








第一题(对应LeetCode题库的第20题)(简单题!)
(当然,后续if自己看不懂自己的总结,可以去力扣网站翻阅回对应的题目去看题解!)
题目:有效的括号(字符串的括号匹配问题)
(first遍写的时候写了一百行都没有完全能deal所有的括号字符串匹配的问题,最后我是看答案学会的!,必须要2-10刷这个题!)
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
1、左括号必须用相同类型的右括号闭合。
2、左括号必须以正确的顺序闭合。
如果链表中存在环,则返回 true 。 否则,返回 false 。
下面是示例:

解法一:
思路:由于我们希望,对于只包含括号的字符串中的括号字符元素中后出现的左括号优先匹配到与其对应的右括号。因此,判断括号的有效性可以使用「栈」这一数据结构来解决。
我们遍历给定的字符串 s。当我们遇到一个左括号时,我们会期望在后续的遍历中,有一个相同类型的右括号将其闭合。由于后遇到的左括号要先闭合,因此我们可以将这个左括号直接顺序放入到栈顶中。
当我们遇到一个右括号时,我们需要将其与一个相同类型的左括号闭合。此时,我们可以取出栈顶的左括号并判断它们是否是相同类型的括号。如果不是相同的类型,或者栈中并没有左括号,那么字符串 s 无效,返回 False。为了快速判断括号的类型,我们可以使用哈希表unordered_map来存储每一种括号。哈希表的键Key为右括号,值Value为相同类型的左括号。
在遍历结束后,如果栈中没有左括号,说明我们将字符串 s 中的所有左括号闭合,返回 True,否则返回 False。
注意到有效字符串的长度一定为偶数,因此如果字符串的长度为奇数,我们可以直接返回 False,省去后续的遍历判断过程。
请看以下正确代码:
class Solution {
public:
bool isValid(string s) {
int n = s.size();
if (n % 2 == 1) {
return false;
}//括号总数if为奇数个的话,那么必然不是一个括号匹配的字符串!
unordered_map<char, char> pairs = {
//{key,value},
{')', '('},
{']', '['},
{'}', '{'}
};
stack<char> stk;
for (char ch : s) {
//对于右括号做事情!
if (pairs.count(ch)) {//pairs.count(ch)这条code表明ch存在于指定好的括号内!
//这里通过unordered_map[key] == value 的方式来寻值value!
if (stk.empty() || stk.top() != pairs[ch]) {
return false;
}
stk.pop();
}
//对于左括号做事情!
else {
//也即忽视左括号的意思!
//if为左括号的话,就push进栈即可!
stk.push(ch);
}
}
return stk.empty();
}
};我后来在看答案的基础上写的codes:
class Solution {
public:
bool isValid(string s) {
//首先若原来的括号字符串就是一个含有奇数个括号的字符串的话
//那么肯定就是个非括号匹配的字符串了!
int len = s.size();
if (len % 2 == 1) {
return false;
}
unordered_map<char, char> pairs;
pairs.insert(make_pair(')', '('));
pairs.insert(make_pair(']', '['));
pairs.insert(make_pair('}', '{'));
stack<char> stk;
for (char ch : s) {
if (pairs.count(ch)) {
if (stk.empty() || stk.top() != pairs[ch]) {
return false;
}
stk.pop();
}
else {
stk.push(ch);//忽视左括号!也即让左括号进栈!
}
}
return stk.empty();
}
};可以注意到,这里我写的是:
unordered_map<char, char> pairs;
pairs.insert(make_pair(')', '('));
pairs.insert(make_pair(']', '['));
pairs.insert(make_pair('}', '{'));
而不是:
unordered_map<char, char> pairs = {
//{key,value},
{')', '('},
{']', '['},
{'}', '{'}
};
我认为这两种创建哈希表的方式都是可以的,当然LeetCode标准的解题答案上直接像用数组的创建方式那样去创建哈希表,这样更容易理解!我可以学习一下哈!
