+------+------+
| id | name |
+------+------+
| 1 | 1 |
+------+------+
1 row in set (0.00 sec)
session2加排他锁
mysql> select * from tab_with_index where id = 2 for update;
+------+------+
| id | name |
+------+------+
| 2 | 2 |
+------+------+
1 row in set (0.00 sec)
3、由于mysql的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行的记录,但是依然无法访问到具体的数据
释放锁提交事务并插入数据
unlock tables;
commit;
insert into tab_with_index values(1,'4');
session1 和 session2 均关闭事务自动提交
set autocommit=0;
session1加排他锁
mysql> select * from tab_with_index where id = 1 and name='1' for update;
+------+------+
| id | name |
+------+------+
| 1 | 1 |
+------+------+
1 row in set (0.00 sec)
session2加排他锁
虽然session2访问的是和session1不同的记录,但是因为使用了相同的索引,所以需要等待锁
select * from tab_with_index where id = 1 and name='4' for update;

总结
对于MyISAM的表锁,主要讨论了以下几点:
(1)共享读锁(S)之间是兼容的,但共享读锁(S)与排他写锁(X)之间,以及排他写锁(X)之间是互斥的,也就是说读和写是串行的。
(2)在一定条件下,MyISAM允许查询和插入并发执行,我们可以利用这一点来解决应用中对同一表查询和插入的锁争用问题。
(3)MyISAM默认的锁调度机制是写优先,这并不一定适合所有应用,用户可以通过设置LOW_PRIORITY_UPDATES参数,或在INSERT、UPDATE、DELETE语句中指定LOW_PRIORITY选项来调节读写锁的争用。
(4)由于表锁的锁定粒度大,读写之间又是串行的,因此,如果更新操作较多,MyISAM表可能会出现严重的锁等待,可以考虑采用InnoDB表来减少锁冲突。
对于InnoDB表,本文主要讨论了以下几项内容:
(1)InnoDB的行锁是基于索引实现的,如果不通过索引访问数据,InnoDB会使用表锁。
(2)在不同的隔离级别下,InnoDB的锁机制和一致性读策略不同。
在了解InnoDB锁特性后,用户可以通过设计和SQL调整等措施减少锁冲突和死锁,包括:
- 尽量使用较低的隔离级别; 精心设计索引,并尽量使用索引访问数据,使加锁更精确,从而减少锁冲突的机会;
- 选择合理的事务大小,小事务发生锁冲突的几率也更小;
- 给记录集显式加锁时,最好一次性请求足够级别的锁。比如要修改数据的话,最好直接申请排他锁,而不是先申请共享锁,修改时再请求排他锁,这样容易产生死锁;
- 不同的程序访问一组表时,应尽量约定以相同的顺序访问各表,对一个表而言,尽可能以固定的顺序存取表中的行。这样可以大大减少死锁的机会;
- 尽量用相等条件访问数据,这样可以避免间隙锁对并发插入的影响; 不要申请超过实际需要的锁级别;除非必须,查询时不要显示加锁;
- 对于一些特定的事务,可以使用表锁来提高处理速度或减少死锁的可能。



















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











