






时间模块
time 模块
时间表示方式
-
**时间戳 timestamp:**表示的是从 1970 年1月1日 00:00:00 开始按秒计算的偏移量
-
**UTC(Coordinated Universal Time, 世界协调时)**亦即格林威治天文时间,世界标准时间。在中国为 UTC+8 DST(Daylight Saving Time) 即夏令时;
-
元组(struct_time): 由 9 个元素组成
结构化时间(struct_time)
使用 time.localtime() 等方法可以获得一个结构化时间元组。
>>> import time
>>> time.localtime()
time.struct_time(tm_year=2021, tm_mon=9, tm_mday=1, tm_hour=14, tm_min=23, tm_sec=29, tm_wday=2, tm_yday=244, tm_isdst=0)结构化时间元组共有9个元素,按顺序排列如下表:
| 索引 | 属性 | 取值范围 |
|---|---|---|
| 0 | tm_year(年) | 比如 2021 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 59 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为-1 |
然结构化时间是一个元组,那么就可以通过索引进行取值,也可以进行分片,或者通过属性名获取对应的值。
注意
但是要记住,Python的time类型是不可变类型,所有的时间值都只读,不能改
格式化时间字符串
利用
time.strftime('%Y-%m-%d %H:%M:%S')等方法可以获得一个格式化时间字符串注意其中的空格、短横线和冒号都是美观修饰符号,真正起控制作用的是百分符
对于格式化控制字符串
"%Y-%m-%d %H:%M:%S,其中每一个字母所代表的意思如下表所示,注意大小写的区别:
| 格式 | 含义 | 格式 | 含义 |
|---|---|---|---|
| %a | 本地简化星期名称 | %m | 月份(01 - 12) |
| %A | 本地完整星期名称 | %M | 分钟数(00 - 59) |
| %b | 本地简化月份名称 | %p | 本地am或者pm的相应符 |
| %B | 本地完整月份名称 | %S | 秒(01 - 59) |
| %c | 本地相应的日期和时间 | %U | 一年中的星期数(00 – 53,星期日是一个星期的开始) |
| %d | 一个月中的第几天(01 - 31) | %w | 一个星期中的第几天(0 - 6,0是星期天) |
| %H | 一天中的第几个小时(24小时制,00 - 23) | %x | 本地相应日期 |
| %I | 第几个小时(12小时制,01 - 12) | %X | 本地相应时间 |
| %j | 一年中的第几天(001 - 366) | %y | 去掉世纪的年份(00 - 99) |
| %Z | 时区的名字 | %Y | 完整的年份 |
time 模块主要方法
1. time.sleep(t)
time 模块最常用的方法之一,用来睡眠或者暂停程序t秒,t可以是浮点数或整数。
2. time.time()
返回当前系统时间戳。时间戳可以做算术运算。
3. time.gmtime([secs])
将一个时间戳转换为 UTC时区的结构化时间。可选参数secs的默认值为
time.time()。
4. time.localtime([secs])
