







77. 组合
解题思路:
(DFS) O(Cnk × k)
由题意可知,需返回所有可能的k个数的组合,那么可以利用 深度优先搜索 递归遍历,依次填入不同的数字到k个位置,为了防止填入重复的组合,每次应更新当前位置可填入的数字。
(1)传入三个数到深搜函数(用 k 记录当前组合中还需填入的数字个数):
深度优先搜索,枚举当前位置选哪个数,并且记录当前还有几个位置需要进行填入,每填入一个数字到组合中时,将需要填入的位置减一,当所有k个位置上都填有数字时,即可将当前组合加入结果中,然后进行回溯,重复以上过程,将所有组合加入结果中。
C++代码:
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
vector<vector<int>> combine(int n, int k) {
dfs(n, k, 1); //当前组合需要填入 k 个数字,且可从 1 开始填入
return res;
}
void dfs(int n, int k, int start) { // k 表示当前组合还需要在k个位置上填入数字
if (!k) { // 当 k == 0 时,则说明已经选好 k 个数,将方案记录下来
res.push_back(path);
return;
}
for (int i = start; i <= n; i ++) {
path.push_back(i);
dfs(n, k - 1, i + 1); //当前位置的数填好后,递归填入下一个位置的数字,即从 i+1 开始填入, 还需要填入 k - 1 个数字
path.pop_back();
}
}
};
(2)传入四个数到深搜函数(用 u 记录当前组合中填入的数字个数):
深度优先搜索,每层枚举第 u 个数选哪个,一共枚举 k 层。由于这道题要求组合数,不考虑数的顺序,所以我们需要再记录一个值 start,表示当前数需要从几开始选,来保证所选的数递增。
时间复杂度分析:一共有 Cnk 个方案,另外记录每个方案时还需要 O(k) 的时间,所以时间复杂度是 O(Cnk × k)。
C++ 代码:
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
vector<vector<int>> combine(int n, int k) {
dfs(0, 1, n, k);
return ans;
}
void dfs(int u, int start, int n, int k)
{
if (u == k)
{
ans.push_back(path);
return ;
}
for (int i = start; i <= n; i ++ )
{
path.push_back(i);
dfs(u + 1, i + 1, n, k);
path.pop_back();
}
}
};
216. 组合总和 III
解题思路:
(DFS) O(C9k × k)
暴力搜索出所有从9个数中选 k 个数,记录所有数的和等于 n 的方案。
为了避免重复计数,比如 {1, 2, 3} 和 {1, 3, 2} 是同一个集合,我们对集合中的数定序,每次枚举时,要保证同一方案中的数严格递增,即如果上一个选的数是 x,那我们从 x+1 开始枚举当前数字。
时间复杂度分析:从9个数中选 k 个总共有 C9k 个方案,将每个方案记录下来需要 O(k) 的时间,所以时间复杂度是 O(C9k × k)。
C++ 代码:
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
vector<vector<int>> combinationSum3(int k, int n) {
dfs(k, n, 1);
return ans;
}
void dfs(int k, int n, int start)
{
if (!k)
{
if (!n) ans.push_back(path);
return;
}
for (int i = start; i <= 10 - k; i ++ )
if (n >= i * k)
{
path.push_back(i);
dfs(k - 1, n - i, i + 1);
path.pop_back();
}
}
};
17. 电话号码的字母组合
解题思路:
- 题目给定一个数字字符串,要求返回所有字母组合
- 可使用
