







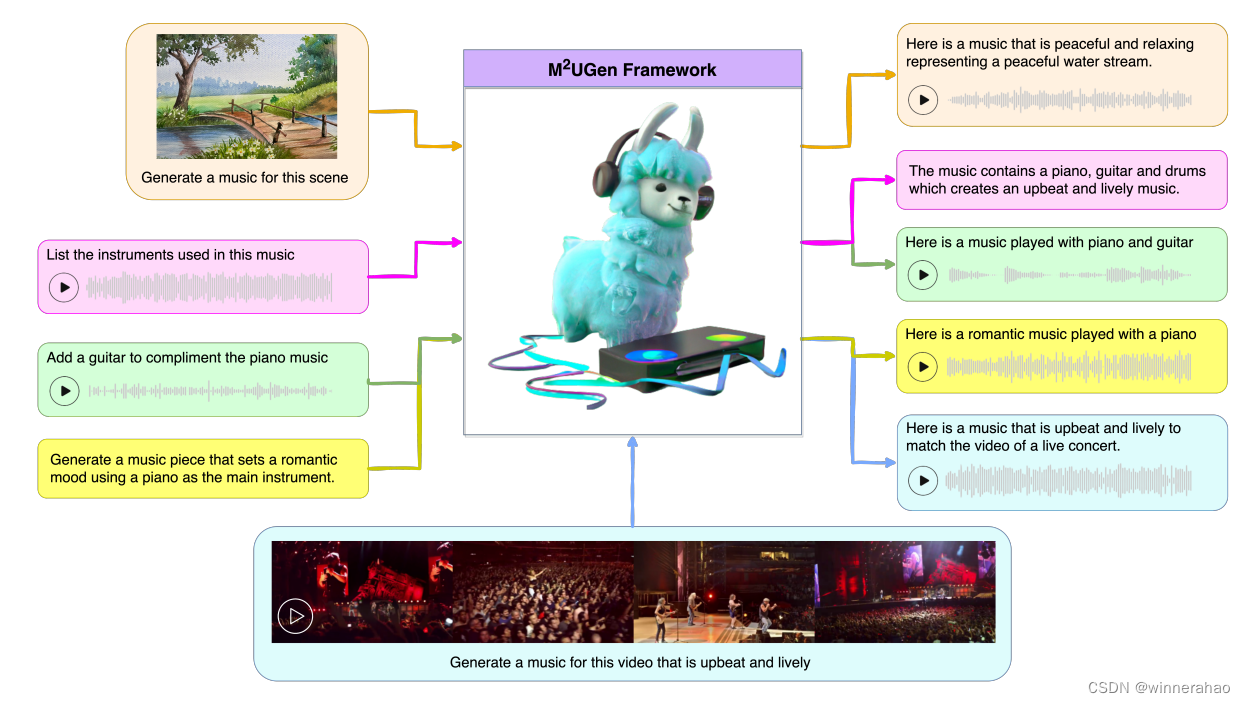
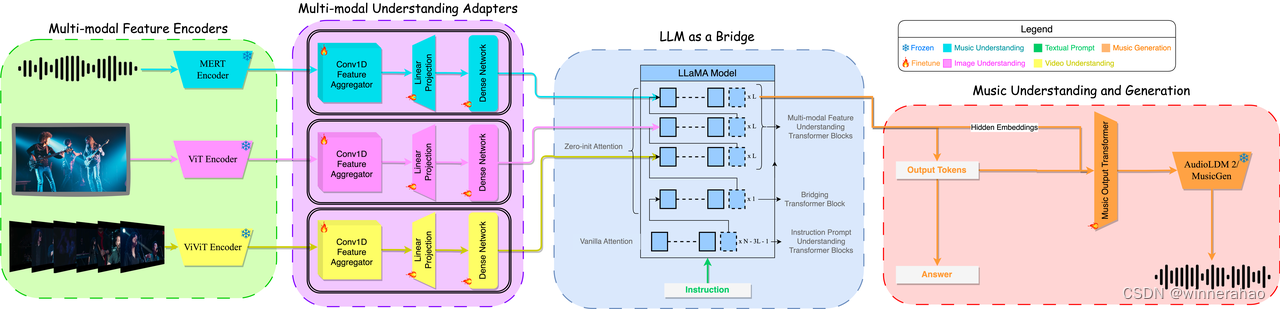
M2UGen 模型是一种音乐理解和生成模型,能够进行音乐问答,还可以从文本、图像、视频和音频生成音乐,以及音乐编辑。该模型利用 MERT 等编码器进行音乐理解、ViT 进行图像理解和 ViViT 进行视频理解,并使用 MusicGen/AudioLDM2 模型作为音乐生成模型(音乐解码器),再加上适配器和 LLaMA 2 模型,使该模型能够多种能力。
论文名称:《M2UGen: Multi-modal Music Understanding and Generation with the Power of Large Language Models》
