







B站弹幕和评论爬虫
最近想爬下B站的弹幕和评论,发现网上找到的教程基本都失效了,毕竟爬虫和反爬是属于魔高一尺、道高一丈的双方。对于爬虫这一方,爬取网站数据,一般目的都是比较明确的,废话不多说,开干!
https://comment.bilibili.com/xxxx.xml在浏览器打开可以看到如下:
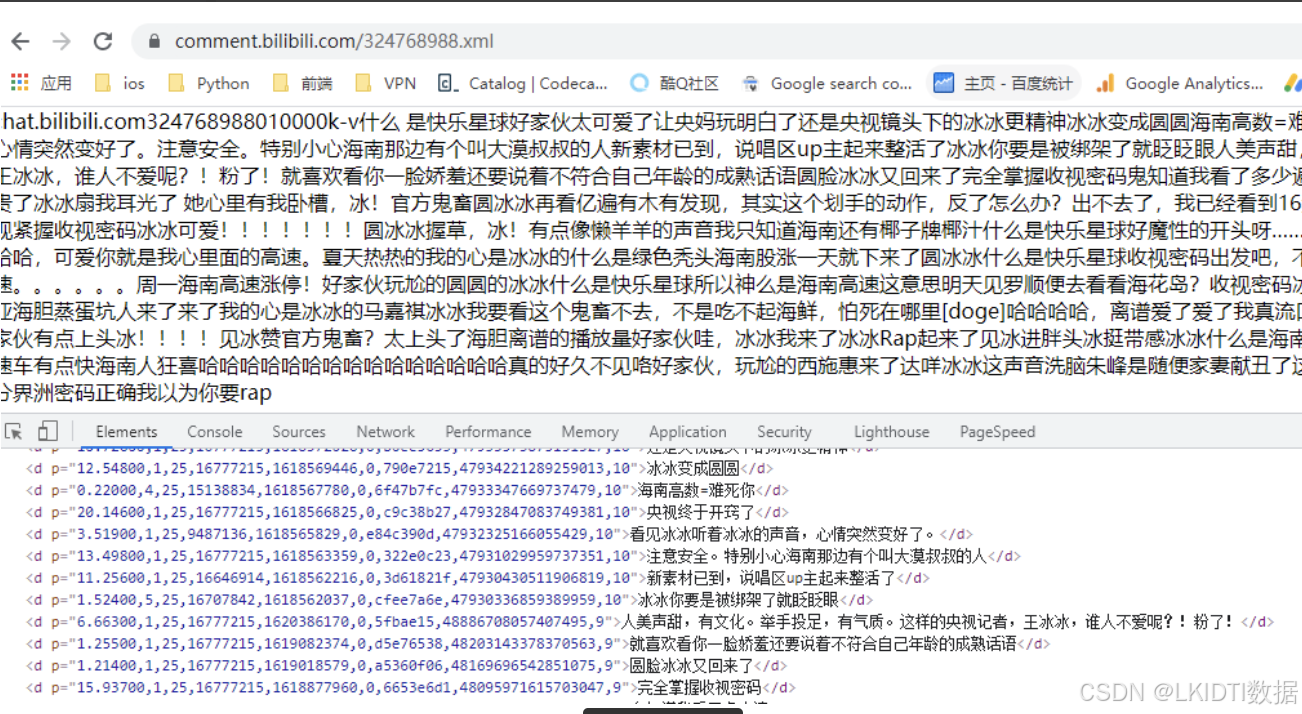
数据还是非常干净的,那么下一步就是看如何获取这个 xml 的 url 地址了,也就是如何获取 324768988 ID接下来我们搜索整个网页的源码,可以发现如下情况

也就是说,我们需要的 ID 是可以在 script 当中获取的,下面就来编写一个提取 script 内容的函数
def getHTML_content(self):
# 获取该视频网页的内容
response = requests.get(self.BVurl, headers = self.headers)
html_str = response.content.decode()
html=etree.HTML(html_str)
result=etree.tostring(html)
return result
def get_script_list(self,str):
html = etree.HTML(str)
script_list = html.xpath("//script/text()")
return script_list
拿到所有的 script 内容之后,我们再来解析我们需要的数据
script_list = self.get_script_list(html_content)
# 解析script数据,获取cid信息
for script in script_list:
if '[{"cid":' in script:
find_script_text = script
final_text = find_script_text.split('[{"cid":')[ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2143
2143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