(
比如这种数组的创建方式,用在哈希表上,值得学习!:
int a[][3]= {
{0,1,2},
{2,3,4},
{5,6,7},
};)
第二题(对应LeetCode题库的第155题)(简单题!)
(当然,后续if自己看不懂自己的总结,可以去力扣网站翻阅回对应的题目去看题解!)
题目:有效的括号(字符串的括号匹配问题)
(first遍写的时候写了一百行都没有完全能deal所有的括号字符串匹配的问题,最后我是看答案学会的!,必须要2-10刷这个题!)
题目:
Design a stack that supports push, pop, top, and retrieving the minimum element in constant time.(设计一个支持push pop top 以及获取栈中的值最小的元素的stack,要求使用O(1)的时间复杂读来完成)
Implement the MinStack class:
1、MinStack() initializes the stack object.
2、void push(int val) pushes the element val onto the stack.
3、void pop() removes the element on the top of the stack.
4、int top() gets the top element of the stack.
5、int getMin() retrieves the minimum element in the stack.
解题思路:其实就是很简单地用一个副助栈或者别地数据结构(就比如哈希表unordered_map)来来存储栈中的最小值元素,当然,由于栈是一种后进先出的特点的数据结构,因此我们不妨可以在push元素进栈的同时去计算当前栈的最小值,也即每一次元素的进栈都计算一边当前栈的min值,那么push和pop的操作都是2步,也即时间复杂度 == O(2) == O(1)了
方法一:(标准解法就是用一个辅助栈来实现)
请看以下代码:
// //解法2:用一个辅助栈do事情!
class MinStack {
private:
stack<int> myStack;
stack<int> minStack;
public:
MinStack() {
}
void push(int val) {
if (myStack.size() == 0) {
myStack.push(val);
minStack.push(val);
}
else {
myStack.push(val);
minStack.push(min(val, minStack.top()));
//保持minStack这个辅助栈的栈顶始终是最小的那个元素值
}
}
void pop() {
myStack.pop();
minStack.pop();
}
int top() {
return myStack.top();
}
int getMin() {
return minStack.top();//此时,副助栈的栈顶元素就是min的
}
};方法二:(用一个哈希表unordered_map来实现)
请看以下代码:
class MinStack {
private:
stack<pair<int,int>> myStack;
//myStack所存储的每一个对组pair元素(也即py中的tuple)都存储一个栈值以及当前栈中的最小值
public:
MinStack() {
}
void push(int val) {
if (myStack.size() == 0) {
myStack.push({ val, val });
//当然你这里可以这样
//myStack.push(make_pair( val, val));这样也ok的
}
else {
myStack.push({ val, min(val,myStack.top().second) });
}//myStack.top().second这个其实就是返回当前栈中的最小元素的意思
}
void pop() {
myStack.pop();
}
int top() {
return myStack.top().first;//这是返回当前栈顶的值
}
int getMin() {
return myStack.top().second;//这是返回当前栈中的min值
}
};第三题(对应LeetCode题库的第496题)(简单题!)
(当然,后续if自己看不懂自己的总结,可以去力扣网站翻阅回对应的题目去看题解!)