项目地址:https://github.com/shansongliu/M2UGen
体验网址:https://huggingface.co/spaces/M2UGen/M2UGen-Demo
目录
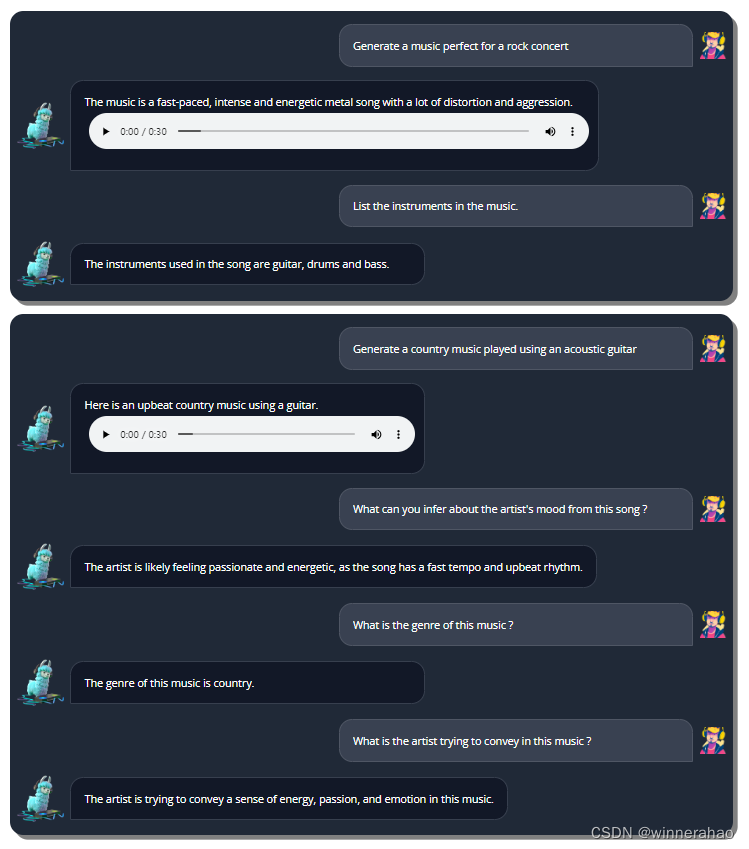
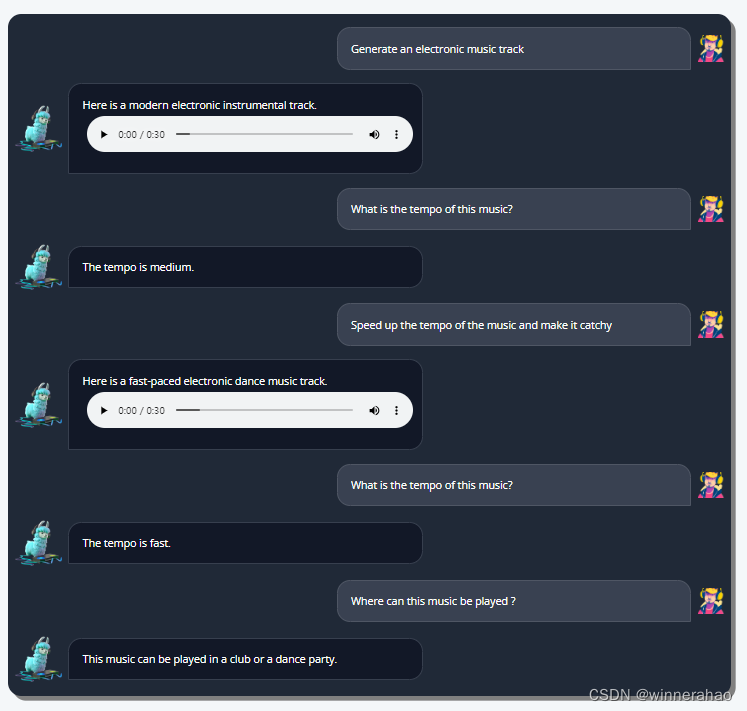
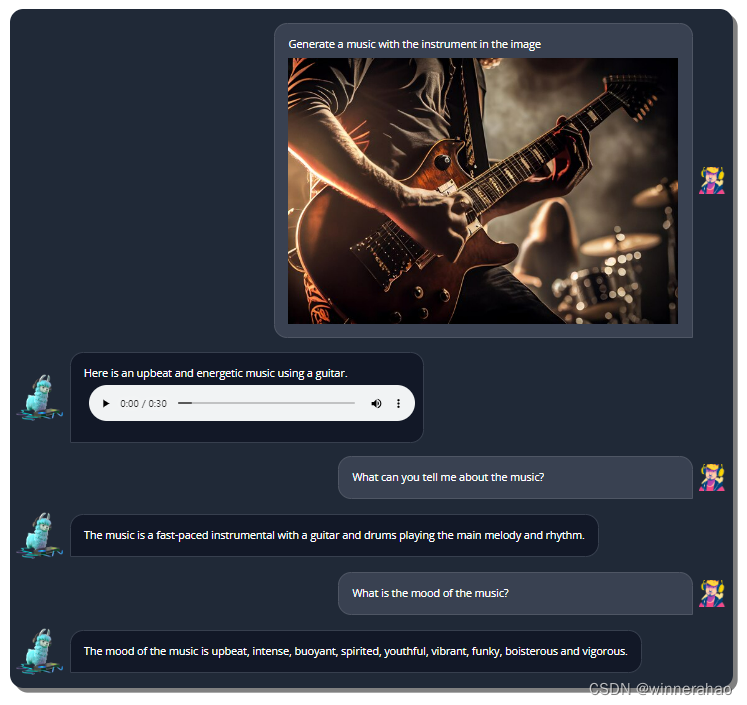
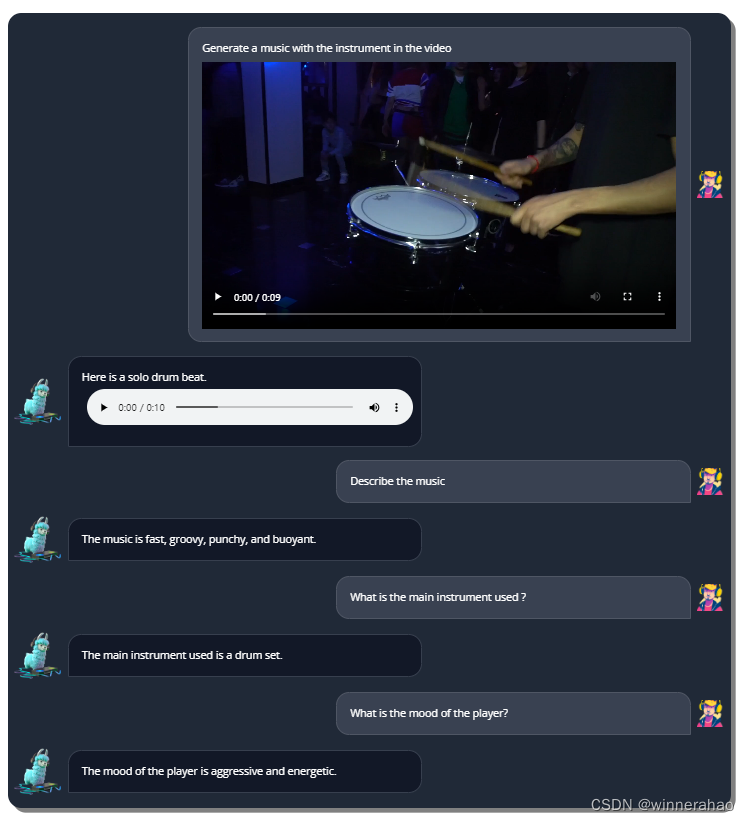
结果先行
摘要
当前利用大型语言模型 (LLM) 的研究正在经历激增。许多作品利用这些模型强大的推理能力来理解各种模式,如文本、语音、图像、视频等。它们还利用LLMs来理解人类意图并生成所需的输出,如图像、视频和音乐 然而,利用LLMs将理解和生成结合起来的研究仍然有限,并且处于起步阶段。为了解决这一差距,文章引入了多模态音乐理解和生成(M2UGen)框架,该框架集成了LLMs理解和生成不同模态音乐的能力。M2UGen 框架专门用于通过使用预训练的 MERT、ViT 和 ViViT 模型来释放不同灵感来源的创造潜力,包括音乐、图像和视频。为了实现音乐生成,探索了 AudioLDM 2 和 MusicGen 的使用。通过 LLaMA 2 模型的集成,实现了多模式理解和音乐生成之间的桥梁。此外,利用 MU-LLaMA 模型生成支持文本/图像/视频到音乐生成的广泛数据集,从而促进 M2UGen 框架的训练。通过对提出的框架进行了彻底的评估。实验结果表明,模型达到或超过了当前最先进模型的性能。
对文章中的其他背景介绍部分,这里就不做过多介绍了~~
直接进入正题!