将一个时间戳转换为 当前时区 的结构化时间。如果secs参数未提供,则以当前时间为准,即
time.time()。
import time
# 1. time.sleep(秒): 让程序阻塞执行
# def func01():
# print("start...")
# time.sleep(5) # 让程序睡5s(让程序阻塞执行5s)
# print("end...")
# func01()
# 2. 时间戳: time.time(): 返回当前时间的时间戳
print(time.time())
# []包裹的参数可写可不写,不写的话有默认值
# 3. time.gmtime([时间戳]): 将一个时间戳转换为 UTC时区的结构化时间(九元组)
# 时间戳: 默认值为 time.time()
t1 = time.gmtime()
print(t1)
# 4. time.localtime([时间戳]): 将一个时间戳转换为本地时区的结构化时间(九元组)
# 时间戳: 默认值为 time.time()
t2 = time.localtime(time.time())
print(t2)
print(t2[0], t2[1], t2[2]) # 2022 04 01
print(t2[:3]) # (2022, 04, 01)
print(t2.tm_hour, t2.tm_min, t2.tm_sec) # 21 46 37
# time.struct_time(tm_year=2022, tm_mon=4, tm_mday=1, tm_hour=05,
# tm_min=38, tm_sec=40, tm_wday=3, tm_yday=90, tm_isdst=1)
5. time.mktime(t)
将一个结构化时间转化为时间戳。time.mktime()执行与gmtime(),localtime()相反的操作,它接收 struct_time 对象作为参数,返回用秒数表示时间的浮点数。如果输入的值不是一个合法的时间,将触发 OverflowError 或 ValueError。
# 5. time.strftime(时间格式,[结构化时间]):将九元组->指定格式的时间字符串
# 结构化时间:默认值 time.localtime()
t3 = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime())
print("t3:",t3)
结果:
t3: 2022-04-01 10:20:286. time.strftime(format [, t])
返回格式化字符串表示的当地时间。把一个
struct_time(如time.localtime()和time.gmtime()的返回值)转化为格式化的时间字符串,显示的格式由参数format决定。如果未指定t,默认传入time.localtime()。
7. time.strptime(string[,format])
将格式化时间字符串转化成结构化时间
- 该方法是
time.strftime()方法的逆操作。time.strptime()方法根据指定的格式把一个时间字符串解析为时间元组。- 提供的字符串要和 format参数 的格式一一对应
- 如果string中日期间使用 “-” 分隔,format中也必须使用“-”分隔
- 时间中使用冒号 “:” 分隔,后面也必须使用冒号分隔
- 并且值也要在合法的区间范围内
时间格式之间的转换
Python的三种类型时间格式,可以互相进行转换
| 从 | 到 | 方法 |
|---|---|---|
| 时间戳 | UTC结构化时间 | gmtime() |
| 时间戳 | 本地结构化时间 | localtime() |
| 本地结构化时间 | 时间戳 | mktime() |
| 结构化时间 | 格式化字符串 | strftime() |
| 格式化字符串 | 结构化时间 | strptime() |
# 6. time.strptime(时间字符串,时间格式)
t4 = time.strptime("1794-09-10 10:10:10","%Y-%m-%d %H:%M:%S")
print("t4:",t4)
print(t4.tm_wday+1)
结果:
t4: time.struct_time(tm_year=1794, tm_mon=9, tm_mday=10, tm_hour=10, tm_min=10, tm_sec=10, tm_wday=2, tm_yday=253, tm_isdst=-1)
3t4 = time.strptime("1794-09-10 10:10:10","%Y-%m-%d %H:%M:%S")
print("t4:",t4)
print(t4.tm_wday+1)
t5 = time.strptime("3333-03-03 03:33:33","%Y-%m-%d %H:%M:%S")
print("t5:",t5)
print("t5 > t4 ?", t5 > t4) #结构化时间可以相互比较,越靠后时间越大
结果:
t4: time.struct_time(tm_year=1794, tm_mon=9, tm_mday=10, tm_hour=10, tm_min=10, tm_sec=10, tm_wday=2, tm_yday=253, tm_isdst=-1)
3
t5: time.struct_time(tm_year=3333, tm_mon=3, tm_mday=3, tm_hour=3, tm_min=33, tm_sec=33, tm_wday=1, tm_yday=62, tm_isdst=-1)
t5 > t4 ? True练习:取出指定时间段的文本
需求
-
有一日志文件,按时间先后顺序记录日志
-
给定 时间范围,取出该范围内的日志
-
自定义日志文件 myweb.log
(mypy) [root@localhost day01]# vim myweb.log 2030-01-02 08:01:43 aaaaaaaaaaaaaaaaa 2030-01-02 08:34:23 bbbbbbbbbbbbbbbbbbbb 2030-01-02 09:23:12 ccccccccccccccccccccc 2030-01-02 10:56:13 ddddddddddddddddddddddddddd 2030-01-02 11:38:19 eeeeeeeeeeeeeeee 2030-01-02 12:02:28 ffffffffffffffff
# 练习:取出指定时间段的文本
# 需求
# 有一日志文件,按时间先后顺序记录日志
# 给定 时间范围,取出该范围内的日志
# 自定义日志文件 myweb.log
import time
t9 = time.strptime("2030-01-02 09:00:00","%Y-%m-%d %H:%M:%S")
t12 = time.strptime("2030-01-02 12:00:00","%Y-%m-%d %H:%M:%S")
fr = open("/opt/myweb.log",mode = "r")
dc = fr.readlines()