dfs递归遍历组合中每一位可选取的字母 - 我们需要再记录一个值
u,表示当前应该填入字母组合中的第u个字母 - 当
u == digits.size()时,说明字母组合中的每个字母都选择好,此时将该字母组合记录到结果数组中,回溯后继续遍历。
C++代码:
class Solution {
public:
vector<string> res;
string path;
string strs[10] = {
"", "", "abc", "def",
"ghi", "jkl", "mno",
"pqrs", "tuv", "wxyz"
};
vector<string> letterCombinations(string digits) {
if (digits.empty()) return res;
dfs(digits, 0);
return res;
}
void dfs(string& digits, int u) {
if (u == digits.size()) {
res.push_back(path);
return;
}
for (auto c : strs[digits[u] - '0']) {
path.push_back(c);
dfs(digits, u + 1);
path.pop_back();
}
}
};
39. 组合总和
解题思路:
- 题目给定一个无重复元素的整数数组
nums和目标值target,找出不同的组合,使得组合中的元素和等于目标值,且同一个数字可重复被选取 - 为了避免重复计数,比如
{1, 2, 3}和{1, 3, 2}是同一个集合,我们对集合中的数定序,每次枚举时,记录当前可从nums数组的哪个下标的元素开始选取元素,保证选取的数下标非递减。 - 我们可先对数组进行排序预处理,可保证从小到大选取数字,可减少无效的枚举次数。
C++代码:
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
vector<vector<int>> combinationSum(vector<int>& nums, int target) {
sort(nums.begin(), nums.end());
dfs(nums, target, 0);
return res;
}
void dfs(vector<int>& nums, int target, int u) {
if (target == 0) {
res.push_back(path);
return;
}
for (int i = u; i < nums.size(); i++) {
if (nums[i] > target) break;
path.push_back(nums[i]);
dfs(nums, target - nums[i], i); // 不用i+1了,表示可以重复读取当前的数
path.pop_back();
}
}
};
40. 组合总和 II
解题思路:
这道题目和 39.组合总和 如下区别:
- 本题
nums中的每个数字在每个组合中只能使用一次。 - 本题数组
nums的元素可能有重复的,而 39.组合总和 是无重复元素的数组nums
最后本题和 39.组合总和 要求一样,解集不能包含重复的组合。
本题的难点在于区别2中:集合(数组nums)有重复元素,但还不能有重复的组合。我们 要去重的是同一树层上的“使用过”,同一树枝上的都是一个组合里的元素,不用去重。与 39.组合总和 套路相同,此题还需要加一个bool型数组used,用来 记录同一树层上的元素是否使用过。这个集合去重的重任就是used来完成的。
C++代码:
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
vector<vector<int>> combinationSum2(vector<int>& nums, int target) {
vector<bool> used(nums.size()); //记录同一树层上的元素是否使用过
sort(nums.begin(), nums.end());
dfs(nums, target, 0, used);
return res;
}
void dfs(vector<int>& nums, int target, int start, vector<bool>& used) {