文章主要工作:
- 音乐理解+多模态音乐生成
- 数据集生成
多模态的特征Encoder(Multi-modal Feature Encoders)
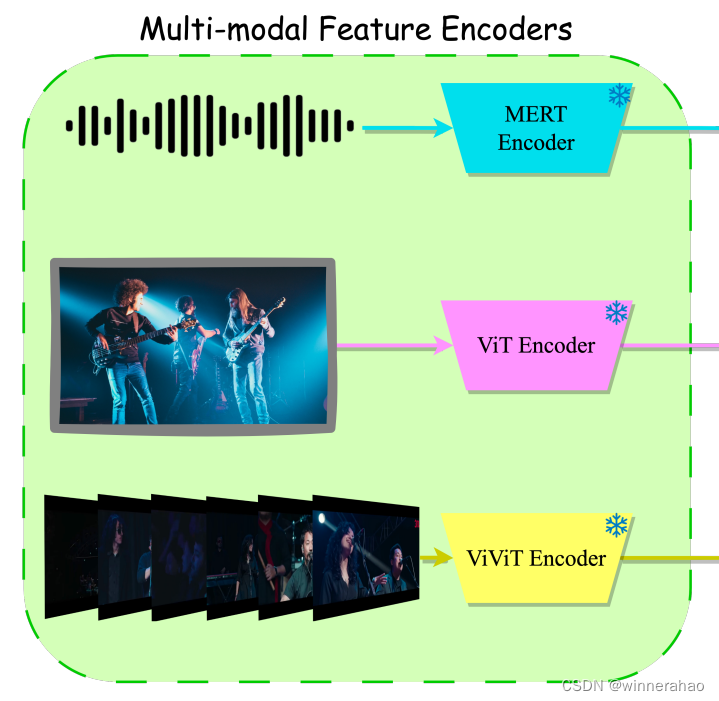
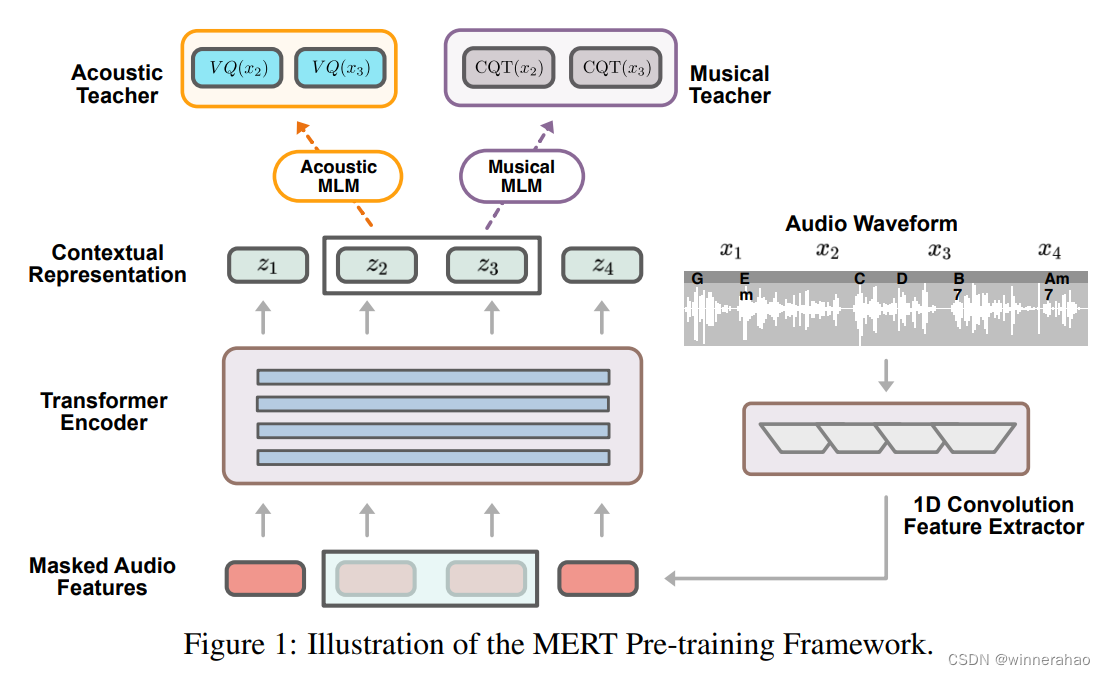
音频:MERT
最终的Output: (25, 1024), which is obtained by stacking the 24 hidden layers and the final output layer of the MERT model.
