







文章目录
SparkStreaming以socket为数据源的WordCount实例
需求介绍:
使用 netcat 工具向 9999 端口不断的发送数据,通过 Spark Streaming 读取端口数据并统计不同单词出现的次数
具体过程:
step1:新建maven项目
在这一步选择本地的maven(Maven home directory)和xml文件,这里只选了本地的maven
step2:修改xml依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.1</version>
</dependency>
step3:scala代码
package main.scala.Streaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object StreamingWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("StreamingWordCount").setMaster("local[*]")
// 1. 创建SparkStreaming的入口对象: StreamingContext 参数2: 表示事件间隔 内部会创建 SparkContext
val ssc = new StreamingContext(conf, Seconds(3))
// 2. 创建一个DStream
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop201", 9999)
// 3. 一个个的单词
val words: DStream[String] = lines.flatMap(_.split("""\s+"""))
// 4. 单词形成元组
val wordAndOne: DStream[(String, Int)] = words.map((_, 1))
// 5. 统计单词的个数
val count: DStream[(String, Int)] = wordAndOne.reduceByKey(_ + _)
//6. 显示
println("aaa")
count.print
//7. 开始接受数据并计算
ssc.start()
//8. 等待计算结束(要么手动退出,要么出现异常)才退出主程序
ssc.awaitTermination()
}
}
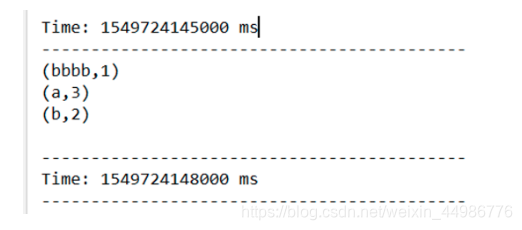
step4:测试
启动netcat
nc -lk 9999
查看输出结果. 每 3 秒统计一次数据的输入情况.
以Flume & Kafka作为高级数据源
Flume的原理介绍
Flume 是一个分布式的、高可靠、高可用日志收集和汇总的工具。常应用于传输网络流量数据、社交媒体数据、电子邮件消息等。
flume作为日志实时采集的框架,可以与SparkStreaming实时处理框进行对接,flume实时产生数据,sparkStreaming做实时处理。Spark Streaming对接FlumeNG有两种方式,一种是FlumeNG将消息Push推给Spark Streaming,还有一种是Spark Streaming从flume 中Poll拉取数据。
编程实践
整合方式1:推(PUSH)
(1)编写flume-push.conf配置文件
#push mode
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#source
a1.sources.r1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/data
a1.sources.r1.fileHeader = true
#channel
a1.channels.c1.type =memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity=5000
#sinks
a1.sinks.k1.channel = c1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname=192.168.11.25
a1.sinks.k1.port = 8888
a1.sinks.k1.batchSize= 2000
注意配置文件中指明的hostname和port是spark应用程序所在服务器的ip地址和端口。
启动flume:
bin/flume-ng agent -n a1 -c conf/ -f conf/flume-push-spark.conf -Dflume.root.logger=INFO,console
(2)代码实现如下:
package cn.testdemo.dstream.flume
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.flume.{FlumeUtils, SparkFlumeEvent}
//todo:利用sparkStreaming对接flume数据,实现单词计数------Push推模式
object SparkStreamingFlume_Push {
def main(args: Array[String]): Unit = {
//1、创建sparkConf
val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingFlume_Push").setMaster("local[2]")
//2、创建sparkContext
val sc = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
//3、创建StreamingContext
val ssc = new StreamingContext(sc,Seconds(5))
