









目录
前言
本文是上刘君老师的云计算与大数据课,记录一下最新软件的安装过程,主要参考厦门大学林子雨老师的教程。另:因为非计算机专业,所以有些地方可能有误或者非必要,欢迎指出!
一、环境版本
| 软件 | 版本号 |
| Ubuntu | 22.04 LTS |
| Hadoop | 3.3.3 |
| jdk1.8 | jdk8u331 |
| Mysql | 8.0 |
| HBase | 2.4.13 |
| Zookeeper | 3.7.1 |
| Hive | 3.1.3 |
| Eclipse | JEE(2022-03) |
| Redis | 6.0.16 |
二、安装步骤
1. Ubuntu 22.04 LTS安装
Ubuntu 22.04 点击下载,使用Vmware 16.2.3 Pro(该软件可自行寻找)进行虚拟机安装。
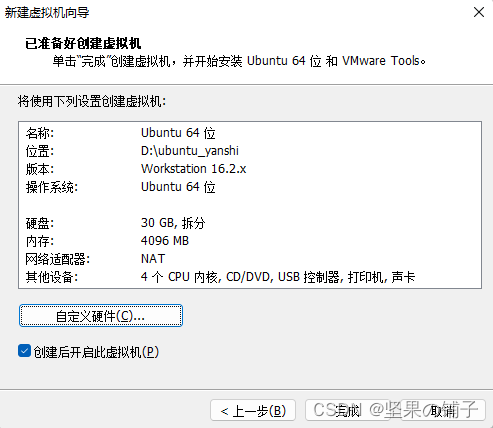
以上是虚拟机的硬件配置,根据自己电脑配置可自行修改(过低配置不建议最新版),此外本次演示系统设置的用户名与密码均是hadoop,之后的Ubuntu安装按照经验去选即可,在安装的时候记得在“更新和其他选项页面”取消“安装Ubuntu时下载更新”,因为由于网络问题,会导致下载安装时间很久
在安装完成之后,建议更换软件源,然后再进行系统软件更新,Ubuntu的cn服务器比较慢
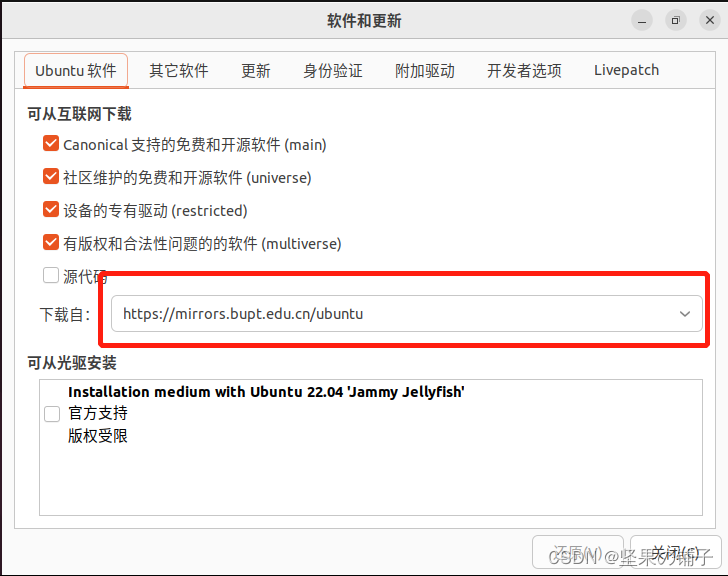
安装vmtools,在命令行终端(按住crtl+alt+t 进入终端)里输入
sudo apt install open-vm-tools-desktop2. Hadoop 3.3.3 安装
因为本文是进行hadoop伪分布式实验,所以这里是为了免密码登录设置,以下命令进入命令行终端进行操作
sudo apt-get install openssh-server
ssh localhost # 输入 yes,然后输入用户密码
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
ssh localhost #登录上去进行安装hadoop先安装jdk1.8,点击下载jdk8u331
cd /usr/lib
sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
sudo tar -zxvf ~/下载/jdk-8u331-linux-x64.tar.gz -C /usr/lib/jvm设置环境变量
sudo apt install vim
vim ~/.bashrc #设置环境变量 在 .bashrc 文件中加入以下代码
# 非命令行输入
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_331
export JRE_HOME=/usr/lib/jvm/jdk1.8.0_331/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH使环境变量生效
source ~/.bashrc
