







目录
5、ClickHouse VS Hologres VS Doris 异同
1、变化维、退化维、一致性维度、维度退化
①退化维和维度退化:
什么是退化维(Degenerate Dimensions) 退化维的定义是Ralph Kimball提出来的。一般来说事实表中的外键都对应一个维表,维的信息主要存放在维表中;但是退化维仅仅是事实表中的一列,这个维的相关信息都在这一 列中,没有维表与之相关联。比如:发票号,序列号等等。
那么退化维有什么作用呢?
a、退化维具有普通维的各种操作,比如:上卷,切片,切块等。
b、如果存在退化维,那么在ETL的过程将会变得容易。
c、它可以让group by等操作变得更快。
维度退化:将维度退化到事实表中,减少事实表和维度表的关联
②缓慢变化维
缓慢变化维(Slowly Changing Dimensions,SCD): 它的提出是因为在现实世界中,维度的属性并不是静态的,它会随着时间的流失发生缓慢的变化。
这种随时间发生变化的维度,一般被称为缓慢变化维;并且把处理维度表的历史变化信息的问题称为处理缓慢变化维的问题,有时也简称为处理SCD的问题。
处理缓慢变化维方法通常分为3种:
a、直接覆盖原值
b、添加维度行-拉链表
c、添加属性列-变化列
③一致性维度
在多维体系结构中,没有物理上的数据仓库,由物理上的数据集市组合成逻辑上的数据仓库。而且数据集市的建立是可以逐步完成的,最终组合在一起,成为一个数据仓库。如果分步建立数据集市的过程出现了问题,数据集市就会变成孤立的集市,不能组合成数据仓库,而一致性维度的提出正是为了解决这个问题。一致性维度的范围是总线架构中的维度,即可能会在多个数据集市中都存在的维度,这个范围的选取需要架构师来决定。一致性维度的内容和普通维度并没有本质上区别,都是经过数据清洗和整合后的结果。 一致性维度建立的地点是多维体系结构的后台(Back Room),即数据准备区。
在多维体系结构的数据仓库项目组内需要有专门的维度设计师,他的职责就是建立维度和维护维度的一致性。在后台建立好的维度同步复制到各个数据集市。这样所有数据集市的这部分维度都是完全相同的。建立新的数据集市时,需要在后台进行一致性维度处理,根据情况来决定是否新增和修改一致性维度,然后同步复制到各个数据集市。这是不同数据集市维度保持一致的要点。
在同一个集市内,一致性维度的意思是两个维度如果有关系,要么就是完全一样的,要么就是一个维度在数学意义上是另一个维度的子集。例如,如果建立月维度话,月维度的各种描述必须与日期维度中的完全一致,最常用的做法就是在日期维度上建立视图生成月维度。这样月维度就可以是日期维度的子集,在后续钻取等操作时可以保持一致。如果维度表中的数据量较大,出于效率的考虑,应该建立物化视图或者实际的物理表。这样,维度保持一致后,事实就可以保存在各个数据集市中。虽然在物理上是独立的,但在逻辑上由一致性维度使所有的数据集市是联系在一起,随时可以进行交叉探察等操作,也就组成了数据仓库。
2、数仓主题域划分方式
3、Flume拦截器
4、SparkSQL VS FlinkSQL异同
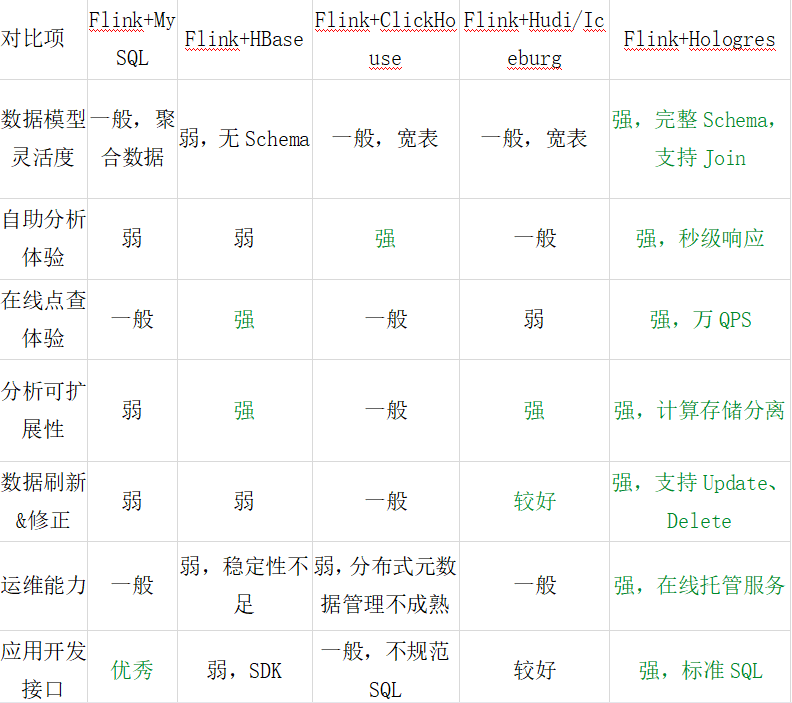
5、ClickHouse VS Hologres VS Doris 异同
Hologres与Flink高度兼容,支持完整的schema,源表、结果表、维表join都支持,能够达到上万秒的QPS写入,实现高性能写入与更新。
Schema是什么?_禅与计算机程序设计艺术的博客-CSDN博客
6、讲述一下Flink状态机制
Flink 内置的很多算子,包括源 source,数据存储 sink 都是有状态的。在 Flink 中,状态始终与特定算子相关联。Flink 会以 checkpoint 的形式对各个任务的 状态进行快照,用于保证故障恢复时的状态一致性。Flink 通过状态后端来管理状态 和 checkpoint 的存储,状态后端也可以有不同的配置选择。
延申:
①、应用架构
问题:公司怎么提交的实时任务,有多少 Job Manager?