for item in dc: # item:每一行日志
# 将时间字符串转换为结构化时间 time.strptime(...)
t = time.strptime(item[:19],"%Y-%m-%d %H:%M:%S")
if t > t12: # 当时间大于12点时,退出循环
break
if t >= t9:
print(item)
fr.close()
# (mypy) [root@localhost day01]# vim myweb.log
# 2030-01-02 08:01:43 aaaaaaaaaaaaaaaaa
# 2030-01-02 08:34:23 bbbbbbbbbbbbbbbbbbbb
# 2030-01-02 09:23:12 ccccccccccccccccccccc
# 2030-01-02 10:56:13 ddddddddddddddddddddddddddd
# 2030-01-02 11:38:19 eeeeeeeeeeeeeeee
# 2030-01-02 12:02:28 ffffffffffffffff
异常处理
什么是异常
程序在运行时,如果 Python 解释器 遇到 到一个错误,会停止程序的执行,并且提示一些错误信息,这就是 异常
异常是因为程序出现了错误,而在正常控制流以外采取的行为
- 这个行为又分为两个阶段:
- 首先是引起异常发生的错误
- 然后是检测(和采取可能的措施)阶段
Python 中的异常
当程序运行时,因遇到未解的错误而导致中止运行,便会出现 traceback 消息,打印异常
try: #将可能出问题的代码放到try中处理
num01 = float(input("num01:"))
num02 = float(input("num02:"))
jg = num01 /num02 # 10 / 0
print(jg)
except ValueError: # except 错误类型
print("请您输入数字!!!") # ValueError 问题的解决方案
except ZeroDivisionError as dc : #as 错误信息(冒号右边内容)
print("您出错的原因是 %s,解决方案: 0不能做除数,换个数试试" %dc)
except (KeyboardInterrupt,EOFError): # ctrl + c / ctrl + d
print("Byebye~")
exit()
except Exception as dc: #对未知错误的兜底方案
print("您的问题是:",dc)
print("ok~")
KeyboardInterrupt # Ctrl + C,会产生用户中断执行错误
EOFError # Ctrl + D,会产出此错误python 中异常演示
>>> a + 5 # NameError,变量a没有定义
>>> 'hello'[5] # IndexError,字符串hello的最长索引下标为4
>>> a = 10
>>> if a = 10: # SyntaxError,python中的等于号使用'=='表示
>>> n = input('number:' ) # 要求输入number时,Ctrl + D, 产生EOFError
>>> n = input('number: ') # Ctrl + C,产生KeyboardInterrupt,用户中断执行错误类型捕获
- 在程序执行时,可能会遇到 不同类型的异常,并且需要 针对不同类型的异常,做出不同的响应,这个时候,就需要捕获错误类型了
- 语法如下:
try:
# 尝试执行的代码
pass
except 错误类型1:
# 针对错误类型1,对应的代码处理
pass
except (错误类型2, 错误类型3):
# 针对错误类型2 和 3,对应的代码处理
pass
except Exception as result:
print("未知错误 %s" % result)try-except 语句
- 定义了进行异常监控的一段代码,并且提供了处理异常的机制
try:
n = int(input('number: ')) # 没有输入任何值,回车,产生ValueError异常
print(n)
except ValueError:
print('无效的输入') # 当异常ValueError发生时,执行print()带有多个 expect 的 try 语句
- 可以把多个 except 语句连接在一起,处理一个try 块中可能发生的多种异常
# 使用多个expect的try语句,处理异常
try:
n = int(input('number: ')) # 没有输入任何值,回车,产生ValueError异常
print(n)
except ValueError: # 当异常ValueError发生时,执行print()
print('无效的输入')
except KeyboardInterrupt: # Ctrl + C,产生KeyboardInterrupt,用户中断执行
print('\nBye-bye')
except EOFError: # Ctrl + D, 产生EOFError, 没有内建输入
print('\nBye-bye')- 检测上述模块中异常处理结果
[root@localhost xxx] # python day01.py
number: # 回车,ValueError异常,s输入错误类型
无效的输入
[root@localhost xxx] # python day01.py