图片:ViT
最终的Output: (197, 768) where 197 is the number of 16×16 patches in a 224 × 224 input image plus the final output layer, while 768 corresponds to the hidden size of the Transformer.
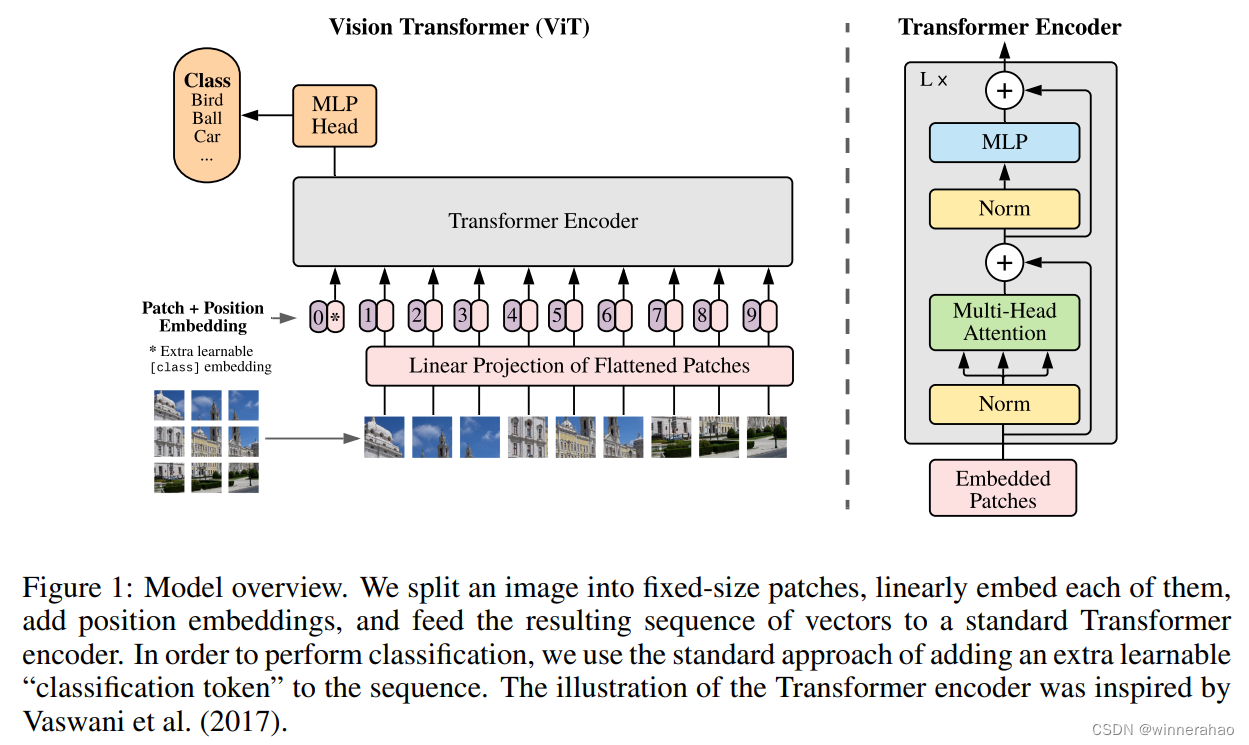
视频:ViViT
最终输出 Output: (3137, 768) where 3137 is derived from the total count of 16×16 patches sampled uniformly from 32 frames of size 224 × 224, including the final output layer, and 768 is the hidden size of the Transformer.