if (target == 0) {
res.push_back(path);
return;
}
for (int i = start; i < nums.size(); i++) {
if (nums[i] > target) break;
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) continue; //当前元素和前一个元素相同,
//且前一个元素处于相同位置的所有组合已经遍历了一遍,当前元素无需重复相同操作,跳过接下来的操作
path.push_back(nums[i]);
used[i] = true;
dfs(nums, target - nums[i], i + 1, used);
used[i] = false;
path.pop_back();
}
}
};
131. 分割回文串
解题思路:
“dfs + 回溯”
dfs算法的过程其实就是一棵 递归树 ,所有的dfs算法的步骤大概有以下几步:
- 找到中止条件,即递归树从根节点走到叶子节点时的返回条件,此时一般情况下已经遍历完了从根节点到叶子结点的一条路径,往往就是我们需要存下来的一种 合法方案
- 如果还没有走到底,那么我们需要对当前层的所有可能选择方案进行 枚举 ,加入路径中,然后走向下一层
- 在枚举过程中,有些情况下需要对不可能走到底的情况进行预判,如果已经知道这条路不可能到达我们想去的地方,那我们干嘛还要一条路走到黑呢,这就是我们常说的 剪枝 的过程
- 当完成往下层的递归后,我们需要将当前层的选择状态进行清零,它下去之前是什么样子,我们现在就要让它恢复原状,也叫 恢复现场。该过程就是 回溯 ,目的是回到最初选择路口的起点,然后再判断有没有其他的路可以走。
将上述思路运用在该题中:
- 从第一个字符开始枚举,用
path数组存储 一条 从递归树根节点到叶子结点的 合法方案 ,用res数组存下 所有的合法方案 dfs过程的 中止条件 是当我们遍历完了所有字符,说明我们已经找到一条合法路径,此时将路径加入方案中- 进行 当前层的选择枚举子串 时,这里枚举从该字符到结尾的所有长度的子串,且该长度的子串为回文串时,我们将其加入路径中,然后 递归到下一层
- 当我们进行了下层的递归后,我们需要进行 回溯 ,也就是 恢复现场 ,目的是我们能够在该层重新做其他选择
C ++代码:
class Solution {
public:
vector<vector<string>> res; //所有方案
vector<string> path; //一个合法方案
vector<vector<string>> partition(string s) {
dfs(0, s); //从位置0开始dfs
return res;
}
void dfs(int u, string s)
{
if (u == s.size()) //遍历完整个字符串
{
res.push_back(path); //将路径加入方案
return;
}
for (int i = u; i < s.size(); i ++) //枚举从当前字符到结尾可以选择的长度
{
if (check(s, u, i)) //判断u ~ i是否为回文串
{
path.push_back(s.substr(u, i - u + 1)); //加入路径
dfs(i + 1, s); //递归下一层
path.pop_back(); //回溯
}
}
}
bool check(string s, int l, int r) //判断从l到r是否为回文串
{
while (l <= r)
{
if (s[l ++] != s[r --])
return false;
}
return true;
}
};
93. 复原 IP 地址
解题思路:
(暴力搜索) O(Cn−13)
直接暴力搜索出所有合法方案。
合法的IP地址由四个0到255的整数组成。我们直接枚举四个整数的位数,然后判断每个数的范围是否在0到255。
时间复杂度分析:一共 n 个数字,n−1 个数字间隔,相当于从 n−1个数字间隔中挑3个断点,所以计算量是 O(Cn−13)。
C++ 代码
class Solution {
public:
vector<string> ans;
vector<int> path;
vector<string> restoreIpAddresses(string s) {