java -version #检查是否安装成功下面开始安装Hadoop,配置伪分布式,官方配置伪分布式说明地址
点击下载Hadoop 3.3.3,执行以下命令
sudo tar -zxf ~/下载/hadoop-3.3.3.tar.gz -C /usr/local
cd /usr/local/
sudo mv ./hadoop-3.3.3/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop:hadoop ./hadoop # 修改文件权限
cd /usr/local/hadoop
./bin/hadoop version #检查 Hadoop 是否可用开始伪分布式配置,输入命令,修改 core-site.xml 文件
gedit /usr/local/hadoop/etc/hadoop/core-site.xmlcore-site.xml 文件的 <configuration> 部分修改为以下内容
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:8020</value>
</property>
</configuration>输入命令,修改 hdfs-site.xml 文件
gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xmlhdfs-site.xml 文件的 <configuration> 部分修改为以下内容
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>配置完成后执行 NameNode 的格式化:
cd /usr/local/hadoop
./bin/hdfs namenode -format然后配置 hadoop-env.sh 文件
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh在 hadoop-env.sh 文件,添加以下内容
JAVA_HOME=/usr/lib/jvm/jdk1.8.0_331把hadoop添加为环境变量,编辑 .bashrc 文件
vim ~/.bashrc #设置环境变量 以下是在 .bashrc 文件添加了内容之后的截图:

然后保存退出文件之后,记得使在终端中使 .bashrc 文件生效
source ~/.bashrc最后我们进行一个hadoop测试例子,首先启动hadoop
start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格启动成功截图如下:
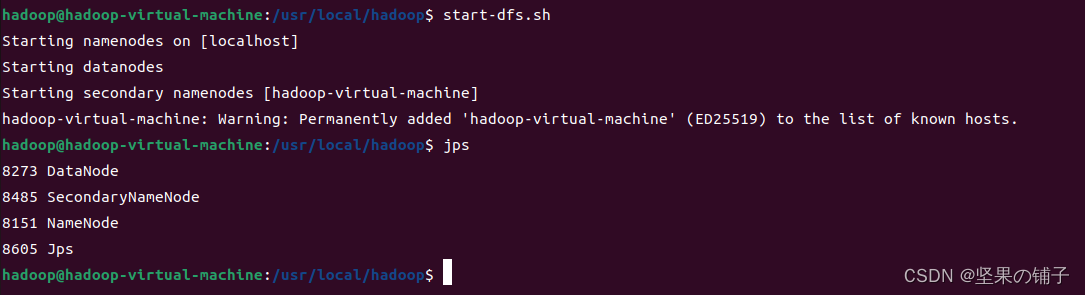
运行Hadoop伪分布式实例,具体参考林子雨老师教程
hdfs dfs -mkdir -p /user/hadoop
hdfs dfs -mkdir input
hdfs dfs -put ./etc/hadoop/*.xml input
hdfs dfs -ls input
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.3.jar grep input output 'dfs[a-z.]+'