多模态理解适配单元(Multi-modal Understanding Adapters)
目的: 为了整合多模态Encoder输出结果,最终作为llama2的输入特征,最终维度4096
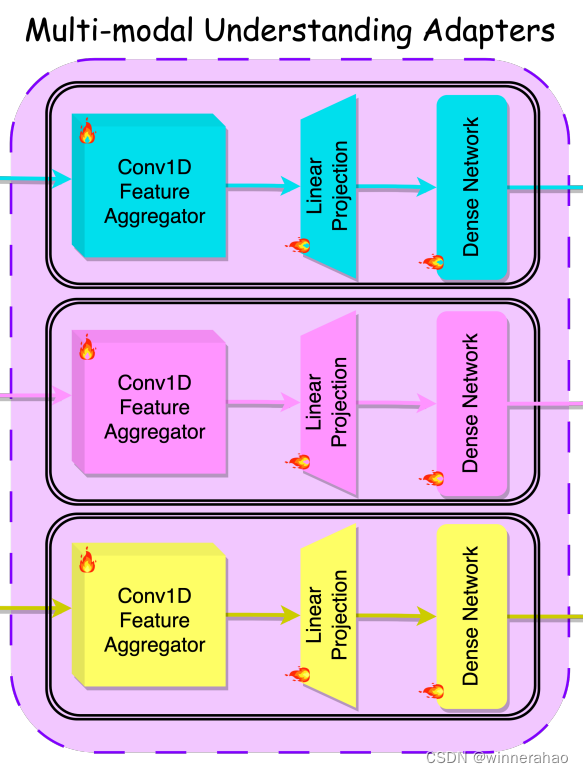
- 不同模态适配相同结构的adapter
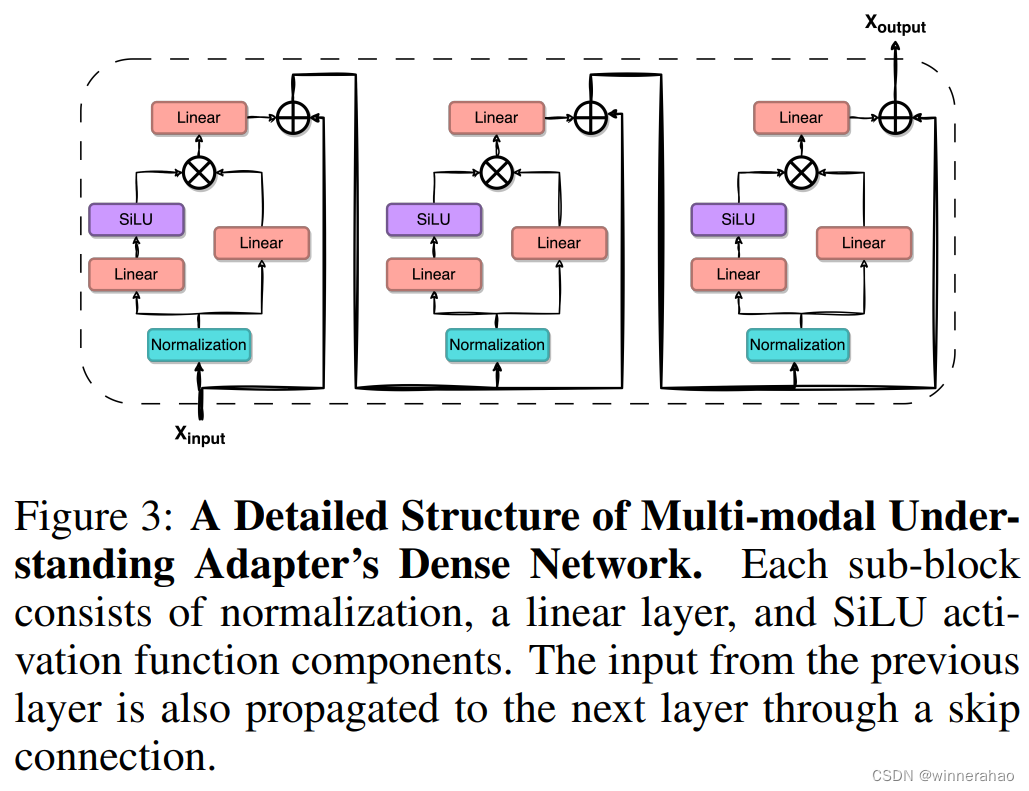
- Dense结构
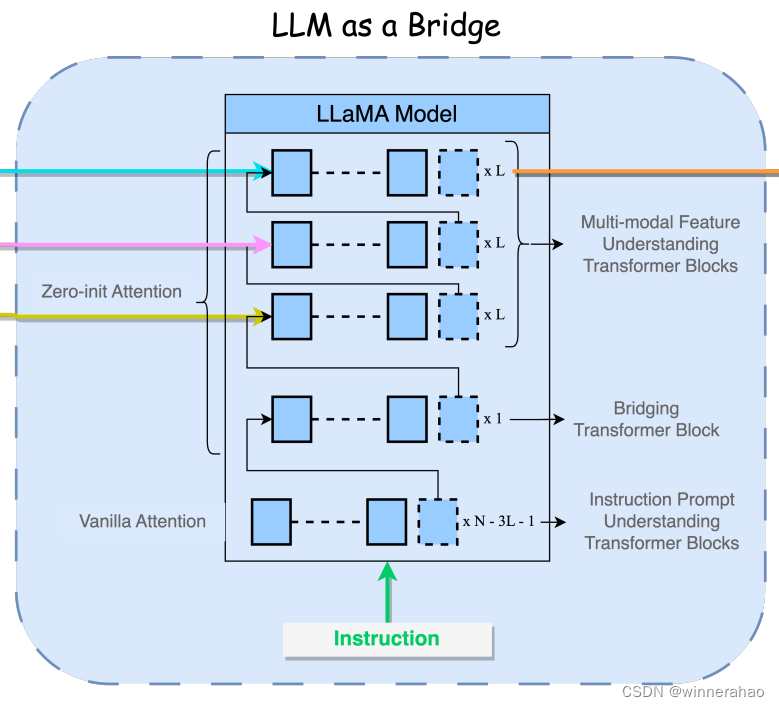
LLM(LLAMA)(LLM as a Bridge )
总共N=32层隐藏层,从顶部(最后)层开始每第 L 层(L = 6)引入一个特定于模态的信息。对于较低的 (N − 3L − 1) 隐藏层,采用普通注意力,而上面的其余层则采用零初始化注意力。输入指令提示被输入到 Transformer 底部的第一层,而来自音乐、图像和视频的嵌入向量分别导入到从顶层(最后一层)。通过这种方法,LLaMA 2 模型可以有效地推理和理解多模态输入。
音乐理解与生成(Music Understanding and Generation)
M2UGen 模型结合了 [AUDi] 形式的专门音频tokens,其中 i ∈ {0, 1, · · · , 7},以区分音乐问答和生成任务 。 音频token的数量是一个超参数,决定了音乐生成过程中音乐输出 Transformer(也称为输出投影仪)的输入维度。在训练阶段,通过将此类音频token附加到输出的末尾来调整包含音乐作为输出的指令集。在推理阶段,仅当指令提示需要音乐输出时,M2UGen 模型才会生成音频token。通过这种方法,M2UGen 模型展示了在同一框架内生成用于音乐问答的纯文本输出和用于音乐生成的音乐输出的能力。
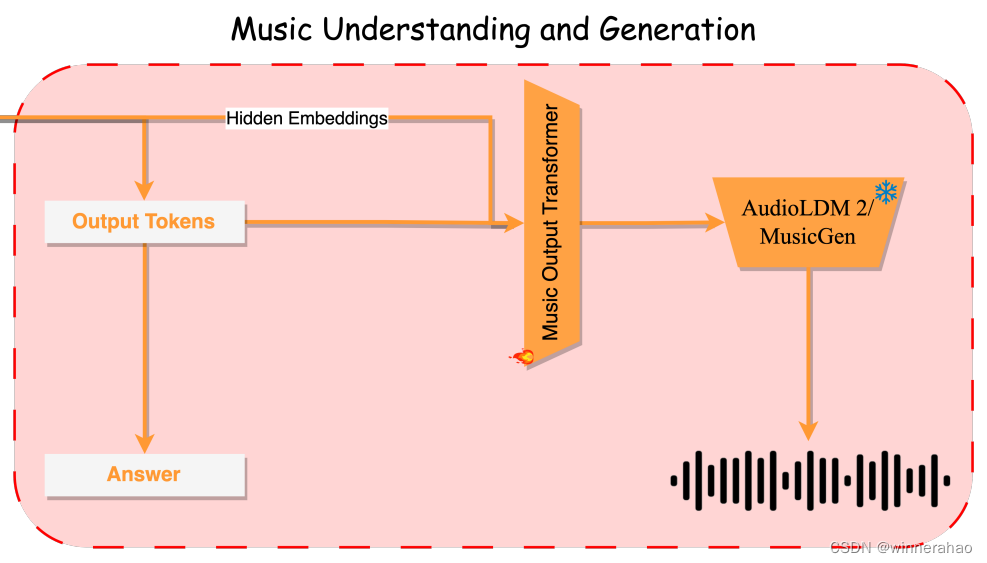
在执行音乐生成任务时,利用输出投影的输出来调制音乐生成过程。由于每个输出token都映射到 LLaMA 2 模型最后一层中的隐藏嵌入特征,因此将与音频token相对应的这些隐藏嵌入与音频标记嵌入本身结合起来,作为输出投影的输入。 输出投影生成的后续输出充当 AudioLDM 2 / MusicGen模型的关键调节信号,指导最终输出音乐的生成。