dfs(0, 0, s);
return ans;
}
// u表示枚举到的字符串下标,k表示当前截断的IP个数,s表示原字符串
void dfs(int u, int k, string &s)
{
if (u == s.size())
{
if (k == 4)
{
string ip = to_string(path[0]);
for (int i = 1; i < 4; i ++ )
ip += '.' + to_string(path[i]);
ans.push_back(ip);
}
return;
}
if (k > 4) return;
unsigned t = 0;
for (int i = u; i < s.size(); i ++ )
{
if (i > u && s[u] == '0') break; //当前整数有前导0
t = t * 10 + s[i] - '0';
if (t >= 0 && t < 256)
{
path.push_back(t);
dfs(i + 1, k + 1, s);
path.pop_back();
}
}
}
};
78. 子集
解题思路:
(dfs + 回溯)
- 组合问题和分割问题都是收集树的叶子节点,而 子集问题是找树的所有节点
- 子集也是一种组合问题,因为它的集合是无序的,子集
{1,2}和 子集{2,1}是一样的 - 既然是无序,取过的元素不会重复取,写回溯算法的时候,for就要从
startIndex开始,而不是从0开始 - 以示例中nums = [1,2,3]为例把求子集抽象为树型结构,如下:
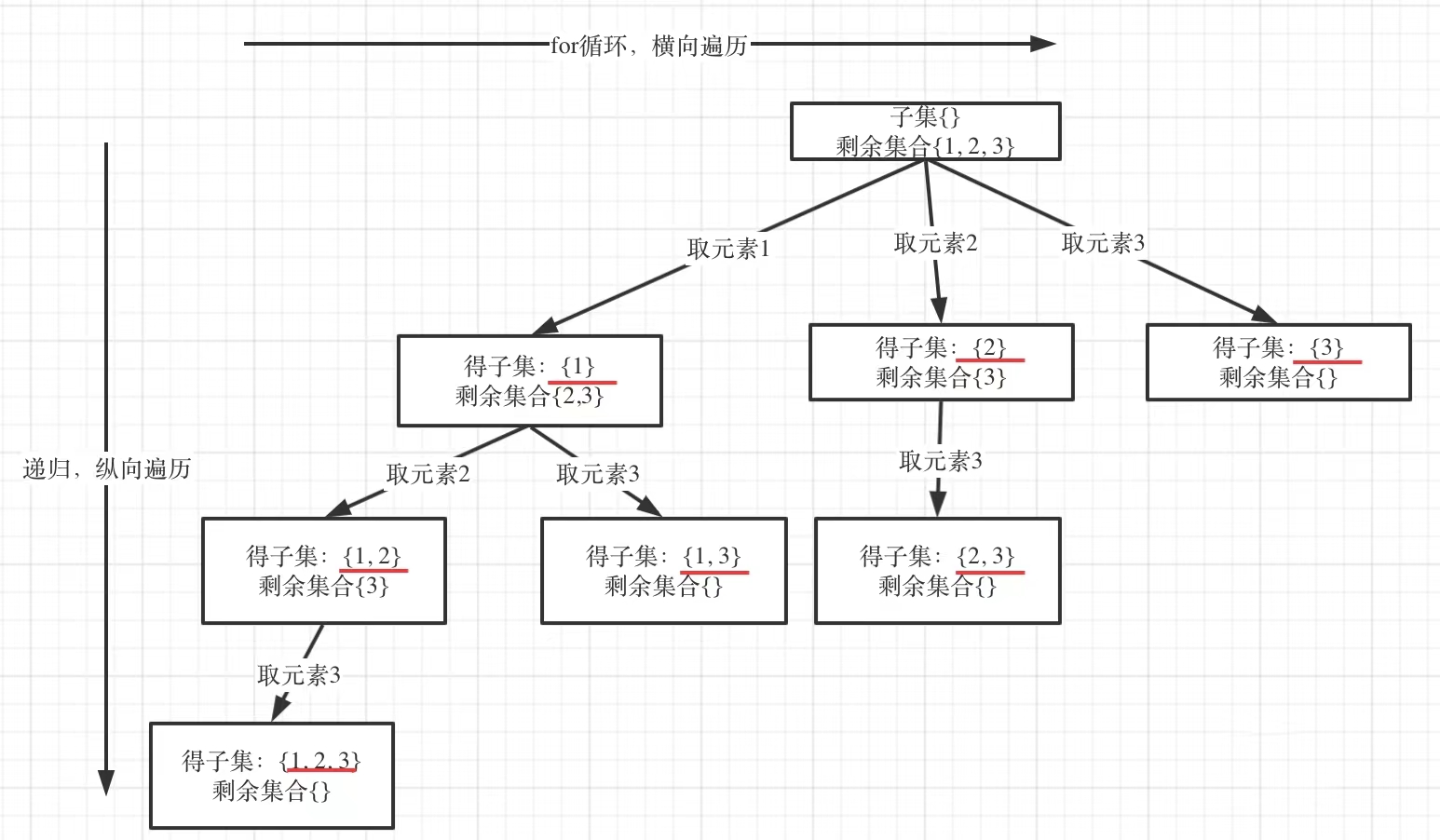
从图中红线部分,可以看出 遍历这个树的时候,把所有节点都记录下来,就是作为结果的子集集合 。
C++代码:
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
vector<vector<int>> subsets(vector<int>& nums) {
dfs(nums, 0);
return res;
}
void dfs(vector<int>& nums, int u) {
res.push_back(path); // 收集子集,要放在终止条件的上面,否则会漏掉自己
if (nums.size() == u) return; // 终止条件可以不加
for (int i = u; i < nums.size(); i++) {
path.push_back(nums[i]);
dfs(nums, i + 1);
path.pop_back();
}
}
};
90. 子集 II
解题思路:
本题的难点:集合(数组nums)有重复元素,但还不能有重复的组合。我们 要去重的是同一树层上的“使用过”,同一树枝上的都是一个组合里的元素,不用去重。与 78. 子集 套路相同,此题还需要加一个bool型数组used,用来 记录同一树层上的元素是否使用过。这个集合去重的重任就是used来完成的。
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
vector<bool> used(nums.size());
sort(nums.begin(), nums.end());
dfs(nums, 0, used);
return res;
}
void dfs(vector<int>& nums, int u, vector<bool>& used) {
res.push_back(path);
if (u == nums.size()) return;
for (int i = u; i < nums.size(); i++) {
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) continue;
path.push_back(nums[i]);
used[i] = true;
dfs(nums, i + 1, used);
used[i] = false;
path.pop_back();
}
}
};
491. 递增子序列
解题思路:
在 90.子集II 中我们是通过排序,再加一个标记数组来达到去重的目的。
而本题求自增子序列,是不能对原数组进行排序的,排完序的数组都是自增子序列了。
所以不能使用之前的去重逻辑!