题目:
给你两个 没有重复元素 的数组 nums1 和 nums2 ,其中nums1 是 nums2 的子集。请你找出 nums1 中每个元素在 nums2 中的下一个比其大的值。nums1 中数字 x 的下一个更大元素是指 x 在 nums2 中对应位置的右边的第一个比 x 大的元素。如果不存在,对应位置输出 -1 。
提示:
nums1和nums2中所有整数 互不相同nums1中的所有整数同样出现在nums2中
解题思路:
1:找到nums1 中的元素x 在nums2中所处的位置下标
2:从这个下标开始一直到nums2数组的末尾尾部,遍历寻找比这个x值更大的元素
3:找到 将其push进入一个临时数组中; 否则 将-1 push进入一个临时数组中
方法一:(暴力解题法,这里毫不犹豫,直接上代码)
//way 1.1 用类似array的方式对vector进行循环的工作
class Solution {
public:
vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {
//找数组nums1 在 nums2中的下一个最大的元素,if没有就返回-1
vector<int> tempVec;
int ret = -1;
//1:找到nums1 中的元素x 在nums2中所处的位置下标
//2:从这个下标开始一直到nums2数组的末尾尾部,遍历寻找比这个x值更大的元素
//3:找到 将其push进入一个临时数组中; 否则 将-1 push进入一个临时数组中 ;
for(size_t i = 0;i < nums1.size();i++)
{
for(size_t j = 0;j < nums2.size();j++)
{
if (nums1[i] == nums2[j])
{
//cout << " == 了!" << endl;
size_t k = j + 1;
while (k < nums2.size())
{
if (nums1[i] < nums2[k])
{
//cout << "有比它大的元素!" << endl;
ret = nums2[k];
break;
}
k++;
}
tempVec.push_back(ret);
if (ret != -1) {
ret = -1;//归位!
}
}
}
}
return tempVec;
}
};
// way 1.2 用迭代器来进行循环的工作
class Solution {
public:
vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {
//找数组nums1 在 nums2中的下一个最大的元素,if没有就返回-1
vector<int> tempVec;
int ret = -1;
for (vector<int>::const_iterator it1 = nums1.begin(); it1 != nums1.end(); it1++)
{
for (vector<int>::const_iterator it2 = nums2.begin(); it2 != nums2.end();it2++)
{
if (*it1 == *it2)
{
vector<int>::const_iterator it3 = it2;
for (; it3 != nums2.end(); it3++)
{
if (*it1 < *it3) {
ret = *it3;
break;
}
}
tempVec.push_back(ret);
if (ret != -1) {
ret = -1;//归位!
}
}
}
}
return tempVec;
}
};
2个示例:
nums1 = [4, 1, 2], nums2 = [1, 3, 4, 2] 预计结果为: [-1,3,-1]
nums1 = [2, 4], nums2 = [1, 2, 3, 4] 预计结果为: [3,-1]运行结果:


但是这种暴力解题法的时间复杂度很不好!
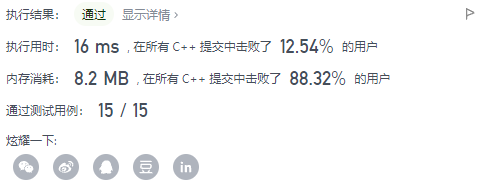
so下面介绍第二种方法!
方法二(用哈希表先行记录nums2中的每一个值的右边第一个比它大的元素):
我认为没有必要像leetcode官方那样用这个单调栈来do(多此一举,我这个way和官方的第二个way运行起来的时间和空间复杂度是差不多的),我既然再这里求到了nums2数组中的每一个值对应的右边的最大的那个元素了,那么我直接通过查字典的方式对应即可得出nums1在nums2数组中的右边第一个最大元素了。
废话不多说,show me code:
class Solution {
public:
vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {
vector<int> tempVec;
int ret = -1;
unordered_map<int,int> mp;//把nums2数组中的每一个元素的下一个最大的元素保存起来
for (vector<int>::const_iterator it2 = nums2.begin(); it2 != nums2.end(); it2++)
{
for (vector<int>::const_iterator it22 = it2; it22 != nums2.end(); it22++)
{
if (*it2 < *it22) {
ret = *it22;
break;
}
}
mp.insert({ *it2 ,ret });
if (ret != -1) {
ret = -1;
}
}
for (vector<int>::const_iterator it1 = nums1.begin(); it1 != nums1.end(); it1++)
{
tempVec.push_back(mp[*it1]);//通过 map[key] == value的形式取键值对!
}
return tempVec;
}
};
















 472
472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