模型训练方法(Training Method)
从头开始训练 MLLM 模型的计算成本很高,这导致多个模型采用 LoRA 微调方法。在M2UGen的训练方法中,通过冻结编码器和生成模型来减轻计算负担,将训练工作重点放在多模态理解适配器和输出投影上。该策略不仅降低了计算成本,还提高了训练效率。为了进一步简化训练过程并最小化可训练参数的数量,通过应用LoRA方法来训练LLaMA 2模型。在训练流程中,利用以下损失函数来指导优化过程:
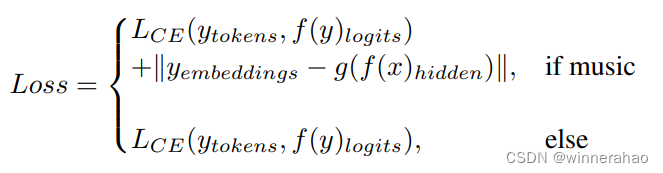
其中 y-tokens 表示目标输出token,y-embeddings 表示 AudioLDM 2/MusicGen 的目标embedding,f(·) 表示 M2UGen 的 LLaMA 2 模型的输出,g(·) 表示 M2UGen 的输出投影层的输出,LCE 是交叉熵 (CE)损失。M2UGen 模型使用的损失函数可以是单独的 CE,也可以是 CE 和均方误差 (MSE) 的组合。在训练期间,如果任务仅涉及文本标记生成,则模型仅由 CE 损失指导。如果任务涉及音乐生成,则 CE 和 MSE 一起使用,MSE 在输出投影层生成的条件嵌入和来自音乐生成模型的目标音乐字幕的文本编码之间计算。这种双损失策略确保 M2UGen 模型擅长文本token生成和生成嵌入以调节下游音乐生成模型(AudioLDM 2 或 MusicGen)。
数据集构建(Music Oriented Instruction Dataset)
MUCaps Dataset
- 文本-音乐,1200小时,来源于AudioSet
- 使用MU-LLAMA预标注:Describe the music in detail, including aspects such as instruments used, tempo, and the mood of the song
MUEdit Dataset
- 55.69小时,10秒长度,使用MU-LLAMA预标注
- 从音乐池中选择对,使用节奏、节拍、音高和幅度等指标来确保所选对表现出相似的节奏特征。
- 对于每个选定的对,MPT-7B 模型用于生成指令。
