









Task:
用随机森林训练出一个区分好坏图像的模型,计算accurancy
流程:
首先做的是cv2.imread()读入图像,读入的是BGR格式,应该是三个M x N的二维矩阵,分别表示各个像素的R、G、B三个颜色分量(见下图的x_test)。接着转化为灰度图像,灰度数字图像是每个像素只有一个采样颜色的图像,它是一个M x N的二维矩阵。然后由于手头用的是大小不同的图像,还要在进行统一大小。最后就是运用随机森林,得到精确度。
遇到的一些问题:
- 在将训练集送入随机森林时候,报错:

应该是输入的训练集是三维的,所以出现错误。
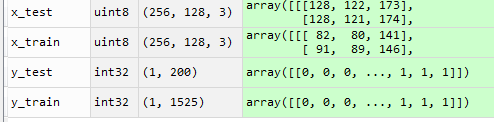
要想办法把它降维,解决办法就是保持它的第一纬度,另外两个维度进行展平,即
nsamples_test, nx, ny = x_test.shape
x_test = x_test.reshape(nsamples_test, nx*ny)
nsamples_train, nx, ny = x_train.shape
x_train = x_test.reshape(nsamples_train, nx*ny)
变化后如图
还有一个方法(我用的是这个);
因为我是用cv2.imread()写的,读出来是BGR格式(H,W,C),可以将其转换成灰度图也可以起到降维的办法。
im = cv2.imread(impath)
# 转灰度
im_gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)

2.绝对路径和相对路径
绝对路径就是文件实际位置,从盘符开始
相对路径主要由三种:
../ 程序的上级文件位置
./ 程序的同级文件位置
/ 当前的站点的根目录
3.在过程中用的一些函数
im = cv2.imread(图片位置):从输入位置读入图像
im_gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY) :转化为灰度
im_test_size0 = cv2.resize(im_gray, dim, interpolation = cv2.INTER_AREA):dim是自己定义的大小
im_test_0 = im_test_size0.flatten():flatten是降维的
flatten()可以参考:https://blog.csdn.net/qq_18433441/article/details/54916991
代码如下:
import os
import cv2
import numpy as np
from sklearn.ensemble import RandomForestClassifier
y_train = []
x_train = []
datapath = './data/7_29trainData/0'
#outpath = './data/gray_data/'
filelist = []
for i in os.listdir(datapath):
filelist.append(i)
length = len(filelist)
for i in range(0,length):
impath = datapath + '/' + filelist[i]
im = cv2.imread(impath)
# 1.转灰度
im_gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
# 输出灰度图到某文件夹
# outname = outpath + '/' + filelist[i]
# cv2.imwrite(outname,im_gray)
#2.调整所有图片为统一大小
width = 128
height = 128
dim = (width,height)
im_train_size0 = cv2.resize(im_gray, dim, interpolation = cv2.INTER_AREA)
#3.把128*128的图片降维
im_train_0 = im_train_size0.flatten()
x_train.append(im_train_0)
y_train.append(0)
datapath = './data/7_29trainData/1'
outpath = './data/gray_data/'
filelist = []
for i in os.listdir(datapath):
filelist.append(i)
length = len(filelist)
for i in range(0,length):
impath = datapath + '/' + filelist[i]
im = cv2.imread(impath)
# 转灰度
im_gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
#输出灰度图到某文件夹
# outname = outpath + '/' + filelist[i]
# cv2.imwrite(outname,im_gray)
#调整所有图片为统一大小
width = 128
height = 128
dim = (width,height)
im_train_size1 = cv2.resize(im_gray, dim, interpolation = cv2.INTER_AREA)
#3.把128*128的图片降维
im_train_1 = im_train_size1.flatten()
x_train.append(im_train_1)
y_train.append(1)
y_test = []
x_test = []
datapath = './data/7_29testData/0'
outpath = './data/gray_data/'
filelist = []
for i in os.listdir(datapath):
filelist.append(i)
length = len(filelist)
for i in range(0,length):
impath = datapath + '/' + filelist[i]
im = cv2.imread(impath)
# 转灰度
im_gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
#输出灰度图到某文件夹
# outname = outpath + '/' + filelist[i]
# cv2.imwrite(outname,im_gray)
#调整所有图片为统一大小
width = 128
height = 128
dim = (width,height)
im_test_size0 = cv2.resize(im_gray, dim, interpolation = cv2.INTER_AREA)
#3.把128*128的图片降维
im_test_0 = im_test_size0.flatten()
x_test.append(im_test_0)
y_test.append(0)
datapath = './data/7_29testData/1'
outpath = './data/gray_data/'
filelist = []
for i in os.listdir(datapath):
filelist.append(i)
length = len(filelist)
for i in range(0,length):
impath = datapath + '/' + filelist[i]
im = cv2.imread(impath)
# 转灰度
im_gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
#输出灰度图到某文件夹
# outname = outpath + '/' + filelist[i]
# cv2.imwrite(outname,im_gray)
#调整所有图片为统一大小
width = 128
height = 128
dim = (width,height)
im_test_size1 = cv2.resize(im_gray, dim, interpolation = cv2.INTER_AREA)
#3.把128*128的图片降维
im_test_1 = im_test_size1.flatten()
x_test.append(im_test_1)
y_test.append(1)
y_test = np.array(y_test).reshape(1, -1)
y_train = np.array(y_train).reshape(1, -1)
y_test = np.reshape(y_test,(200, 1))
y_train = np.reshape(y_train,(1525, 1))
forest = RandomForestClassifier(n_estimators=10000, n_jobs=-1, random_state=0)
forest.fit(x_train, y_train)
score = forest.score(x_test, y_test)
print(score)















 438
438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