number: ^CBye-bye # Ctrl + C,KeyboardInterrupt异常,用户操作中断
[root@localhost xxx]# python day01.py
number: Bye-bye # Ctrl + D, EOFError异常, 没有内建输入捕获未知错误
- 在开发时,要预判到所有可能出现的错误,还是有一定难度的
- 如果希望程序 无论出现任何错误,都不会因为
Python解释器 抛出异常而被终止,可以再增加一个except
语法如下:
except Exception as result:
print("未知错误 %s" % result)异常参数
-
异常也可以有参数,异常引发后它会被传递给异常处理器
-
当异常被引发后参数是作为附加帮助信息传递给异常处理器的
查看异常提示信息
>>> n = int(input('number: '))
number: # 回车,ValueError异常
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: ''
else 子句
-
在 try 范围中没有异常被检测到时,执行 else 子句
-
在else 范围中的任何代码运行前,try 中的所有代码必须完全成功
try: #将可能出问题的代码放到try中处理
num01 = float(input("num01:"))
num02 = float(input("num02:"))
jg = num01 /num02 # 10 / 0
print(jg)
except ValueError: # except 错误类型
print("请您输入数字!!!") # ValueError 问题的解决方案
except ZeroDivisionError as dc : #as 错误信息(冒号右边内容)
print("您出错的原因是 %s,解决方案: 0不能做除数,换个数试试" %dc)
except (KeyboardInterrupt,EOFError): # ctrl + c / ctrl + d
print("Byebye~")
exit()
except Exception as dc: #对未知错误的兜底方案
print("您的问题是:",dc)
else:
print("try中的逻辑没有报错,会执行else的逻辑")
print("ok~")
finally子句
-
finally 子句是 无论异常是否发生,是否捕捉都会执行的一段代码
-
如果打开文件后,因为发生异常导致文件没有关闭,可能会发生数据损坏,使用finally 可以保证文件总是能正常的关闭
try: #将可能出问题的代码放到try中处理
num01 = float(input("num01:"))
num02 = float(input("num02:"))
jg = num01 /num02 # 10 / 0
print(jg)
except ValueError: # except 错误类型
print("请您输入数字!!!") # ValueError 问题的解决方案
except ZeroDivisionError as dc : #as 错误信息(冒号右边内容)
print("您出错的原因是 %s,解决方案: 0不能做除数,换个数试试" %dc)
except (KeyboardInterrupt,EOFError): # ctrl + c / ctrl + d
print("Byebye~")
exit()
except Exception as dc: #对未知错误的兜底方案
print("您的问题是:",dc)
else:
print("try中的逻辑没有报错,会执行else的逻辑")
finally:
print("try中不管有没有错误,都会执行finally的逻辑")
print("ok~")
自定义异常
抛出异常—raise
应用场景
- 在开发中,除了 代码执行出错
Python解释器会 抛出 异常之外 - 还可以根据 应用程序 特有的业务需求 主动抛出异常
示例
- 提示用户 输入密码,如果 长度少于 8,抛出 异常
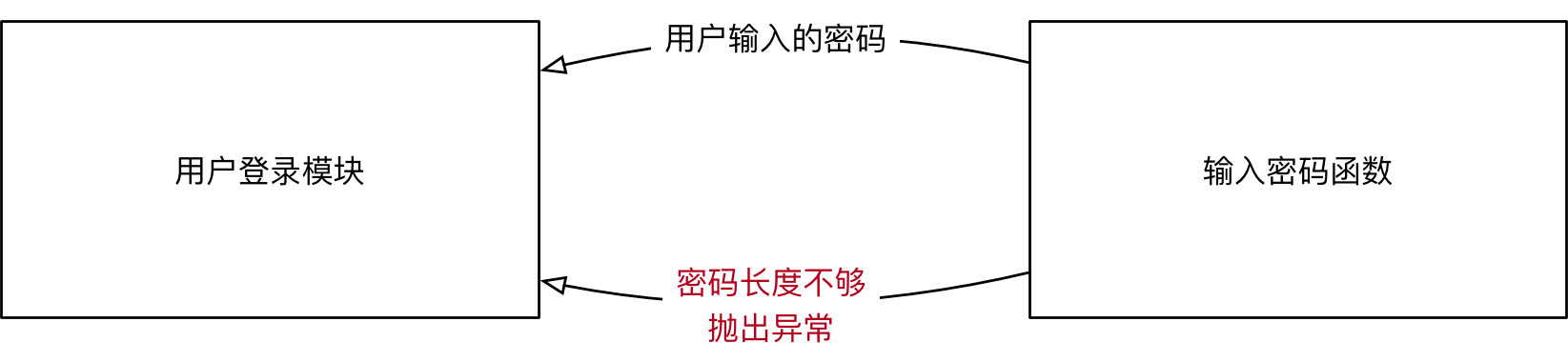
注意
- 当前函数 只负责 提示用户输入密码,如果 密码长度不正确,需要其他的函数进行额外处理
- 因此可以 抛出异常,由其他需要处理的函数 捕获异常
抛出异常
Python中提供了一个Exception异常类- 在开发时,如果满足 特定业务需求时,希望 抛出异常,可以:
- 创建 一个
Exception的 对象 - 使用
raise关键字 抛出 异常对象
- 创建 一个
需求
- 定义
input_password函数,提示用户输入密码 - 如果用户输入长度 < 8,抛出异常
- 如果用户输入长度 >= 8,返回输入的密码
def input_passwd():
# 1. 要求用户输入密码
passwd = input("密码:")
# 2. 判断密码长度,如果密码长度大于等于8位,则正常打印
if len(passwd) >= 8 :
print("passwd:",passwd)
else:
# 3. 如果密码长度小于8位,抛出异常
# 3.1 创建异常
ex = Exception("密码长度小于8位,请重新输入")
# 3.2 抛出异常
raise ex #raise主动告诉用户
input_passwd() #调用函数