解答:
1. 我们使用 yarn session 模式提交任务。每次提交都会创建一个新的 Flink 集群,为每一个 job 提供一个 yarn-session,任务之间互相独立,互不影响, 方便管理。任务执行完成之后创建的集群也会消失。线上命令脚本如下:
bin/yarn-session.sh -n 7 -s 8 -jm 3072 -tm 32768 -qu root.*.* -nm *-* -d
其中申请 7 个 taskManager,每个 8 核,每个 taskmanager 有 32768M 内存。
2. 集群默认只有一个 Job Manager。但为了防止单点故障,我们配置了高可用。 我们公司一般配置一个主 Job Manager,两个备用 Job Manager,然后结合 ZooKeeper 的使用,来达到高可用。
②、压测和监控
问题:怎么做压力测试和监控?
解答:我们一般碰到的压力来自以下几个方面:
一,产生数据流的速度如果过快,而下游的算子消费不过来的话,会产生背压。 背压的监控可以使用 Flink Web UI(localhost:8081) 来可视化监控,一旦报警就能知道。一般情况下背压问题的产生可能是由于 sink 这个 操作符没有优化好,做一下 优化就可以了。比如如果是写入 ElasticSearch, 那么可以改成批量写入,可以调 大 ElasticSearch 队列的大小等等策略。
二,设置 watermark 的最大延迟时间这个参数,如果设置的过大,可能会造成内存的压力。可以设置最大延迟时间小一些,然后把迟到元素发送到侧输出流中去。 晚一点更新结果。或者使用类似于 RocksDB 这样的状态后端, RocksDB 会开辟堆外存储空间,但 IO 速度会变慢,需要权衡。
三,还有就是滑动窗口的长度如果过长,而滑动距离很短的话,Flink 的性能会下降的很厉害。我们主要通过时间分片的方法,将每个元素只存入一个“重叠窗 口”,这样就可以减少窗口处理中状态的写入。(详情链接:Flink 滑动窗口优化)
四,状态后端使用 RocksDB,还没有碰到被撑爆的问题
③、为什么用 Flink
问题:为什么使用 Flink 替代 Spark?
解答:主要考虑的是 flink 的低延迟、高吞吐量和对流式数据应用场景更好的支持;另外,flink 可以很好地处理乱序数据,而且可以保证 exactly-once 的状态一致性。
④、checkpoint 的理解
问题:如何理解Flink的checkpoint
解答:Checkpoint是Flink实现容错机制最核心的功能,它能够根据配置周期性地基于Stream中各个Operator/task的状态来生成快照,从而将这些状态数据定期持久化存储下来,当Flink程序一旦意外崩溃时,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序数据异常。他可以存在内存,文件系统,或者 RocksDB。
⑤、exactly-once 的保证
问题:如果下级存储不支持事务,Flink 怎么保证 exactly-once?
解答:端到端的 exactly-once 对 sink 要求比较高,具体实现主要有幂等写入和 事务性写入两种方式。幂等写入的场景依赖于业务逻辑,更常见的是用事务性写入。 而事务性写入又有预写日志(WAL)和两阶段提交(2PC)两种方式。
如果外部系统不支持事务,那么可以用预写日志的方式,把结果数据先当成状态保存,然后在收到 checkpoint 完成的通知时,一次性写入 sink 系统。
⑥、海量 key 去重
问题:怎么去重?考虑一个实时场景:双十一场景,滑动窗口长度为 1 小时, 滑动距离为 10 秒钟,亿级用户,怎样计算 UV?