hdfs dfs -get output ./output # 将 HDFS 上的 output 文件夹拷贝到本机
cat ./output/*
./bin/hdfs dfs -rm -r output # Hadoop 运行程序时,输出目录不能存在,删除 output 文件夹运行结果截图如下:

另外,浏览器中输入以下地址,可查看hadoop状态
http://localhost:9870/3. Hbase 2.4.13 安装
点击下载Hbase 2.4.13 ,然后执行以下命令
sudo tar -zxf ~/下载/hbase-2.4.13-bin.tar.gz -C /usr/local
sudo mv /usr/local/hbase-2.4.13 /usr/local/hbase添加环境变量,最后结果如下图,红框为增加部分,记得使环境变量生效:
vim ~/.bashrc 
source ~/.bashrc
cd /usr/local
sudo chown -R hadoop:hadoop ./hbase #将hbase下的所有文件的所有者改为hadoop
hbase version #测试是否okHbase 伪分布式配置见下节 Zookeeper 3.7.1 安装(本次实验使用内置Zookeeper遇到错误)
4. Zookeeper 3.7.1 安装
本文实验采用外置 Zookeeper 进行实验,点击下载 Zookeeper 3.7.1
sudo tar -zxvf ~/下载/apache-zookeeper-3.7.1-bin.tar.gz -C /usr/local/
cd /usr/local/
sudo mv apache-zookeeper-3.7.1-bin/ zookeeper/
sudo chown -R hadoop:hadoop ./zookeeper
cd /usr/local/zookeeper/
cp conf/zoo_sample.cfg conf/zoo.cfg添加环境变量
vim ~/.bashrc
source ~/.bashrcHbase 伪分布式配置,编辑环境文件,添加以下内容:
vim /usr/local/hbase/conf/hbase-env.shexport HBASE_CLASSPATH=/usr/local/hadoop/etc/hadoop
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_331
export HBASE_MANAGES_ZK=false
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"编辑 hbase-site.xml 文件
gedit /usr/local/hbase/conf/hbase-site.xmlhdfs-site.xml 文件的 <configuration> 部分修改为以下内容
<configuration>
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