练习 4:自定义异常
需求
- 编写第一个函数,接收姓名和年龄,如果年龄不在1到120之间,产生 ValueError 异常
#需求
#编写第一个函数,接收姓名和年龄,如果年龄不在1到119之间,产生 ValueError 异常
def get_info(name,age):
if 0< age <= 120:
print("name: %s,age: %s"%(name, age))
else:
raise ValueError('无效的年龄(1 ~ 119)')
get_info("wwy",180)
os 模块
- 对文件系统的访问大多通过 python 的 os 模块实现
- 该模块是 python 访问操作系统功能的主要接口
- 有些方法,如:copy 等,并没有提供,可以使用 shutil 模块作为补充
# os模块的常用方法
>>> import os #导入os系统模块
>>> os. #os.<Tab><Tab> 查看os模块的所以方法
>>> os.getcwd() #getcwd(),查看当前所处的文件路径,类似于: pwd
>>> os.listdir() #listdir(), 查看当前目录下的所有文件(包括隐藏文件),类似于:ls -a
>>> os.listdir('/tmp') #listdir('/tmp'), 查看/tmp目录下的内容,类似于:ls /tmp
>>> os.mkdir('/tmp/mytest') #mkdir(), 创建目录,类似于:mkdir /tmp/mytest
>>> os.mkdir('/tmp/demo/abc') #只能创建单级目录,父目录无法创建
>>> os.makedirs('/tmp/demo/abc') #创建目录时,父目录不存在,会自动创建,类似于: mkdir -p ...
>>> os.chdir('/tmp/demo') #chdir(), 切换当前所处的文件位置,类似于:cd /tmp/demo
>>> os.getcwd() #getcwd(),查看当前所处的文件路径,类似于: pwd
>>> os.listdir() #listdir(), 查看当前目录下的所有文件(包括隐藏文件),类似于:ls -a
>>> os.symlink('/etc/passwd', 'mima') #symlink(), 为/etc/passwd建立软链接mima,类似于: ln -s /etc/passwd mima
>>> os.remove('abc') #remove(), 只能删除单个文件,不能删除目录
>>> os.rmdir('abc') #rmdir(),只能删除空目录;要删除非空目录要使用shutil.rmtree()
>>> os.rmdir('/var/tmp') #rmdir(),只能删除空目录;要删除非空目录要使用shutil.rmtree()
>>> os.remove('hosts') #remove(),只能删除单个文件,不能删除目录
>>> os.unlink('mima') #unlink(),取消删除链接文件
>>> os.path. #查看os.path子模块的所有方法
>>> os.mkdir('abc') #mkdir(), 在当前路径下,创建一个目录'abc'
>>> os.path.abspath('abc') #abspath(), 获取abc文件的路径
>>> os.path.basename('/tmp/demo/abc') #获取最右边'/',右边的数据‘abc’
>>> os.path.basename('/tmp/demo/abc/') #basename(),获取最右边'/',右边的数据''
>>> os.path.dirname('/tmp/demo/abc') #dirname(), 获取最右边'/',左边的数据'/tmp/demo'
>>> os.path.split('/tmp/demo/abc') #split(), 路径切割,从最右边'/'开始,进行切割
>>> os.path.splitext('tedu.txt') #splitext(),将扩展名和文件名进行切割
>>> os.path.join('/tmp/demo', 'abc') #join(), 路径的拼接
>>> os.path.is #os.path.is<Tab><Tab>, 列出所有判断的方法
>>> os.path.isabs('tmp/abc/xyz') #'tmp/abc/xyz'是否是绝对路径,不管文件是否存在,False
>>> os.path.isabs('/tmp/abc/xyz') #'/tmp/abc/xyz'是否是绝对路径,不管文件是否存在,True
>>> os.path.isdir('/tmp/demo/abc') # 字符串是否为目录(文件必须存在,且必须是目录) ,True
>>> os.path.isdir('/tmp/demo/xyz') # 字符串是否为目录(文件必须存在,且必须是目录),False
>>> os.path.isfile('/etc/hosts') #字符串是否是文件(文件必须存在,且必须是文件),True
>>> os.path.isfile('/etc/') #字符串是否是文件(文件必须存在,且必须是文件),False
>>> os.path.islink('/etc/grub2.cfg') #字符串是否是链接文件(文件必须存在,且必须是链接文件),True