解答:使用类似于 scala 的 set 数据结构或者 redis 的 set 显然是不行的, 因为可能有上亿个 Key,内存放不下。所以可以考虑使用布隆过滤器(Bloom Filter) 来去重。
⑦、checkpoint 与 spark 比较
问题:Flink 的 checkpoint 机制对比 spark 有什么不同和优势?
解答: spark streaming 的 checkpoint 仅仅是针对 driver 的故障恢复做了数据和元数据的checkpoint。而 flink 的 checkpoint 机制要复杂了很多,它采用的是轻量级的分布式快照,实现了每个算子的快照,及流动中的数据的快照。
⑧、watermark 机制
问题:请详细解释一下 Flink 的 Watermark 机制。
解答:在使用 EventTime 处理 Stream 数据的时候会遇到数据乱序的问题,流处理从 Event(事 件)产生,流经 Source,再到 Operator,这中间需要一定的时间。虽然大部分情况下,传输到 Operator 的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络延迟等原因而导致乱序的产生,特别是使用 Kafka 的时候,多个分区之间的数据无法保证有序。因此, 在进行 Window 计算的时候,不能无限期地等下去,必须要有个机制来保证在特定的时间后, 必须触发 Window 进行计算,这个特别的机制就是 Watermark(水位线)。Watermark是用于处理乱序事件的。
在 Flink 的窗口处理过程中,如果确定全部数据到达,就可以对 Window 的所有数据做窗口计算操作(如汇总、分组等),如果数据没有全部到达,则继续等待该窗口中的数据全部到达才开始处理。这种情况下就需要用到水位线(WaterMarks)机制,它能够衡量数据处理进度(表达数据到达的完整性),保证事件数据(全部)到达 Flink 系统,或者在乱序及延迟到达时,也能够像预期一样计算出正确并且连续的结果。
⑨、exactly-once 如何实现
问题:Flink 中 exactly-once 语义是如何实现的,状态是如何存储的?
解答:Flink 依靠 checkpoint 机制来实现 exactly-once 语义,如果要实现端到端 的 exactly-once,还需要外部 source 和 sink 满足一定的条件。状态的存储通过状态 后端来管理,Flink 中可以配置不同的状态后端。
⑩、CEP
问题:Flink CEP 编程中当状态没有到达的时候会将数据保存在哪里?
解答:在流式处理中,CEP 当然是要支持 EventTime 的,那么相对应的也要支持数据的迟到现象,也就是 watermark的处理逻辑。CEP对未匹配成功的事件序 列的处理,和迟到数据是类似的。在 Flink CEP 的处理逻辑中,状态没有满足的和迟到的数据,都会存储在一个 Map 数据结构中,也就是说,如果我们限定判断事件 序列的时长为5 分钟,那么内存中就会存储 5 分钟的数据,这在我看来,也是对内存的极大损伤之一。
@11、三种时间语义
问题:Flink 三种时间语义是什么,分别说出应用场景?
解答:
Event Time:这是实际应用最常见的时间语义,指的是事件创建的时间,往往跟watermark结合使用
Processing Time:指每一个执行基于时间操作的算子的本地系统时间,与机器相关。适用场景:没有事件时间的情况下,或者对实时性要求超高的情况
Ingestion Time:指数据进入Flink的时间。适用场景:存在多个 Source Operator 的情况下,每个 Source Operator 可以使用自己本地系统时钟指派 Ingestion Time。后续基于时间相关的各种操作, 都会使用数据记录中的 Ingestion Time
@12、数据高峰的处理
问题:Flink 程序在面对数据高峰期时如何处理?
解答:使用大容量的 Kafka 把数据先放到消息队列里面作为数据源,再使用 Flink 进行消费,不过这样会影响到一点实时性。
7、sum() over(partition by *** order by *** desc) 加不加order by 有什么区别
有order by 是依次累加,没有order by 是全量累加
SELECT id
,num
,datadate
,SUM(num) OVER (PARTITION BY id ORDER BY datadate DESC ) rk
,SUM(num) OVER (PARTITION BY id ) rm
FROM (
SELECT 1 id
,2 num
,'20220901' datadate
UNION ALL
SELECT 1 id
,2 num
,'20220902' datadate
UNION ALL
SELECT 2 id
,2 num
,'20220901' datadate
) t
;














 309
309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