本题给出的示例,还是一个有序数组 [4, 6, 7, 7],这更容易误导大家按照排序的思路去做了。
为了有鲜明的对比,我用[4, 7, 6, 7]这个数组来举例,抽象为树形结构如图:
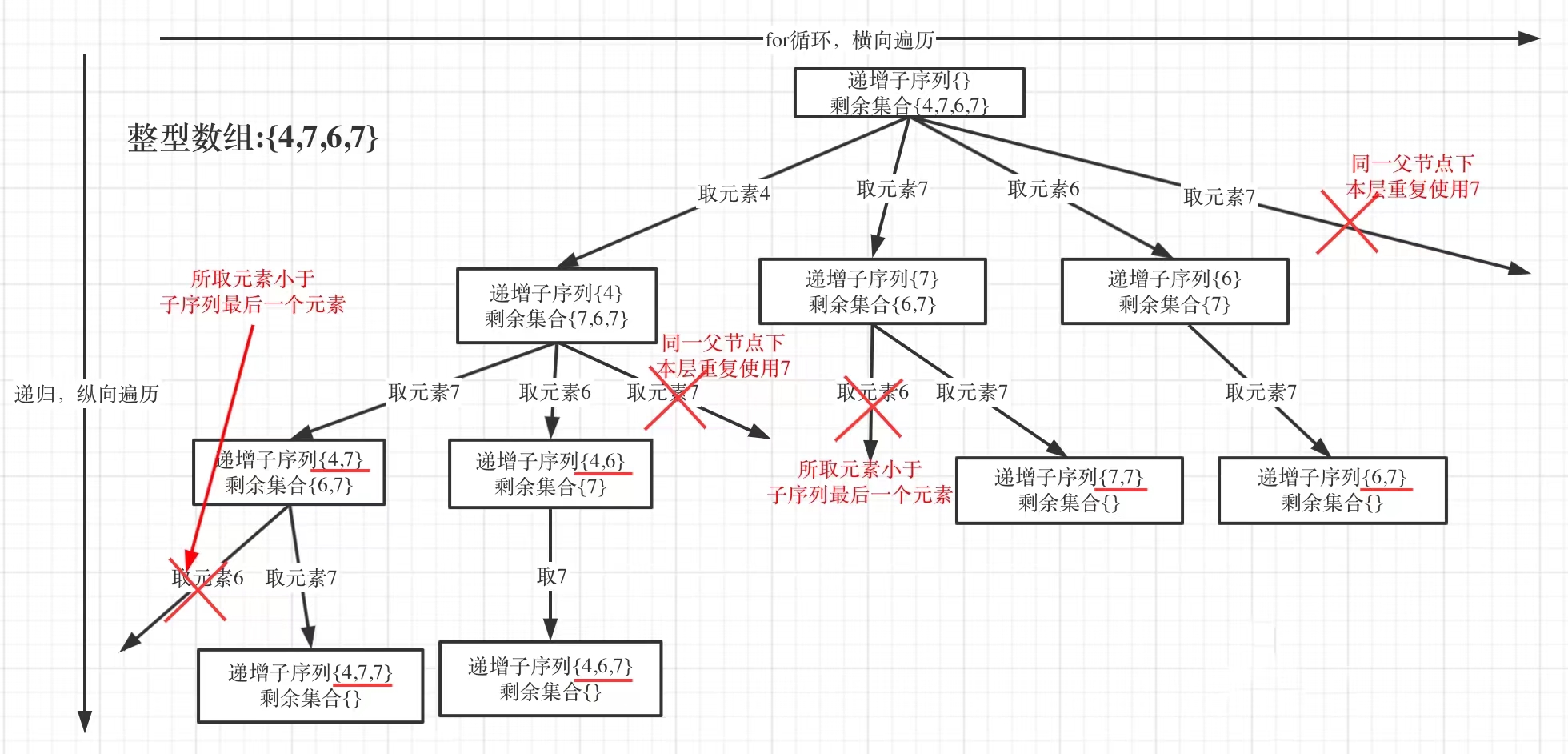
在图中可以看出,同一父节点下的同层上使用过的元素就不能再使用了,因此在这道题中使用unordered_set来对本层元素进行去重,在递归函数的上面添加S.insert(nums[i]);,记录本层元素是否重复使用,新的一层集合S都会重新定义(清空),所以S只负责本层,因此没有对应的pop之类的操作。
C++代码:
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
vector<vector<int>> findSubsequences(vector<int>& nums) {
dfs(nums, 0);
return res;
}
void dfs(vector<int>& nums, int u) {
if (path.size() >= 2)res.push_back(path);
if (u == nums.size()) return;
unordered_set<int> S; // 使用 S 对本层元素进行去重
for (int i = u; i < nums.size(); i++) {
if (path.empty() || nums[i] >= path.back())
{
if (S.count(nums[i])) continue;// 如果这个元素在本层已经用过,则直接跳过处理当前元素的操作
S.insert(nums[i]);// 记录这个元素在本层用过了,本层后面不能再用了
path.push_back(nums[i]);
dfs(nums, i + 1);
path.pop_back();
}
}
}
};
46. 全排列
解题思路:
(回溯) O(n×n!)