>>> os.path.ismount('/') #判断字符串是否是挂载文件,'/'是挂载文件
>>> os.path.ismount('/etc') #判断字符串是否是挂载文件,'/etc' 不是挂载文件
>>> os.path.exists('/etc/hostname') #判断字符串是否存在,/etc/hostname,True常用:
# >>> import os # operation system
# >>> os.getcwd() # pwd
# '/root/PycharmProjects/nsd2112/day07'
# >>> os.listdir() # ls
# ['demo01.py', 'test01.py', 'demo02.py', 'demo03.py', 'test02.py']
# >>> os.listdir("/opt") # ls /opt
# ['mypasswd', 'test01.txt', 'test02.txt', 'myls', 'user.data', 'myweb.log']
# >>> os.mkdir("aaa") # mkdir aaa
# >>> os.listdir()
# ['demo01.py', 'test01.py', 'demo02.py', 'demo03.py', 'test02.py', 'aaa']
# >>> os.makedirs("bbb/ccc") # mkdir -p bbb/ccc
# >>> os.remove("test_rm.py")
# >>> os.rmdir("aaa")
# >>> os.rmdir("bbb") # 只能删除空目录,删除非空: shutil.rmtree(xxx)
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# OSError: [Errno 39] Directory not empty: 'bbb'
# /etc/udev/udev.conf
# >>> import os
# >>> os.path.basename("/etc/udev/udev.conf") # udev.conf
# 'udev.conf'
# >>> os.path.dirname("/etc/udev/udev.conf") # /etc/udev
# '/etc/udev'
# >>> os.path.split("/etc/udev/udev.conf")
# ('/etc/udev', 'udev.conf')
# >>> os.path.join("/etc", "passwd")
# '/etc/passwd'
# >>> os.path.exists("/etc/passwd")
# True
# >>> os.path.exists("/etc/hahahhehe")
# False
pickle 模块
模块简介
- 把数据写入文件时,常规的文件方法只能把字符串对象写入。其他数据需先转换成字符串再写入文件
- python 提供了一个标准的模块,称为 pickle。使用它可以在一个文件中 存储任何 python 对象,之后又可以把它完整无缺地取出来
主要方法
| 方法 | 功能 |
|---|---|
| pickle.dump(obj, file) | 将 Python 数据转换并保存到 pickle 格式的文件内 |
| pickle.load(file) | 从 pickle 格式的文件中读取数据并转换为 python 的类型 |
基本演示
- 常规方法写入数据,只能是字符串类型,其他类型无法写入,例如:int,字典,列表等类型;
- pickle模块,可以在文件中存储任何类型的数据,也可以完整取出任何类型的数据;
import pickle
list01 = [1, 2, "hello", 4, 5]
fw1 = open("/opt/test01.data", mode="wb")
pickle.dump(list01, fw1) # 将列表数据写入文件
fw1.close()
fr1 = open("/opt/test01.data", mode="rb")
dc = pickle.load(fr1) # 将列表数据读取出来
print("type:", type(dc)) # <class 'list'>
print(dc) # [1, 2, 'hello', 4, 5]
dc.append("world")
print(dc)
fr1.close()
# userdb = {"name": "zhangsan", "age": 18}
# fw = open("/opt/test.data", mode="wb")
# pickle.dump(userdb, fw) # 将python字典数据写入文件
# fw.close()
#
# fr = open("/opt/test.data", mode="rb")
# dc = pickle.load(fr) # 将python字典数据读取出来
# print(type(dc)) # <class 'dict'>
# for item in dc.items():
# print(item)
# fr.close()
















 73
73











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