- 为了创建对话的人性化一面,模型提供了音乐文件的标题作为输入
MUImage Dataset
- 来自AudioSet with paired video,从每个视频中随机选择一帧作为输入图像 为使用获取的所有音乐文件生成字幕MU-LLaMA 模型(使用MU-LLAMA预标注)
- 使用BLIP图像字幕模型为相应图像生成字幕。(BLIP进行图文标注)
- 对于每对音乐和图像,采用MPT-7B模型来生成指令,音乐和图像标题用作输入。
MUVideo Dataset
- 来自AudioSet with paired video
- 为使用获取的所有音乐文件生成字幕MU-LLaMA模型(使用MU-LLAMA预标注)
- 使用 VideoMAE 字幕模型生成相应视频的字幕
- 对于每对音乐和视频,采用MPT-7B模型来生成指令,音乐和视频字幕用作输入
模型技术评估(Model Evaluation)
主要对比了在音乐理解能力(Music Understanding )、文生音乐能力( Text to Music Generation)、音乐编辑能力(Prompt Based Music Editing)、多模态音乐生成能力(Multi-modal Music Generation)等方面的效果,以及进行音乐生成主观评价(Subjective Evaluation for Music Generation),整体效果还是SOTA的!
总结
文章主要介绍了M2UGen模型,该模型利用大语言模型(LLM)在统一框架内实现音乐理解和多模态音乐生成。 此外,文章提出了一种生成用于训练模型的数据集的综合方法。 实验表明,提出的 M2UGen 模型在各种任务中都优于或实现了 SOTA 性能,包括音乐理解、音乐编辑和文本/图像/视频到音乐生成。 未来的工作将集中于进一步增强模型的细粒度音乐理解能力,以及提高生成的音乐和输入指令之间的相关性。
End
感谢你看到这里,也欢迎关注个人公众号:二度简并,一个有趣有AI的AIGC公众号: 关注AI、深度学习、计算机视觉、语音信号处理、AIGC等相关技术。欢迎你的关注哦~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