- 首先排列是 有序 的,也就是说
[1,2]和[2,1]是两个集合,这和之前分析的子集以及组合所不同的地方。
可以看出元素1在[1,2]中已经使用过了,但是在[2,1]中还要在使用一次1,所以处理排列问题就不用使用startIndex了。 - 我们从前往后,一位一位 枚举 ,每次选择一个没有被使用过的数。
选好之后,将该数的状态改成 已被使用 ,同时将该数记录在相应位置上,然后递归。
递归返回时,不要忘记将该数的状态改成 未被使用 ,并将该数从相应位置上删除。
而used数组,其实就是记录此时path里都有哪些元素使用了,一个排列里一个元素只能使用一次。
我以[1,2,3]为例,抽象成树形结构如下:
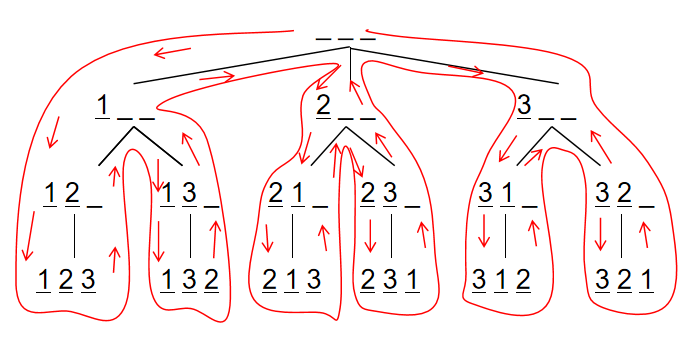
时间复杂度分析:
搜索树中最后一层共 n! 个叶节点,在叶节点处记录方案的计算量是 O(n),所以叶节点处的计算量是 O(n×n!)。
搜索树一共有 n!(1+1/2!+1/3!+…) ≤ n!(1+1/2+1/4+1/8+…) = 2n! 个内部节点,在每个内部节点内均会for循环 n 次,因此内部节点的计算量也是 O(n×n!)。 所以总时间复杂度是 O(n×n!)。
C++代码:
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
vector<vector<int>> permute(vector<int>& nums) {
vector<bool> used(nums.size());
dfs(nums, 0, used);
return res;
}
void dfs(vector<int>& nums, int u, vector<bool>& used) {
if (u == nums.size()) {
res.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
if (used[i] == true) continue; // path里已经收录的元素,直接跳过
path.push_back(nums[i]);
used[i] = true;
dfs(nums, u + 1, used);
used[i] = false;
path.pop_back();
}
}
};
47. 全排列 II
解题思路:
(回溯) O(n!)
这道题目和 46.全排列 的区别在与给定一个可包含重复数字的序列,要返回所有不重复的全排列。还要强调的是 去重 一定要对元素进行 排序 ,这样我们才方便通过相邻的节点来判断是否重复使用了。
- 先将所有数从小到大 排序 ,这样相同的数会排在一起;
- 从左到右依次枚举每个数,每次将它放在一个空位上;
- 对于相同数,我们人为定序,就可以避免重复计算
- 不要忘记递归前和回溯时,对状态进行更新。
我以示例中的[1,1,2]为例(为了方便举例,已经排序)抽象为一棵树,去重过程如图:
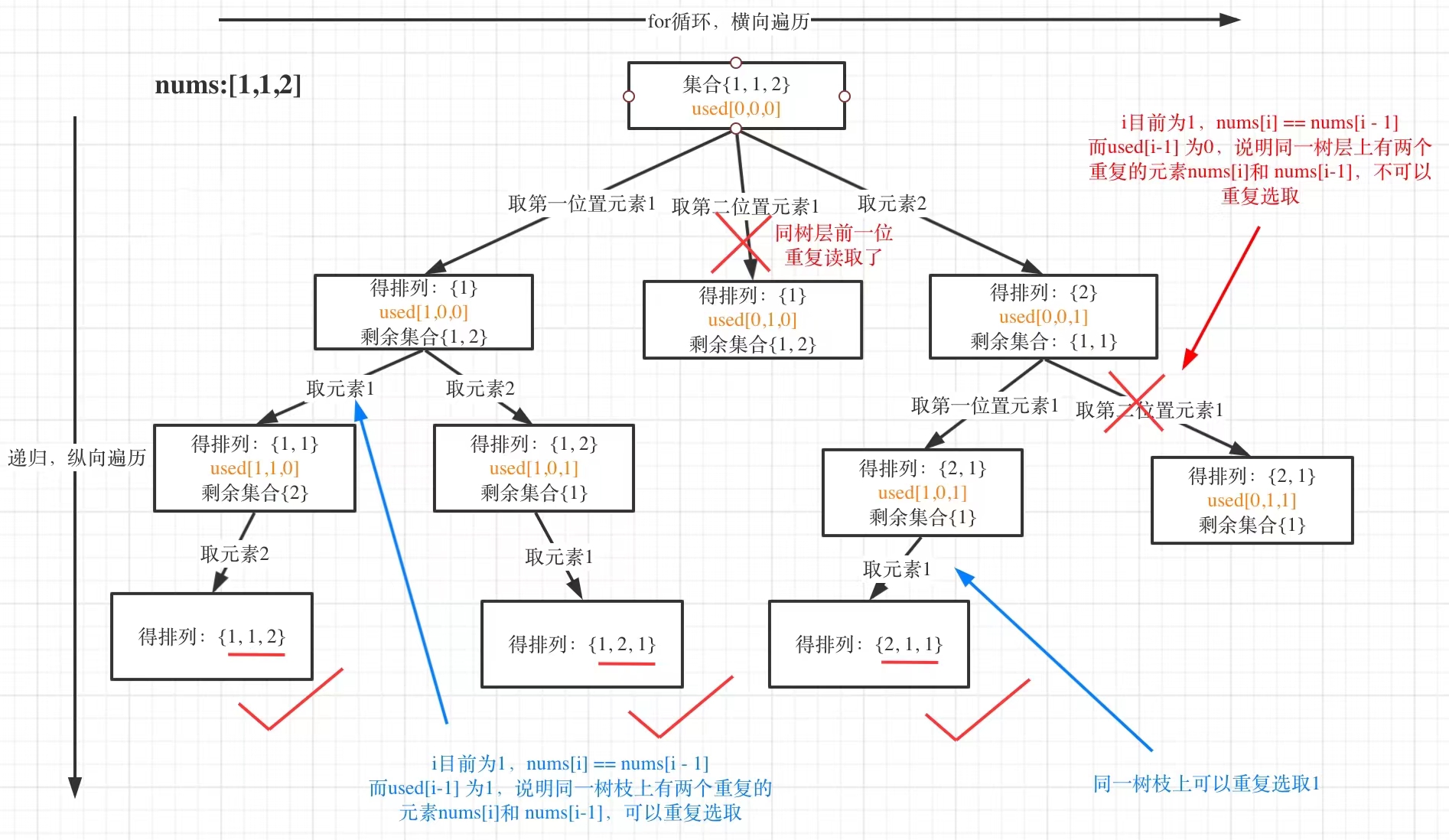
图中我们对同一树层,前一位(也就是nums[i-1])如果使用过,那么就进行 去重 。
一般来说:组合问题和排列问题是在树形结构的叶子节点上收集结果,而子集问题就是取树上所有节点的结果。
时间复杂度分析:搜索树中最后一层共 n! 个节点,前面所有层加一块的节点数量相比于最后一层节点数是无穷小量,可以忽略。且最后一层节点记录方案的计算量是 O(n),所以总时间复杂度是 O(n×n!) 。
C++代码:
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
vector<vector<int>> permuteUnique(vector<int>& nums) {
vector<bool> used(nums.size());
sort(nums.begin(), nums.end());
dfs(nums, 0, used);
return res;
}
void dfs(vector<int>& nums, int u, vector<bool>& used) {
if (u == nums.size()) {
res.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
// used[i - 1] == true,说明同一树枝nums[i - 1]使用过
// used[i - 1] == false,说明同一树层nums[i - 1]使用过
// 如果同一树层nums[i - 1]使用过则直接跳过
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) continue;
if (used[i] == false) {
path.push_back(nums[i]);
used[i] = true;
dfs(nums, u + 1, used);
used[i] = false;
path.pop_back();
}
}
}
};
注意⚠️:
如果把 if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) 中的 used[i - 1] == false 改成 used[i - 1] == true, 也是 正确 的!
- 对于排列问题,树层上去重和树枝上去重,都是可以的,但是树层上去重效率更高!
- 如果要对树层中前一位去重,就用
used[i - 1] == false; - 如果要对树枝前一位去重,就用
used[i - 1] == true。
















 514
514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