//4、获取flume中的数据
val stream: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createStream(ssc,"192.168.11.25",9999)
//5、从Dstream中获取flume中的数据 {"header":xxxxx "body":xxxxxx}
val lineDstream: DStream[String] = stream.map(x => new String(x.event.getBody.array()))
//6、切分每一行,每个单词计为1
val wordAndOne: DStream[(String, Int)] = lineDstream.flatMap(_.split(" ")).map((_,1))
//7、相同单词出现的次数累加
val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_+_)
//8、打印输出
result.print()
//开启计算
ssc.start()
ssc.awaitTermination()
}
}
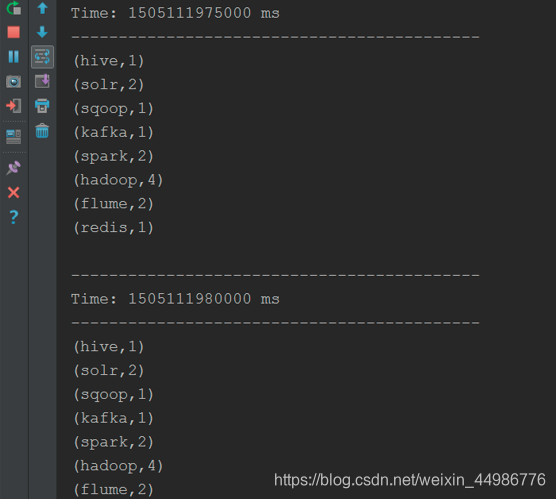
(3) 启动执行
先执行spark代码,再执行flume
(4) 观察IDEA控制台输出
整合方式2:拉(poll)
(1)下载依赖包
spark-streaming-flume-sink_2.11-2.0.2.jar放入到flume的lib目录下
(2)写flume的agent,注意既然是拉取的方式,那么flume向自己所在的机器上产数据就行
(3)编写flume-poll.conf配置文件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#source
a1.sources.r1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/data 注:存放数据文件的地址
a1.sources.r1.fileHeader = true
#channel
a1.channels.c1.type =memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity=5000
#sinks
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink
a1.sinks.k1.hostname=node-1
a1.sinks.k1.port = 8888
a1.sinks.k1.batchSize= 2000
(4)启动spark-streaming应用程序,去flume所在机器拉取数据
(5)代码
package cn.testdemo.dstream.flume
import java.net.InetSocketAddress
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.flume.{FlumeUtils, SparkFlumeEvent}
//todo:利用sparkStreaming对接flume数据,实现单词计算------Poll拉模式
object SparkStreamingFlume_Poll {
def main(args: Array[String]): Unit = {
//1、创建sparkConf
val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingFlume_Poll").setMaster("local[2]")
//2、创建sparkContext
val sc = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
//3、创建StreamingContext
val ssc = new StreamingContext(sc,Seconds(5))
//定义一个flume地址集合,可以同时接受多个flume的数据
val address=Seq(new InetSocketAddress("192.168.216.120",9999),new InetSocketAddress("192.168.216.121",9999))
//4、获取flume中数据
val stream: ReceiverInputDStream[SparkFlumeEvent] =
FlumeUtils.createPollingStream(ssc,address,StorageLevel.MEMORY_AND_DISK_SER_2)
//5、从Dstream中获取flume中的数据 {"header":xxxxx "body":xxxxxx}
val lineDstream: DStream[String] = stream.map(x => new String(x.event.getBody.array()))
//6、切分每一行,每个单词计为1
val wordAndOne: DStream[(String, Int)] = lineDstream.flatMap(_.split(" ")).map((_,1))
//7、相同单词出现的次数累加
val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_+_)
//8、打印输出
result.print()
//开启计算
ssc.start()
ssc.awaitTermination()
}
}
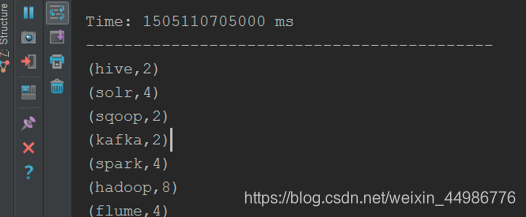
(6)IDEA的输出














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