</configuration>启动 hbase 进行测试,启动 hbase 前,要先启动 hadoop 与zookeeper
start-dfs.sh #启动hadoop
zkServer.sh start #启动zookeeper
start-hbase.sh #启动hbase另外,浏览器中输入以下地址,可查看hbase状态
http://localhost:60010测试hbase功能
hbase shell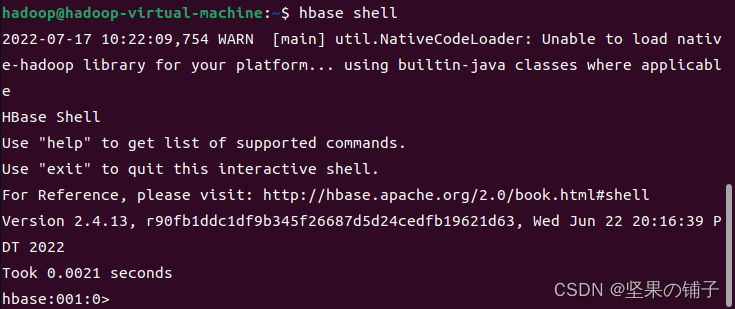
输入建表命令,结果如下:
create 'Student','S_No','S_Name','S_Sex','S_Age'
测试hbase完成,退出 exit 即可
停止hbase命令,顺序与启动反向
stop-hbase.sh #关闭hbase
zkServer.sh stop #关闭zookeeper
stop-dfs.sh #关闭Hadoop5. Hive 3.1.3安装
点击下载 Hive 3.1.3,执行以下命令
sudo tar -zxvf ~/下载/apache-hive-3.1.3-bin.tar.gz -C /usr/local
cd /usr/local/
sudo mv apache-hive-3.1.3-bin hive
sudo chown -R hadoop:hadoop hive添加环境变量
vim ~/.bashrc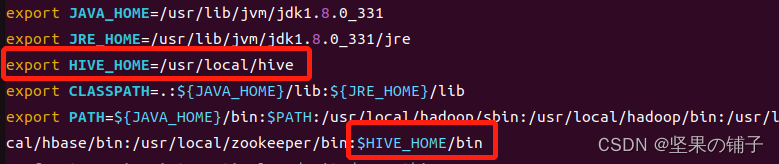
source ~/.bashrc新建 hive-site.xml 文件,先执行以下命令:
cd /usr/local/hive/conf
mv hive-default.xml.template hive-default.xml
vim hive-site.xmlhive-site.xml 文件内容修改为以下,保存退出:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
</configuration>安装 mysql 8.0
sudo apt-get install mysql-server #安装mysql点击下载mysql jdbc 包
sudo tar -zxvf ~/下载/mysql-connector-java-8.0.28.tar.gz -C ~/下载/
cp ~/下载/mysql-connector-java-8.0.28/mysql-connector-java-8.0.28.jar /usr/local/hive/lib/进入mysql8.0,进行配置
sudo su #输入hadoop密码,切换到超级用户
mysql在mysql里面输入以下命令
create database hive;
USE mysql;
CREATE USER hive IDENTIFIED BY 'hive';
use hive;
GRANT ALL ON hive.* TO 'hive'@'%';
flush privileges; 退出mysql与超级用户
exit;
su hadoop对hive进行测试,进入hive(启动hive之前先启动Hadoop):
service mysql start #启动mysql
hive在 hive 输入命令测试(先启动Hadoop):
create database hive;
use hive;
create table t1(id int, name string) stored as textile;
show tables;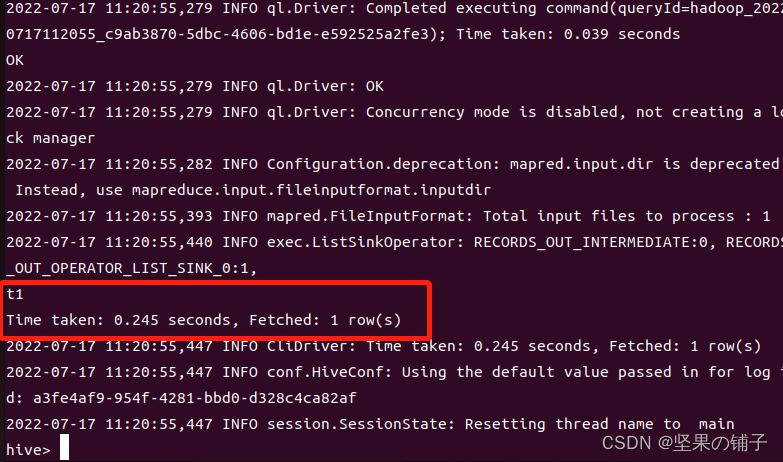
输入 exit; 即可退出hive
6. Eclipse JEE(2022-03)安装
点击下载 Eclipse JEE(2022-03),执行以下命令
cd ~/下载
sudo tar -zxvf eclipse-jee-2022-03-R-linux-gtk-x86_64.tar.gz -C /usr/local
cd /usr/local/
sudo chown -R hadoop:hadoop eclipseunzip ~/下载/eclipse-hadoop3x-master.zip
cp ~/下载/eclipse-hadoop3x-master/release/hadoop-eclipse-plugin-2.6.0.jar /usr/local/eclipse/plugins/ # 复制到 eclipse 安装目录的 plugins 目录下
/usr/local/eclipse/eclipse -clean 启动eclipse的话寻找以下路径,找到eclipse双击即可,其余参照林子雨老师的步骤即可
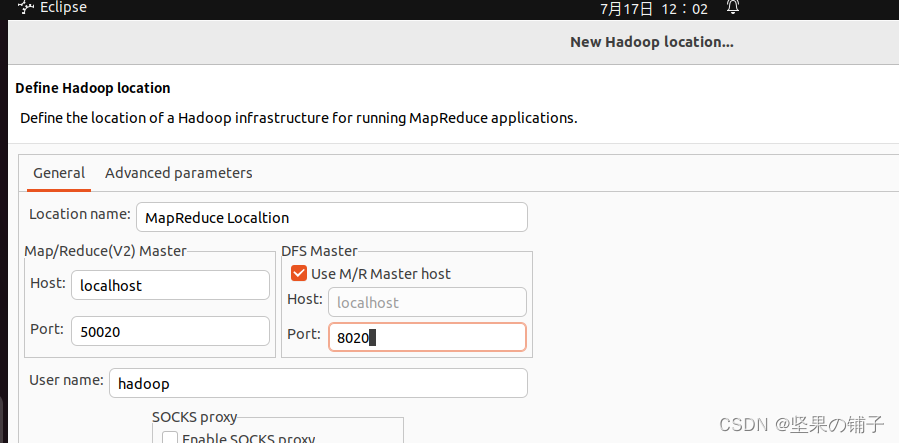
记得这里的端口写8020(9000是hadoop2.x版本的):
配置完成截图,后续直接按照林子雨老师eclipse教程即可
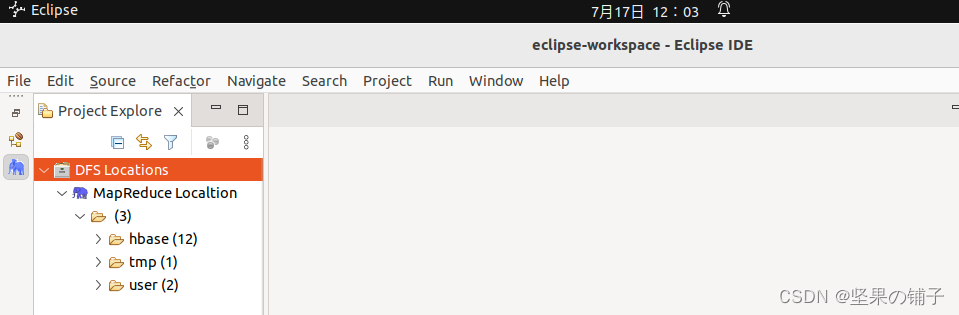
7. Redis 6.0.16 的安装
sudo apt install redis-server
redis-cli --raw #启动redis,--raw 避免中文乱码8. 其他说明
(1)课程中,要求安装的sqoop由于已经停止维护,所以不再演示安装;
(2)而Mangodb的安装在Ubuntu遇到了困难,猜测可能是最新版的Ubuntu 22.04采用了openssl 3.0的原因,Mangodb官网还没有支持22.04,建议直接下Windows版本来实验,或者安装20.04版本尝试;
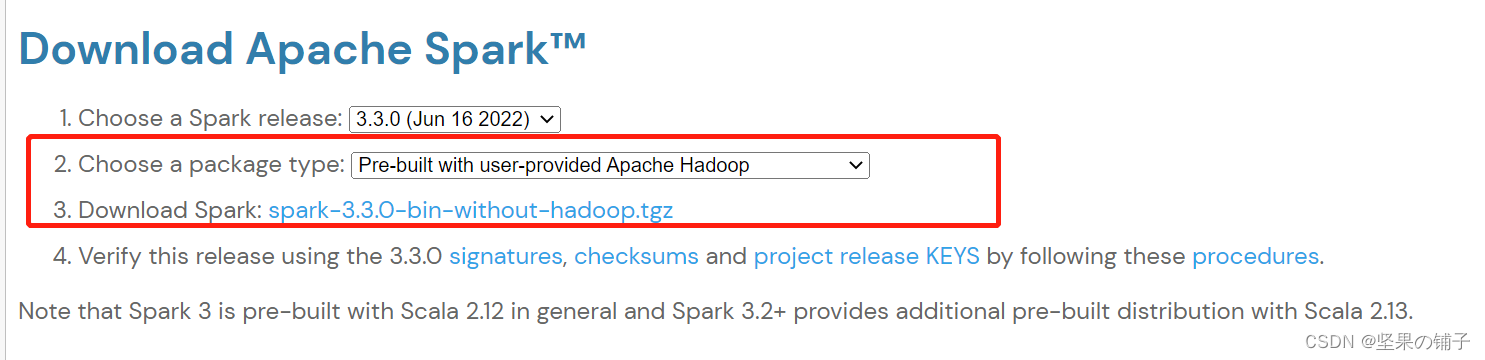
(3)至于spark在安装的时候选择without-hadoop即可,其配置大同小异,按林子雨老师spark教程走即可
三、总结
本文主要是记录在课程中是如何安装这些软件的,主要参考林子雨老师的大数据教程写就而成,由于非科班出身,难免有所问题,请包涵
需要镜像的,点击下载系统镜像,下载后自行百度如何使用VMware打开克隆镜像















 3421
3421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









